
从 Google Distributed Cloud (GDC) 气隙环境中已部署的工作负载收集指标后,您就可以开始分析这些指标了。如需分析指标,您可以在信息丰富的 Grafana 信息中心直观呈现和过滤这些指标,也可以使用 curl 工具直接从 Cortex 访问这些指标,以便灵活地编写脚本和实现自动化。
本页详细介绍了如何使用 Grafana 界面和 Cortex 端点的 curl 工具查询和直观呈现指标,从而深入了解工作负载性能。
您可以通过以下两种方法之一访问指标:
- Grafana 信息中心:通过直观的可视化图表探索趋势并发现异常情况,这些图表会显示 CPU 利用率、存储空间消耗和网络活动等关键指标。Grafana 提供了一个用户友好的界面,用于在信息中心内过滤和分析工作负载数据。
- Cortex 端点:对于更高级的用例,您可以使用命令行中的
curl工具直接查询项目的 Cortex 实例。Cortex 会存储项目的 Prometheus 指标,并提供一个 HTTP 端点以供程序化访问。通过此访问权限,您可以导出数据、自动执行任务和构建自定义集成。
准备工作
如需获得在 Grafana 信息中心上查询和直观呈现指标所需的权限,请让您的组织 IAM 管理员或项目 IAM 管理员向您授予预定义的组织 Grafana 查看者或项目 Grafana 查看者角色。根据您需要的访问权限级别,您可以在组织或项目中获取 Grafana 角色。
或者,如需获得从 Cortex 端点查询指标所需的权限,请让您的项目 IAM 管理员在项目命名空间中向您授予 Project Cortex Prometheus Viewer 角色。
下表总结了 PA persona 的 Role 要求。
| 角色 | 对象 | 集群 | 角色 | 命名空间 | 群组/用户 | 配置 |
|---|---|---|---|---|---|---|
| PA | grafana | 组织管理员 | project-grafana-viewer |
platform-obs | 群组 | 1 |
| PA | Cortex | 组织管理员 | project-cortex-prometheus-viewer |
platform-obs | 群组 | 2 |
| PA | grafana | 组织管理员 | project-grafana-viewer |
platform-obs | 用户 | 3 |
| PA | Cortex | 组织管理员 | project-cortex-prometheus-viewer |
platform-obs | 用户 | 4 |
相应地替换以下变量:
| 变量 | 说明 |
|---|---|
KUBECONFIG |
您需要包含 NAMESPACE 的特定集群的 kubeconfig,此 RoleBinding 将应用于该集群。 |
RULE_NAME |
相应命名空间内此 RoleBinding 资源的唯一名称。例如 io-root-cortex-prometheus-viewer。 |
NAMESPACE |
将创建和应用此 RoleBinding 的 Kubernetes 命名空间。在上表中查找 Namespace 列。 |
EMAIL_ADDRESS |
被授予角色的用户的标识符。这通常是电子邮件地址。例如 infrastructure-operator@example.com。 |
ROLE |
包含您要向用户授予的权限的 Role 的名称。查找上表中提供的角色 |
GROUP_NAME |
包含您要向用户授予的权限的 Role 的名称。例如 io-group。 |
ZONE |
可用区的名称 |
配置 1
此配置适用于 PA 角色,以 org-admin 集群中的 grafana 对象为目标。它向 Group 授予 platform-obs 命名空间内的 project-grafana-viewer 角色。
Kubectl 命令
以下是通用命令格式:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-grafana-viewer示例:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --group=my-team --namespace=platform-obsIAC 文件路径
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>YAML 文件
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
配置 2
此配置适用于 PA 角色,以 org-admin 集群中的 cortex 对象为目标。它向 Group 授予 platform-obs 命名空间内的 project-cortex-prometheus-viewer 角色。
Kubectl 命令
以下是通用命令格式:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-cortex-prometheus-viewer示例:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --group=my-team --namespace=platform-obsIAC 文件路径
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>YAML 文件
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
配置 3
此配置适用于 PA 角色,以 org-admin 集群中的 grafana 对象为目标。它向 User 授予 platform-obs 命名空间内的 project-grafana-viewer 角色。
Kubectl 命令
以下是通用命令格式:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-grafana-viewer示例:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --user=my-email@example.com --namespace=platform-obsIAC 文件路径
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>YAML 文件
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
配置 4
此配置适用于 PA 角色,以 org-admin 集群中的 cortex 对象为目标。它向 User 授予 platform-obs 命名空间内的 project-cortex-prometheus-viewer 角色。
Kubectl 命令
以下是通用命令格式:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-cortex-prometheus-viewer示例:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --user=my-email@example.com --namespace=platform-obsIAC 文件路径
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>YAML 文件
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
如需详细了解这些角色,请参阅准备 IAM 权限。
获取和过滤指标
选择以下方法之一,以构建查询、直观呈现趋势并过滤项目工作负载中的指标:
Grafana 信息中心
本部分介绍如何使用 Grafana 信息中心访问指标。
确定 Grafana 端点
以下网址是您项目的 Grafana 实例的端点:
https://GDC_URL/PROJECT_NAMESPACE/grafana
替换以下内容:
GDC_URL:您组织在 GDC 中的网址。PROJECT_NAMESPACE:您的项目命名空间。例如,组织
org-1中项目platform-obs的 Grafana 端点为https://org-1/platform-obs/grafana。
在 Grafana 界面中查看指标
在 Grafana 界面中检索指标:
- 在 GDC 控制台中,选择您的项目。
- 在导航菜单中,依次选择操作 > 监控。
点击 View all in Grafana(在 Grafana 中查看全部)。
系统会打开一个新页面,其中显示 Grafana 端点和界面。
在界面上,依次点击导航菜单中的探索 探索,打开探索页面。
从探索栏中的菜单中,根据您的数据源类型选择一个数据源以检索指标:
单可用区 universe:选择 Prometheus 以显示 universe 中单个可用区的指标。
多地区数据宇宙:Grafana 可以连接到不同地区并显示跨地区数据。选择指标 ZONE_NAME,以显示您所在宇宙中任何可用区的指标,无论您登录的是哪个可用区。
此外,如需在单个信息中心内显示跨可用区的数据可视化图表,并向查询中添加多个可用区,请选择混合作为数据源。
输入查询内容,以使用 PromQL(Prometheus 查询语言)表达式搜索指标。您可以通过以下任一方式执行此步骤:
- 从指标和标签过滤条件菜单中为查询选择指标和标签。 点击添加图标 添加,即可向查询中添加更多标签。然后,点击运行查询。
- 直接在指标文本字段中输入查询,然后按 Shift+Enter 运行查询。
该页面会显示与您的查询匹配的指标。
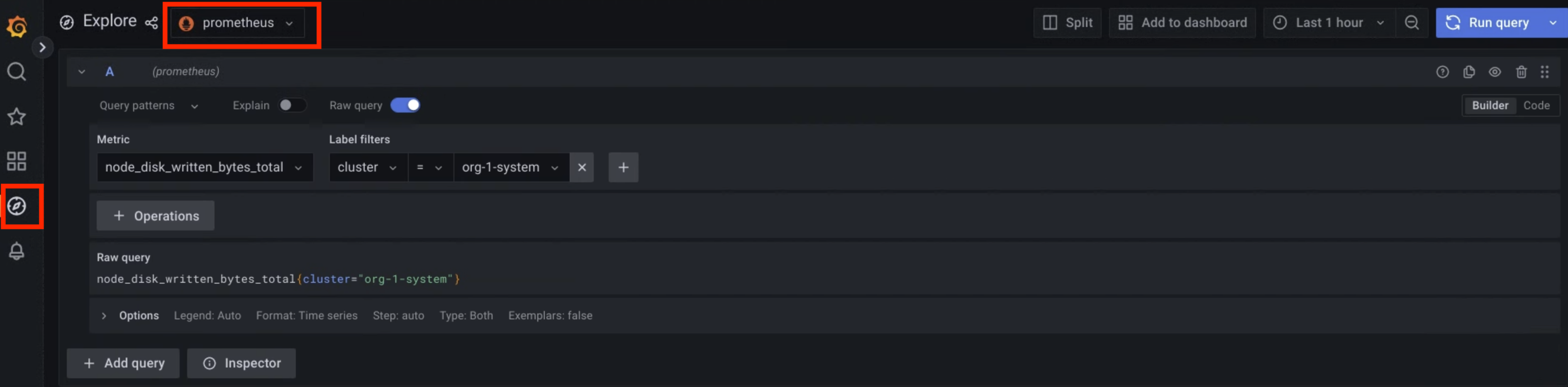
图 1. 用于从 Grafana 界面查询指标的菜单选项。
在图 1 中,Prometheus 选项会显示一个界面,您可以在其中构建从 Grafana 检索指标的查询。
如需查看可用于查询指标的标签的值示例,请参阅查询和标签示例。
Cortex 端点 - 单个可用区
本部分介绍如何使用 Cortex 访问指标。
确定 Cortex 端点
以下网址是您项目的 Cortex 实例的端点:
https://GDC_URL/PROJECT_NAMESPACE/cortex/prometheus/
替换以下内容:
GDC_URL:您组织在 GDC 中的网址。PROJECT_NAMESPACE:您的项目命名空间。例如,
org-1组织中platform-obs项目的 Cortex 端点为https://org-1/platform-obs/cortex/prometheus/。
对 curl 请求进行身份验证
- 下载并安装 gdcloud CLI。
设置 gdcloud
core/organization_console_url属性:gdcloud config set core/organization_console_url https://GDC_URL-
gdcloud auth login 使用您的用户名和密码进行身份验证并登录。
登录成功后,您可以通过
gdcloud auth print-identity-token命令在 curl 请求中使用授权标头。如需了解详情,请参阅 gdcloud auth。
调用 Cortex 端点
完成以下步骤,以使用 curl 工具访问 Cortex 端点:
- 对
curl请求进行身份验证。 使用
curl调用 Cortex 端点,并使用查询 HTTP API 格式扩展网址以查询指标。以下是
curl请求的示例:curl https://GDC_URL/PROJECT_NAME/cortex/prometheus/api/v1/query?query=my_metric{cluster="my-cluster"}&time=2015-07-01T20:10:51.781Z \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"您会获得以下命令输出。API 响应采用 JSON 格式。
Cortex 端点 - 多可用区
本部分介绍如何使用 Cortex 访问指标。
确定 Cortex 端点
以下网址是项目的 Cortex 实例的端点,用于多可用区查询:
https://GDC_URL/PROJECT_NAMESPACE/cortex/metrics
替换以下内容:
GDC_URL:您组织在 GDC 中的网址。- 组织 1、可用区 1 的示例:
console.org-1.zone1.google.gdch.test - 替换应用的组织和地区。
- 组织 1、可用区 1 的示例:
PROJECT_NAMESPACE:您的项目命名空间。例如,
org-1组织中project-1项目的 Cortex 端点为https://console.org-1.zone1.google.gdch.test/project-1/cortex/metrics.。
对 curl 请求进行身份验证
- 下载并安装 gdcloud CLI。
设置 gdcloud
core/organization_console_url属性:gdcloud config set core/organization_console_url https://GDC_URL-
gdcloud auth login 使用您的用户名和密码进行身份验证并登录。
登录成功后,您可以通过
gdcloud auth print-identity-token命令在 curl 请求中使用授权标头。如需了解详情,请参阅 gdcloud auth。
调用 Cortex 端点
完成以下步骤,以使用 curl 工具访问 Cortex 端点:
- 对
curl请求进行身份验证。 - 使用
curl调用 Cortex 端点,并使用查询 HTTP API 格式扩展网址以查询指标。 除了 Prometheus 网址查询参数之外,还添加了位置参数,以提供要查询的可用区列表。 - location={string}:以
|分隔的可用区列表 - 如果未提供,查询将在所有可用区中执行。以下是
curl POST请求的示例:curl POST \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range" \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'query=pod_cpu_usage_total' \ --data-urlencode 'start=2025-07-21T16:00:00Z' \ --data-urlencode 'end=2025-07-21T16:15:00Z' \ --data-urlencode 'step=60s' \ --data-urlencode 'location=zone1|zone2' \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"以下是
curl GET请求的示例:curl -X GET \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range?query=pod_cpu_usage_total&start=2025-07-21T16:00:00Z&end=2025-07-21T16:15:00Z&step=1s&location=zone1|zone2" \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"您将获得以下输出结果。API 响应采用 JSON 格式。
示例查询和标签
您可以使用指标名称和标签的键值对查询指标。PromQL 查询的语法如下:
metric_name{label_one="value", label_two="value"}
借助标签,您可以区分指标的特征。这样一来,容器作者就可以让其工作负载生成指标,并添加用于过滤这些指标的标记。
例如,您可以设置一个 api_http_requests_total 指标来统计收到的 HTTP 请求数。然后,您可以为此指标添加 request_method 标签,该标签可采用 POST、GET 或 PUT 值。因此,您需要为可能收到的每种请求类型创建三个指标流。在这种情况下,如需查找 HTTP GET 请求的数量,请运行以下查询:
api_http_requests_total{request_method="GET"}
如需详细了解指标和标签,请参阅指标和标签命名。
以下是 MonitoringTarget 自定义资源添加的一些默认标签。您可以使用这些默认标签来查询指标:
_gdch_service:服务的简称。cluster:集群的名称。container_name:Pod 中容器的名称。namespace_name:您的项目命名空间。pod_name:Pod 名称前缀。
下表介绍了 Prometheus 自动添加的标签:
| 指标标签 | 说明 |
|---|---|
job |
用于收集指标的抓取作业的内部名称。由 MonitoringTarget 自定义资源创建的作业的名称采用以下模式:obs-system/OBS_SHADOW_PROJECT_NAME/MONITORINGTARGET_NAME.MONITORINGTARGET_NAMESPACE/I/JI 和 J 是内部确定的唯一编号,用于避免名称冲突。 |
instance |
废弃服务的 $IP:$PORT。如果工作负载资源有多个副本,请使用此字段来区分它们。 |
以下代码示例展示了如何使用标签的键值对查询不同的指标,以查看在 Kubernetes 集群中收集的 CPU 使用情况:
pod_cpu_usage_total{cluster="CLUSTER_NAME"}
使用指标重新添加标签工具来添加被抓取的容器最初未公开的标签,并重命名生成的指标。您必须配置 MonitoringTarget 自定义资源,以便在收集的指标上添加标签。在自定义资源的 metricsRelabelings 字段中指定这些标签。如需了解详情,请参阅标签指标。
以下是从 Cortex 指标端点收到的响应示例:
{
"zone1": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.192.1.74:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-swzgq",
"zone_id": "zone1"
},
"values": [
[
1753261200,
"2.258621991"
],
[
1753261800,
"1.029301454"
]
]
}
]
}
},
"zone2": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.196.3.208:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-kchfv",
"zone_id": "zone2"
},
"values": [
[
1753261200,
"1.814027424"
],
[
1753261800,
"2.7767060260000003"
]
]
}
]
}
}
}
查询 HTTP API
格式概览
API 响应始终采用 JSON 格式。成功的请求始终会收到 2xx 状态代码。
对于无效请求,API 处理程序将返回 JSON 错误对象以及以下某个 HTTP 状态代码:
- 400 Bad Request:如果缺少必需参数或提供的必需参数不正确,则会返回此错误。
- 503 服务不可用:如果查询超出时间限制或被中止。
成功收集的所有数据都将包含在响应的“data”字段中。
JSON 响应信封格式如下:
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>",
// Only set if there were warnings while executing the request.
// There will still be data in the data field.
"warnings": ["<string>"],
// Only set if there were info-level annotations while executing the request.
"infos": ["<string>"]
}
即时查询
以下端点用于评估单个时间点的即时查询:
GET /api/v1/query
POST /api/v1/query
以下网址查询参数可用于 Prometheus 表达式查询:
query=<string>:Prometheus 表达式查询字符串。time=<rfc3339 | unix_timestamp>:可选的评估时间戳,指定为 RFC 3339 字符串或 Unix 时间戳。如果省略,则使用当前服务器时间。timeout=<duration>:可选的评估超时时间。默认值和上限均为 query.timeout 标志的值。limit=<number>:要返回的序列的可选数量上限。此函数会截断矩阵和向量的序列,但不会影响标量或字符串。值为 0 表示停用此限制。lookback_delta=<number>:一个可选参数,用于专门针对此查询替换回溯期。
如果省略时间参数,系统会使用当前服务器时间。
对于可能超出网址字符数限制的较大查询,您可以使用 POST 方法提交这些参数。确保请求正文采用网址编码,并将 Content-Type 标头设置为 application/x-www-form-urlencoded。
查询结果的数据部分采用以下格式:
{
"resultType": "matrix" | "vector" | "scalar" | "string",
"result": <value>
}
<value> 是指查询结果数据,其格式因 resultType 而异。
以下示例评估了 2015-07-01T20:10:51.781Z 时刻的表达式 up:
curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z'
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
]
}
}
范围查询
以下端点用于评估一段时间范围内的表达式查询:
GET /api/v1/query_range
POST /api/v1/query_range
以下网址查询参数可用于 Prometheus 表达式查询:
query=<string>:Prometheus 表达式查询字符串。start=<rfc3339 | unix_timestamp>:开始时间戳(含)。end=<rfc3339 | unix_timestamp>:结束时间戳(含)。step=<duration | float>:以时长格式或浮点秒数表示的查询分辨率步长。timeout=<duration>:可选的评估超时时间。默认值和上限均为 query.timeout 标志的值。limit=<number>:要返回的序列的可选数量上限。此函数会截断矩阵和向量的序列,但不会影响标量或字符串。值为 0 表示停用此限制。lookback_delta=<number>:一个可选参数,用于专门针对此查询替换回溯期。
对于可能超出网址字符数限制的较大查询,您可以使用 POST 方法提交这些参数。确保请求正文采用网址编码,并将 Content-Type 标头设置为 application/x-www-form-urlencoded。
查询结果的数据部分采用以下格式:
{
"resultType": "matrix",
"result": <value>
}
以下示例评估了 30 秒范围内的表达式 up,查询分辨率为 15 秒。
curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
指标和标签命名
指标命名准则
定义指标名称时,请考虑以下原则:
指标名称应包含单字词应用前缀,客户端库有时将其称为“命名空间”。此前缀用于标识指标所属的网域。对于应用专用指标,应用的名称通常用作前缀。
示例:
- prometheus_notifications_total(特定于 Prometheus 服务器)
- process_cpu_seconds_total(由许多客户端库导出)
- http_request_duration_seconds(适用于所有 HTTP 请求)
一个指标名称必须表示一个单位(例如,避免将秒与毫秒或秒与字节混用)。
指标名称应使用基本单位(例如秒、字节、米),而不是派生单位(例如毫秒、兆字节、千米)。
指标名称应包含复数单位后缀。对于累积计数,应使用后缀“total”,如果适用,还应使用单位后缀。
示例:
- http_request_duration_seconds
- node_memory_usage_bytes
- http_requests_total(用于表示无单位的累积计数)
- process_cpu_seconds_total(用于表示累计计数,带有单位)
- foobar_build_info(用于提供有关正在运行的二进制文件的元数据的伪指标)
指标名称可以对其组成部分进行排序,以便在按字典顺序排序时方便地进行分组,前提是遵循所有其他规则。相关指标通常会将共同的名称组成部分放在前面,以确保它们可以一起排序。
示例:
- prometheus_tsdb_head_truncations_closed_total
- prometheus_tsdb_head_truncations_established_total
- prometheus_tsdb_head_truncations_failed_total
- prometheus_tsdb_head_truncations_total
指标名称应在所有标签维度中始终表示相同的逻辑“被衡量对象”。
示例:
- 请求持续时间
- 数据传输字节数
- 以百分比表示的瞬时资源使用量
标签命名准则
在衡量某项事物时,请使用标签来区分其特征。例如:
- 对于 API HTTP 请求总数 (
api_http_requests_total),按操作类型(例如create、update、delete)区分(请求类型:operation="create|update|delete")。 - 对于以秒为单位的 API 请求时长 (
api_request_duration_seconds),按请求阶段进行区分,例如extract、transform、load(请求阶段:stage="extract|transform|load")。
避免在指标名称本身中包含标签名称,因为这会造成冗余,并且如果这些标签日后进行汇总,可能会导致混淆。