
Depois de recolher métricas das cargas de trabalho implementadas no Google Distributed Cloud (GDC) air-gapped, pode começar a analisá-las. Para analisar as métricas, pode visualizá-las e filtrá-las em painéis de controlo do Grafana informativos ou aceder diretamente a partir do Cortex através da ferramenta curl para scripting flexível e automatização.
Esta página fornece instruções detalhadas sobre como consultar e visualizar as suas métricas através da interface do utilizador do Grafana e da ferramenta curl para o ponto final do Cortex, de modo a obter estatísticas sobre o desempenho da sua carga de trabalho.
Pode aceder às suas métricas através de um dos dois métodos seguintes:
- Painéis de controlo do Grafana: explore tendências e identifique anomalias com visualizações intuitivas de métricas importantes, como a utilização da CPU, o consumo de armazenamento e a atividade de rede. O Grafana oferece uma interface intuitiva para filtrar e analisar os dados da carga de trabalho em painéis de controlo.
- Ponto final do Cortex: para exemplos de utilização mais avançados, consulte diretamente a instância do Cortex do seu projeto através da ferramenta
curlnuma linha de comandos. O Cortex armazena as métricas do Prometheus do seu projeto e fornece um ponto final HTTP para acesso programático. Este acesso permite-lhe exportar dados, automatizar tarefas e criar integrações personalizadas.
Antes de começar
Para receber as autorizações necessárias para consultar e visualizar métricas nos painéis de controlo do Grafana, peça ao administrador de IAM da organização ou ao administrador de IAM do projeto que lhe conceda uma das funções predefinidas de visualizador do Grafana da organização ou visualizador do Grafana do projeto. Consoante o nível de acesso e as autorizações de que precisa, pode obter funções do Grafana numa organização ou num projeto.
Em alternativa, para obter as autorizações necessárias para consultar métricas do ponto final do Cortex, peça ao administrador de IAM do projeto para lhe conceder a função de visualizador do Prometheus do Project Cortex no seu espaço de nomes do projeto.
A tabela seguinte resume os requisitos de Role para PA persona.
| Perfil | Objeto | Cluster | Função | Espaço de nomes | Grupo/utilizador | Configuração |
|---|---|---|---|---|---|---|
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Grupo | 1 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Grupo | 2 |
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Utilizador | 3 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Utilizador | 4 |
Substitua as seguintes variáveis adequadamente:
| Variável | Descrição |
|---|---|
KUBECONFIG |
Precisa do kubeconfig para o cluster específico que contém o NAMESPACE onde esta RoleBinding vai ser aplicada. |
RULE_NAME |
O nome exclusivo deste recurso RoleBinding no espaço de nomes. Por exemplo, io-root-cortex-prometheus-viewer. |
NAMESPACE |
O espaço de nomes do Kubernetes onde este RoleBinding vai ser criado e aplicado. Procure a coluna Namespace na tabela anterior. |
EMAIL_ADDRESS |
O identificador do utilizador ao qual está a ser concedida a função. Normalmente, trata-se de um endereço de email. Por exemplo, infrastructure-operator@example.com. |
ROLE |
O nome do Role que contém as autorizações que quer conceder ao utilizador. Procure as funções disponíveis na tabela anterior |
GROUP_NAME |
O nome do Role que contém as autorizações que quer conceder ao utilizador. Por exemplo, io-group. |
ZONE |
Nome da zona |
Configuração 1
Esta configuração destina-se à persona PA, segmentando o objeto grafana no cluster org-admin.
Concede a função project-grafana-viewer no espaço de nomes platform-obs a um Group.
Comando Kubectl
Este é o formato de comando genérico:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-grafana-viewerExemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --group=my-team --namespace=platform-obsCaminho do ficheiro IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>Ficheiro YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Configuração 2
Esta configuração destina-se à persona PA, segmentando o objeto cortex no cluster org-admin.
Concede a função project-cortex-prometheus-viewer no espaço de nomes platform-obs a um Group.
Comando Kubectl
Este é o formato de comando genérico:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-cortex-prometheus-viewerExemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --group=my-team --namespace=platform-obsCaminho do ficheiro IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>Ficheiro YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Configuração 3
Esta configuração destina-se à persona PA, segmentando o objeto grafana no cluster org-admin.
Concede a função project-grafana-viewer no espaço de nomes platform-obs a um User.
Comando Kubectl
Este é o formato de comando genérico:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-grafana-viewerExemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --user=my-email@example.com --namespace=platform-obsCaminho do ficheiro IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>Ficheiro YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Config 4
Esta configuração destina-se à persona PA, segmentando o objeto cortex no cluster org-admin.
Concede a função project-cortex-prometheus-viewer no espaço de nomes platform-obs a um User.
Comando Kubectl
Este é o formato de comando genérico:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-cortex-prometheus-viewerExemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --user=my-email@example.com --namespace=platform-obsCaminho do ficheiro IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>Ficheiro YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Para mais informações sobre estas funções, consulte o artigo Prepare as autorizações de IAM.
Obtenha e filtre as suas métricas
Selecione um dos seguintes métodos para criar consultas, visualizar tendências e filtrar métricas das cargas de trabalho do seu projeto:
Painéis de controlo do Grafana
Esta secção descreve como aceder às suas métricas através dos painéis de controlo do Grafana.
Identifique o seu ponto final do Grafana
O seguinte URL é o ponto final da instância do Grafana do seu projeto:
https://GDC_URL/PROJECT_NAMESPACE/grafana
Substitua o seguinte:
GDC_URL: o URL da sua organização no GDC.PROJECT_NAMESPACE: o espaço de nomes do seu projeto.Por exemplo, o ponto final do Grafana para o projeto
platform-obsna organizaçãoorg-1éhttps://org-1/platform-obs/grafana.
Veja métricas na interface do utilizador do Grafana
Recupere métricas na interface do utilizador do Grafana:
- Na consola do GDC, selecione o seu projeto.
- No menu de navegação, selecione Operações > Monitorização.
Clique em Ver tudo no Grafana.
É aberta uma nova página com o seu ponto final do Grafana e apresenta a interface do utilizador.
Na interface do utilizador, clique em explorar Explorar no menu de navegação para abrir a página Explorar.
No menu da barra Explorar, selecione uma origem de dados para obter métricas, de acordo com o tipo de universo:
Universos de zona única: selecione prometheus para apresentar métricas da zona única do seu universo.
Universos multizona: o Grafana pode ligar-se a diferentes zonas e mostrar dados entre zonas. Selecione Métricas ZONE_NAME para apresentar métricas de qualquer zona do seu universo, independentemente da zona em que tem sessão iniciada.
Além disso, para ter visualizações de dados entre zonas num único painel de controlo e adicionar várias zonas à sua consulta, selecione Misto como origem de dados.
Introduza uma consulta para pesquisar métricas através de expressões PromQL (Prometheus Query Language). Pode concluir este passo de uma das seguintes formas:
- Selecione uma métrica e uma etiqueta para a sua consulta nos menus Métrica e Filtros de etiquetas. Clique em adicionar Adicionar para adicionar mais etiquetas à sua consulta. Em seguida, clique em Executar consulta.
- Introduza a consulta diretamente no campo de texto Métricas e prima Shift+Enter para executar a consulta.
A página apresenta as métricas que correspondem à sua consulta.
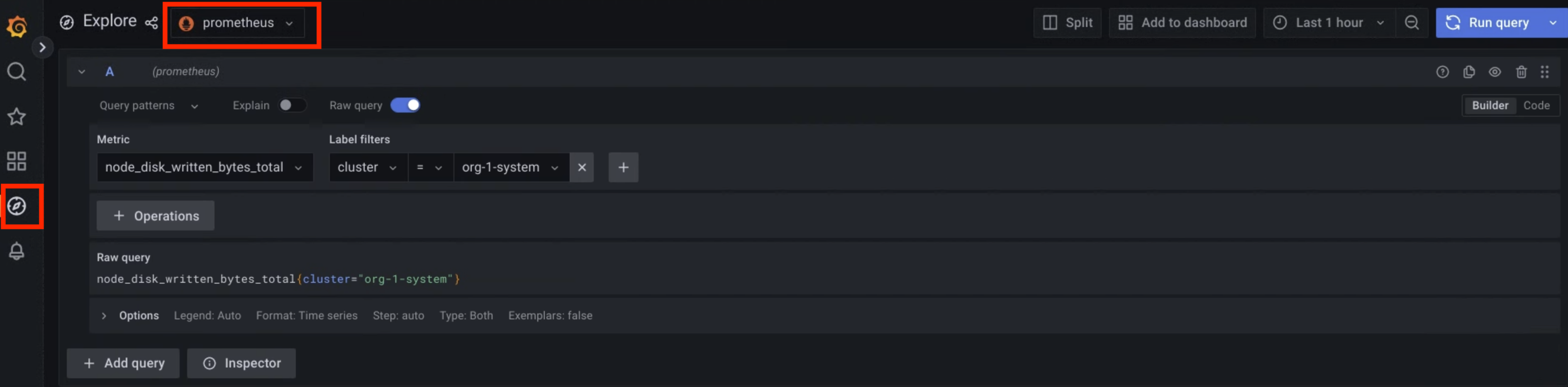
Figura 1. Opção de menu para consultar métricas a partir da interface do utilizador do Grafana.
Na figura 1, a opção prometheus apresenta a interface que lhe permite criar consultas a partir do Grafana para obter métricas.
Para ver exemplos de valores de etiquetas que pode usar para consultar métricas, consulte o artigo Consultas e etiquetas de exemplo.
Ponto final do Cortex – zona única
Esta secção descreve como aceder às suas métricas através do Cortex.
Identifique o seu ponto final do Cortex
O seguinte URL é o ponto final da instância do Cortex do seu projeto:
https://GDC_URL/PROJECT_NAMESPACE/cortex/prometheus/
Substitua o seguinte:
GDC_URL: o URL da sua organização no GDC.PROJECT_NAMESPACE: o espaço de nomes do seu projeto.Por exemplo, o ponto final do Cortex para o projeto
platform-obsna organizaçãoorg-1éhttps://org-1/platform-obs/cortex/prometheus/.
Autentique o pedido curl
- Transfira e instale a CLI gcloud.
Defina a propriedade
core/organization_console_urlgdcloud:gdcloud config set core/organization_console_url https://GDC_URLInicie sessão com o Fornecedor de identidade configurado:
gdcloud auth loginUse o seu nome de utilizador e palavra-passe para autenticar e iniciar sessão.
Quando o início de sessão for bem-sucedido, pode usar o cabeçalho de autorização no seu pedido curl através do comando
gdcloud auth print-identity-token. Para mais informações, consulte gdcloud auth.
Chame o ponto final do Cortex
Conclua os passos seguintes para aceder ao ponto final do Cortex através da ferramenta curl:
- Autentique o
curlpedido. Use
curlpara chamar o ponto final da Cortex e expanda o URL com o formato da API HTTP de consulta para consultar métricas.Segue-se um exemplo de um pedido
curl:curl https://GDC_URL/PROJECT_NAME/cortex/prometheus/api/v1/query?query=my_metric{cluster="my-cluster"}&time=2015-07-01T20:10:51.781Z \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Obtém o resultado após o comando. A resposta da API está no formato JSON.
Ponto final do Cortex – várias zonas
Esta secção descreve como aceder às suas métricas através do Cortex.
Identifique o seu ponto final do Cortex
O URL seguinte é o ponto final da instância do Cortex do seu projeto para a consulta multizonal:
https://GDC_URL/PROJECT_NAMESPACE/cortex/metrics
Substitua o seguinte:
GDC_URL: o URL da sua organização no GDC.- Exemplo para org-1, zone1:
console.org-1.zone1.google.gdch.test - Substitua a organização e a zona da sua aplicação.
- Exemplo para org-1, zone1:
PROJECT_NAMESPACE: o espaço de nomes do seu projeto.Por exemplo, o ponto final do Cortex para o projeto
project-1na organizaçãoorg-1éhttps://console.org-1.zone1.google.gdch.test/project-1/cortex/metrics..
Autentique o pedido curl
- Transfira e instale a CLI gcloud.
Defina a propriedade
core/organization_console_urlgdcloud:gdcloud config set core/organization_console_url https://GDC_URLInicie sessão com o Fornecedor de identidade configurado:
gdcloud auth loginUse o seu nome de utilizador e palavra-passe para autenticar e iniciar sessão.
Quando o início de sessão for bem-sucedido, pode usar o cabeçalho de autorização no seu pedido curl através do comando
gdcloud auth print-identity-token. Para mais informações, consulte gdcloud auth.
Chame o ponto final do Cortex
Conclua os passos seguintes para aceder ao ponto final do Cortex através da ferramenta curl:
- Autentique o
curlpedido. - Use
curlpara chamar o ponto final da Cortex e expanda o URL com o formato da API HTTP de consulta para consultar métricas. Além dos parâmetros de consulta de URL do Prometheus, inclua o parâmetro de localização para fornecer uma lista de zonas para consultar. - location={string}: lista de zonas separadas por
|- Se não for fornecida, a consulta é executada em todas as zonas disponíveis.Segue-se um exemplo de um pedido
curl POST:curl POST \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range" \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'query=pod_cpu_usage_total' \ --data-urlencode 'start=2025-07-21T16:00:00Z' \ --data-urlencode 'end=2025-07-21T16:15:00Z' \ --data-urlencode 'step=60s' \ --data-urlencode 'location=zone1|zone2' \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Segue-se um exemplo de um pedido
curl GET:curl -X GET \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range?query=pod_cpu_usage_total&start=2025-07-21T16:00:00Z&end=2025-07-21T16:15:00Z&step=1s&location=zone1|zone2" \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Segue o comando para obter o resultado. A resposta da API está no formato JSON.
Consultas e etiquetas de exemplo
Pode consultar métricas através do nome da métrica e de pares de chave-valor para etiquetas. Uma consulta PromQL tem a seguinte sintaxe:
metric_name{label_one="value", label_two="value"}
As etiquetas permitem-lhe diferenciar as caraterísticas de uma métrica. Desta forma, os autores dos contentores fazem com que as respetivas cargas de trabalho gerem métricas e adicionem etiquetas para filtrar essas métricas.
Por exemplo, pode ter uma métrica api_http_requests_total para contabilizar o número de pedidos HTTP recebidos. Em seguida, pode adicionar uma etiqueta request_method a esta métrica, que assume um valor POST, GET ou PUT. Consequentemente, cria três streams de métricas para cada tipo de pedido que possa receber. Neste caso, para encontrar o número de pedidos HTTP GET, execute a seguinte consulta:
api_http_requests_total{request_method="GET"}
Consulte o artigo Nomenclatura de métricas e etiquetas para mais informações sobre métricas e etiquetas.
Seguem-se algumas das etiquetas predefinidas que o recurso personalizado MonitoringTarget adiciona. Pode usar estas etiquetas predefinidas para consultar métricas:
_gdch_service: o diminutivo do serviço.cluster: o nome do cluster.container_name: o nome do contentor num agrupamento.namespace_name: o espaço de nomes do seu projeto.pod_name: o prefixo do nome do agrupamento.
A tabela seguinte descreve as etiquetas que o Prometheus adiciona automaticamente:
| Etiqueta da métrica | Descrição |
|---|---|
job |
O nome interno da tarefa de recolha de dados usada para recolher a métrica. As tarefas
criadas pelo recurso personalizado MonitoringTarget têm um nome
com o seguinte padrão:obs-system/OBS_SHADOW_PROJECT_NAME/MONITORINGTARGET_NAME.MONITORINGTARGET_NAMESPACE/I/JI e J são números únicos determinados internamente
para evitar conflitos de nomes. |
instance |
O $IP:$PORT do serviço desativado. Se um recurso de carga de trabalho tiver várias réplicas, use este campo para as diferenciar. |
O seguinte exemplo de código mostra a utilização de pares de chave-valor para etiquetas para consultar diferentes métricas para ver a utilização da CPU recolhida num cluster do Kubernetes:
pod_cpu_usage_total{cluster="CLUSTER_NAME"}
Use a ferramenta de reetiquetagem de métricas para adicionar etiquetas não expostas inicialmente pelos contentores
eliminados e mudar o nome das métricas produzidas. Tem de configurar o recurso personalizado MonitoringTarget para adicionar etiquetas às métricas que recolhe.
Especifique essas etiquetas no campo metricsRelabelings do recurso personalizado.
Para mais informações, consulte o artigo
Métricas de etiquetas.
Segue-se um exemplo de uma resposta recebida de um ponto final de métricas do Cortex:
{
"zone1": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.192.1.74:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-swzgq",
"zone_id": "zone1"
},
"values": [
[
1753261200,
"2.258621991"
],
[
1753261800,
"1.029301454"
]
]
}
]
}
},
"zone2": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.196.3.208:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-kchfv",
"zone_id": "zone2"
},
"values": [
[
1753261200,
"1.814027424"
],
[
1753261800,
"2.7767060260000003"
]
]
}
]
}
}
}
Consultar a API HTTP
Vista geral do formato
As respostas da API são formatadas de forma consistente em JSON. Os pedidos com êxito recebem sempre um código de estado 2xx.
Para pedidos inválidos, os controladores da API devolvem um objeto de erro JSON juntamente com um dos seguintes códigos de estado HTTP:
- 400 Pedido errado: se faltarem parâmetros essenciais ou se forem fornecidos incorretamente.
- 503 Serviço indisponível: se as consultas excederem o respetivo limite de tempo ou forem anuladas.
Todos os dados recolhidos com êxito são incluídos no campo "data" da resposta.
O formato do envelope de resposta JSON é o seguinte:
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>",
// Only set if there were warnings while executing the request.
// There will still be data in the data field.
"warnings": ["<string>"],
// Only set if there were info-level annotations while executing the request.
"infos": ["<string>"]
}
Consultas instantâneas
O seguinte ponto final avalia uma consulta instantânea num único ponto no tempo:
GET /api/v1/query
POST /api/v1/query
Os seguintes parâmetros de consulta de URL estão disponíveis para consultas de expressões Prometheus:
query=<string>: a sequência de carateres de consulta da expressão Prometheus.time=<rfc3339 | unix_timestamp>: uma indicação de tempo de avaliação opcional, especificada como uma string RFC 3339 ou uma indicação de tempo Unix. Se for omitido, é usado o tempo atual do servidor.timeout=<duration>: um limite de tempo de avaliação opcional. O valor predefinido é o valor do sinalizador query.timeout e está limitado por este.limit=<number>: um número máximo opcional de séries a devolver. Isto trunca as séries para matrizes e vetores, mas não afeta os escalares nem as strings. Um valor de 0 desativa este limite.lookback_delta=<number>: um parâmetro opcional para substituir o período de retrospetiva especificamente para esta consulta.
A hora atual do servidor é usada se o parâmetro de tempo for omitido.
Para consultas maiores que possam exceder os limites de carateres do URL, pode enviar estes parâmetros através do método POST. Certifique-se de que o corpo do pedido está codificado por URL e que o cabeçalho Content-Type está definido como application/x-www-form-urlencoded.
A secção de dados do resultado da consulta tem o seguinte formato:
{
"resultType": "matrix" | "vector" | "scalar" | "string",
"result": <value>
}
<value> refere-se aos dados dos resultados da consulta, que têm formatos variáveis consoante o resultType.
O exemplo seguinte avalia a expressão até à hora 2015-07-01T20:10:51.781Z:
curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z'
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
]
}
}
Consultas de intervalo
O seguinte ponto final avalia uma consulta de expressão num intervalo de tempo:
GET /api/v1/query_range
POST /api/v1/query_range
Os seguintes parâmetros de consulta de URL estão disponíveis para consultas de expressões Prometheus:
query=<string>: a sequência de carateres de consulta da expressão Prometheus.start=<rfc3339 | unix_timestamp>: indicação de tempo de início, inclusive.end=<rfc3339 | unix_timestamp>: indicação de tempo de fim, inclusive.step=<duration | float>: largura do passo de resolução da consulta no formato de duração ou número de segundos flutuante.timeout=<duration>: um limite de tempo de avaliação opcional. O valor predefinido é o valor do sinalizador query.timeout e está limitado por este.limit=<number>: um número máximo opcional de séries a devolver. Isto trunca as séries para matrizes e vetores, mas não afeta os escalares nem as strings. Um valor de 0 desativa este limite.lookback_delta=<number>: um parâmetro opcional para substituir o período de retrospetiva especificamente para esta consulta.
Para consultas maiores que possam exceder os limites de carateres do URL, pode enviar estes parâmetros através do método POST. Certifique-se de que o corpo do pedido está codificado por URL e que o cabeçalho Content-Type está definido como application/x-www-form-urlencoded.
A secção de dados do resultado da consulta tem o seguinte formato:
{
"resultType": "matrix",
"result": <value>
}
O exemplo seguinte avalia a expressão up num intervalo de 30 segundos com uma resolução de consulta de 15 segundos.
curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
Nomenclatura de métricas e etiquetas
Diretrizes de nomenclatura de métricas
Ao definir nomes de métricas, tenha em consideração os seguintes princípios:
Um nome de métrica DEVE incluir um prefixo de aplicação de uma única palavra, que as bibliotecas de cliente referem por vezes como um "espaço de nomes". Este prefixo identifica o domínio ao qual a métrica pertence. Para métricas específicas da aplicação, o nome da aplicação é normalmente usado como prefixo.
Exemplos:
- prometheus_notifications_total (específico do servidor Prometheus)
- process_cpu_seconds_total (exportado por muitas bibliotecas de cliente)
- http_request_duration_seconds (para todos os pedidos HTTP)
Um nome de métrica TEM de representar uma única unidade (por exemplo, evite misturar segundos com milissegundos ou segundos com bytes).
Um nome de métrica DEVE usar unidades base (por exemplo, segundos, bytes, metros) em vez de unidades derivadas (por exemplo, milissegundos, megabytes, quilómetros).
Um nome de métrica DEVE incluir um sufixo de unidade no plural. Para contagens de acumulação, deve usar o sufixo "total" além do sufixo da unidade, se aplicável.
Exemplos:
- http_request_duration_seconds
- node_memory_usage_bytes
- http_requests_total (para uma contagem acumulada sem unidade)
- process_cpu_seconds_total (para uma contagem acumulada com unidade)
- foobar_build_info (para uma pseudométrica que fornece metadados sobre o ficheiro binário em execução)
Um nome de métrica PODE ordenar os respetivos componentes para facilitar o agrupamento conveniente quando ordenado lexicograficamente, desde que todas as outras regras sejam seguidas. As métricas relacionadas têm frequentemente componentes de nomes comuns colocados em primeiro lugar para garantir que são ordenadas em conjunto.
Exemplos:
- prometheus_tsdb_head_truncations_closed_total
- prometheus_tsdb_head_truncations_established_total
- prometheus_tsdb_head_truncations_failed_total
- prometheus_tsdb_head_truncations_total
Um nome de métrica DEVE representar consistentemente a mesma "coisa a ser medida" lógica em todas as dimensões de etiquetas.
Exemplos:
- duração do pedido
- bytes de transferência de dados
- utilização instantânea de recursos como percentagem
Diretrizes de nomenclatura de etiquetas
Quando mede algo, use etiquetas para distinguir as respetivas caraterísticas. Por exemplo:
- Para o total de pedidos HTTP da API (
api_http_requests_total), diferencie por tipo de operação, por exemplo,create,update,delete(tipos de pedidos:operation="create|update|delete"). - Para a duração do pedido da API em segundos (
api_request_duration_seconds), diferencie por fase do pedido, por exemplo,extract,transform,load(fases do pedido:stage="extract|transform|load").
Evite incluir nomes de etiquetas no próprio nome da métrica, uma vez que isto cria redundância e pode gerar confusão se essas etiquetas forem agregadas posteriormente.