
התשובה לבקשת עיבוד מכילה אובייקט Document
שכולל את כל מה שידוע על המסמך שעבר עיבוד, כולל כל המידע המובנה ש-Document AI הצליח לחלץ.
בדף הזה מוסבר הפריסה של אובייקט Document באמצעות מסמכים לדוגמה, ולאחר מכן ממופים היבטים של תוצאות ה-OCR לרכיבים הספציפיים של אובייקט Document בפורמט JSON.
בנוסף, האתר כולל ספריות לקוח, דוגמאות קוד ודוגמאות קוד של Document AI Toolbox SDK.
בדוגמאות הקוד האלה נעשה שימוש בעיבוד אונליין, אבל ניתוח האובייקט Document פועל באותו אופן גם בעיבוד באצווה.
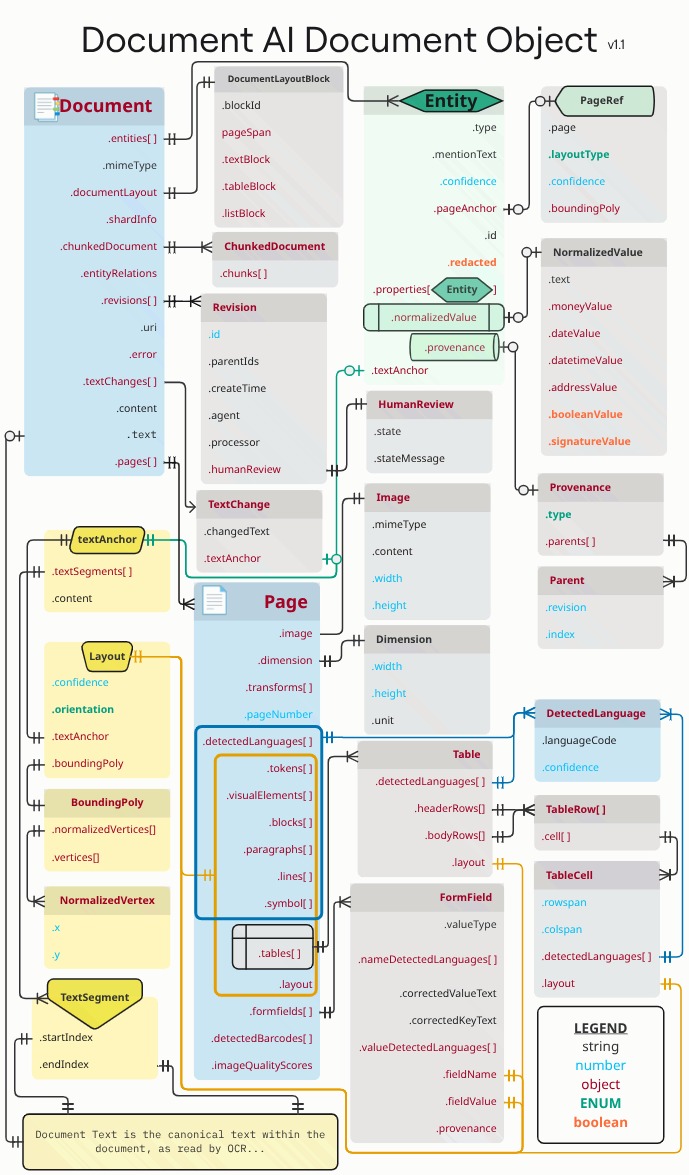
המלבנים והחיצים הכתומים והכחולים מייצגים שלפחות שדה אחד של האובייקטים המקושרים הוא .layout או detectedLanguage, בהתאמה. התרשים משתמש בסימון של רגל עורב.
משתמשים בכלי לצפייה ב-JSON או בכלי לעריכה שנועד במיוחד להרחבה או לכיווץ של אלמנטים. בדיקת JSON גולמי בכלי טקסט פשוט היא לא יעילה.
טקסט, פריסה וציוני איכות
דוגמה למסמך טקסט:

זהו אובייקט המסמך המלא שמוחזר על ידי מעבד Enterprise Document OCR:
הפלט של ה-OCR תמיד נכלל גם בפלט של מעבד Document AI, כי המעבדים מריצים OCR. הוא משתמש בנתוני ה-OCR הקיימים, ולכן אפשר להזין נתוני JSON כאלה למעבדי Document AI באמצעות האפשרות 'מסמך מוטבע'.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
אלה כמה מהשדות החשובים:
טקסט גולמי
השדה text מכיל את הטקסט שמזוהה על ידי Document AI.
הטקסט הזה לא מכיל מבנה פריסה מלבד רווחים, טאבים ומעברי שורה. זהו השדה היחיד שבו מאוחסן מידע טקסטואלי של מסמך, והוא משמש כמקור האמת של הטקסט במסמך. בשדות אחרים אפשר להפנות לחלקים בשדה הטקסט לפי מיקום (startIndex ו-endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
גודל הדף ושפות
כל page באובייקט המסמך תואם לדף פיזי ממסמך הדוגמה. פלט ה-JSON לדוגמה מכיל דף אחד כי מדובר בתמונה אחת בפורמט PNG.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- השדה
pages[].detectedLanguages[]מכיל את השפות שנמצאו בדף מסוים, יחד עם ציון רמת הביטחון.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
נתוני OCR
OCR ב-Document AI מזהה טקסט עם רמות שונות של פירוט או ארגון בדף, כמו בלוקים של טקסט, פסקאות, טוקנים וסמלים (רמת הסמל היא אופציונלית, אם המערכת מוגדרת להפקת נתונים ברמת הסמל). אלה כל החברים באובייקט הדף.
לכל רכיב יש layout תואם שמתאר את המיקום והטקסט שלו. אלמנטים חזותיים שאינם טקסט (כמו תיבות סימון) נמצאים גם הם ברמת הדף.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
הטקסט הגולמי מופיע באובייקט textAnchor, שממופתח במחרוזת הטקסט הראשית באמצעות startIndex ו-endIndex.
במקרה של
boundingPoly, הפינה הימנית העליונה של הדף היא נקודת המוצא(0,0). ערכי X חיוביים הם מימין, וערכי Y חיוביים הם למטה.האובייקט
verticesמשתמש באותן קואורדינטות כמו התמונה המקורית, ואילו הערכים שלnormalizedVerticesהם בטווח[0,1]. יש מטריצת טרנספורמציה שמציינת את המדדים של תיקון העיוות ומאפיינים אחרים של הנורמליזציה של התמונה.
- כדי לשרטט את הצורה
boundingPoly, מציירים קטעי קו מקודקוד אחד לקודקוד הבא. לאחר מכן, סוגרים את הפוליגון על ידי שרטוט של קטע קו מהקודקוד האחרון חזרה לקודקוד הראשון. רכיב הכיוון בפריסה מציין אם הטקסט סובב ביחס לדף.
כדי לעזור לכם להמחיש את מבנה המסמך, בתמונות הבאות מצוירים מצולעים תוחמים עבור page.paragraphs, page.lines ו-page.tokens.
פסקאות

שורות

טוקנים

אבני בניין

מעבד Enterprise Document OCR יכול לבצע הערכת איכות של מסמך על סמך קלות הקריאה שלו.
- כדי לקבל את הנתונים האלה בתגובת ה-API, צריך להגדיר את השדה
processOptions.ocrConfig.enableImageQualityScoresלערךtrue.
הערכת האיכות הזו היא ציון איכות ב[0, 1], כאשר 1 מייצג איכות מושלמת.
ציון האיכות מוחזר בשדה Page.imageQualityScores.
כל הפגמים שזוהו מפורטים כ-quality/defect_* וממוינים בסדר יורד לפי ערך מהימנות.
זוהי דוגמה לקובץ PDF כהה ומטושטש מדי לקריאה נוחה:
הנה מידע על איכות המסמך שמוחזר על ידי מעבד Enterprise Document OCR:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
דוגמאות קוד
בדוגמאות הקוד הבאות אפשר לראות איך לשלוח בקשת עיבוד, ואז לקרוא את השדות ולהדפיס אותם במסוף:
Java
למידע נוסף, קראו את מאמרי העזרה של Document AI Java API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Node.js
למידע נוסף, קראו את מאמרי העזרה של Document AI Node.js API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
טפסים וטבלאות
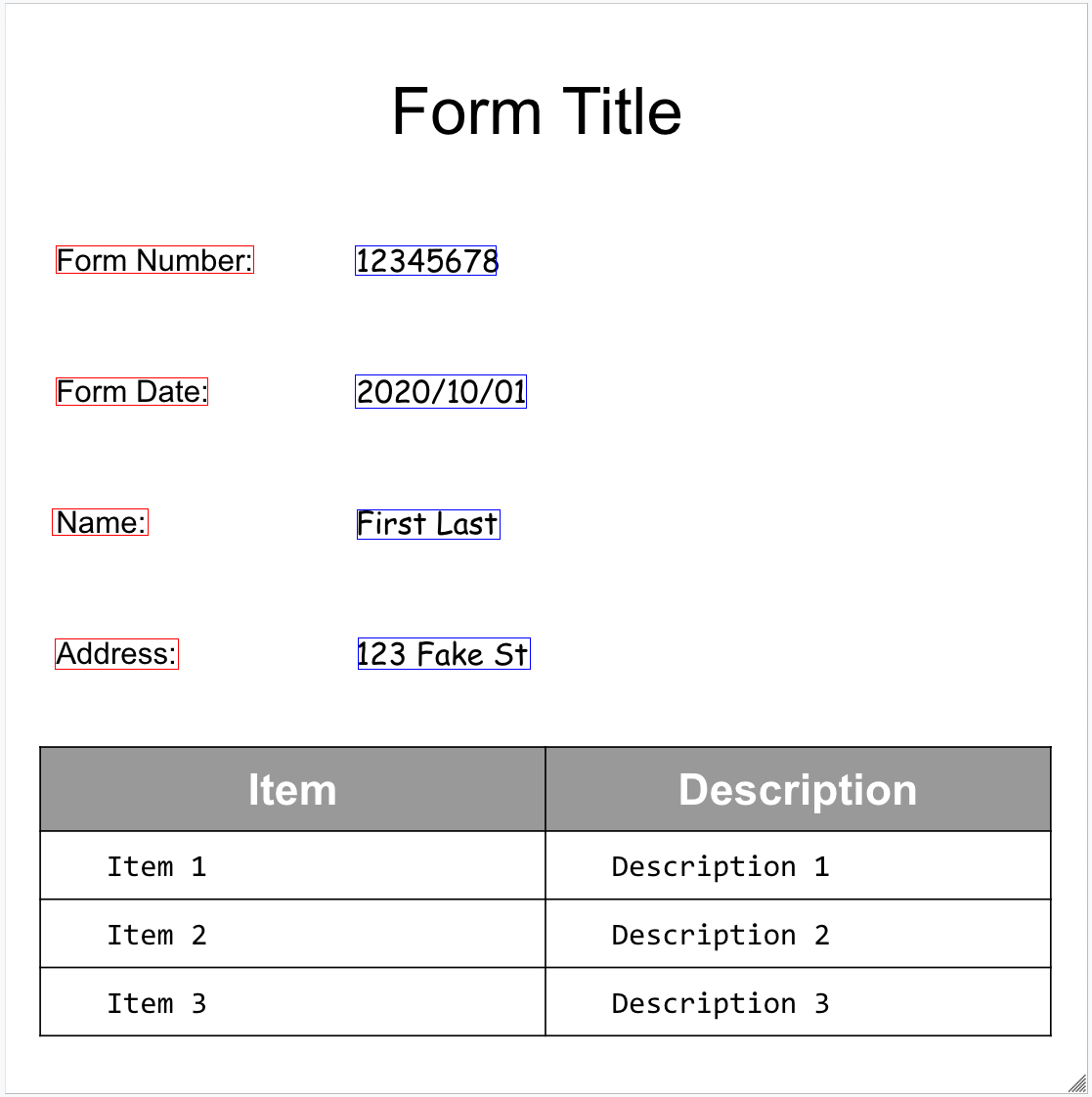
הנה דוגמה לטופס:
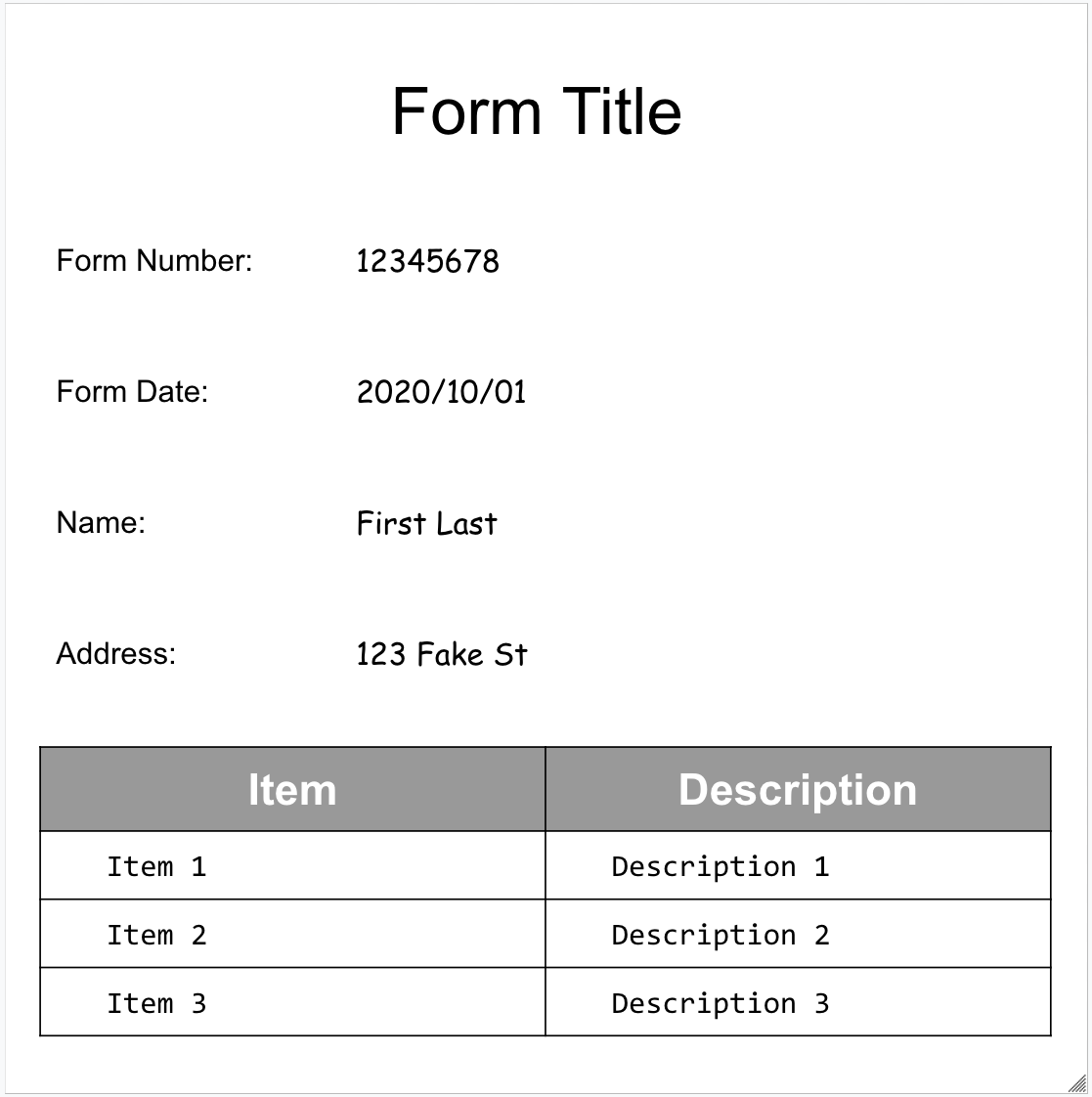
זהו אובייקט המסמך המלא שמוחזר על ידי Form Parser:
אלה כמה מהשדות החשובים:
הכלי Form Parser יכול לזהות FormFields בדף. לכל שדה בטופס יש שם וערך. הם נקראים גם צמדים של מפתח/ערך (KVP). הערה: זוגות של מפתח/ערך שונים מישויות (סכמה) בכלי חילוץ אחרים:
השמות של הישויות מוגדרים. המקשים ב-KVP הם בדיוק הטקסט של המקש במסמך.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI יכול גם לזהות
Tablesבדף.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
הטבלה שמופקת באמצעות הכלי 'ניתוח טפסים' מזהה רק טבלאות רגילות, כלומר טבלאות ללא תאים שמשתרעים על פני שורות או עמודות. לכן rowSpan וcolSpan תמיד 1.
החל מגרסת המעבד
pretrained-form-parser-v2.0-2022-11-10, הכלי Form Parser יכול לזהות גם ישויות כלליות. מידע נוסף זמין במאמר בנושא כלי לניתוח טפסים.כדי לעזור לכם להבין את מבנה המסמך, בתמונות הבאות מוצגים פוליגונים של תיבות תוחמות עבור
page.formFieldsו-page.tables.תיבות סימון בטבלאות. הכלי Form Parser יכול לבצע דיגיטציה של תיבות סימון מתמונות ומקובצי PDF כזוגות של מפתח/ערך. דוגמה לדיגיטציה של תיבת סימון כצמד מפתח/ערך.
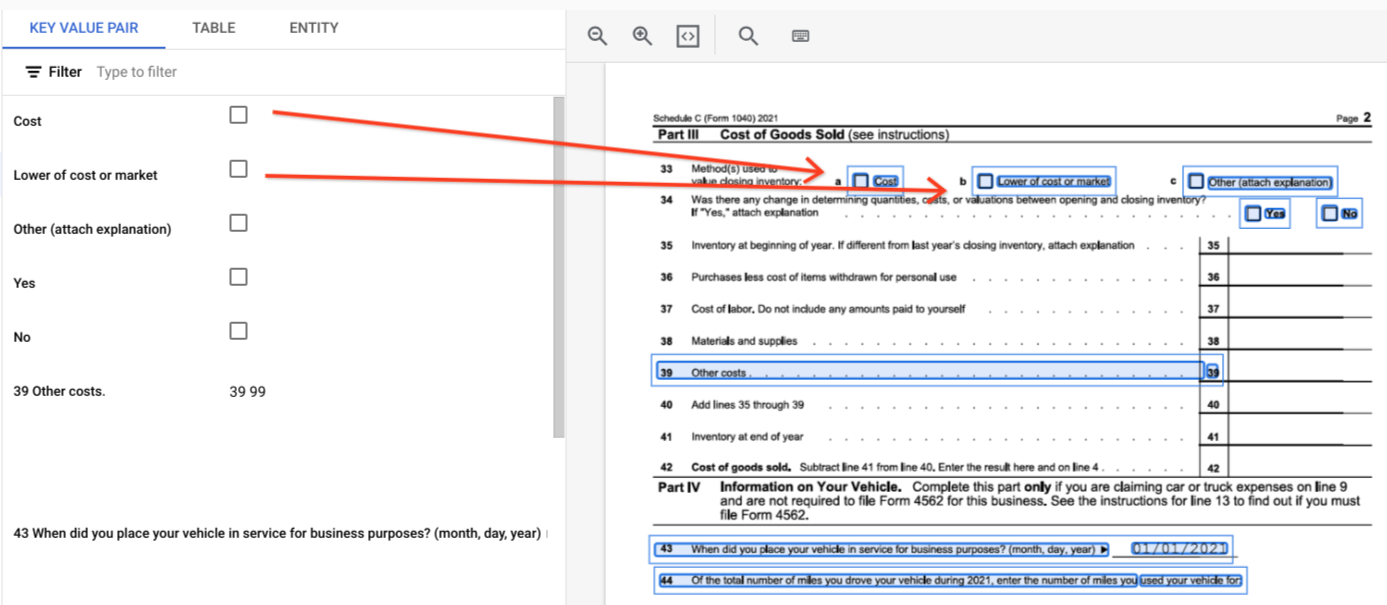
מחוץ לטבלאות, תיבות הסימון מיוצגות כרכיבים חזותיים בכלי Form Parser. הדגשה של התיבות המרובעות עם סימני וי בממשק המשתמש ושל סימן היוניקוד ✓ ב-JSON.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
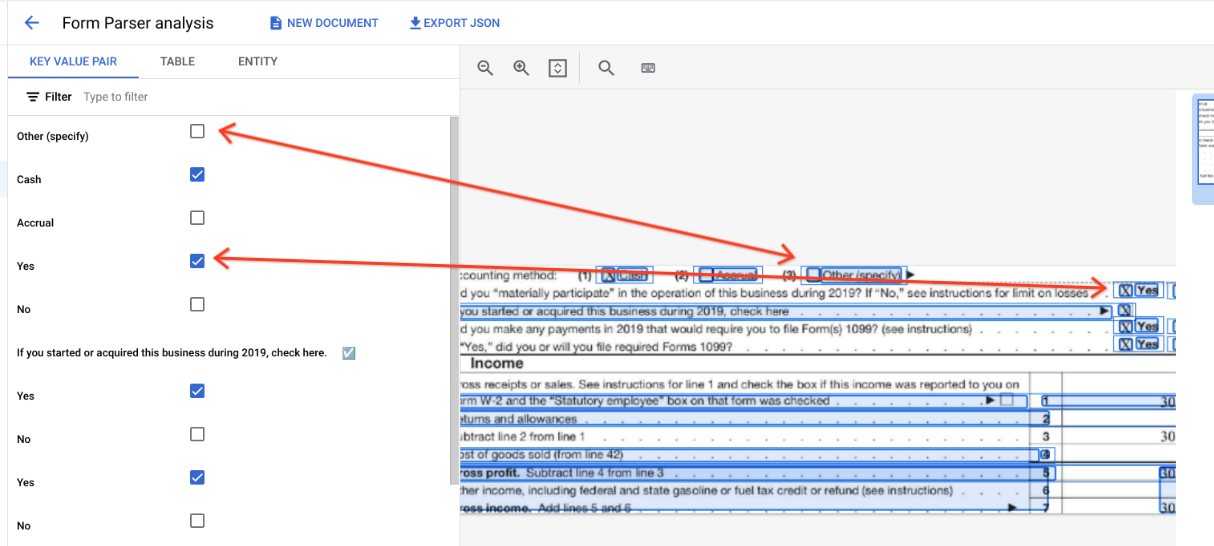
בטבלאות, תיבות הסימון מופיעות כתווי Unicode כמו ✓ (מסומן) או ☐ (לא מסומן).
תיבות הסימון שמסומנות מקבלות את הערך filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. הערך של תיבות הסימון שלא מסומנות הוא unfilled_checkbox.
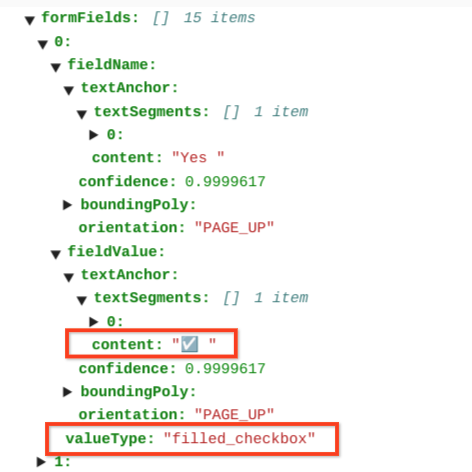
בשדות התוכן מוצג ערך התוכן של תיבת הסימון כשהוא מודגש ✓ בנתיב pages>formFields>x>fieldValue>textAnchor>content.
כדי לעזור לכם להמחיש את מבנה המסמך, בתמונות הבאות מצוירים מצולעים תוחמים עבור page.formFields ו-page.tables.
שדות בטופס
Tables
דוגמאות קוד
בדוגמאות הקוד הבאות אפשר לראות איך לשלוח בקשת עיבוד, ואז לקרוא את השדות ולהדפיס אותם במסוף:
Java
למידע נוסף, קראו את מאמרי העזרה של Document AI Java API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Node.js
למידע נוסף, קראו את מאמרי העזרה של Document AI Node.js API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
ישויות, ישויות מוטמעות וערכים מנורמלים
רבים מהמעבדים המיוחדים מחלצים נתונים מובְנים שמבוססים על סכמה מוגדרת היטב. לדוגמה, כלי לניתוח חשבוניות מזהה שדות ספציפיים כמו invoice_date ו-supplier_name. לדוגמה, הנה חשבונית:
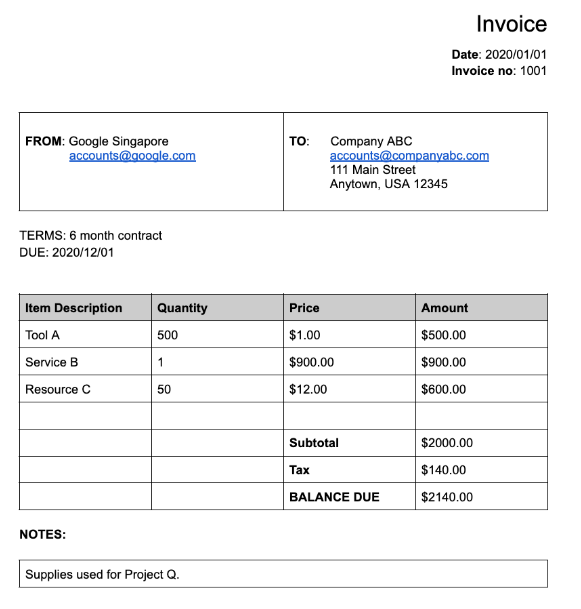
זה אובייקט המסמך המלא שמוחזר על ידי כלי הניתוח של חשבוניות:
אלה כמה מהחלקים החשובים של אובייקט המסמך:
שדות שזוהו:
Entitiesמכיל את השדות שהמעבד הצליח לזהות, לדוגמה,invoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }במקרים מסוימים, המעבד גם מנרמל את הערך של השדה. בדוגמה הזו, התאריך עבר נירמול מ-
2020/01/01ל-2020-01-01.נרמול: עבור הרבה שדות ספציפיים נתמכים, המעבד גם מנרמל את הערך וגם מחזיר
entity. השדהnormalizedValueמתווסף לשדה הגולמי שחולץ באמצעותtextAnchorשל כל ישות. לכן, הוא מבצע נורמליזציה של הטקסט המילולי, ולעתים קרובות מחלק את ערך הטקסט לשדות משנה. לדוגמה, תאריך כמו 1 בספטמבר 2024 ייוצג כך:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
בדוגמה הזו, התאריך עבר נרמול מ-2020/01/01 ל-2020-01-01, שהוא פורמט סטנדרטי שמקטין את הצורך בעיבוד שלאחר ההמרה ומאפשר המרה לפורמט שנבחר.
בנוסף, הכתובות עוברות לעיתים קרובות נורמליזציה, שבה האלמנטים של הכתובת מפורקים לשדות נפרדים. המספרים עוברים נורמליזציה כך שnormalizedValue הוא מספר שלם או מספר עם נקודה עשרונית.
- העשרה: מעבדים ושדות מסוימים תומכים גם בהעשרה.
לדוגמה, המונח המקורי
supplier_nameבמסמךGoogle Singaporeעבר נורמליזציה בהשוואה ל-Enterprise Knowledge Graph והפך ל-Google Asia Pacific, Singapore. שימו לב גם שבגלל שתרשים הידע של Enterprise מכיל מידע על Google, Document AI מסיק אתsupplier_addressלמרות שהוא לא הופיע במסמך לדוגמה.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
שדות מוטמעים: אפשר ליצור סכימה מוטמעת (שדות) על ידי הכרזה על ישות כהורה, ואז יצירת ישויות צאצא מתחת להורה. תגובת הניתוח של ההורה כוללת את שדות הצאצא ברכיב
propertiesשל שדה ההורה. בדוגמה הבאה,line_itemהוא שדה הורה שיש לו שני שדות צאצא:line_item/descriptionו-line_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
הנתונים הבאים מנותחים על ידי מנתחים:
- חילוץ (כלי מותאם אישית לחילוץ)
- קודם
- מנתח דפי חשבון בנק
- מנתח הוצאות
- כלי לניתוח חשבוניות
- PaySlip parser
- W2 Parser
דוגמאות קוד
בדוגמאות הקוד הבאות אפשר לראות איך לשלוח בקשת עיבוד, ואז לקרוא ולהדפיס את השדות ממעבד ייעודי במסוף:
Java
למידע נוסף, קראו את מאמרי העזרה של Document AI Java API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Node.js
למידע נוסף, קראו את מאמרי העזרה של Document AI Node.js API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
כלי מותאם אישית לחילוץ מסמכים
מעבד מותאם אישית לחילוץ מסמכים יכול לחלץ ישויות מותאמות אישית ממסמכים שאין להם מעבד שאומן מראש. אפשר לעשות את זה באמצעות אימון של מודל בהתאמה אישית או באמצעות שימוש במודלים בסיסיים של AI גנרטיבי כדי לחלץ ישויות בעלות שם בלי אימון. מידע נוסף זמין במאמר יצירת כלי מותאם אישית לחילוץ מסמכים במסוף.
- אם מאמנים מודל בהתאמה אישית, אפשר להשתמש במעבד בדיוק כמו במעבד של ישות שחולצה שאומן מראש.
- אם אתם משתמשים במודל בסיסי, אתם יכולים ליצור גרסת מעבד כדי לחלץ ישויות ספציפיות לכל בקשה, או להגדיר את זה לכל בקשה בנפרד.
למידע על מבנה הפלט, אפשר לעיין במאמר ישויות, ישויות מקוננות וערכים מנורמלים.
דוגמאות קוד
אם אתם משתמשים במודל בהתאמה אישית או שיצרתם גרסת מעבד באמצעות מודל בסיסי, אתם צריכים להשתמש בדוגמאות קוד לחילוץ ישויות.
בדוגמת הקוד הבאה אפשר לראות איך מגדירים ישויות ספציפיות ל-Custom Document Extractor של מודל בסיסי על בסיס כל בקשה, ומדפיסים את הישויות שחולצו:
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
סיכום
מעבד הסיכום משתמש במודלים בסיסיים של AI גנרטיבי כדי לסכם את הטקסט שחולץ ממסמך. אפשר להתאים אישית את האורך והפורמט של התשובה בדרכים הבאות:
- אורך
-
BRIEF: סיכום קצר של משפט או שניים -
MODERATE: סיכום באורך פסקה -
COMPREHENSIVE: האפשרות הכי ארוכה שזמינה
-
- פורמט
אפשר ליצור גרסת מעבד לאורך ופורמט ספציפיים, או להגדיר אותה לכל בקשה בנפרד.
הטקסט המסוכם מופיע בDocument.entities.normalizedValue.text. אפשר לראות קובץ JSON מלא לדוגמה בפלט לדוגמה של מעבד.
מידע נוסף מופיע במאמר בנושא יצירת כלי לסיכום מסמכים במסוף.
דוגמאות קוד
בדוגמת הקוד הבאה אפשר לראות איך מגדירים אורך ופורמט ספציפיים בבקשת עיבוד ומדפיסים את הטקסט המסוכם:
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
פיצול וסיווג
הנה קובץ PDF מורכב בן 10 עמודים שמכיל סוגים שונים של מסמכים וטפסים:
זה אובייקט המסמך המלא שמוחזר על ידי כלי החלוקה והסיווג של מסמכי הלוואות:
כל מסמך שמזוהה על ידי הכלי לפיצול מיוצג על ידי התג entity. לדוגמה:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorמציין שהמסמך הזה כולל 2 דפים. הערה: הערךpageRefs[].pageמבוסס על אפסים והוא האינדקס בשדהdocument.pages[].
Entity.typeמציין שהמסמך הזה הוא טופס 1040 Schedule SE. רשימה מלאה של סוגי המסמכים שאפשר לזהות מופיעה בקטע סוגי המסמכים שזוהו בתיעוד של המעבד.
מידע נוסף זמין במאמר בנושא התנהגות של כלי לפיצול מסמכים.
דוגמאות קוד
הכלי לפיצול מזהה את הגבולות בין הדפים, אבל הוא לא מפצל את מסמך הקלט בפועל. אתם יכולים להשתמש בארגז הכלים של Document AI כדי לפצל פיזית קובץ PDF באמצעות גבולות הדפים. בדוגמאות הקוד הבאות מודפסים טווחי הדפים בלי לפצל את קובץ ה-PDF:
Java
למידע נוסף, קראו את מאמרי העזרה של Document AI Java API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Node.js
למידע נוסף, קראו את מאמרי העזרה של Document AI Node.js API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Document שעבר עיבוד.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
ארגז הכלים של Document AI
Document AI Toolbox הוא SDK ל-Python שמספק פונקציות עזר לניהול, לעריכה ולחילוץ מידע מהתגובה של המסמך.
היא יוצרת אובייקט מסמך 'עטוף' מתגובת מסמך מעובד מקובצי JSON ב-Cloud Storage, מקובצי JSON מקומיים או מפלט ישירות מהשיטה process_document().
הוא יכול לבצע את הפעולות הבאות:
- שילוב של קובצי JSON מפוצלים של
Documentמתוך עיבוד באצווה למסמך 'עטוף' יחיד. - ייצוא של שברי נתונים כקובץ
Documentמאוחד. -
קבלת פלט
Documentמ: - גישה לטקסט מ-
Pages,Lines,Paragraphs,FormFieldsו-Tablesבלי לטפל במידעLayout. - חיפוש
Pagesשמכיל מחרוזת יעד או שתואם לביטוי רגולרי. - מחפשים את
FormFieldsלפי שם. - חיפוש
Entitiesלפי סוג. - המרת
Tablesל-Pandas Dataframe או ל-CSV. - הוספת
Entitiesו-FormFieldsלטבלת BigQuery. - פיצול קובץ PDF על סמך פלט ממעבד מסוג Splitter/Classifier.
- תחלץ את התמונה
EntitiesמDocumentתיבות התוחמות. -
המרת
Documentsלפורמטים נפוצים ומפורמטים נפוצים ל-Documents:- Cloud Vision API
AnnotateFileResponse - hOCR
- פורמטים לעיבוד מסמכים של צד שלישי
- Cloud Vision API
- יצירת קבוצות של מסמכים לעיבוד מתיקייה ב-Cloud Storage.
דוגמאות קוד
בדוגמאות הקוד הבאות אפשר לראות איך להשתמש ב-Document AI Toolbox.