
Auf dieser Seite wird beschrieben, wie Sie einen benutzerdefinierten Connector erstellen.
Hinweis
Folgendes wird benötigt:
Prüfen Sie, ob die Abrechnung für Ihr Google Cloud -Projekt aktiviert ist.
Installieren und initialisieren Sie die Google Cloud -Befehlszeile. Achten Sie darauf, dass sie für Ihr Projekt authentifiziert ist.
Installieren Sie die erforderlichen Python-Bibliotheken:
pip install google-cloud-discoveryengine requestsRufen Sie den Discovery Engine-Administratorzugriff für Ihr Google Cloud Projekt ab.
Rufen Sie Zugriffsanmeldedaten für Ihre Drittanbieter-Datenquelle ab, z. B. API-Schlüssel oder Datenbankauthentifizierung.
Erstellen Sie einen klaren Plan zur Datenzuweisung. Dazu muss gehören, welche Felder indexiert werden sollen und wie die Zugriffssteuerung einschließlich Drittanbieteridentitäten dargestellt werden soll.
Einfachen Connector erstellen
In diesem Abschnitt wird gezeigt, wie Sie einen benutzerdefinierten Connector in der von Ihnen ausgewählten Sprache erstellen. Die hier gezeigten Prinzipien und Muster gelten für jedes externe System. Passen Sie einfach die API-Aufrufe und Datentransformationen für Ihre spezifische Quelle in der von Ihnen gewählten Sprache an, um einen einfachen Connector zu erstellen.
Daten abrufen
Rufen Sie zuerst Daten aus Ihrer Drittanbieterdatenquelle ab. In diesem Beispiel wird gezeigt, wie Sie Beiträge mithilfe der Paginierung abrufen. In Produktionsumgebungen empfehlen wir, für große Datasets einen Streamingansatz zu verwenden. So werden Speicherprobleme vermieden, die beim gleichzeitigen Laden aller Daten auftreten können.
Python
from typing import List
import requests
def fetch_posts(base_url: str, per_page: int = 15) -> List[dict]:
#Fetch all posts from the given site.#
url = base_url.rstrip("/") + "/wp-json/wp/v2/posts"
posts: List[dict] = []
page = 1
while True:
resp = requests.get(
url,
params={"page": page, "per_page": per_page},
# headers={"Authorization": "Bearer YOUR_API_KEY"}, # Add auth if needed
)
resp.raise_for_status()
batch = resp.json()
posts.extend(batch)
if len(batch) < per_page:
break
page += 1
return posts
Daten transformieren
Wenn Sie Ihre Quelldaten in das Discovery Engine-Dokumentformat konvertieren möchten, strukturieren Sie sie wie in der folgenden Beispielnutzlast. Sie können beliebig viele Schlüssel/Wert-Paare einfügen. Sie können beispielsweise den vollständigen Inhalt einbeziehen, um eine umfassende Suche durchzuführen. Alternativ können Sie strukturierte Felder für eine Suche mit Facetten oder eine Kombination aus beidem einfügen.
Python
from typing import List
import json
from google.cloud import discoveryengine_v1 as discoveryengine
def convert_posts_to_documents(posts: List[dict]) -> List[discoveryengine.Document]:
# Convert WP posts into Discovery Engine Document messages.
docs: List[discoveryengine.Document] = []
for post in posts:
payload = {
"title": post.get("title", {}).get("rendered"),
"body": post.get("content", {}).get("rendered"),
"url": post.get("link"),
"author": post.get("author"),
"categories": post.get("categories"),
"tags": post.get("tags"),
"date": post.get("date"),
}
doc = discoveryengine.Document(
id=str(post["id"]),
json_data=json.dumps(payload),
)
docs.append(doc)
return docs
Identitätsspeicher abrufen oder erstellen
Wenn Sie Nutzeridentitäten und Gruppen für die Zugriffssteuerung verwalten möchten, müssen Sie einen Identitätsspeicher abrufen oder erstellen. Mit dieser Funktion wird ein vorhandener Identitätsspeicher anhand seiner ID, seines Projekts und seines Standorts abgerufen. Wenn der Identitätsspeicher nicht vorhanden ist, wird ein neuer, leerer Identitätsspeicher erstellt und zurückgegeben.
Python
from google.cloud import discoveryengine_v1 as discoveryengine
def get_or_create_ims_data_store(
project_id: str,
location: str,
identity_mapping_store_id: str,
) -> discoveryengine.DataStore:
"""Get or create a DataStore."""
# Initialize the client
client_ims = discoveryengine.IdentityMappingStoreServiceClient()
# Construct the parent resource name
parent_ims = client_ims.location_path(project=project_id, location=location)
try:
# Create the request object
name = f"projects/{project_id}/locations/{location}/identityMappingStores/{identity_mapping_store_id}"
request = discoveryengine.GetIdentityMappingStoreRequest(
name=name,
)
return client_ims.get_identity_mapping_store(request=request)
except:
# Create the IdentityMappingStore object (it can be empty for basic creation)
identity_mapping_store = discoveryengine.IdentityMappingStore()
# Create the request object
request = discoveryengine.CreateIdentityMappingStoreRequest(
parent=parent_ims,
identity_mapping_store=identity_mapping_store,
identity_mapping_store_id=identity_mapping_store_id,
)
return client_ims.create_identity_mapping_store(request=request)
Die Funktion „get_or_create_ims_data_store“ verwendet die folgenden Schlüsselvariablen:
project_id: Die ID Ihres Google Cloud -Projekts.location: Der Speicherort in Google Cloud für den Identitätszuweisungsspeicher.identity_mapping_store_id: Eine eindeutige Kennung für den Identitätsspeicher.client_ims: Eine Instanz von discoveryengine.IdentityMappingStoreServiceClient, die für die Interaktion mit der Identity Store API verwendet wird.parent_ims: Der Ressourcenname des übergeordneten Standorts, der mit „client_ims.location_path“ erstellt wird.name: Der vollständige Ressourcenname des Identitätszuweisungsspeichers, der für GetIdentityMappingStoreRequest verwendet wird.
Identitätszuweisung in Identitätsspeicher aufnehmen
Mit dieser Funktion können Sie Identitätszuweisungseinträge in den angegebenen Identitätsspeicher laden. Sie nimmt eine Liste von Identitätszuweisungseinträgen entgegen und initiiert einen Inline-Importvorgang. Das ist entscheidend, um die Beziehungen zwischen Nutzern, Gruppen und externen Identitäten herzustellen, die für die Zugriffssteuerung und Personalisierung erforderlich sind.
Python
Python
from google.cloud import discoveryengine_v1 as discoveryengine
def load_ims_data(
ims_store: discoveryengine.DataStore,
id_mapping_data: list[discoveryengine.IdentityMappingEntry],
) -> discoveryengine.DataStore:
"""Get the IMS data store."""
# Initialize the client
client_ims = discoveryengine.IdentityMappingStoreServiceClient()
# Create the InlineSource object
inline_source = discoveryengine.ImportIdentityMappingsRequest.InlineSource(
identity_mapping_entries=id_mapping_data
)
# Create the main request object
request_ims = discoveryengine.ImportIdentityMappingsRequest(
identity_mapping_store=ims_store.name,
inline_source=inline_source,
)
try:
# Create the InlineSource object, which holds your list of entries
operation = client_ims.import_identity_mappings(
request=request_ims,
)
result = operation.result()
return result
except Exception as e:
print(f"IMS Load Error: {e}")
return None
Die Funktion „load_ims_data“ verwendet die folgenden Schlüsselvariablen:
ims_store: Das discoveryengine.DataStore-Objekt, das den Identitätszuweisungsspeicher darstellt, in den Daten geladen werden.id_mapping_data: Eine Liste von discoveryengine.IdentityMappingEntry-Objekten, die jeweils eine externe Identität und die entsprechende Nutzer- oder Gruppen-ID enthalten.result: Rückgabewert vom Typ „discoveryengine.DataStore“.
Datenspeicher erstellen
Wenn Sie einen benutzerdefinierten Connector verwenden möchten, müssen Sie einen Datenspeicher für Ihre Inhalte initialisieren. Verwenden Sie default_collection für benutzerdefinierte Connectors. Mit dem Parameter IndustryVertical wird das Verhalten des Datenspeichers für bestimmte Anwendungsfälle angepasst. GENERIC ist für die meisten Szenarien geeignet. Sie können jedoch einen anderen Wert für eine bestimmte Branche auswählen, z. B. MEDIA oder HEALTHCARE_FHIR. Konfigurieren Sie den Anzeigenamen und andere Eigenschaften entsprechend den Namenskonventionen und Anforderungen Ihres Projekts.
Python
from google.cloud import discoveryengine_v1 as discoveryengine
def get_or_create_data_store(
project_id: str,
location: str,
display_name: str,
data_store_id: str,
identity_mapping_store: str,
) -> discoveryengine.DataStore:
"""Get or create a DataStore."""
client = discoveryengine.DataStoreServiceClient()
ds_name = client.data_store_path(project_id, location, data_store_id)
try:
result = client.get_data_store(request={"name": ds_name})
return result
except:
parent = client.collection_path(project_id, location, "default_collection")
operation = client.create_data_store(
request={
"parent": parent,
"data_store": discoveryengine.DataStore(
display_name=display_name,
acl_enabled=True,
industry_vertical=discoveryengine.IndustryVertical.GENERIC,
identity_mapping_store=identity_mapping_store,
),
"data_store_id": data_store_id,
}
)
result = operation.result()
return result
Die Funktion „get_or_create_data_store“ verwendet die folgenden Schlüsselvariablen:
project_id: Die ID Ihres Google Cloud -Projekts.location: Der Google Cloud -Speicherort für den Datenspeicher.display_name: Der für Menschen lesbare Anzeigename des Datenspeichers.data_store_id: Eine eindeutige Kennung für den Datenspeicher.identity_mapping_store: Der Ressourcenname des Identitätszuweisungsspeichers, der gebunden werden soll.result: Rückgabewert vom Typ „discoveryengine.DataStore“.
Dokumente inline hochladen
Wenn Sie Dokumente direkt an Discovery Engine senden möchten, verwenden Sie den Inline-Upload. Bei dieser Methode wird standardmäßig der inkrementelle Abgleichsmodus verwendet. Der vollständige Abgleichsmodus wird nicht unterstützt. Im inkrementellen Modus werden neue Dokumente hinzugefügt und vorhandene Dokumente aktualisiert. Dokumente, die nicht mehr in der Quelle enthalten sind, werden jedoch nicht gelöscht. Im vollständigen Abgleichsmodus wird der Datenspeicher mit Ihren Quelldaten synchronisiert. Dabei werden auch Dokumente gelöscht, die nicht mehr in der Quelle vorhanden sind.
Der inkrementelle Abgleich ist ideal für Systeme wie ein CRM, in denen häufig kleine Änderungen an Daten vorgenommen werden. Anstatt die gesamte Datenbank zu synchronisieren, werden nur bestimmte Änderungen gesendet. Das macht den Prozess schneller und effizienter.
Als Best Practice sollten Sie zuerst eine vollständige Synchronisierung und dann häufigere inkrementelle Synchronisierungen durchführen.
Python
from typing import List
from google.cloud import discoveryengine_v1 as discoveryengine
def upload_documents_inline(
project_id: str,
location: str,
data_store_id: str,
branch_id: str,
documents: List[discoveryengine.Document],
) -> discoveryengine.ImportDocumentsMetadata:
"""Inline import of Document messages."""
client = discoveryengine.DocumentServiceClient()
parent = client.branch_path(
project=project_id,
location=location,
data_store=data_store_id,
branch=branch_id,
)
request = discoveryengine.ImportDocumentsRequest(
parent=parent,
inline_source=discoveryengine.ImportDocumentsRequest.InlineSource(
documents=documents,
),
)
operation = client.import_documents(request=request)
operation.result()
result = operation.metadata
return result
Für die Funktion upload_documents_inline werden die folgenden Schlüsselvariablen verwendet:
project_id: Die ID Ihres Google Cloud -Projekts.location: Der Google Cloud -Speicherort für den Datenspeicher.data_store_id: Die ID des Datenspeichers.branch_id: Die ID des Zweigs im Datenspeicher (in der Regel „0“).documents: Eine Liste der hochzuladenden discoveryengine.Document-Objekte.result: Rückgabewert vom Typ „discoveryengine.ImportDocumentsMetadata“.
Das Feld uri im Objekt discoveryengine.Document verweist auf die Contentquelle der aufgenommenen Inhalte, entweder als Rohbytes oder als URI in Google Cloud Storage. Dies unterscheidet sich vom URI der Inhalte der Drittanbieterquelle. Der URI der Inhalte der Drittanbieterquelle sollte als Feld in der json_data-Nutzlast des Dokuments definiert werden. In der Funktion convert_posts_to_documents dient beispielsweise das Feld url in der Nutzlast diesem Zweck.
Connector validieren
Führen Sie einen Testlauf durch, um zu prüfen, ob Ihr Connector wie erwartet funktioniert und die Daten ordnungsgemäß von der Quelle zu Discovery Engine übertragen werden.
Python
from google.cloud import discoveryengine_v1 as discoveryengine
from google.api_core import exceptions as gcp_exceptions
SITE = "https://altostrat.com"
PROJECT_ID = "ucs-3p-connectors-testing"
LOCATION = "global"
IDENTITY_MAPPING_STORE_ID = "your-unique-ims-id17" # A unique ID for your new store
DATA_STORE_ID = "my-acl-ds-id1"
BRANCH_ID = "0"
posts = fetch_posts(SITE)
docs = convert_posts_to_documents(posts)
print(f"Fetched {len(posts)} posts and converted to {len(docs)} documents.")
try:
# Step #1: Retrieve an existing identity mapping store or create a new identity mapping store
ims_store = get_or_create_ims_data_store(PROJECT_ID, LOCATION, IDENTITY_MAPPING_STORE_ID)
print(f"STEP #1: IMS Store Retrieval/Creation: {ims_store}")
RAW_IDENTITY_MAPPING_DATA = [
discoveryengine.IdentityMappingEntry(
external_identity="external_id_1",
user_id="testuser1@example.com",
),
discoveryengine.IdentityMappingEntry(
external_identity="external_id_2",
user_id="testuser2@example.com",
),
discoveryengine.IdentityMappingEntry(
external_identity="external_id_2",
group_id="testgroup1@example.com",
)
]
# Step #2: Load IMS Data
response = load_ims_data(ims_store, RAW_IDENTITY_MAPPING_DATA)
print(
"\nStep #2: Load Data in IMS Store successful.", response
)
# Step #3: Create Entity Data Store & Bind IMS Data Store
data_store = get_or_create_data_store(PROJECT_ID, LOCATION, "my-acl-datastore", DATA_STORE_ID, ims_store.name)
print("\nStep #3: Entity Data Store Create Result: ", data_store)
metadata = upload_documents_inline(
PROJECT_ID, LOCATION, DATA_STORE_ID, BRANCH_ID, docs
)
print(f"Uploaded {metadata.success_count} documents inline.")
except gcp_exceptions.GoogleAPICallError as e:
print(f"\n--- API Call Failed ---")
print(f"Server Error Message: {e.message}")
print(f"Status Code: {e.code}")
except Exception as e:
print(f"An error occurred: {e}")
Prüfen Sie, ob in Ihrem Connector-Code die folgenden Schlüsselvariablen verwendet werden:
SITE: Die Basis-URL der Drittanbieterdatenquelle.PROJECT_ID: Ihre Google Cloud Projekt-IDLOCATION: Der Google Cloud -Standort der Ressourcen.IDENTITY_MAPPING_STORE_ID: Eine eindeutige ID für Ihren Identitätszuweisungsspeicher.DATA_STORE_ID: Eine eindeutige ID für Ihren Datenspeicher.BRANCH_ID: Die ID des Zweigs im Datenspeicher.posts: Speichert die abgerufenen Beiträge aus der Drittanbieterquelle.docs: Speichert die konvertierten Dokumente im Format „discoveryengine.Document“.ims_store: Das abgerufene oder erstellte discoveryengine.DataStore-Objekt für die Identitätszuweisung.RAW_IDENTITY_MAPPING_DATA: Eine Liste von discoveryengine.IdentityMappingEntry-Objekten.
Erwartete Ausgabe:
Shell
Fetched 20 posts and converted to 20 documents.
STEP #1: IMS Store Retrieval/Creation: "projects/ <Project Number>/locations/global/identityMappingStores/your-unique-ims-id17"
Step #2: Load Data in IMS Store successful.
Step #3: Entity Data Store Create Result: "projects/ <Project Number>/locations/global/collections/default_collection/dataStores/my-acl-ds-id1"
display_name: "my-acl-datastore"
industry_vertical: GENERIC
create_time {
seconds: 1760906997
nanos: 192641000
}
default_schema_id: "default_schema"
acl_enabled: true
identity_mapping_store: "projects/ <Project Number>/locations/global/identityMappingStores/your-unique-ims-id17".
Uploaded 20 documents inline.
Sie können Ihren Datenspeicher jetzt auch in der Google Google Cloud Console sehen:
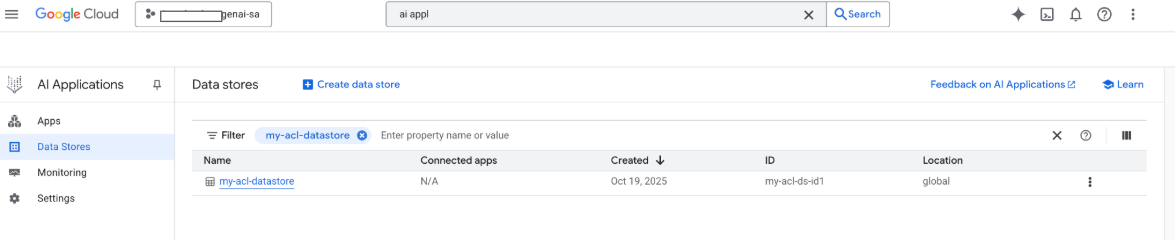
Wenn eine Suche durchgeführt wird, werden Felder aus der Nutzlast für die Suche verwendet und das URI-Feld der Nutzlast für Zitate. Die drei wichtigsten Eigenschaftsfelder, die von Gemini Enterprise identifiziert werden, sind title, description und uri. Die entsprechenden Dokumentfelder können unterschiedliche Namen haben. Die Zuordnung kann über die Option „Schema“ > „Bearbeiten“ in der Google Cloud Console erfolgen.
Connector mit Google Cloud Storage-Upload erstellen
Der Inline-Import eignet sich zwar gut für die Entwicklung, für Produktionsconnectors sollte jedoch Google Cloud Storage verwendet werden, um eine bessere Skalierbarkeit zu erzielen und den vollständigen Abgleichsmodus zu aktivieren. Mit diesem Ansatz lassen sich große Datasets effizient verarbeiten. Außerdem wird das automatische Löschen von Dokumenten unterstützt, die nicht mehr in der Datenquelle von Drittanbietern vorhanden sind.
Dokumente in JSONL konvertieren
Wenn Sie Dokumente für den Bulk-Import in Discovery Engine vorbereiten möchten, konvertieren Sie sie in das JSON Lines-Format.
Python
from typing import List
from google.cloud import discoveryengine_v1 as discoveryengine
def convert_documents_to_jsonl(
documents: List[discoveryengine.Document],
) -> str:
"""Serialize Document messages to JSONL."""
return "\n".join(
discoveryengine.Document.to_json(doc, indent=None)
for doc in documents
) + "\n"
Die Funktion „convert_documents_to_jsonl“ verwendet die folgende Variable:
documents: Eine Liste der discoveryengine.Document-Objekte, die konvertiert werden sollen.
In Google Cloud Storage hochladen
Damit ein effizienter Bulk-Import möglich ist, müssen Sie Ihre Daten in Google Cloud Storage bereitstellen.
Python
from google.cloud import storage
def upload_jsonl_to_gcs(jsonl: str, bucket_name: str, blob_name: str) -> str:
"""Upload JSONL content to Google Cloud Storage."""
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
blob.upload_from_string(jsonl, content_type="application/json")
return f"gs://{bucket_name}/{blob_name}"
Die Funktion „upload_jsonl_to_gcs“ verwendet die folgenden Schlüsselvariablen:
jsonl: Der hochzuladende String-Inhalt im JSONL-Format.bucket_name: Der Name des Google Cloud Storage-Buckets.blob_name: Der Name des Blobs (Objekts) im angegebenen Bucket.
Aus Google Cloud Storage mit vollständigem Abgleich importieren
Verwenden Sie diese Methode, um eine vollständige Datensynchronisierung im Modus „Vollständiger Abgleich“ durchzuführen. So wird sichergestellt, dass Ihr Datenspeicher die Drittanbieter-Datenquelle genau widerspiegelt. Alle Dokumente, die nicht mehr vorhanden sind, werden automatisch entfernt.
Beachten Sie beim Importieren aus Google Cloud Storage die folgenden Einschränkungen:
- Eine einzelne Importanfrage kann maximal 100 Dateien enthalten oder 100.000 Dateien, wenn der Parameter
dataSchemaaufcontentgesetzt ist. Jede Datei darf maximal 2 GB groß sein oder 100 MB, wenn der Parameter
dataSchemaaufcontentgesetzt ist.
Python
from google.cloud import discoveryengine_v1 as discoveryengine
def import_documents_from_gcs(
project_id: str,
location: str,
data_store_id: str,
branch_id: str,
gcs_uri: str,
) -> discoveryengine.ImportDocumentsMetadata:
"""Bulk-import documents from Google Cloud Storage with FULL reconciliation mode."""
client = discoveryengine.DocumentServiceClient()
parent = client.branch_path(
project=project_id,
location=location,
data_store=data_store_id,
branch=branch_id,
)
gcs_source = discoveryengine.GcsSource(input_uris=[gcs_uri])
request = discoveryengine.ImportDocumentsRequest(
parent=parent,
gcs_source=gcs_source,
reconciliation_mode=
discoveryengine.ImportDocumentsRequest
.ReconciliationMode.FULL,
)
operation = client.import_documents(request=request)
operation.result()
return operation.metadata
Die Funktion „import_documents_from_gcs“ verwendet die folgenden Schlüsselvariablen:
project_id: Die ID Ihres Google Cloud -Projekts.location: Der Google Cloud -Speicherort für den Datenspeicher.data_store_id: Die ID des Datenspeichers.branch_id: Die ID des Zweigs im Datenspeicher (in der Regel „0“).gcs_uri: Der Google Cloud Storage-URI, der auf die JSONL-Datei verweist.
Google Cloud Storage-Upload testen
Führen Sie Folgendes aus, um den auf Google Cloud Storage basierenden Importworkflow zu prüfen:
Python
BUCKET = "your-existing-bucket"
BLOB = "path-to-any-blob/wp/posts.jsonl"
SITE = "https://altostrat.com"
PROJECT_ID = "ucs-3p-connectors-testing"
LOCATION = "global"
IDENTITY_MAPPING_STORE_ID = "your-unique-ims-id17" # A unique ID for your new store
DATA_STORE_ID = "your-data-store-id"
BRANCH_ID = "0"
posts = fetch_posts(SITE)
docs = convert_posts_to_documents(posts)
print(f"Fetched {len(posts)} posts and converted to {len(docs)} documents.")
jsonl_payload = convert_documents_to_jsonl(docs)
gcs_uri = upload_jsonl_to_gcs(jsonl_payload, BUCKET, BLOB)
print("Uploaded to:", gcs_uri)
metadata = import_documents_from_gcs(
PROJECT_ID, LOCATION, DATA_STORE_ID, BRANCH_ID, gcs_uri
)
print(f"Imported: {metadata.success_count} documents")
Die folgenden Schlüsselvariablen werden beim Testen des Google Cloud Storage-Uploads verwendet:
BUCKET: Der Name des Google Cloud Storage-Buckets.BLOB: Der Pfad zum Blob im Bucket.SITE: Die Basis-URL der Drittanbieterdatenquelle.PROJECT_ID: Ihre Google Cloud Projekt-IDLOCATION: Der Google Cloud Standort der Ressourcen (z.B. „global“).IDENTITY_MAPPING_STORE_ID: Eine eindeutige ID für Ihren Identitätszuweisungsspeicher.DATA_STORE_ID: Eine eindeutige ID für Ihren Datenspeicher.BRANCH_ID: Die ID des Zweigs im Datenspeicher (in der Regel „0“).jsonl_payload: Die in das JSONL-Format konvertierten Dokumente.gcs_uri: Der Google Cloud Storage-URI der hochgeladenen JSONL-Datei.
Erwartete Ausgabe:
Shell
Fetched 20 posts and converted to 20 documents.
Uploaded to: gs://alex-de-bucket/wp/posts.jsonl
Imported: 20 documents
Berechtigungen verwalten
Zur Verwaltung des Zugriffs auf Dokumentebene in Unternehmensumgebungen unterstützt Gemini Enterprise Zugriffssteuerungslisten (Access Control Lists, ACLs) und die Identitätszuweisung. So lässt sich einschränken, welche Inhalte Nutzer sehen können.
ACLs im Datenspeicher aktivieren
Führen Sie Folgendes aus, um ACLs beim Erstellen des Datenspeichers zu aktivieren:
Python
# get_or_create_data_store()
"data_store": discoveryengine.DataStore(
display_name=data_store_id,
industry_vertical=discoveryengine.IndustryVertical.GENERIC,
acl_enabled=True, # ADDED
)
ACLs zu Dokumenten hinzufügen
Führen Sie Folgendes aus, um AclInfo beim Transformieren der Dokumente zu berechnen und einzufügen:
Python
# convert_posts_to_documents()
doc = discoveryengine.Document(
id=str(post["id"]),
json_data=json.dumps(payload),
acl_info=discoveryengine.Document.AclInfo(
readers=[{
"principals": [
{"user_id": "baklavainthebalkans@gmail.com"},
{"user_id": "cloudysanfrancisco@gmail.com"}
]
}]
),
)
Inhalte öffentlich machen
Wenn Sie ein Dokument öffentlich zugänglich machen möchten, legen Sie das Feld readers so fest:
Python
readers=[{"idp_wide": True}]
ACLs validieren
So prüfen Sie, ob Ihre ACL-Konfigurationen wie erwartet funktionieren:
Suchen Sie als Nutzer, der keinen Zugriff auf das Dokument hat.
Prüfen Sie die Struktur des hochgeladenen Dokuments in Cloud Storage und vergleichen Sie sie mit einer Referenz.
JSON
{
"id": "108",
"jsonData": "{...}",
"aclInfo": {
"readers": [
{
"principals": [
{ "userId": "baklavainthebalkans@gmail.com" },
{ "userId": "cloudysanfrancisco@gmail.com" }
],
"idpWide": false
}
]
}
}
Identitätszuweisung verwenden
Verwenden Sie die Identitätszuweisung in den folgenden Fällen:
Ihre Drittanbieter-Datenquelle verwendet Identitäten, die nicht von Google stammen.
Sie möchten auf benutzerdefinierte Gruppen (z. B. „wp-admins“) anstatt auf einzelne Nutzer verweisen.
Ihre API gibt nur Gruppennamen zurück.
Sie müssen Nutzer manuell gruppieren, um die Skalierung oder Konsistenz zu verbessern.
Ihr Drittanbietersystem implementiert ACLs mit Gruppen, die nicht auf IDPs basieren, und Sie möchten diese ACLs mit dem benutzerdefinierten Datenspeicher in Gemini Enterprise berücksichtigen.
So weisen Sie Identitäten zu:
- Erstellen Sie den Identitätsdatenspeicher und verknüpfen Sie ihn.
Importieren Sie externe Identitäten (z. B.
external_group:wp-admins). Geben Sie beim Importieren nicht dasexternal_group: prefixan, z. B.:JSON
{ "externalIdentity": "wp-admins", "userId": "user@example.com" }Definieren Sie in den ACL-Informationen Ihres Dokuments die externe Entitäts-ID in der
principal identifier. Wenn Sie auf benutzerdefinierte Gruppen verweisen, verwenden Sie das Präfixexternal_group:im FeldgroupId.Das Präfix
external_group:ist für Gruppen-IDs in den ACL-Informationen des Dokuments während des Imports erforderlich, wird aber nicht verwendet, wenn Identitäten in den Zuweisungsspeicher importiert werden. Beispieldokument mit Identitätszuweisung:JSON
{ "id": "108", "aclInfo": { "readers": [ { "principals": [ { "userId": "cloudysanfrancisco@gmail.com" }, { "groupId": "external_group:wp-admins" } ] } ] }, "structData": { "id": 108, "date": "2025-04-24T18:16:04", ... } }
Nächste Schritte
- Wenn Sie eine Benutzeroberfläche für das Abfragen Ihrer Daten bereitstellen möchten, erstellen Sie eine Anwendung in Gemini Enterprise und verbinden Sie sie mit dem vorhandenen Datenspeicher für benutzerdefinierte Connectors.