
Ce document présente la gestion des charges de travail dans Google Distributed Cloud (GDC) air-gapped. Voici les sujets abordés :
Bien que certains modèles de déploiement de charge de travail soient recommandés, il n'est pas obligatoire de les suivre exactement comme indiqué. Chaque univers GDC présente des exigences et des considérations uniques qui doivent être satisfaites au cas par cas.
Ce document s'adresse aux administrateurs informatiques du groupe d'administrateurs de plate-forme, qui sont chargés de gérer les ressources de leur organisation, et aux développeurs d'applications du groupe d'opérateurs d'applications, qui sont chargés de développer et de gérer les applications dans un univers GDC.
Pour en savoir plus, consultez Audiences pour la documentation GDC sous air gap.
Où déployer les charges de travail
Sur la plate-forme GDC, les opérations de déploiement des charges de travail de machines virtuelles (VM) et de conteneurs sont différentes. Le schéma suivant illustre la séparation des charges de travail au sein de la couche de plan de données de votre organisation.
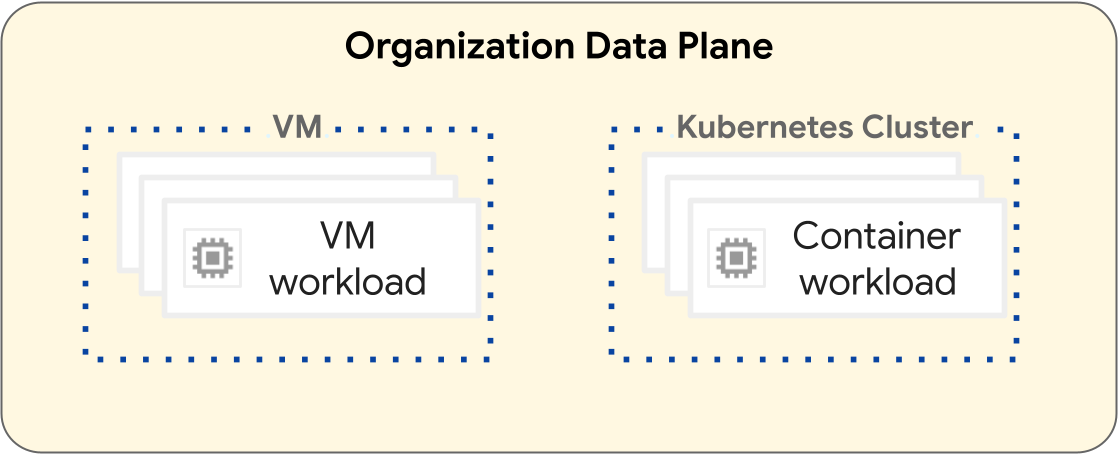
Les charges de travail basées sur des VM fonctionnent dans une VM. À l'inverse, les charges de travail de conteneur fonctionnent dans un cluster Kubernetes. La séparation fondamentale entre les VM et les clusters Kubernetes fournit des limites d'isolation entre vos charges de travail de VM et vos charges de travail de conteneurs. Pour en savoir plus, consultez la section Hiérarchie des ressources.
Les sections suivantes présentent les différences entre chaque type de charge de travail et leur cycle de vie de déploiement.
Charges de travail basées sur des VM
Vous pouvez créer des VM pour héberger vos charges de travail basées sur des VM. Vous disposez de nombreuses options de configuration pour la forme et la taille de votre VM afin de répondre au mieux aux exigences de votre charge de travail basée sur une VM. Vous devez créer une VM dans un projet, qui peut comporter de nombreuses charges de travail de VM. Les VM sont une ressource enfant d'un projet. Pour en savoir plus, consultez la présentation des VM.
Les projets contenant uniquement des charges de travail basées sur des VM ne nécessitent pas de cluster Kubernetes. Par conséquent, vous n'avez pas besoin de provisionner de clusters Kubernetes pour les charges de travail basées sur des VM.
Charges de travail basées sur des conteneurs
Vous pouvez déployer des charges de travail basées sur des conteneurs sur un pod d'un cluster Kubernetes. Un cluster Kubernetes se compose des types de nœuds suivants :
Nœud du plan de contrôle : exécute les services de gestion, tels que la planification, etcd et un serveur d'API.
Nœud de calcul : exécute vos pods et vos applications de conteneur.
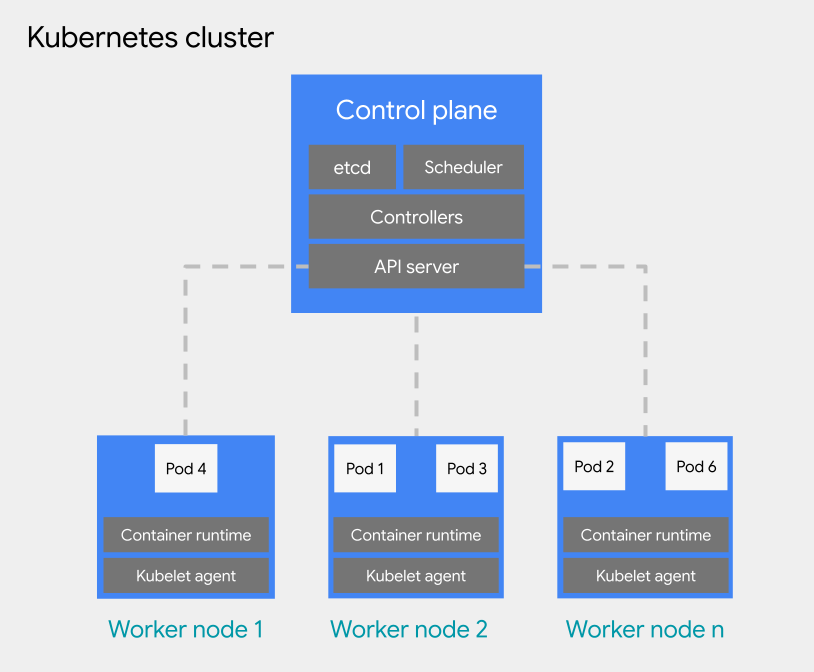
Il existe deux types de configuration pour les clusters Kubernetes :
- Clusters partagés : cluster Kubernetes à l'échelle de l'organisation qui peut s'étendre sur plusieurs projets et qui n'est pas géré par un seul projet, mais qui y est associé.
- Clusters standards : cluster Kubernetes à l'échelle d'un projet qui gère les ressources de cluster au sein d'un projet et ne peut pas s'étendre sur plusieurs projets.
Pour en savoir plus, consultez Configurations de cluster Kubernetes.
Les clusters Kubernetes offrent différentes options de hiérarchie des ressources, car les clusters partagés sont de portée organisationnelle et les clusters standards sont de portée projet. Il s'agit d'une différence fondamentale entre les clusters Kubernetes et les VM. Une VM est une ressource enfant d'un projet et ne peut pas être configurée pour fonctionner en dehors d'un projet. Pour en savoir plus sur la conception de l'infrastructure de votre cluster Kubernetes, consultez Bonnes pratiques pour concevoir des clusters Kubernetes.
Pour la planification des pods dans un cluster Kubernetes, GDC adopte les concepts généraux de Kubernetes en matière de planification, de préemption et d'éviction. Les bonnes pratiques concernant la planification des pods dans un cluster varient en fonction des exigences de votre charge de travail.
Pour en savoir plus sur les clusters Kubernetes, consultez la présentation des clusters Kubernetes. Pour en savoir plus sur la gestion de vos conteneurs dans un cluster Kubernetes, consultez Charges de travail de conteneurs dans GDC.
Bonnes pratiques pour concevoir des clusters Kubernetes
Cette section présente les bonnes pratiques à suivre pour concevoir des clusters Kubernetes :
- Créer des clusters distincts pour chaque environnement de développement logiciel
- Créer moins de clusters, mais plus grands
- Créer moins de pools de nœuds, mais de plus grande taille, dans un cluster
Tenez compte de chaque bonne pratique pour concevoir un cluster résilient pour le cycle de vie de votre charge de travail de conteneur.
Créer des clusters distincts par environnement de développement logiciel
En plus d'utiliser des projets distincts par environnement de développement logiciel, nous vous recommandons de concevoir des clusters Kubernetes distincts par environnement de développement logiciel. Un environnement de développement logiciel est une zone de votre univers GDC destinée à toutes les opérations correspondant à une phase désignée du cycle de vie. Par exemple, si votre organisation dispose de trois environnements de développement logiciel nommés development, staging et production, vous pouvez créer un ensemble distinct de clusters Kubernetes pour chaque environnement et associer des projets à chaque cluster en fonction de vos besoins.
Nous vous recommandons d'utiliser des clusters standards dans les cycles de vie de préproduction, qui sont limités à un seul projet. Cela permet d'isoler les processus destructifs liés aux tests des projets de production. En revanche, les clusters partagés sont idéaux pour les environnements de production qui peuvent s'étendre sur plusieurs projets. Un cluster partagé qui héberge des charges de travail de production réparties sur plusieurs projets fournit une zone de déploiement partagée où les clusters standards limités à un seul projet peuvent promouvoir leurs charges de travail directement dans l'environnement de production.
Les clusters standards définis pour chaque environnement de développement logiciel supposent que les charges de travail de préproduction au sein d'un environnement de développement logiciel sont limitées à ce cluster. Un cluster Kubernetes peut être subdivisé en plusieurs pools de nœuds ou utiliser des rejets pour isoler les charges de travail.
En séparant les clusters Kubernetes par environnement de développement logiciel, vous isolez la consommation de ressources, les règles d'accès, les événements de maintenance et les modifications de configuration au niveau du cluster entre vos charges de travail de production et hors production.
Le schéma suivant montre un exemple de conception de cluster Kubernetes pour plusieurs charges de travail qui couvrent des projets, des clusters, des environnements de développement logiciel et des classes de machines fournies par différents pools de nœuds.
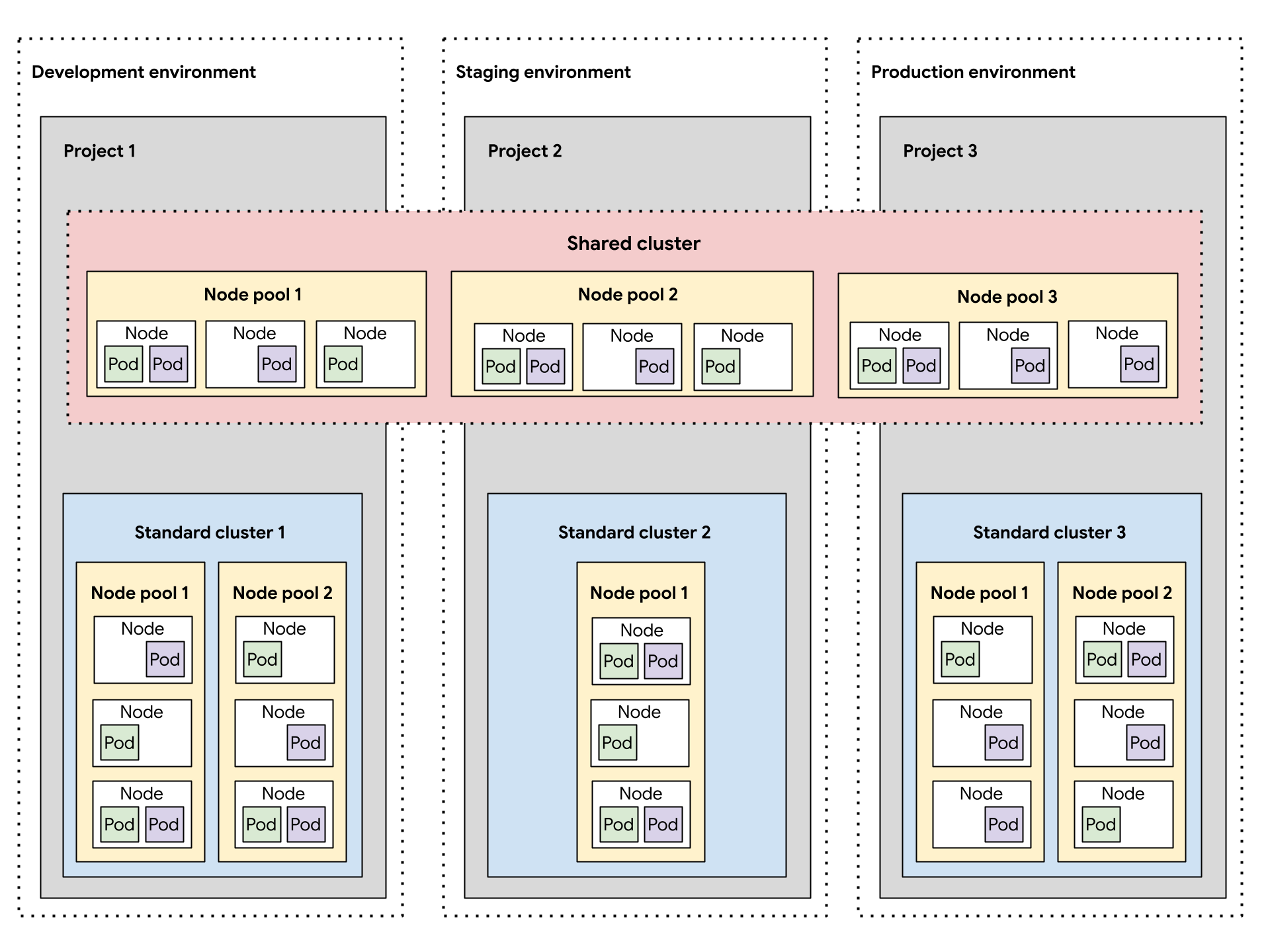
Cette architecture exemple suppose que les charges de travail dans les environnements de développement logiciel, de préproduction et de production peuvent partager des clusters. Chaque environnement dispose d'un cluster standard distinct, qui est lui-même subdivisé en plusieurs pools de nœuds pour répondre aux différentes exigences en termes de classe de machine. Le cluster partagé couvre tous les environnements de développement logiciel, ce qui fournit une zone de déploiement commune pour tous les environnements.
Vous pouvez également concevoir plusieurs clusters standards par environnement de développement logiciel pour les opérations de conteneur, comme dans les scénarios suivants :
- Vous avez épinglé certaines charges de travail à une version spécifique de Kubernetes. Vous gérez donc différents clusters à différentes versions.
- Vous avez des charges de travail qui nécessitent différentes configurations de cluster, comme la stratégie de sauvegarde. Vous créez donc plusieurs clusters avec des configurations différentes.
- Vous exécutez des copies d'un cluster en parallèle pour faciliter les mises à niveau de version disruptives ou une stratégie de déploiement bleu-vert.
- Vous créez une charge de travail expérimentale qui risque de limiter le serveur d'API ou d'autres points de défaillance uniques dans un cluster. Vous l'isolez donc des charges de travail existantes.
Vous devez adapter vos environnements de développement logiciel aux exigences définies par vos opérations de conteneur.
Créer moins de clusters
Pour une utilisation efficace des ressources, nous vous recommandons de concevoir le plus petit nombre possible de clusters Kubernetes qui répondent à vos exigences en matière de séparation des environnements de développement logiciel et des opérations de conteneur. Chaque cluster supplémentaire entraîne une consommation de ressources supplémentaire, comme des nœuds de plan de contrôle supplémentaires. Par conséquent, un grand cluster avec de nombreuses charges de travail utilise les ressources de calcul sous-jacentes plus efficacement que de nombreux petits clusters.
Lorsque plusieurs clusters ont des configurations similaires, la surveillance de la capacité des clusters et la planification des dépendances entre les clusters entraînent une charge de maintenance supplémentaire.
Si un cluster approche de sa capacité maximale, nous vous recommandons d'ajouter des nœuds à un cluster plutôt que d'en créer un.
Créer moins de pools de nœuds dans un cluster
Pour une utilisation efficace des ressources, nous vous recommandons de concevoir moins de pools de nœuds, mais de plus grande taille, dans un cluster Kubernetes.
La configuration de plusieurs pools de nœuds est utile lorsque vous devez planifier des pods qui nécessitent une classe de machine différente de celle des autres. Créez un pool de nœuds pour chaque classe de machine requise par vos charges de travail et définissez la capacité des nœuds sur l'autoscaling pour permettre une utilisation efficace des ressources de calcul.
Étapes suivantes
- Hiérarchie des ressources
- Créer une application de conteneur à haute disponibilité
- Créer une application de VM à haute disponibilité