Mit benutzerdefinierten Connectors können Sie externe Datenquellen einbinden, die nicht in der Connector-Standardbibliothek von Gemini Enterprise enthalten sind. So können Sie die speziellen Daten Ihrer Organisation durchsuchen und in natürlicher Sprache darauf zugreifen. Die Suche wird von Gemini und der erweiterten Suchintelligenz von Google unterstützt. Der benutzerdefinierte Connector interagiert direkt mit der Discovery Engine API, die robuste Datenspeicherung, Indexierung und intelligente Suchfunktionen ermöglicht. Der Connector konvertiert die Quellinformationen in das standardisierte JSON-basierte Dokumentformat (Strukturierung von Inhalt, Metadaten und Zugriffssteuerungslisten (Access Control Lists, ACLs)) und sorgt dafür, dass diese Daten in Datenspeichern organisiert werden. Diese Speicher fungieren als logische Repositories, die idealerweise ein einzelnes Dokumentformat darstellen und jeweils einen eigenen dedizierten Suchindex und eigene Konfigurationen haben.
Funktionsweise von benutzerdefinierten Connectors
Benutzerdefinierte Connectors verwenden eine automatisierte Datenpipeline, um drei wichtige Aktionen auszuführen: Abrufen, Transformieren und Synchronisieren. Hierbei werden externe Daten korrekt vorbereitet und in Gemini Enterprise hochgeladen.
Abrufen: Der Connector ruft Daten (einschließlich Dokumenten, Metadaten und Berechtigungen) aus dem externen System über seine APIs, Datenbanken oder Dateiformate ab.
Transformieren: Der Connector wandelt Rohdaten in das Dokumentformat der Discovery Engine um, strukturiert die Inhalte und Metadaten und weist jedem Dokument eine global eindeutige ID zu. Für die Zugriffssteuerung können Sie entweder direkt von Google erkannte Identitäten oder die Identitätszuweisung für externe Nutzer oder benutzerdefinierte Gruppen verwenden.
Synchronisierung: Der Connector lädt die Dokumente in Gemini Enterprise-Datenspeicher hoch und hält sie durch geplante Jobs auf dem neuesten Stand. Die Datensynchronisierung erfolgt über einen Datenspeicher, der für eine Entität erstellt wurde. Weitere Informationen zum Erstellen eines Datenspeichers finden Sie unter Datenspeicher erstellen. Wählen Sie einen entsprechenden Synchronisierungsmodus aus: Mit Inkrementell können Sie Daten hinzufügen und aktualisieren, mit Vollständig ersetzen Sie das gesamte Dataset.
ACLs und Identitätszuweisung
Für die Verwaltung des Zugriffs auf Dokumentebene haben Sie zwei Möglichkeiten: reine ACLs oder die Identitätszuweisung. Welche Methode Sie verwenden, hängt vom Identitätsformat der Daten ab.
Reine ACLs (AclInfo): Diese Methode wird verwendet, wenn die Datenquelle auf E-Mails basierende Identitäten verwendet, die von (Google Cloud) erkannt werden. Dieser Ansatz ist ideal, um direkt festzulegen, wer Zugriff hat.
Identitätszuweisung: Diese Methode wird verwendet, wenn in der Datenquelle Nutzernamen, Legacy-IDs oder andere externe Identitätssysteme verwendet werden. Dadurch ergibt sich eine eindeutige 1:1-Verknüpfung zwischen externen Identitätsgruppen (z. B. EXT1) und internen Nutzern oder Gruppen des Identitätsanbieters (Identity Provider, IDP) (z. B. IDPUser1@example.com). So kann das System gruppenbasierte Zugriffssteuerungen aus dem Quellsystem verstehen und anwenden. Das ist nützlich, wenn eine API Gruppenlabels ohne vollständige Nutzermitgliedschaften zurückgibt oder wenn ACLs effizient skaliert werden sollen, ohne dass Tausende von Nutzern pro Dokument aufgeführt werden müssen. Dazu müssen alle verschachtelten oder hierarchischen Identitätsstrukturen in eine flache Liste direkter Zuweisungen aufgelöst werden, in der Regel in einem angegebenen JSON-Format. Verwenden Sie eindeutige externe Gruppen-IDs (z. B. EXT1) für externe Identitäten, um die Systemintegrität zu wahren. Weitere Informationen und Beispiele finden Sie unter „Identitätszuweisung“.
Datenspeicher erstellen
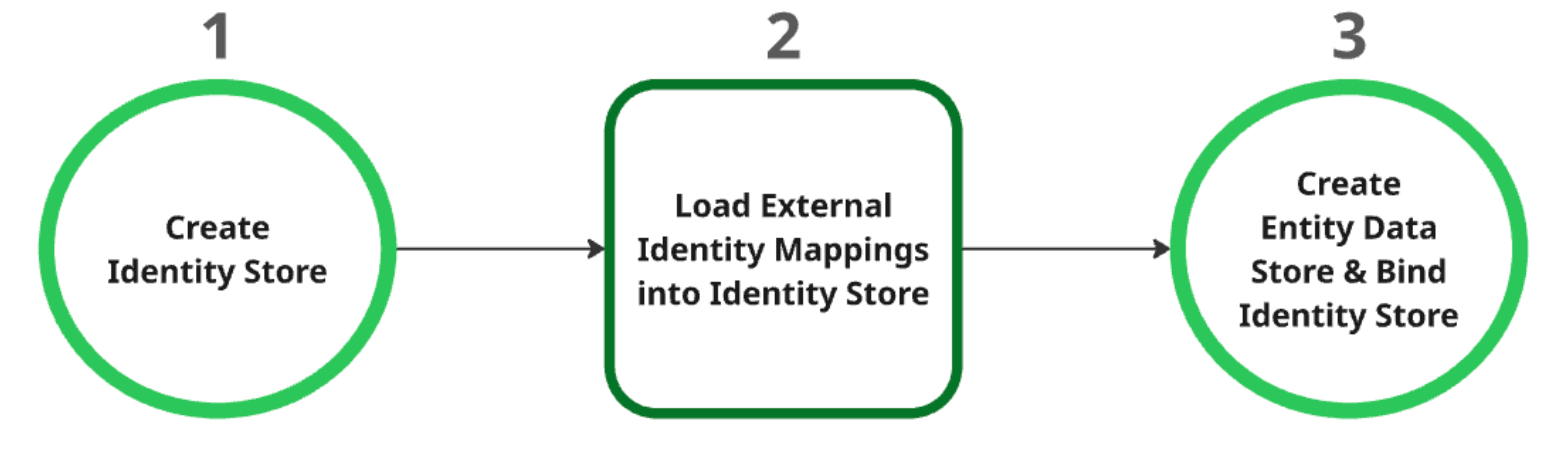
Identitätsspeicher erstellen: Dieser Speicher dient als übergeordnete Ressource für alle Identitätszuweisungen. Nach der Erstellung werden automatisch die Einstellungen des Identitätsanbieters (IDP) auf Projektebene abgerufen. Weitere Informationen finden Sie unter Identitätsspeicher abrufen oder erstellen.
Externe Identitätszuweisungen in den Identitätsspeicher laden: Nachdem Sie den Identitätsspeicher erstellt haben, laden Sie die externen Identitätsdaten in den Speicher. Weitere Informationen finden Sie unter Identitätszuweisung in Identitätsspeicher aufnehmen.
Entitätsdatenspeicher erstellen und binden: Der Entitätsdatenspeicher kann erst nach dem erfolgreichen Erstellen des Identitätsspeichers und dem Laden der Identitätszuweisungen erstellt werden. Sie müssen den Identitätsspeicher beim Erstellen an den Entitätsdatenspeicher binden. Weitere Informationen zum Erstellen eines Entitätsdatenspeichers finden Sie unter Datenspeicher erstellen.
Daten synchronisieren
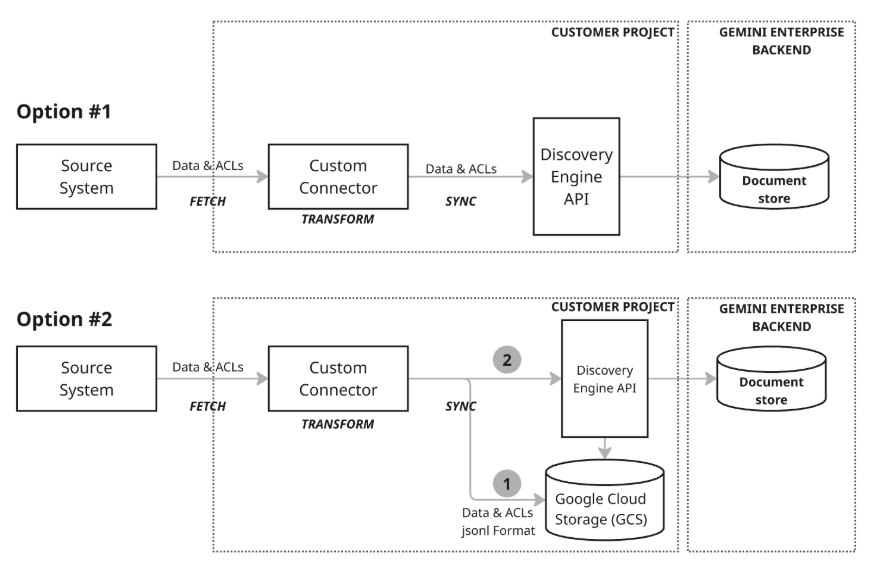
Es gibt zwei Architekturmodelle für die Datensynchronisierung:
Architekturmodell 1: Inkrementelles Upsert. Der inkrementelle Upsert-Ansatz eignet sich am besten für Szenarien, in denen Daten gestreamt werden und Echtzeitaktualisierungen erforderlich sind. Der Connector nutzt die Discovery Engine API, um effiziente, inkrementelle Upserts (Einfügen oder Aktualisieren von Daten) durchzuführen. Dazu werden die entsprechenden Funktionen mit kleinen Änderungen aufgerufen, wenn sie auftreten. Durch diesen Fokus auf minimale Änderungsgrößen und Verzögerungen bleibt der Dokumentspeicher auch bei sich schnell ändernden Daten immer aktuell.
Architekturmodell 2: Umfassende Synchronisierung mit Google Cloud Storage. Dieser empfohlene Ansatz bietet eine umfassende Reihe von Datenmanagementfunktionen und hohe Flexibilität. Er unterstützt vollständige Synchronisierungen, die das Einfügen, Aktualisieren und Löschen von Daten im gesamten Dataset ermöglichen, sowie inkrementelle Synchronisierungen, bei denen nur Einfügungen und Aktualisierungen durch Senden von Änderungen abgewickelt werden. Dadurch ist der Ansatz für viele Datenanforderungen geeignet, insbesondere für die Verwaltung größerer oder komplexerer Datenvorgänge. Dieses Modell verwendet einen Staging-Prozess (Schritt 1 im Diagramm), bei dem der Connector die Daten zuerst in Google Cloud Storage (GCS) schreibt und dann die Discovery Engine API nutzt, um den Dokumentenspeicher zu aktualisieren. Dazu werden die erforderlichen Importfunktionen am GCS-Staging-Speicherort aufgerufen.
Benutzerdefinierte Connectors sind flexibel genug, um eine Hybridarchitektur zu unterstützen. So können Sie inkrementelle Upserts für sich schnell ändernde Daten und eine umfassende Synchronisierung für geplante vollständige Datenaktualisierungen oder -löschungen implementieren.