

Data Insights エージェントは、Made by Google のエージェントです。BigQuery データからデータ分析情報を取得できます。Data Insights エージェントを使用すると、SQL の事前知識は必要ありません。これにより、データドリブンな情報に基づいたビジネス上の意思決定が可能になり、データ アナリストはより複雑なタスクに注力できます。
このページでは、 Google Cloud プロジェクト管理者が Google Cloud コンソールと REST API を使用して Data Insights エージェントを認可、作成、デプロイする方法について説明します。また、エンドユーザーがエージェントを使用する方法についても説明します。
概要
Data Insights エージェントは、次の処理を行うように設計されています。
- ユーザーの意図を理解する: 接続されたデータソースのコンテキストとユーザーの自然言語クエリを分析して、ユーザーの目標を理解します。
- SQL を生成する: この理解に基づいて、ユーザーの質問を構文的にも意味的にも正しい SQL クエリに変換します。
- データを取得する: 生成された SQL を実行して、接続されたデータソース(BigQuery データセット)から関連データを直接取得します。
- 分析情報を提供する: 取得したデータをグラフや表などの可視化された形式で表示するか、テキストベースの要約として表示することによって、ユーザーのクエリに回答します。
Data Insights エージェントに尋ねることができるクエリの例
Data Insights エージェントに質問できるクエリの例を次に示します。
- データの集計と可視化:
- 「今年の中南米地域の第 2 四半期の売上は、昨年の第 2 四半期と比較してどうだった?」
- 「この地域のアクセス数上位 5 か国の比較を示す棒グラフを作成して。」
- 傾向分析:
- 「過去 6 か月間の発信通話の件数は、地域別にどのように変化した?」
- 「リスボンの 4 つ星以上のホテルの予約パターンを分析して。」
- データ マイニング:
- 「顧客が何かを購入する際、総売上高と相関関係にある要因は何?その関係を示すヒートマップを作成して。」
- 分析とレポート:
- 「商談とアカウントの表を要約して、主な傾向をハイライトした短いレポートを作成して。」
始める前に
Gemini Enterprise で Data Insights エージェントの使用を開始する手順は次のとおりです。
- Gemini Enterprise を使ってみるの手順に沿って操作します。
- Gemini Enterprise のライセンスを取得する手順に沿って操作します。
- Data Insights エージェントにアクセスするには、Google アカウント マネージャーにお問い合わせください。
- BigQuery データを準備します。詳細については、BigQuery のドキュメントをご覧ください。
- エージェントを最大限に活用するには、BigQuery データセット内のデータを理解します。
BigQuery データへのアクセス権を付与する
Data Insights エージェントが BigQuery データを表示してクエリを実行できるようにするには、エージェントのユーザーに Identity and Access Management(IAM)ロールを付与します。
- BigQuery データ閲覧者(
roles/bigquery.dataViewer) - BigQuery ジョブユーザー(
roles/bigquery.jobUser) - BigQuery メタデータ閲覧者(
roles/bigquery.metadataViewer)
ワークフロー
Data Insights エージェントを設定して使用するための全体的なワークフローは次のとおりです。
- 認可の詳細情報を取得する
- Google Cloud コンソールまたは REST API を使用してエージェントを設定する
- ユーザーとそれらのユーザーの権限を追加または変更する
- エージェント インスタンスの動作状態を変更する
- エージェントを使用する
認可の詳細情報を取得する
認可を設定する手順は次のとおりです。取得した詳細情報は、Data Insights エージェントが BigQuery データに接続することを認可するために必要です。
Google Cloud コンソールで、[API とサービス] の [認証情報] ページに移動します。
エージェントにクエリを実行させる BigQuery データセットを含む Google Cloud プロジェクトを選択します。
[認証情報を作成] をクリックし、[OAuth クライアント ID] を選択します。
[アプリケーションの種類] で [ウェブ アプリケーション] を選択します。
[承認済みのリダイレクト URI] セクションに、次の URI を追加します。
https://vertexaisearch.cloud.google.com/oauth-redirecthttps://vertexaisearch.cloud.google.com/static/oauth/oauth.html
[作成] をクリックします。
[OAuth クライアントを作成しました] パネルで、[JSON をダウンロード] をクリックします。ダウンロードした JSON には、選択したGoogle Cloud プロジェクトの次の詳細情報が含まれます。認可リソースを作成するには、次の情報が必要です。
- クライアント ID: CLIENT_ID
- 認可 URI:
https://accounts.google.com/o/oauth2/v2/auth?client_id=CLIENT_ID&redirect_uri=https%3A%2F%2Fvertexaisearch.cloud.google.com%2Fstatic%2Foauth%2Foauth.html&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fbigquery&include_granted_scopes=true&response_type=code&access_type=offline&prompt=consent
- トークン URI:
https://oauth2.googleapis.com/token - クライアント シークレット: CLIENT_SECRET
Google Cloud コンソールを使用してエージェントを設定する
このセクションでは、 Google Cloud コンソールを使用して Data Insights エージェントのインスタンスを認可、作成、デプロイする方法について説明します。作成したエージェントにアクセスできるユーザーを決定するためのユーザー権限を追加することもできます。
エージェント インスタンスを認可して作成する
次の手順で、Data Insights エージェントのインスタンスを認可して作成します。
Google Cloud コンソールで、[Gemini Enterprise] に移動します。
エージェントを作成するアプリを選択します。
メニューで [エージェント] をクリックします。
[エージェント] ページに、既存のエージェントが表示されます。
[エージェントを追加] をクリックします。
[エージェントを作成] ペインで、[データ エージェント] カードの [作成] をクリックします。
[承認] で、[承認を追加] をクリックして、承認の詳細を入力します。詳細については、承認を取得するをご覧ください。
[完了] をクリックします。
[次へ] をクリックします。
エージェントを次のように構成します。
- エージェントの名前と説明を入力します。
- [BigQuery データセット] で、[参照] をクリックし、次のいずれかを行います。
- 使用可能なデータセットを選択し、[選択] をクリックします。
- 必要な BigQuery データセットのパスを入力して、[検索] をクリックして選択し、[選択] を選択します。
省略可: 詳細オプションを表示するには、[詳細を表示] をクリックします。
正しいテーブル アクセス オプションを選択します。許可リストまたはブロックリストを適用する場合は、制限付きテーブルのパスを指定します。
省略可: 自然言語クエリ構成を定義して、自然言語から SQL または Python コードへの変換に固有のカスタマイズを指定します。自然言語クエリ、想定される SQL 出力、想定されるレスポンスを使用して SQL の例を指定することもできます。これにより、エージェントの出力の品質が向上します。
- スキーマの説明: BigQuery データセットのスキーマを説明する自然言語の文字列。
- 自然言語クエリを SQL に変換するプロンプト: 自然言語のクエリが SQL 命令に変換されます。
- 自然言語クエリを Python に変換するプロンプト: 自然言語のクエリが Python の指示に変換されます。
省略可: SQL クエリに変換された自然言語クエリの例を追加します。
- クエリ: SQL クエリに変換する必要がある自然言語クエリの例。例: 「カリフォルニア州に在住するお客様の名前とメールアドレスを教えて」
- Expected SQL: 自然言語クエリに対応する SQL クエリの例を示す文字列。たとえば、
customersという名前の BigQuery テーブルがあるとします。この場合、想定される SQL クエリはSELECT customer_name, email FROM customers WHERE state = 'California'になります。 - 想定されるレスポンス: 想定される SQL クエリを実行して、クエリに対する想定される回答を提示する文字列。例:
Here are the names and email addresses of your customers in California: \ * Customer name: Lara B, Email address: 222larabrown@gmail.com \ * Customer name: Alex A, Email address: baklavainthebalkans@gmail.com \ * Customer name: Bola C, Email address: cloudysanfrancisco@gmail.com \
[作成] をクリックします。
Data Insights エージェントのインスタンスが [エージェント] リストに表示されます。
エージェントの操作を開始するには、[エージェントの状態] 列にインスタンスが [有効] と表示されるまで待ちます。
REST API を使用してエージェントを設定する
このセクションでは、REST API を使用して Data Insights エージェントのインスタンスを認可、作成、デプロイする方法について説明します。
エージェントを認可する
管理者として、Gemini Enterprise で認可リソースを作成します。これにより、Data Insights エージェントが BigQuery データにアクセスできるようになります。
認可リソースを作成します。
REST
次のサンプルは、
authorizations.createメソッドを使用して認可リソースを作成する方法を示しています。curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_NUMBER" \ "https://discoveryengine.googleapis.com/v1alpha/projects/PROJECT_NUMBER/locations/LOCATION/authorizations?authorizationId=AUTHORIZATION_ID" \ -d '{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/authorizations/AUTHORIZATION_ID", "serverSideOauth2": { "clientId": "CLIENT_ID", "clientSecret": "CLIENT_SECRET", "authorizationUri": "AUTHORIZATION_URI", "tokenUri": "https://oauth2.googleapis.com/token" } }'次のように置き換えます。
PROJECT_NUMBER: Google Cloud プロジェクトの数。LOCATION: Google Cloud プロジェクトのロケーション。AUTHORIZATION_ID: 認可リソースを識別するために指定する必要がある ID。CLIENT_ID: 前のステップで取得したクライアント ID。CLIENT_SECRET: 前のステップで取得したクライアント シークレット。AUTHORIZATION_URI: 前のステップで取得した認可 URI。
エージェント インスタンスを作成する
Google Cloud プロジェクト管理者として、Data Insights エージェントのインスタンスを作成できます。これには、エージェントを使用してクエリする BigQuery データのプロジェクト ID とデータセット ID が必要です。
REST
次のサンプルは、agents.create メソッドを使用して Data Insights エージェントのインスタンスを作成する方法を示しています。このサンプルに追加できる高度なフィールドについては、エージェントの高度な構成を追加するをご覧ください。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Goog-User-Project: PROJECT_NUMBER" \
"https://discoveryengine.googleapis.com/v1alpha/projects/PROJECT_NUMBER/locations/LOCATION/collections/default_collection/engines/APP_ID/assistants/default_assistant/agents" \
-d '{
"displayName": "AGENT_DISPLAY_NAME",
"description": "AGENT_DESCRIPTION",
"icon": {
"uri": "AGENT_ICON_URI"
},
"managed_agent_definition": {
"tool_settings": {
"tool_description": "AGENT_DESCRIPTION"
},
"data_science_agent_config": {
"bq_project_id": "BIGQUERY_PROJECT_ID",
"bq_dataset_id": "BIGQUERY_DATASET_ID"
}
},
"authorization_config": {
"tool_authorizations" : [
"AUTHORIZATION_RESOURCE_NAME"
]
}
}'
次のように置き換えます。
PROJECT_NUMBER: Google Cloud プロジェクトの数。LOCATION: Gemini Enterprise アプリのロケーション。APP_ID: アプリの ID。AGENT_DISPLAY_NAME: Data Insights エージェントのインスタンスの名前。AGENT_ICON_URI: エージェントのアイコンの URI を指定するオプションのフィールド。AGENT_DESCRIPTION: エージェントの目的や BigQuery データソースの詳細を示す Data Insights エージェントのインスタンスの説明。BIGQUERY_PROJECT_ID: BigQuery データセットを含むGoogle Cloud プロジェクトのプロジェクト ID。BIGQUERY_DATASET_ID: クエリ対象のデータを含む BigQuery データセット ID。AUTHORIZATION_RESOURCE_NAME: 前のセクションで取得した認可リソース名。
エージェントの高度な構成を追加する
必要に応じて nlQueryConfig フィールドを定義して、自然言語から SQL または Python コードへの変換に固有のカスタマイズを指定できます。自然言語クエリ、想定される SQL 出力、想定されるレスポンスを使用して SQL の例を指定することもできます。これにより、エージェントの出力の品質が向上します。次のコード スニペットは、これらの詳細フィールドを構成する方法を示しています。
"dataScienceAgentConfig": {
"nlQueryConfig": {
"nl2sqlPrompt": "NL_TO_SQL_INSTRUCTIONS",
"nl2pyPrompt": "NL_TO_PYTHON_INSTRUCTIONS",
"nl2sqlExample": {
"query": "EXAMPLE_NL_QUERY",
"expectedSql": "EXPECTED_SQL_QUERY",
"expectedResponse": "EXPECTED_SQL_RESPONSE"
},
"schemaDescription": "NL_DESCRIPTION_OF_BQ_DATASET"
}
}
次のように置き換えます。
NL_TO_SQL_INSTRUCTIONS: 自然言語のクエリが SQL 命令に変換されたもの。NL_TO_PYTHON_INSTRUCTIONS: 自然言語のクエリが Python の指示に変換されたもの。EXAMPLE_NL_QUERY: SQL クエリに変換する必要がある自然言語クエリの例。例: 「カリフォルニア州に在住するお客様の名前とメールアドレスを教えて」EXPECTED_SQL_QUERY: 自然言語クエリに対応する SQL クエリの例を示す文字列。たとえば、customersという名前の BigQuery テーブルがあるとします。この場合、想定される SQL クエリは「SELECT customer_name, email FROM customers WHERE state = 'California'」であることが考えられます。EXPECTED_SQL_RESPONSE: クエリの想定される回答と想定される SQL クエリを提示する文字列。例:Here are the names and email addresses of your customers in California: \ * Customer name: Lara B, Email address: 222larabrown@gmail.com \ * Customer name: Alex A, Email address: baklavainthebalkans@gmail.com \ * Customer name: Bola C, Email address: cloudysanfrancisco@gmail.com \NL_DESCRIPTION_OF_BQ_DATASET: BigQuery データセットのスキーマを説明する自然言語の文字列。
インスタンスをデプロイする
Data Insights エージェントのインスタンスを作成したら、管理者として、エンドユーザーによる使用が可能になるようにデプロイできます。
REST
エージェントをデプロイします。次のサンプルは、
agents.deployメソッドを使用して作成したエージェントをデプロイする方法を示しています。エージェントのデプロイは長時間実行オペレーション(LRO)です。curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_NUMBER" \ "https://discoveryengine.googleapis.com/v1alpha/AGENT_RESOURCE_NAME:deploy" \ -d '{ "name":"AGENT_RESOURCE_NAME" }'次のように置き換えます。
PROJECT_NUMBER: Google Cloud プロジェクトの数。AGENT_RESOURCE_NAME: 前のセクションでエージェントを作成したときに取得したエージェント リソース名。
デプロイ オペレーションのステータスを取得します。次のサンプルは、デプロイ オペレーションの
operations.getメソッドのステータスを取得する方法を示しています。curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ "https://discoveryengine.googleapis.com/v1alpha/DEPLOY_OPERATION_NAME"
DEPLOY_OPERATION_NAMEは、前のステップでエージェントをデプロイしたときに取得した LRO 名に置き換えます。レスポンスで、
doneフィールドの値がtrueの場合、デプロイは完了しています。doneフィールドの値がfalseの場合、デプロイは進行中です。
ユーザーとそれらのユーザーの権限を追加または変更する
次の手順で、Data Insights エージェントのインスタンスに対してプリンシパルを追加または変更し、特定の Identity and Access Management(IAM)ロールを割り当てます。
コンソール
Google Cloud コンソールで、[Gemini Enterprise] に移動します。
Data Insights エージェントのインスタンスを含むアプリを選択します。
メニューで [エージェント] をクリックします。
[エージェント] ページに、既存のエージェントが表示されます。
ユーザーを追加または変更するエージェントをクリックします。たとえば、Data Insights エージェント インスタンスをクリックします。
デフォルトでは、新しく作成されたエージェントにはユーザーが設定されていません。
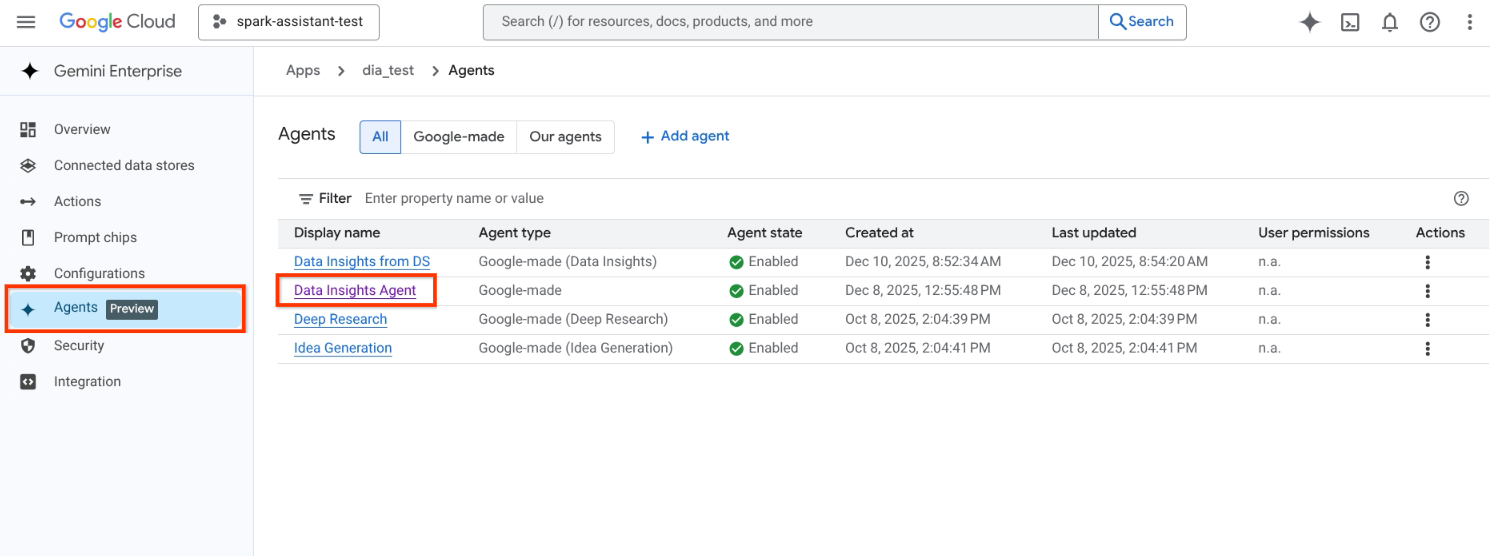
Data Insights エージェント インスタンスをクリック [ユーザー権限] をクリックします。
[権限のあるユーザー] テーブルで、[ユーザーを追加] をクリックします。
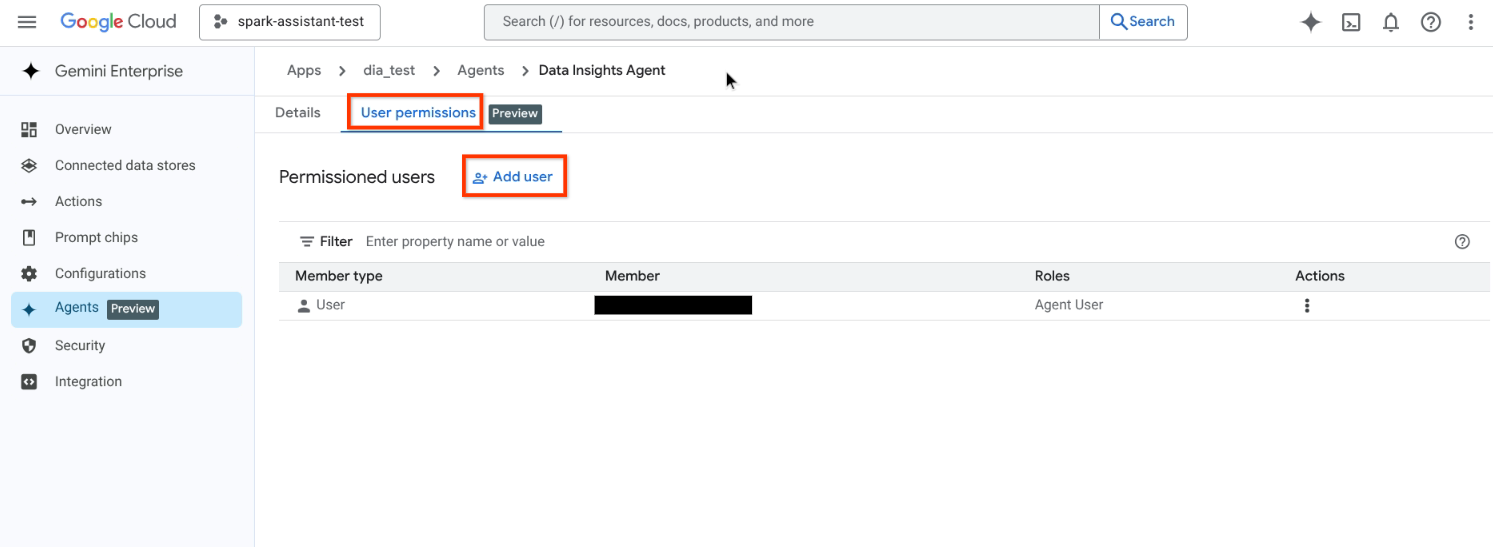
ユーザーを追加する画面に移動 使用可能なリストからメンバータイプを選択します。
ユーザーまたはグループの場合は、メールアドレスをメンバー文字列として入力し、ロールを選択します。
Workforce Identity プールの場合は、有効なプリンシパルをメンバー文字列として入力し、ロールを選択します。
[すべてのユーザー] でロールを選択します。
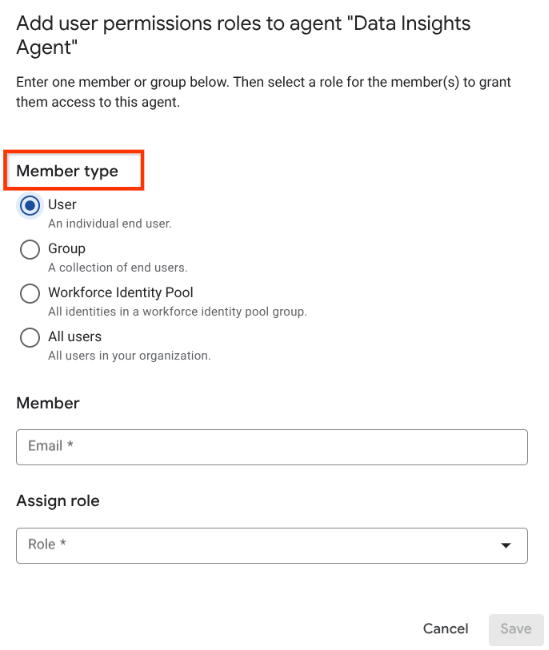
メンバータイプを選択 [保存] をクリックします。
IAM ポリシーが更新され、ユーザーが権限付与されたユーザーのリストに追加されます。
割り当てられた権限を削除するには、[操作] 列の をクリックし、[削除] をクリックします。
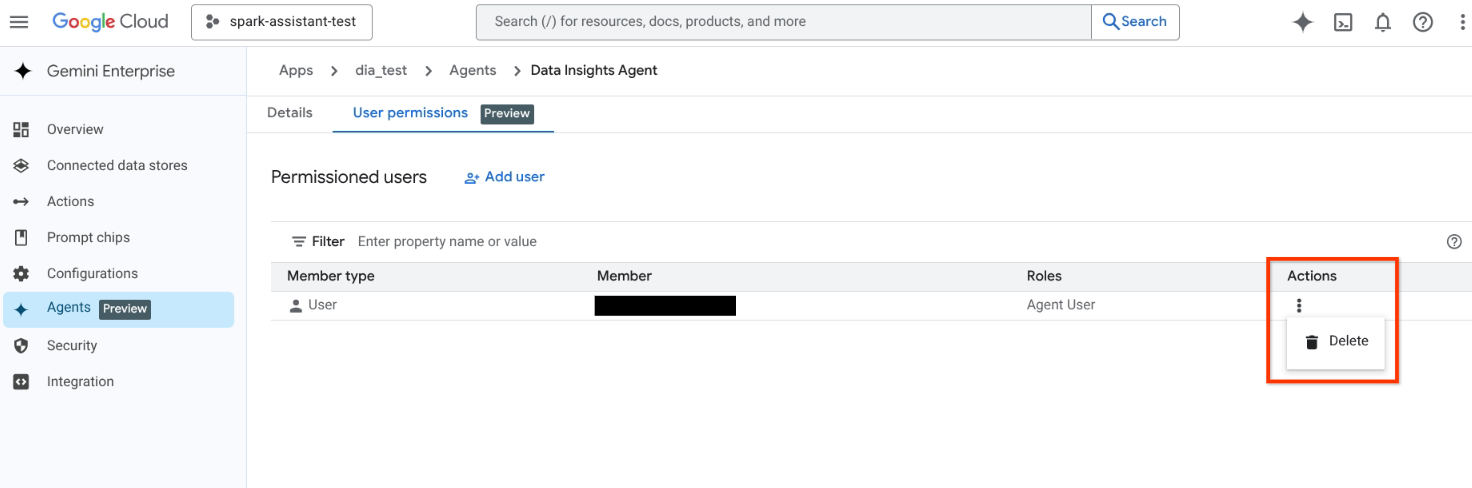
ロールを削除
インスタンスの動作状態を変更する
Data Insights エージェントのインスタンスを作成すると、エージェントはデフォルトで有効になります。次の手順で、動作状態を [プレビュー]、[無効]、[一時停止]、または [削除] に変更できます。
コンソール
Google Cloud コンソールで、[Gemini Enterprise] に移動します。
Data Insights エージェントのインスタンスを含むアプリを選択します。
メニューで [エージェント] をクリックします。
[エージェント] ページに、既存のエージェントが表示されます。
エージェントの [操作] 列で をクリックし、次のいずれかを選択します。
- プレビュー: エージェントを新しいタブで開きます。
- 無効: エージェントを作成したユーザー以外のすべてのユーザーがエージェントを利用できないようにします。
- 一時停止: エージェントを一時的に使用できないようにします。ただし、エージェントにアクセスするための任意のレベルの権限を付与されているユーザーは、引き続きエージェントを表示できます。
- 削除: エージェント インスタンスを削除します。
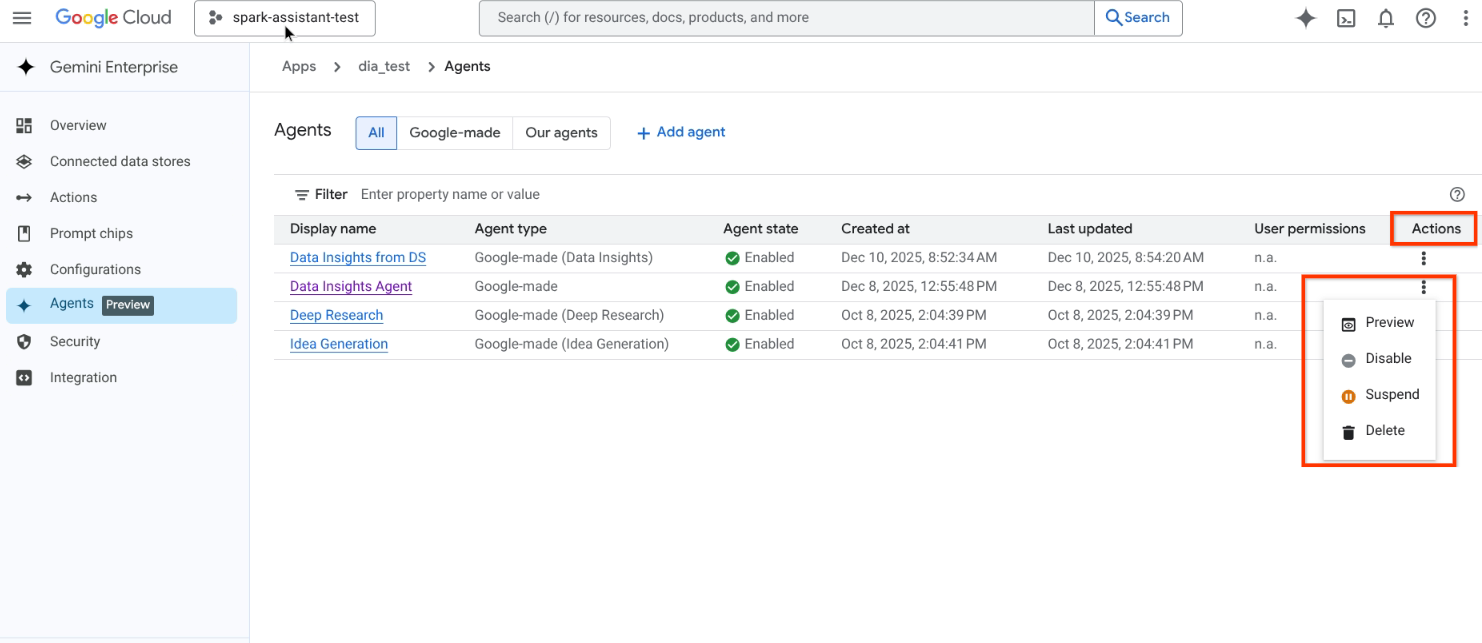
エージェントのアクションを 1 つ選択します。
エージェントを使用する
エージェントを使用してデータ分析情報を取得する手順は次のとおりです。
アプリ
アプリのナビゲーション メニューで、[エージェント] をクリックします。
[View all agents] をクリックします。
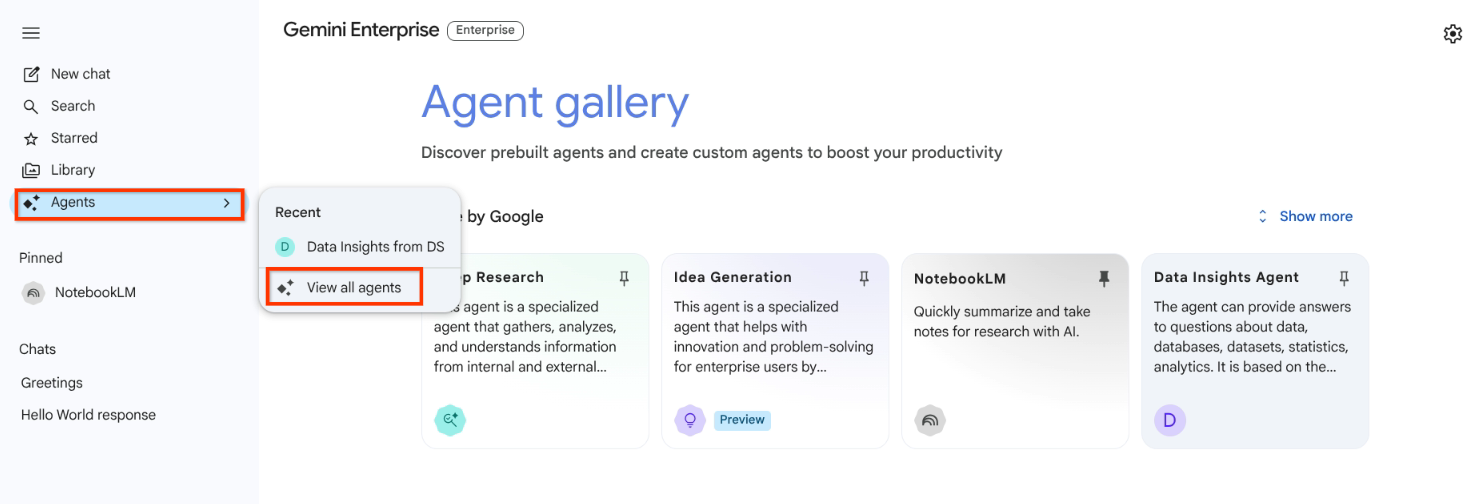
すべてのエージェントを表示 表示されたエージェントのリストまたは最近使用したリストからエージェントを選択します。
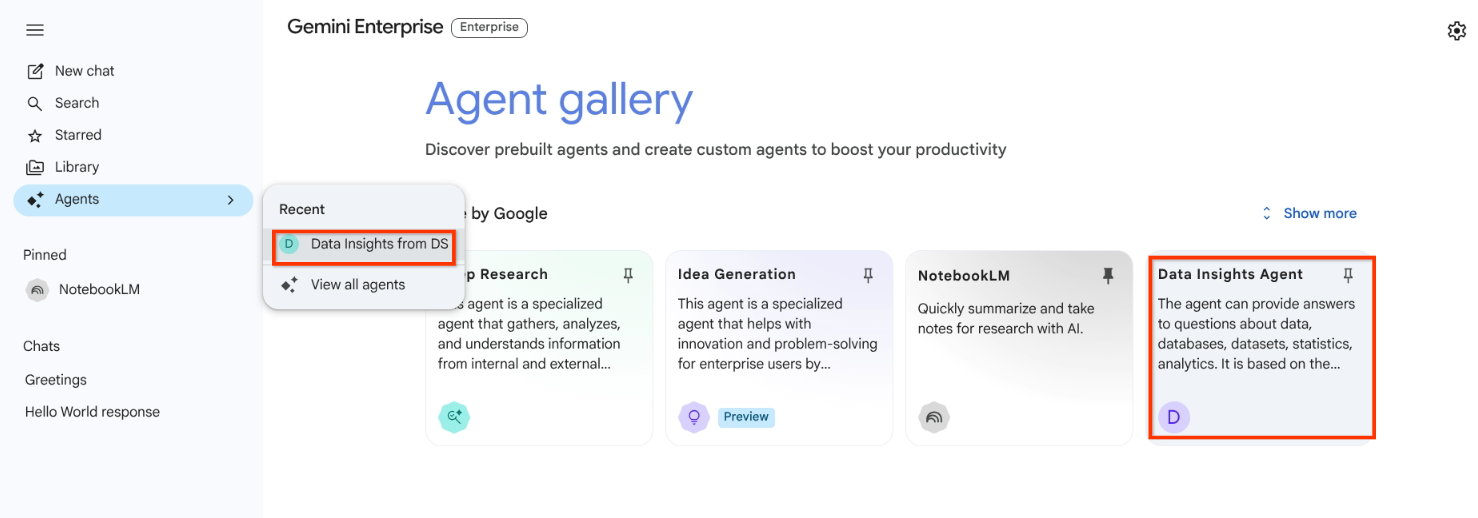
エージェント インスタンスを選択 エージェントが追加の承認を必要とする場合は、[承認] をクリックして承認の詳細を入力します。
検索ボックスで、次の操作を行います。
アイコンをクリックして、エージェントが使用する追加のデータソースとしてファイルを追加します。
アイコンをクリックしてデータを管理します。
質問またはプロンプトを入力し、Enter キーを押します。