

Los conectores obtienen datos de Google y de fuentes de datos externas en Gemini Enterprise, y los almacenan en almacenes de datos dedicados. En este documento, se proporciona una descripción general de estos conectores. Centralizar tus datos en Gemini Enterprise mejora la accesibilidad a los datos, la funcionalidad de búsqueda y las capacidades de análisis.
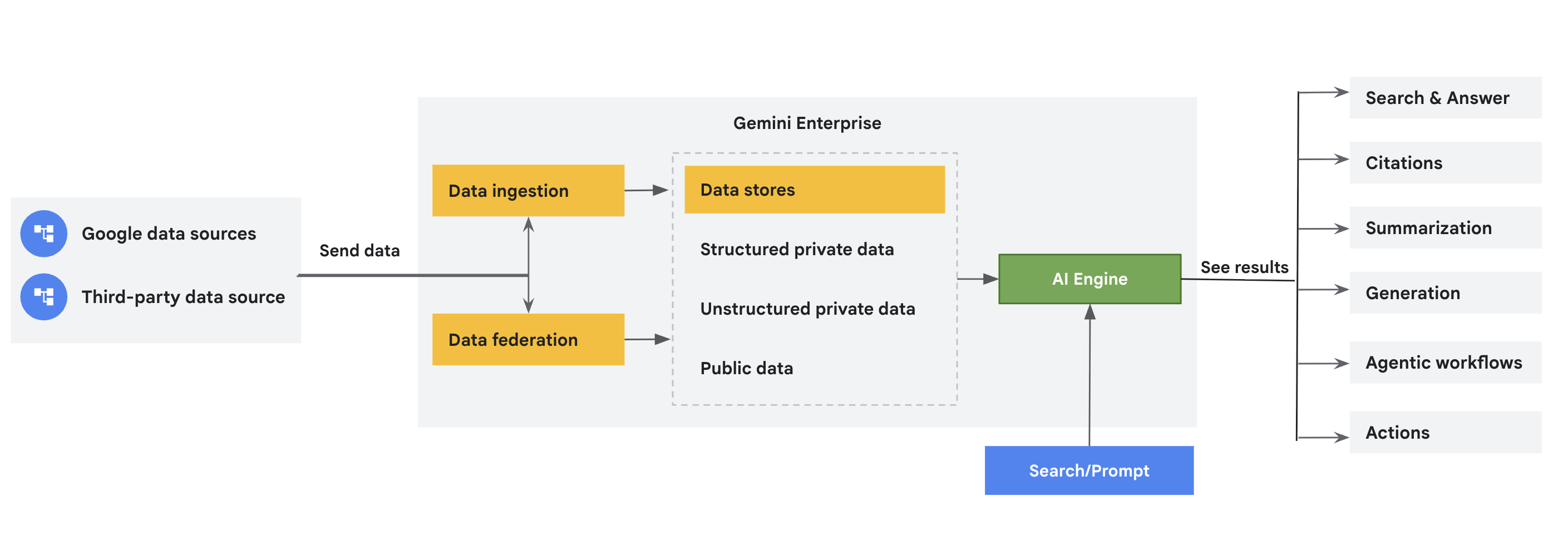
Conceptos de conectores y almacén de datos
Almacenes de datos |
| Cada fuente de datos admite un conjunto de tipos de entidades. Por ejemplo, Jira Cloud tiene entidades como problemas, archivos adjuntos, comentarios y registros de trabajo, que son exclusivos de la fuente de datos. Gemini Enterprise crea un almacén de datos independiente para cada entidad. Por lo tanto, cuando creas un almacén de datos con la consola de Google Cloud , obtienes una colección de almacenes de datos que representan estas entidades de datos ingeridas. |
Federación de datos versus transferencia (indexación) |
| La federación de datos recupera información directamente de la fuente de datos especificada. Como los datos no se copian en el índice de Vertex AI Search, no tienes que preocuparte por el almacenamiento de datos. Sin embargo, debido a que los datos no se indexan, la calidad de la búsqueda puede ser menor. La transferencia de datos (indexación) copia los datos en el índice de Vertex AI Search. Esto puede mejorar la calidad de la búsqueda. Sin embargo, este proceso consume más almacenamiento y tiempo. Si el conector admite la federación y la transferencia de datos, selecciona tu método de conexión de datos preferido. |
Datos no estructurados |
| El formato de datos admitido es específico de la fuente de datos y el tipo de entidad. Si el contenido de una entidad se almacena en un formato no estructurado, como PDF, HTML, DOCX, PPTX, XLSX y XLSM, Vertex AI Search crea un almacén de datos no estructurados. Para obtener más información y conocer los tipos de archivos compatibles, consulta Búsqueda no estructurada. |
Datos estructurados |
| El formato de datos admitido es específico de la fuente de datos y el tipo de entidad. Si el contenido de una entidad se almacena en un formato estructurado, Vertex AI Search crea un almacén de datos estructurados. Para obtener más información, consulta Búsqueda estructurada. |
Esquemas de datos |
| El esquema de datos define la estructura de los datos. Cuando importas datos estructurados con Gemini Enterprise, el sistema detecta automáticamente el esquema. Puedes usar el esquema detectado automáticamente o definirlo con la API. Para obtener más información, consulta Cómo proporcionar o detectar automáticamente un esquema. |
Regiones del almacén de datos |
| Cuando transfieras datos, deberás seleccionar la región en la que deseas almacenarlos, como global, EE.UU. o la UE. Para obtener más información, consulta Compromisos de residencia de datos y procesamiento regional de AA. Los datos almacenados en las regiones de EE.UU. o la UE requieren encriptación. La encriptación predeterminada se realiza con Google-owned and Google-managed encryption keys, pero, como alternativa, puedes usar claves de encriptación administradas por el cliente. |
Sincronizaciones de datos |
Una sincronización de datos extrae y actualiza los datos de identidad (como roles, permisos y usuarios) y los datos de entidades (como los datos relacionados con una fuente de datos específica) de la fuente de datos original. Para obtener más información, consulta Tipos y programas de sincronización de datos. |
Tipos y programas de sincronización de datos
Una sincronización de datos captura datos de entidades, datos de identidad o ambos, y actualiza el contenido del almacén de datos en Gemini Enterprise.
Tipos de sincronización
Los almacenes de datos de Gemini Enterprise usan dos tipos esenciales de sincronización de datos:
Una sincronización completa capta todo el estado de la app o el servicio de terceros. Esto incluye adiciones, actualizaciones y eliminaciones. Una sincronización completa reemplaza el contenido existente del almacén de datos.
Una sincronización incremental captura periódicamente los datos de entidades que se agregaron o actualizaron desde la última sincronización. No sincroniza los datos de identidad ni las eliminaciones de datos de entidades.
Puedes programar una sincronización completa por separado para los siguientes tipos de datos:
Una sincronización de entidades captura datos específicos de la fuente de datos externa. Por ejemplo, un almacén de datos para un sistema como Jira puede sincronizar problemas, registros de trabajo, comentarios y archivos adjuntos. Las sincronizaciones de entidades no incluyen información de identidad.
Una sincronización de identidad captura datos sobre las cuentas de usuario asociadas con un grupo de LCA.
Interacción entre la sincronización de identidades y la sincronización completa
Para comprender cómo funciona una ejecución de sincronización de identidades individual con una ejecución de sincronización completa, considera un ejemplo que incluye dos páginas: page_1, vinculada a un grupo de LCA group_1, y page_2, vinculada a un grupo de LCA group_2.
Se ejecuta una sincronización inicial de identidades y se recupera información sobre los grupos
group_1ygroup_2.Supón que
group_1contiene al usuariouser_1.Supón que
group_2contiene al usuariouser_2.
Esta sincronización de identidades establece la siguiente asignación:
user_1se asigna agroup_1.user_2se asigna agroup_2.
Junto con la sincronización de identidades, se ejecuta una sincronización completa que recupera
page_1ypage_2.Esta sincronización completa establece la siguiente asignación:
user_1tiene acceso apage_1(a través degroup_1).user_2tiene acceso apage_2(a través degroup_2).
Programas de sincronización
Para cada almacén de datos, puedes seleccionar una frecuencia para los diferentes tipos de sincronización:
Las sincronizaciones completas de todos los datos de identidad y de entidad se pueden programar de forma simultánea cada 3, 6, 12 horas, 1 día o 3 días.
Las sincronizaciones completas independientes de todos los datos de identidad y de todos los datos de entidad se pueden programar por separado con cualquiera de las siguientes frecuencias de sincronización personalizadas:
Datos de entidades: Cada 3, 6, 12 horas, 1, 3, 5 y 7 días
Datos de identidad: Cada 30 minutos, 1 hora, 3 horas, 6 horas, 12 horas, 1 día, 3 días, 5 días y cada 7 días
Las sincronizaciones incrementales de los datos de entidades actualizados o agregados se pueden programar cada 3, 6, 12, 24, 72, 120 o 168 horas. De forma predeterminada, se realiza una sincronización incremental cada 3 horas.
Recomendaciones de frecuencia
Elige una frecuencia de sincronización de datos que se alinee con la cantidad de registros recuperados y las consultas por segundo (QPS) recomendadas.
En la siguiente tabla, se muestra la cantidad típica de registros recuperados para las sincronizaciones de uno, tres, cinco y siete días. La cantidad real de registros puede variar según la fuente de datos y su configuración.
| QPS | Volumen de registros para la sincronización de 1 día | Volumen de registros para la sincronización de 3 días | Volumen de registros para la sincronización de 5 días | Volumen de registros para la sincronización de 7 días |
|---|---|---|---|---|
| 5 | 432,000 | 1.296M | 2.16 millones | 3 millones |
| 10 | 864 000 | 2.592M | 4.32 M | 6 millones |
| 20 | 1.7 millones | 5.1 M | 8.5 M | 11.9 M |
| 50 | 4.3 M | 12.9 M | 21.5 millones | 30.1M |
| 100 | 8.6 M | 25.8 M | 43 M | 60.2 millones |
Cómo pausar y reanudar la sincronización
Puedes pausar y reanudar tanto las sincronizaciones completas como las incrementales:
Cuando pausas un tipo de sincronización, el almacén de datos cancela las sincronizaciones en curso de ese tipo y deja de programar nuevas sincronizaciones de ese tipo.
Cuando reanudas un tipo de sincronización, el almacén de datos programa la nueva sincronización según la última hora de sincronización programada, pero no continúa con la sincronización interrumpida anteriormente.
Por ejemplo, si pausas la sincronización completa mientras se está realizando, el almacén de datos la cancelará. Si más adelante reanudas la sincronización completa, el almacén de datos programará automáticamente una nueva sincronización completa según el programa de sincronización completa.
Fuentes de datos de Google
Puedes conectarte a fuentes de datos de Google, como BigQuery, Spanner y Google Drive.
Lista de tareas para las fuentes de datos de Google
Antes de enviar datos a Gemini Enterprise, revisa la siguiente lista de tareas:
Configura el control de acceso para tu fuente de datos. Para obtener más información, consulta Identidad y permisos.
Decide si los datos deben ser federados o ingeridos (indexados).
Decide con qué frecuencia se deben sincronizar los datos.
Si usas claves de encriptación administradas por el cliente (CMEK), crea claves multirregionales. Para obtener más información, consulta Cómo registrar claves de una sola región para fuentes de datos de terceros.
Si tienes información de identificación personal (PII) y planeas usar la función de autocompletar para sugerencias de búsqueda, consulta cómo protegerte contra las filtraciones de PII.
Fuentes de datos de Google compatibles
| Google Drive | Gmail | Calendario de Google | Búsqueda de personas |

|

|

|

|
Fuentes de datos de terceros
Los almacenes de datos de terceros transfieren datos de aplicaciones de terceros a Gemini Enterprise.
Lista de verificación para fuentes de datos de terceros
Antes de conectar una fuente de datos de terceros a Gemini Enterprise, consulta la siguiente lista de verificación:
Se deben configurar permisos y alcances específicos para ciertas fuentes de datos. Un administrador de la aplicación de terceros debe revisar las credenciales necesarias para conectar una fuente de datos y configurar la autenticación y los permisos. Para obtener información sobre los permisos y los alcances específicos, consulta la documentación de la fuente de datos externa correspondiente.
Configura el control de acceso para tu almacén de datos. Para obtener más información, consulta Identidad y permisos.
Decide si los datos deben ser federados o ingeridos (indexados).
Si se transfieren datos, asegúrate de que los recursos no estén restringidos para la credencial de usuario que usas para transferir datos a la fuente de datos.
Decide con qué frecuencia se deben sincronizar los datos.
Si usas claves de encriptación administradas por el cliente (CMEK), crea claves de una sola región y de varias regiones. Para obtener más información, consulta Cómo registrar claves de una sola región para almacenes de datos de terceros.
Si tienes información de identificación personal (PII) y planeas usar la función de autocompletar para sugerencias de búsqueda, consulta cómo protegerte contra las filtraciones de PII.
Fuentes de datos de terceros compatibles
| Microsoft Entra ID | Microsoft OneDrive | Microsoft Outlook | Microsoft SharePoint |
|
|
|
|
|
| Jira Cloud | Confluence Cloud | ServiceNow | |
|
|
|
|