
Présentation du connecteur BigQuery
Le connecteur BigQuery vous permet d'exporter les métadonnées du document (y compris les propriétés) stockées dans Document AI Warehouse vers votre table BigQuery. Une fois vos données dans BigQuery, vous pouvez les analyser, créer des rapports et des tableaux de bord pour vous aider à prendre des décisions commerciales.
Pour activer le connecteur BigQuery, vous devez configurer une table BigQuery avec les autorisations nécessaires et configurer les tâches asynchrones via l'API. Le connecteur BigQuery exporte les données de Document AI Warehouse vers vos tables BigQuery.
Avant de commencer
Configurez Document AI Warehouse et ingérez vos documents. Pour en savoir plus, suivez le guide de démarrage rapide.
Vous devez vous assurer que le projet qui héberge votre table BigQuery est le même que celui utilisé par Document AI Warehouse pour stocker vos documents. En d'autres termes, les données doivent toujours être exportées de Document AI Warehouse vers la table BigQuery du même projet.
Dans le projet, vous devez disposer du rôle Owner (roles/owner) ou des rôles resourcemanager.projects.getIamPolicy et resourcemanager.projects.setIamPolicy.
des autorisations supplémentaires.
Configurer BigQuery Access
Associez le compte de service doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
au rôle BigQuery Admin :
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
Configurer un ensemble de données et une table BigQuery
Configurez un ensemble de données et une table BigQuery pour que Document AI Warehouse puisse exporter les données. Si vous n'avez pas d'ensemble de données BigQuery, suivez la procédure de création d'ensembles de données.
Créez une table BigQuery dans votre ensemble de données BigQuery. En suivant les instructions BigQuery, vous créez des tables avec les exemples d'instructions LDD :
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
Le DDL crée une table BigQuery pour vous. La table est partitionnée par heure et la partition est supprimée au bout de 150 jours.
Configurer le connecteur BigQuery
Créer une configuration d'exportation de données
Les instructions suivantes permettent de créer un job d'exportation de données, qui configure les jobs asynchrones pour exporter les données. Nous vous recommandons de commencer par une table vide pour chaque nouveau job d'exportation de données. Pour en savoir plus sur la configuration, consultez la documentation de référence de l'API.
Vous disposez des options d'exécution suivantes. Ils peuvent être configurés à l'aide de FREQUENCY.
Consultez la documentation de référence de l'API.
- ADHOC : le job ne s'exécute qu'une seule fois. Toutes les données sont exportées vers votre table BigQuery.
- DAILY (QUOTIDIEN) : la tâche est exécutée quotidiennement. Lors de la première exécution, toutes les données sont exportées vers votre table BigQuery. Une fois l'exportation initiale terminée, seules les modifications apportées aux données de la veille (ou le delta par rapport à la dernière synchronisation réussie) sont exportées vers votre table BigQuery.
- HOURLY (Toutes les heures) : la tâche s'exécute toutes les heures. Lors de la première exécution, toutes les données sont exportées vers votre table BigQuery. Une fois l'exportation initiale terminée, seules les modifications apportées aux données de l'heure précédente (ou le delta par rapport à la dernière synchronisation réussie) sont exportées vers votre table BigQuery.
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- PROJECT_NUMBER : numéro de votre projet Google Cloud
- LOCATION : emplacement de votre Document AI Warehouse (par exemple, "us")
- DATASET_LOCATION : emplacement de votre ensemble de données
- DATASET_NAME : nom de votre ensemble de données
- TABLE_NAME : nom de votre table
-
FREQUENCY :
ADHOC,DAILYouHOURLY.
Corps JSON de la requête :
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
Exécution du job
Une fois que vous avez créé un job, il s'exécute en fonction de votre configuration. Notez que les tâches s'exécutent de manière asynchrone, car leur exécution prend du temps. Selon la quantité de données à exporter, la première exécution peut prendre du temps. Pour les tâches quotidiennes, prévoyez un délai de 24 heures pour que les résultats s'affichent dans la table BigQuery.
Supprimer la configuration d'exportation de données
La commande suivante supprime (en archivant) une tâche que vous avez créée.
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- PROJECT_NUMBER : numéro de votre projet Google Cloud
- LOCATION : emplacement de votre Document AI Warehouse (par exemple, "us")
- JOB_ID : ID de votre job, dans la réponse obtenue lors de sa création
Corps JSON de la requête :
{}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
Une fois cette opération effectuée, votre tâche d'exportation est supprimée (archivée) et Document AI Warehouse ne l'exécute plus.
Explorer les données ingérées dans BigQuery
Pour extraire les métadonnées et les propriétés des documents dans des champs de table distincts dans BigQuery afin de répondre à vos besoins d'analyse, vous pouvez utiliser les exemples de requêtes LDD ci-dessous. Ces champs extraits peuvent également être utilisés dans Data Studio ou tout autre outil de tableau de bord BI pour visualiser les relations dans les données.
Extraire les champs clés de document_json
Cette requête sélectionne les champs pertinents de l'exportation de données, y compris les champs clés des métadonnées du document (stockés dans le champ document_json).
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
Désimbriquer les propriétés de document_json
Cette requête annule l'imbrication des propriétés des métadonnées du document (document_json) pour créer des paires clé-valeur (nom de propriété, valeur). Ces paires clé-valeur seront transformées en champs de tableau individuels dans la prochaine requête pour permettre l'exploration des données au niveau de la propriété et la visualisation des tableaux de bord.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
Pivoter les propriétés de document_json pour créer des champs de table dans BigQuery
Les procédures suivantes créent une table avec toutes les propriétés du document transformées en champs de table individuels en pivotant les propriétés et les valeurs associées. Les résultats de ce tableau peuvent être utilisés pour obtenir des insights supplémentaires grâce à des requêtes ultérieures dans Data Studio et dans d'autres outils de visualisation de l'informatique décisionnelle.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
Procédures de nettoyage et de transformation des données (spécifiques au cas d'utilisation)
Selon les données ingérées dans BigQuery, vous devrez peut-être effectuer des procédures supplémentaires de nettoyage et de transformation des données pour permettre une analyse plus approfondie. Ces procédures varient d'un cas à l'autre (d'un ensemble de données à l'autre) et doivent être effectuées le cas échéant.
Voici quelques exemples de procédures de nettoyage des données (liste non exhaustive) :
- Unification des formats de date.
- Consolidation des valeurs de propriété.
- Par exemple, caster des types de données en chaînes, en nombres à virgule flottante et en nombres entiers.
Visualiser les données dans Data Studio
Une fois vos données extraites, nettoyées et transformées dans BigQuery, votre ensemble de données final peut être exporté vers Data Studio pour une analyse visuelle.
Tableaux de bord Looker
Les exemples de tableaux de bord présentés illustrent les visualisations qui peuvent être créées à partir de votre ensemble de données. Dans ce scénario, l'exemple d'exportation de données depuis Document AI Warehouse se compose de formulaires W2 et de factures (deux schémas).
Tableaux de bord Looker publics
Exemple de vue : aperçu des données analytiques de Document AI Warehouse
Le tableau de bord suivant vous donne une vue d'ensemble de la variété des documents ingérés dans votre instance Document AI Warehouse.
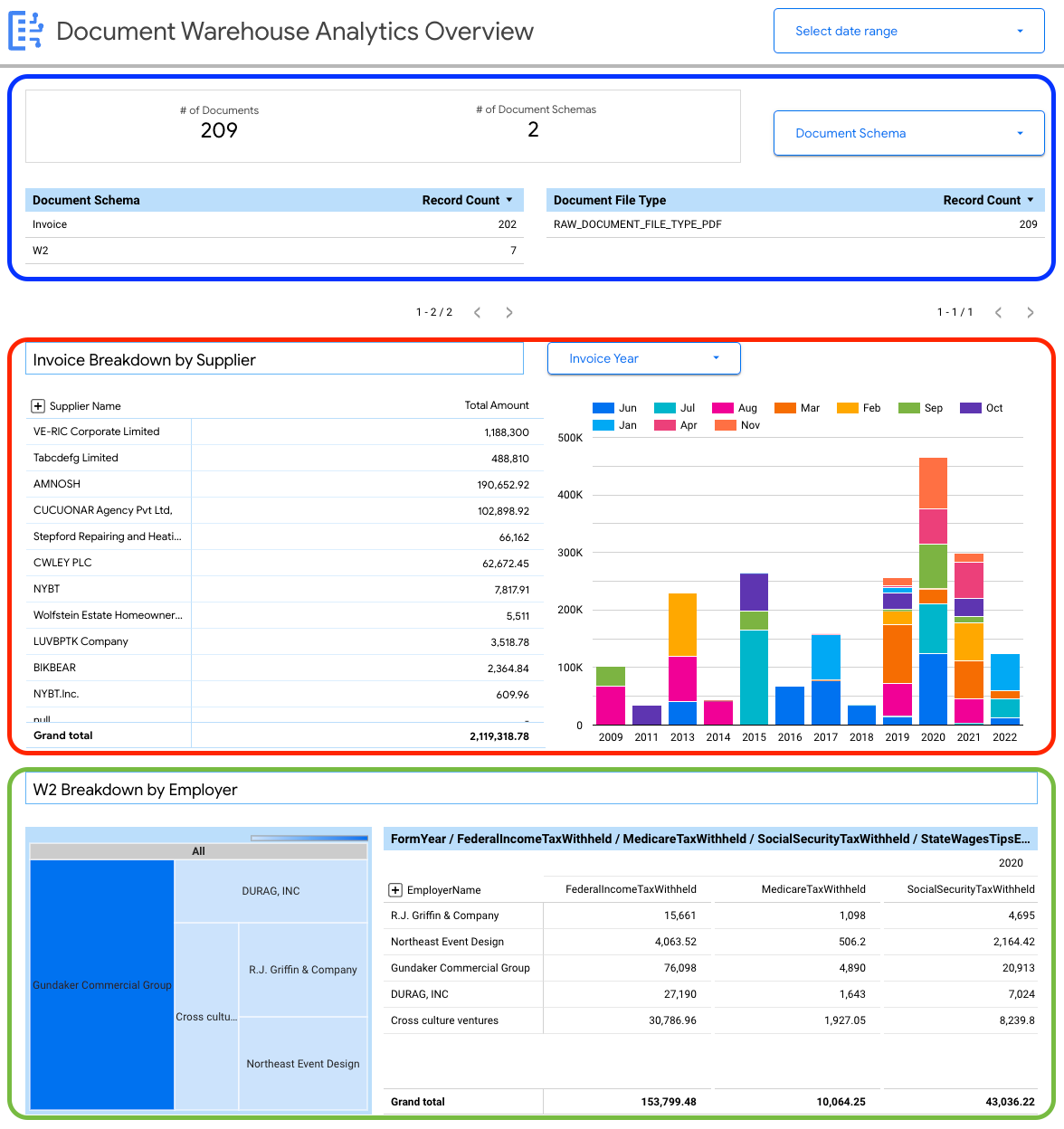
Vous pouvez afficher des informations au niveau du document, y compris :
- Nombre total de documents.
- Nombre total de schémas de document.
- Nombre d'enregistrements par schéma de document.
- Type de fichier du document (PDF, texte, type non spécifié, etc.).
Vous pouvez également utiliser les propriétés extraites des métadonnées du document (document_json) pour créer des répartitions clés pour les factures et les formulaires W-2 ingérés dans BigQuery.
Exemple de vue : tableau de bord des insights spécifiques à l'entreprise (factures)
Le tableau de bord suivant fournit à l'utilisateur une vue détaillée d'un seul schéma de document (factures) pour lui permettre d'obtenir des insights sur toutes les factures ingérées dans Document AI Warehouse.
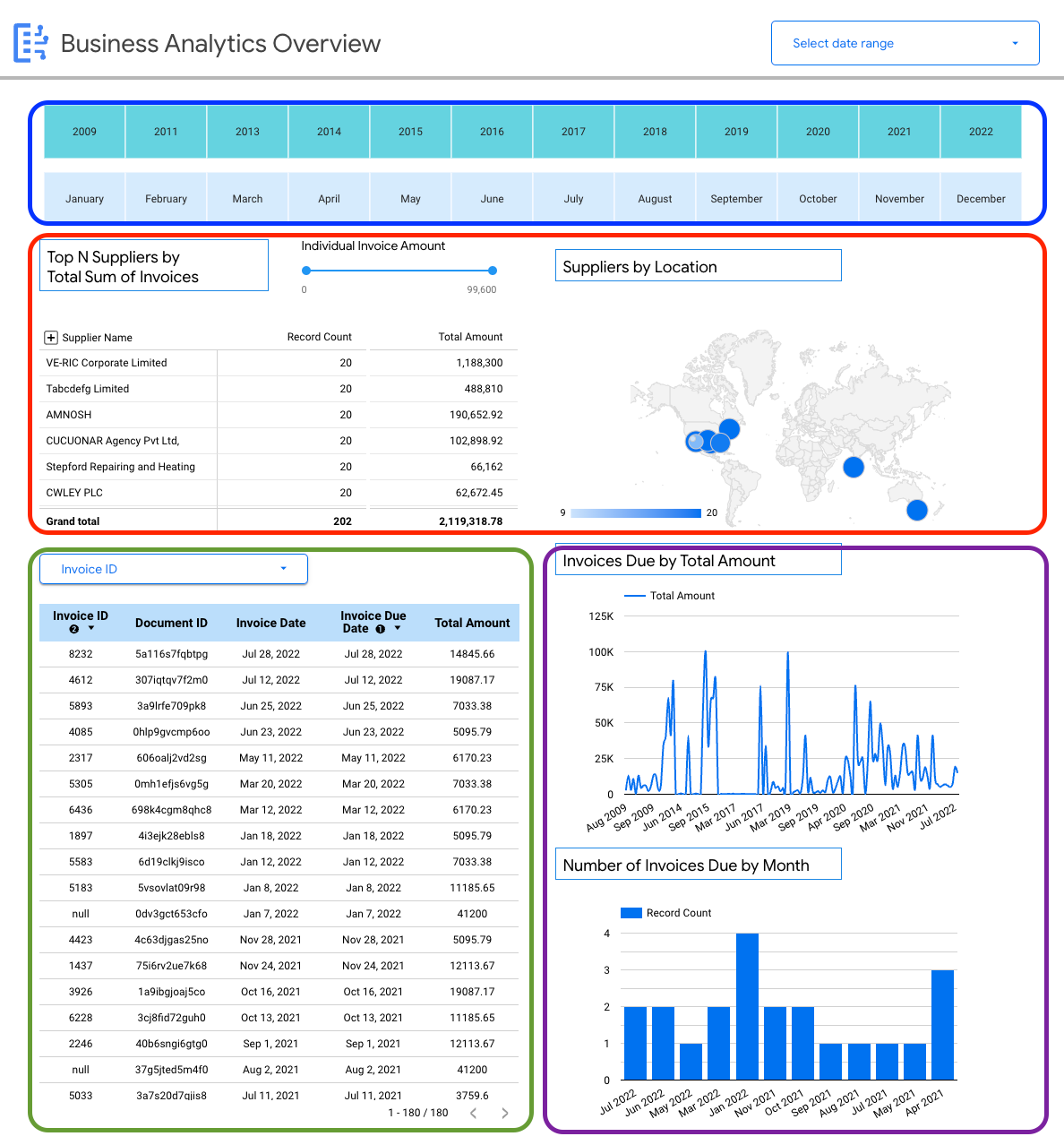
Vous pouvez afficher des informations spécifiques aux schémas sur les factures. Par exemple :
- Principaux fournisseurs par montant de facture.
- Fournisseurs par zone géographique.
- Dates des factures et leurs échéances correspondantes.
- Tendances des factures d'un mois à l'autre, par montant et par nombre d'enregistrements.
Connecter une source de données à des tableaux de bord
Pour utiliser ces exemples de tableaux de bord comme point de départ pour visualiser votre ensemble de données, vous pouvez connecter votre source de données à partir de BigQuery.
Avant de connecter les exemples de tableaux de bord à votre source de données BigQuery, assurez-vous d'être connecté au compte associé à votre environnement Google Cloud.

Sélectionnez le bouton en surbrillance pour afficher les options du menu déroulant.

Sélectionnez Créer une copie.
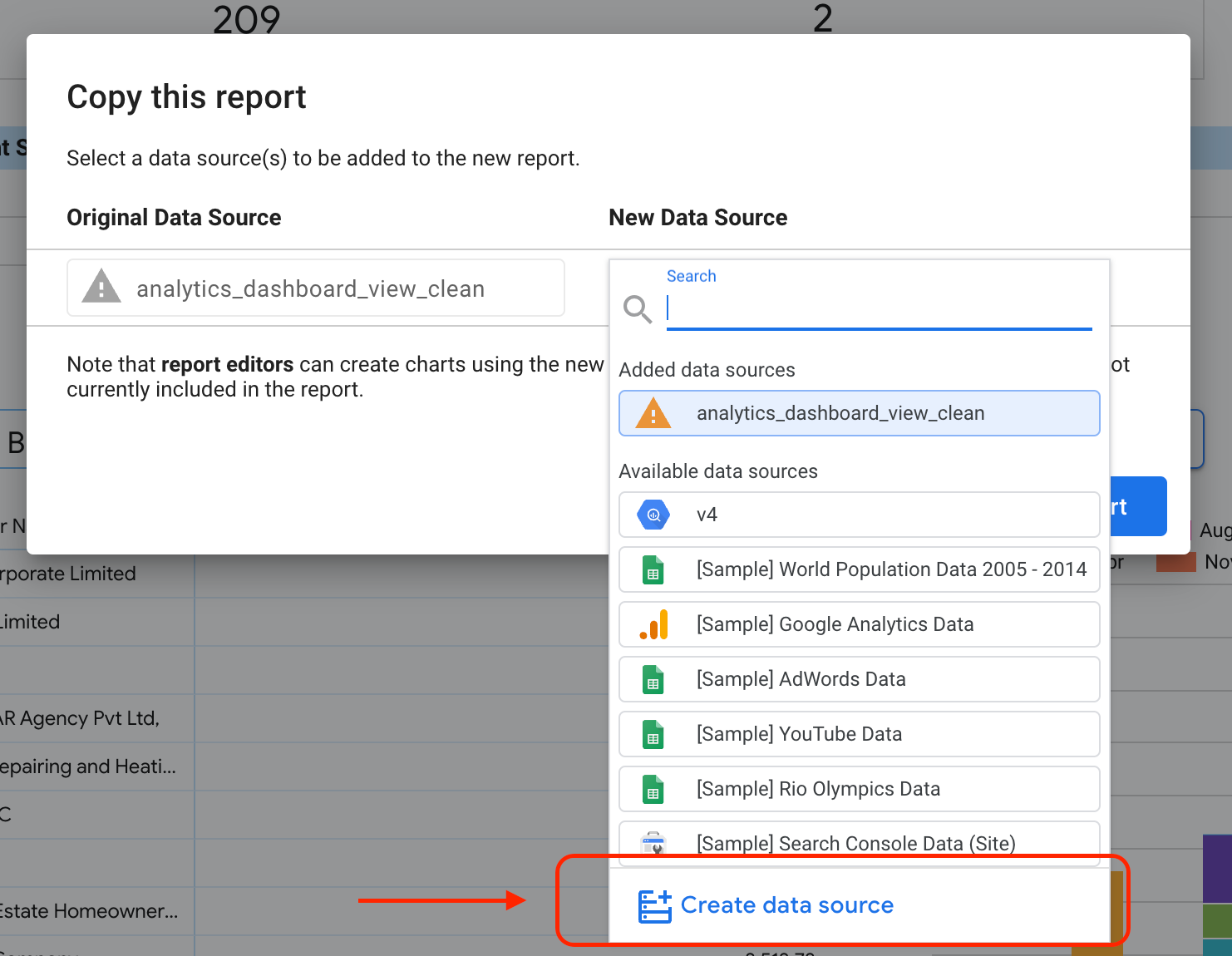
Dans la sous-section "Nouvelle source de données", sélectionnez Créer une source de données.
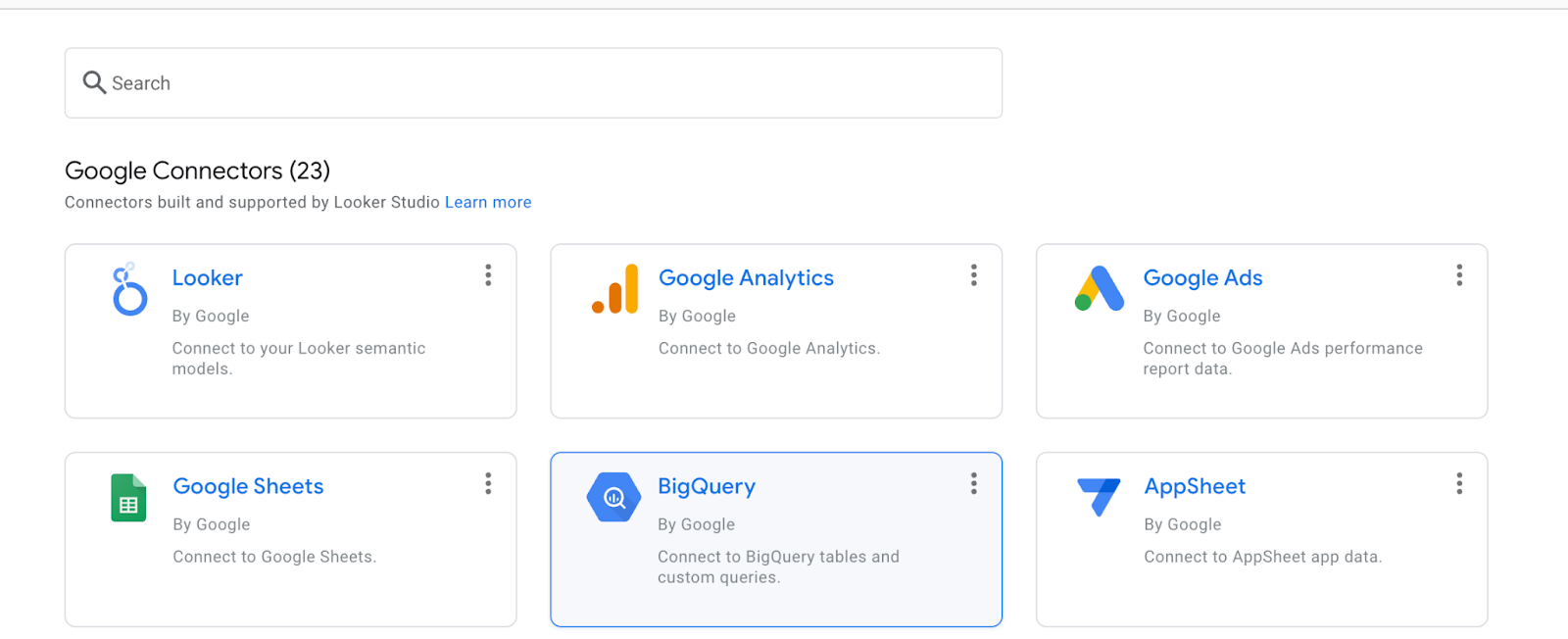
Sélectionnez BigQuery.
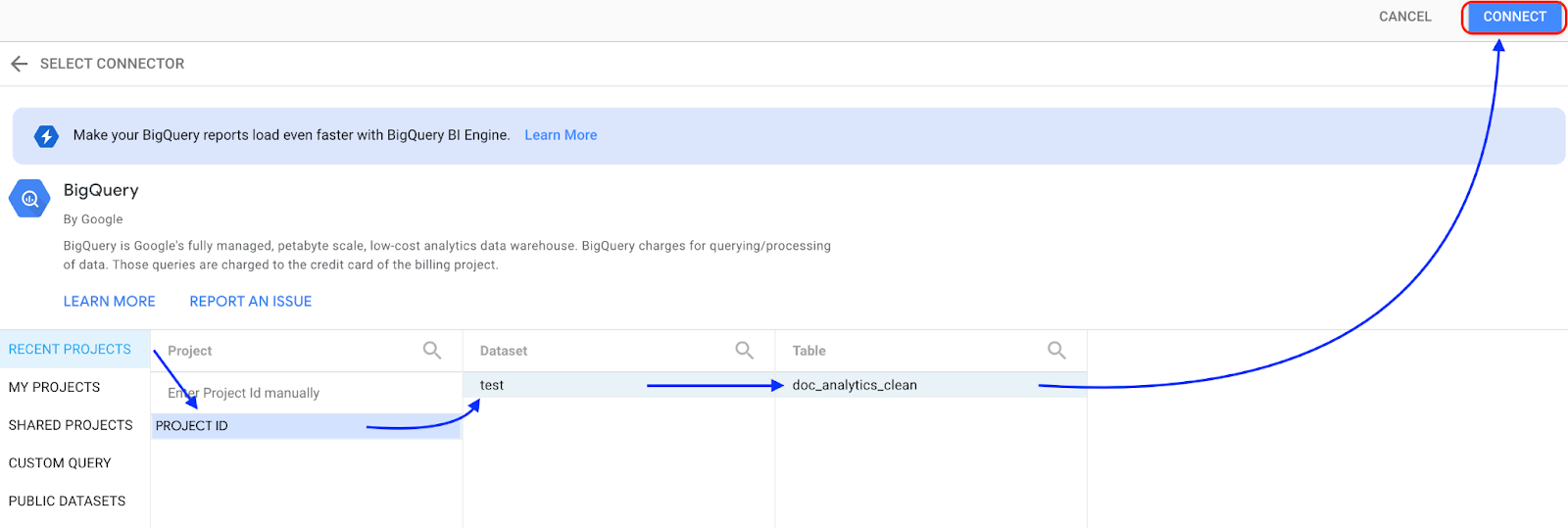
Sélectionnez le projet dans lequel votre ensemble de données est stocké, puis suivez les instructions pour sélectionner votre ensemble de données et votre table. Cliquez sur Se connecter.

Cliquez sur Ajouter au rapport.
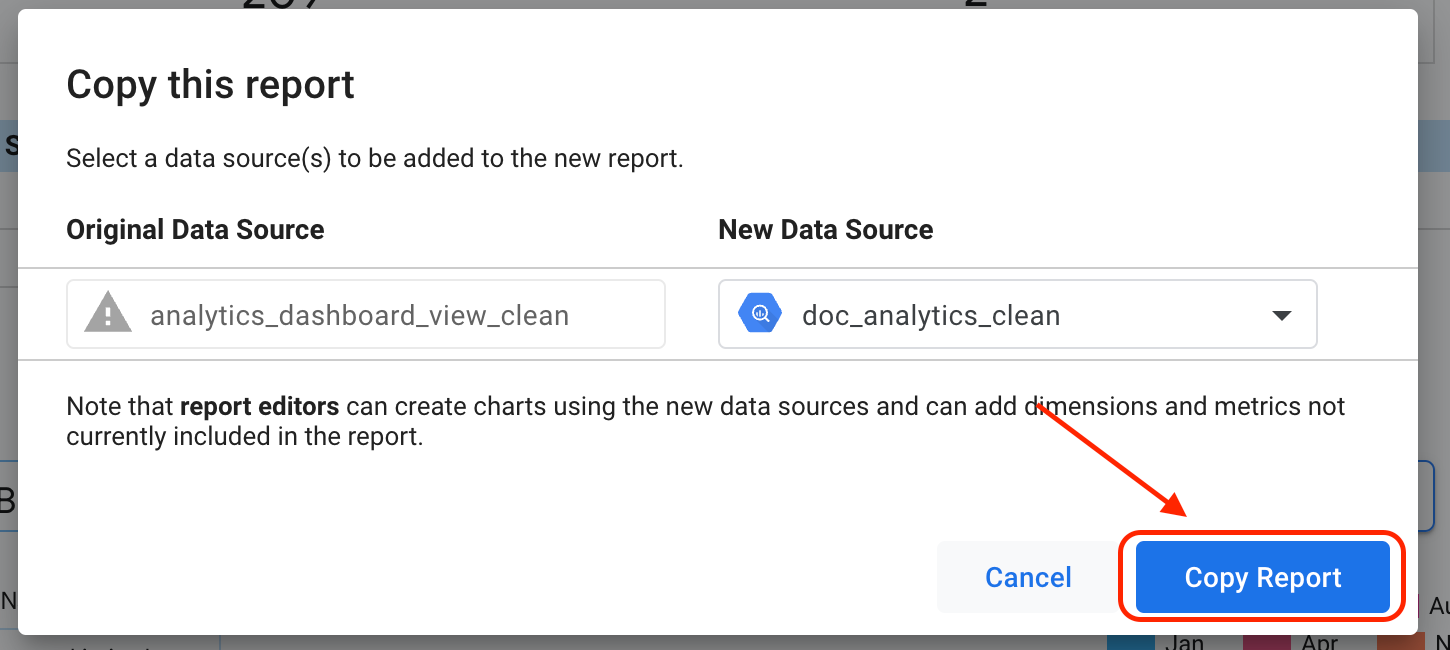
Cliquez sur Copier le rapport.
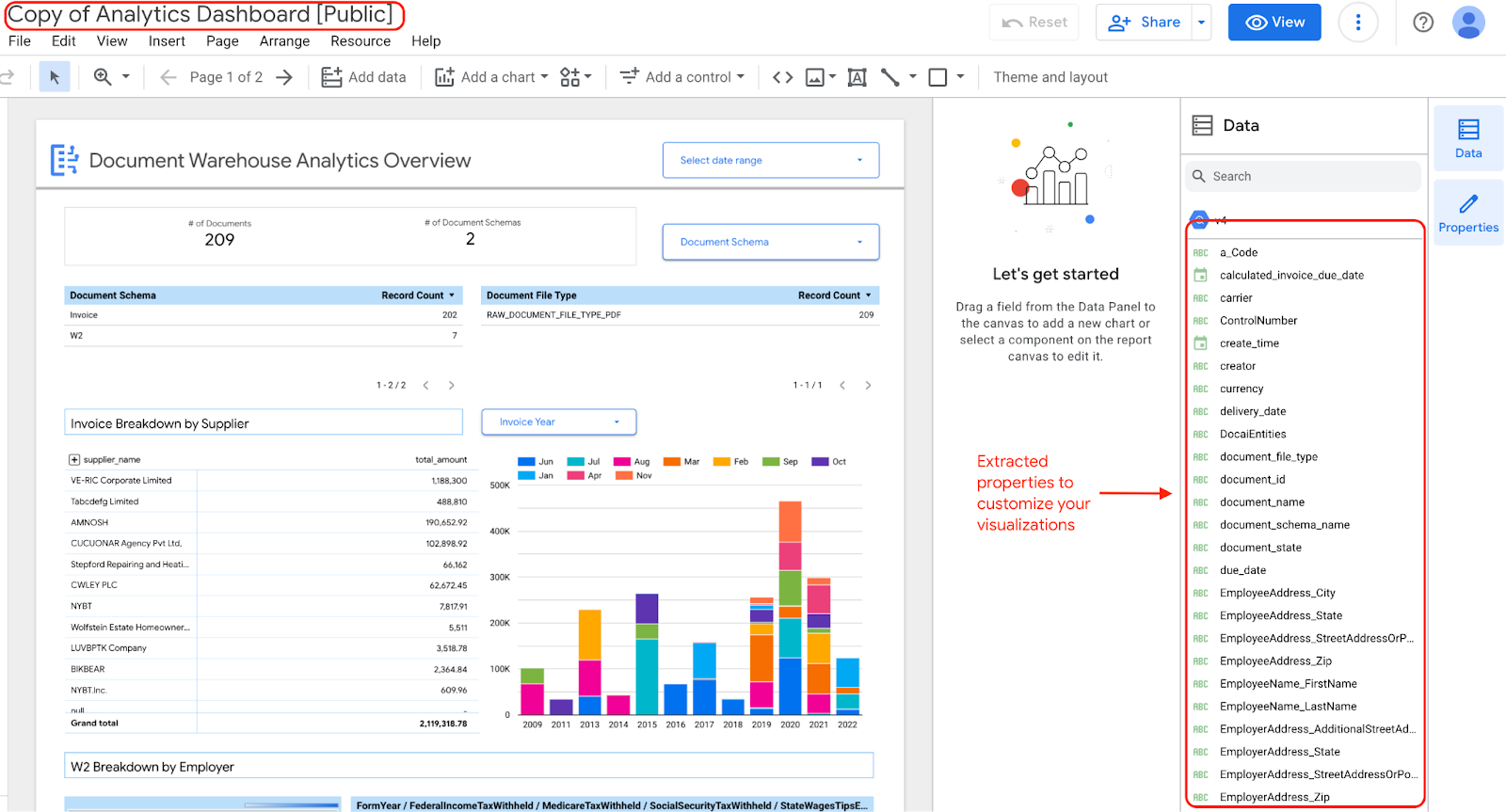
Si vous choisissez de modifier et de mettre à jour les widgets de votre tableau de bord, vous pouvez le faire, car vous disposez d'une copie du tableau de bord avec les propriétés extraites.