
Una vez que hayas recogido métricas de las cargas de trabajo implementadas en Google Distributed Cloud (GDC) air-gapped, podrás empezar a analizarlas. Para analizar las métricas, puedes visualizarlas y filtrarlas en paneles de control de Grafana informativos o acceder a ellas directamente desde Cortex mediante la herramienta curl para disfrutar de flexibilidad en las secuencias de comandos y la automatización.
En esta página se proporcionan instrucciones detalladas sobre cómo consultar y visualizar sus métricas mediante la interfaz de usuario de Grafana y la herramienta curl para el endpoint de Cortex, con el fin de obtener información valiosa sobre el rendimiento de su carga de trabajo.
Puedes acceder a tus métricas de dos formas:
- Paneles de Grafana: descubre tendencias e identifica anomalías con visualizaciones intuitivas de métricas clave, como la utilización de la CPU, el consumo de almacenamiento y la actividad de la red. Grafana proporciona una interfaz fácil de usar para filtrar y analizar los datos de tu carga de trabajo en paneles de control.
- Endpoint de Cortex: para casos prácticos más avanzados, consulta directamente la instancia de Cortex de tu proyecto mediante la herramienta
curlen una línea de comandos. Cortex almacena las métricas de Prometheus de tu proyecto y proporciona un endpoint HTTP para el acceso programático. Este acceso te permite exportar datos, automatizar tareas y crear integraciones personalizadas.
Antes de empezar
Para obtener los permisos que necesitas para consultar y visualizar métricas en los paneles de Grafana, pide al administrador de gestión de identidades y accesos de tu organización o proyecto que te conceda uno de los roles predefinidos de lector de Grafana de la organización o del proyecto. En función del nivel de acceso y de los permisos que necesites, puedes obtener roles de Grafana en una organización o en un proyecto.
También puedes pedir al administrador de gestión de identidades y accesos de tu proyecto que te conceda el rol Lector de Prometheus de Cortex del proyecto en el espacio de nombres de tu proyecto para obtener los permisos que necesitas para consultar métricas del endpoint de Cortex.
En la siguiente tabla se resumen los requisitos de Role para PA persona.
| Perfil ficticio | Objeto | Clúster | Rol | Espacio de nombres | Grupo o usuario | Configuración |
|---|---|---|---|---|---|---|
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Grupo | 1 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Grupo | 2 |
| PA | grafana | org-admin | project-grafana-viewer |
platform-obs | Usuario | 3 |
| PA | cortex | org-admin | project-cortex-prometheus-viewer |
platform-obs | Usuario | 4 |
Sustituye las siguientes variables por los valores correspondientes:
| Variable | Descripción |
|---|---|
KUBECONFIG |
Necesitarás el archivo kubeconfig del clúster específico que contenga el NAMESPACE en el que se aplicará este RoleBinding. |
RULE_NAME |
Nombre único de este recurso RoleBinding en el espacio de nombres. Por ejemplo, io-root-cortex-prometheus-viewer. |
NAMESPACE |
El espacio de nombres de Kubernetes donde se creará y se aplicará este RoleBinding. Busca la columna Namespace en la tabla anterior. |
EMAIL_ADDRESS |
Identificador del usuario al que se le concede el rol. A menudo, se trata de una dirección de correo electrónico. Por ejemplo, infrastructure-operator@example.com. |
ROLE |
Nombre del Role que contiene los permisos que quieres conceder al usuario. Busca los roles disponibles en la tabla anterior |
GROUP_NAME |
Nombre del Role que contiene los permisos que quieres conceder al usuario. Por ejemplo, io-group. |
ZONE |
Nombre de la zona |
Configuración 1
Esta configuración es para el perfil PA, que se dirige al objeto grafana del clúster org-admin.
Asigna el rol project-grafana-viewer en el espacio de nombres platform-obs a un Group.
Comando kubectl
Este es el formato genérico de los comandos:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-grafana-viewerEjemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --group=my-team --namespace=platform-obsRuta de archivo IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>Archivo YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Configuración 2
Esta configuración es para el perfil PA, que se dirige al objeto cortex del clúster org-admin.
Asigna el rol project-cortex-prometheus-viewer en el espacio de nombres platform-obs a un Group.
Comando kubectl
Este es el formato genérico de los comandos:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --group=`GROUP_NAME` --role=project-cortex-prometheus-viewerEjemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --group=my-team --namespace=platform-obsRuta de archivo IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`GROUP_NAME`/<YAML_FILE>Archivo YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: Group name: GROUP_NAME apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Configuración 3
Esta configuración es para el perfil PA, que se dirige al objeto grafana del clúster org-admin.
Asigna el rol project-grafana-viewer en el espacio de nombres platform-obs a un User.
Comando kubectl
Este es el formato genérico de los comandos:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-grafana-viewerEjemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-grafana-viewers-binding --role=project-grafana-viewer --user=my-email@example.com --namespace=platform-obsRuta de archivo IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>Archivo YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-grafana-viewer apiGroup: rbac.authorization.k8s.io
Configuración 4
Esta configuración es para el perfil PA, que se dirige al objeto cortex del clúster org-admin.
Asigna el rol project-cortex-prometheus-viewer en el espacio de nombres platform-obs a un User.
Comando kubectl
Este es el formato genérico de los comandos:
kubectl --kubeconfig `KUBECONFIG` create rolebinding `RULE_NAME` -n platform-obs --user=`EMAIL_ADDRESS` --role=project-cortex-prometheus-viewerEjemplo:
kubectl --kubeconfig <path-to-kubeconfig> create rolebinding project-cortex-prometheus-viewer-binding --role=project-cortex-prometheus-viewer --user=my-email@example.com --namespace=platform-obsRuta de archivo IAC
/infrastructure/zonal/zones/`ZONE`/org-admin/rolebindings/`EMAIL_ADDRESS`/<YAML_FILE>Archivo YAML
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: RULE_NAME namespace: platform-obs subjects: - kind: User name: EMAIL_ADDRESS apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: project-cortex-prometheus-viewer apiGroup: rbac.authorization.k8s.io
Para obtener más información sobre estos roles, consulta Preparar permisos de gestión de identidades y accesos.
Obtener y filtrar métricas
Selecciona uno de los siguientes métodos para crear consultas, visualizar tendencias y filtrar métricas de las cargas de trabajo de tu proyecto:
Paneles de control de Grafana
En esta sección se describe cómo acceder a sus métricas mediante los paneles de control de Grafana.
Identificar el endpoint de Grafana
La siguiente URL es el endpoint de la instancia de Grafana de tu proyecto:
https://GDC_URL/PROJECT_NAMESPACE/grafana
Haz los cambios siguientes:
GDC_URL: la URL de tu organización en GDC.PROJECT_NAMESPACE: el espacio de nombres de tu proyecto.Por ejemplo, el endpoint de Grafana del proyecto
platform-obsde la organizaciónorg-1eshttps://org-1/platform-obs/grafana.
Ver métricas en la interfaz de usuario de Grafana
Recupera métricas en la interfaz de usuario de Grafana:
- En la consola de GDC, selecciona tu proyecto.
- En el menú de navegación, selecciona Operaciones > Monitorización.
Haz clic en Ver todo en Grafana.
Se abrirá una página con su endpoint de Grafana y se mostrará la interfaz de usuario.
En la interfaz de usuario, haz clic en Explorar Explorar en el menú de navegación para abrir la página Explorar.
En el menú de la barra Explorar, seleccione una fuente de datos para obtener métricas según el tipo de universo:
Universos de una sola zona: selecciona prometheus para mostrar las métricas de la zona única de tu universo.
Universos multizona: Grafana puede conectarse a diferentes zonas y mostrar datos de varias zonas. Seleccione Métricas ZONE_NAME para ver las métricas de cualquier zona de su universo, independientemente de la zona en la que haya iniciado sesión.
Además, para tener visualizaciones de datos entre zonas en un solo panel de control y añadir varias zonas a tu consulta, selecciona Mixta como fuente de datos.
Introduce una consulta para buscar métricas mediante expresiones de PromQL (lenguaje de consulta de Prometheus). Puedes completar este paso de cualquiera de las siguientes formas:
- Seleccione una métrica y una etiqueta para su consulta en los menús Métrica y Filtros de etiquetas. Haz clic en Añadir Añadir para añadir más etiquetas a tu consulta. A continuación, haz clic en Ejecutar consulta.
- Introduce tu consulta directamente en el campo de texto Métricas y pulsa Mayús+Intro para ejecutarla.
En la página se muestran las métricas que coinciden con tu consulta.
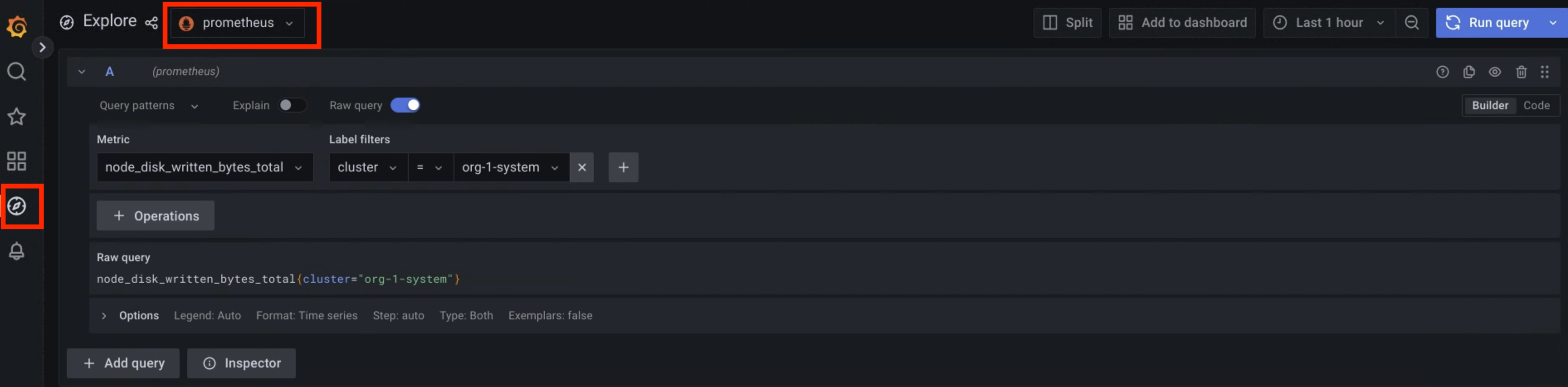
Imagen 1. Opción de menú para consultar métricas desde la interfaz de usuario de Grafana.
En la figura 1, la opción prometheus muestra la interfaz que te permite crear consultas desde Grafana para obtener métricas.
Para ver ejemplos de valores de etiquetas que puede usar para consultar métricas, consulte Consultas y etiquetas de ejemplo.
Endpoint de Cortex: una sola zona
En esta sección se describe cómo acceder a tus métricas con Cortex.
Identificar tu endpoint de Cortex
La siguiente URL es el endpoint de la instancia de Cortex de tu proyecto:
https://GDC_URL/PROJECT_NAMESPACE/cortex/prometheus/
Haz los cambios siguientes:
GDC_URL: la URL de tu organización en GDC.PROJECT_NAMESPACE: el espacio de nombres de tu proyecto.Por ejemplo, el endpoint de Cortex del proyecto
platform-obsde la organizaciónorg-1eshttps://org-1/platform-obs/cortex/prometheus/.
Autenticar la solicitud curl
- Descarga e instala la CLI de gdcloud.
Define la propiedad gdcloud
core/organization_console_url:gdcloud config set core/organization_console_url https://GDC_URLInicia sesión con el proveedor de identidades configurado:
gdcloud auth loginUsa tu nombre de usuario y tu contraseña para autenticarte e iniciar sesión.
Cuando el inicio de sesión se haya completado correctamente, podrá usar el encabezado de autorización en su solicitud curl mediante el comando
gdcloud auth print-identity-token. Para obtener más información, consulta gdcloud auth.
Llamar al endpoint de Cortex
Para acceder al endpoint de Cortex con la herramienta curl
, sigue estos pasos:
- Autentica la solicitud
curl. Usa
curlpara llamar al endpoint de Cortex y amplía la URL con el formato de la API HTTP de consulta para consultar métricas.A continuación, se muestra un ejemplo de solicitud
curl:curl https://GDC_URL/PROJECT_NAME/cortex/prometheus/api/v1/query?query=my_metric{cluster="my-cluster"}&time=2015-07-01T20:10:51.781Z \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Obtendrás el resultado después del comando. La respuesta de la API está en formato JSON.
Endpoint de Cortex: multizona
En esta sección se describe cómo acceder a tus métricas con Cortex.
Identificar tu endpoint de Cortex
La siguiente URL es el endpoint de la instancia de Cortex de tu proyecto para consultas multizona:
https://GDC_URL/PROJECT_NAMESPACE/cortex/metrics
Haz los cambios siguientes:
GDC_URL: la URL de tu organización en GDC.- Ejemplo de org-1, zone1:
console.org-1.zone1.google.gdch.test - Sustituye la organización y la zona de tu aplicación.
- Ejemplo de org-1, zone1:
PROJECT_NAMESPACE: el espacio de nombres de tu proyecto.Por ejemplo, el endpoint de Cortex del proyecto
project-1de la organizaciónorg-1eshttps://console.org-1.zone1.google.gdch.test/project-1/cortex/metrics..
Autenticar la solicitud curl
- Descarga e instala la CLI de gdcloud.
Define la propiedad gdcloud
core/organization_console_url:gdcloud config set core/organization_console_url https://GDC_URLInicia sesión con el proveedor de identidades configurado:
gdcloud auth loginUsa tu nombre de usuario y tu contraseña para autenticarte e iniciar sesión.
Cuando el inicio de sesión se haya completado correctamente, podrá usar el encabezado de autorización en su solicitud curl mediante el comando
gdcloud auth print-identity-token. Para obtener más información, consulta gdcloud auth.
Llamar al endpoint de Cortex
Para acceder al endpoint de Cortex con la herramienta curl
, sigue estos pasos:
- Autentica la solicitud
curl. - Usa
curlpara llamar al endpoint de Cortex y amplía la URL con el formato de la API HTTP de consulta para consultar métricas. Además de los parámetros de consulta de URL de Prometheus, incluya el parámetro de ubicación para proporcionar una lista de zonas que consultar. - location={string}: lista de zonas separadas por
|- Si no se proporciona, la consulta se ejecutará en todas las zonas disponibles.A continuación, se muestra un ejemplo de solicitud
curl POST:curl POST \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range" \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'query=pod_cpu_usage_total' \ --data-urlencode 'start=2025-07-21T16:00:00Z' \ --data-urlencode 'end=2025-07-21T16:15:00Z' \ --data-urlencode 'step=60s' \ --data-urlencode 'location=zone1|zone2' \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"A continuación, se muestra un ejemplo de solicitud
curl GET:curl -X GET \ https://GDC_URL/PROJECT_NAME/cortex/metrics/api/v1/query_range?query=pod_cpu_usage_total&start=2025-07-21T16:00:00Z&end=2025-07-21T16:15:00Z&step=1s&location=zone1|zone2" \ -H "Authorization: Bearer $(gdcloud auth print-identity-token \ --audiences=https://GDC_URL)"Obtienes el resultado después de ejecutar el comando. La respuesta de la API está en formato JSON.
Consultas y etiquetas de ejemplo
Puede consultar métricas mediante el nombre de la métrica y los pares clave-valor de las etiquetas. Una consulta de PromQL tiene la siguiente sintaxis:
metric_name{label_one="value", label_two="value"}
Las etiquetas te permiten diferenciar las características de una métrica. De esta forma, los autores de contenedores hacen que sus cargas de trabajo generen métricas y añadan etiquetas para filtrar esas métricas.
Por ejemplo, puedes tener una métrica api_http_requests_total para contar el número de solicitudes HTTP recibidas. Después, puedes añadir una etiqueta request_method a esta métrica, que toma un valor POST, GET o PUT. Por lo tanto, debe crear tres flujos de métricas para cada tipo de solicitud que pueda recibir. En este caso, para encontrar el número de solicitudes HTTP GET, ejecuta la siguiente consulta:
api_http_requests_total{request_method="GET"}
Consulte Métricas y nombres de etiquetas para obtener más información sobre las métricas y las etiquetas.
A continuación, se indican algunas de las etiquetas predeterminadas que añade el recurso personalizado MonitoringTarget. Puede usar estas etiquetas predeterminadas para consultar métricas:
_gdch_service: el nombre corto del servicio.cluster: el nombre del clúster.container_name: el nombre del contenedor de un pod.namespace_name: el espacio de nombres de tu proyecto.pod_name: el prefijo del nombre del pod.
En la siguiente tabla se describen las etiquetas que añade Prometheus automáticamente:
| Etiqueta de métrica | Descripción |
|---|---|
job |
Nombre interno del trabajo de raspado que se usa para recoger la métrica. Las tareas creadas por el recurso personalizado MonitoringTarget tienen un nombre con el siguiente patrón:obs-system/OBS_SHADOW_PROJECT_NAME/MONITORINGTARGET_NAME.MONITORINGTARGET_NAMESPACE/I/JI y J son números únicos determinados internamente
para evitar conflictos de nombres. |
instance |
El $IP:$PORT del servicio retirado. Si un recurso de carga de trabajo tiene varias réplicas, usa este campo para diferenciarlas. |
En el siguiente ejemplo de código se muestra el uso de pares clave-valor para las etiquetas con el fin de consultar diferentes métricas para ver el uso de CPU recogido en un clúster de Kubernetes:
pod_cpu_usage_total{cluster="CLUSTER_NAME"}
Usa la herramienta de cambio de nombre de métricas para añadir etiquetas que no se hayan expuesto inicialmente por los contenedores retirados y cambiar el nombre de las métricas producidas. Debe configurar el recurso personalizado MonitoringTarget para añadir etiquetas a las métricas que recoge.
Especifica esas etiquetas en el campo metricsRelabelings del recurso personalizado.
Para obtener más información, consulta Métricas de etiquetas.
A continuación, se muestra un ejemplo de una respuesta recibida de un endpoint de métricas de Cortex:
{
"zone1": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.192.1.74:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-swzgq",
"zone_id": "zone1"
},
"values": [
[
1753261200,
"2.258621991"
],
[
1753261800,
"1.029301454"
]
]
}
]
}
},
"zone2": {
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "pod_cpu_usage_total",
"_gdch_project": "project-1",
"cluster": "root-admin",
"container_name": "otel-collector",
"exported_instance": "localhost:2112",
"exported_job": "workload-0",
"ha_cluster": "root-admin-shard1",
"instance": "172.196.3.208:3113",
"job": "metrics-server-exporter.mon-system",
"namespace": "mon-system",
"namespace_name": "mon-system",
"pod": "cortex-0",
"pod_name": "metrics-server-exporter-695c9f848b-kchfv",
"zone_id": "zone2"
},
"values": [
[
1753261200,
"1.814027424"
],
[
1753261800,
"2.7767060260000003"
]
]
}
]
}
}
}
Consultar la API HTTP
Descripción general del formato
Las respuestas de la API tienen un formato JSON coherente. Las solicitudes correctas siempre recibirán un código de estado 2xx.
En el caso de las solicitudes no válidas, los controladores de la API devolverán un objeto de error JSON junto con uno de los siguientes códigos de estado HTTP:
- 400 Bad Request: si faltan parámetros esenciales o se han proporcionado de forma incorrecta.
- 503: Servicio no disponible. Si las consultas superan el límite de tiempo o se cancelan.
Los datos que se hayan recogido correctamente se incluirán en el campo "data" de la respuesta.
El formato del envoltorio de respuesta JSON es el siguiente:
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>",
// Only set if there were warnings while executing the request.
// There will still be data in the data field.
"warnings": ["<string>"],
// Only set if there were info-level annotations while executing the request.
"infos": ["<string>"]
}
Consultas instantáneas
El siguiente endpoint evalúa una consulta instantánea en un momento concreto:
GET /api/v1/query
POST /api/v1/query
Los siguientes parámetros de consulta de URL están disponibles para las consultas de expresiones de Prometheus:
query=<string>: cadena de consulta de la expresión de Prometheus.time=<rfc3339 | unix_timestamp>: marca de tiempo de evaluación opcional, especificada como una cadena RFC 3339 o una marca de tiempo de Unix. Si se omite, se usará la hora actual del servidor.timeout=<duration>: tiempo de espera de evaluación opcional. El valor predeterminado es el valor de la marca query.timeout y está limitado por él.limit=<number>: número máximo opcional de series que se devolverán. Esto trunca las series de matrices y vectores, pero no afecta a los escalares ni a las cadenas. El valor 0 inhabilita este límite.lookback_delta=<number>: parámetro opcional para anular el periodo retrospectivo específicamente en esta consulta.
Si se omite el parámetro de hora, se usará la hora actual del servidor.
En el caso de las consultas más grandes que puedan superar los límites de caracteres de las URLs, puede enviar estos parámetros mediante el método POST. Asegúrate de que el cuerpo de la solicitud esté codificado en formato URL y de que el encabezado Content-Type esté definido como application/x-www-form-urlencoded.
La sección de datos del resultado de la consulta tiene el siguiente formato:
{
"resultType": "matrix" | "vector" | "scalar" | "string",
"result": <value>
}
<value> hace referencia a los datos de los resultados de la consulta, que tienen formatos diferentes en función del valor de resultType.
En el siguiente ejemplo se evalúa la expresión hasta el momento 2015-07-01T20:10:51.781Z:
curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z'
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
]
}
}
Consultas de intervalo
El siguiente endpoint evalúa una consulta de expresión en un intervalo de tiempo:
GET /api/v1/query_range
POST /api/v1/query_range
Los siguientes parámetros de consulta de URL están disponibles para las consultas de expresiones de Prometheus:
query=<string>: cadena de consulta de la expresión de Prometheus.start=<rfc3339 | unix_timestamp>: marca de tiempo de inicio (inclusive).end=<rfc3339 | unix_timestamp>: marca de tiempo de finalización (inclusive).step=<duration | float>: ancho del paso de resolución de la consulta en formato de duración o número decimal de segundos.timeout=<duration>: tiempo de espera de evaluación opcional. El valor predeterminado es el valor de la marca query.timeout y está limitado por él.limit=<number>: número máximo opcional de series que se devolverán. Esto trunca las series de matrices y vectores, pero no afecta a los escalares ni a las cadenas. El valor 0 inhabilita este límite.lookback_delta=<number>: parámetro opcional para anular el periodo retrospectivo específicamente en esta consulta.
En el caso de las consultas más grandes que puedan superar los límites de caracteres de las URLs, puede enviar estos parámetros mediante el método POST. Asegúrate de que el cuerpo de la solicitud esté codificado en formato URL y de que el encabezado Content-Type esté definido como application/x-www-form-urlencoded.
La sección de datos del resultado de la consulta tiene el siguiente formato:
{
"resultType": "matrix",
"result": <value>
}
En el siguiente ejemplo se evalúa la expresión up en un intervalo de 30 segundos con una resolución de consulta de 15 segundos.
curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
Nombres de métricas y etiquetas
Directrices de nomenclatura de métricas
Al definir nombres de métricas, tenga en cuenta los siguientes principios:
El nombre de una métrica DEBE incluir un prefijo de aplicación de una sola palabra, al que las bibliotecas de cliente a veces se refieren como "espacio de nombres". Este prefijo identifica el dominio al que pertenece la métrica. En el caso de las métricas específicas de la aplicación, el nombre de la aplicación se suele usar como prefijo.
Ejemplos:
- prometheus_notifications_total (específico del servidor Prometheus)
- process_cpu_seconds_total (exportado por muchas bibliotecas de cliente)
- http_request_duration_seconds (para todas las solicitudes HTTP)
El nombre de una métrica DEBE representar una sola unidad (por ejemplo, no se deben mezclar segundos con milisegundos, ni segundos con bytes).
Los nombres de las métricas DEBEN usar unidades base (por ejemplo, segundos, bytes o metros) en lugar de unidades derivadas (por ejemplo, milisegundos, megabytes o kilómetros).
El nombre de una métrica DEBE incluir un sufijo de unidad en plural. Para los recuentos acumulados, se debe usar el sufijo "total" además del sufijo de unidad, si procede.
Ejemplos:
- http_request_duration_seconds
- node_memory_usage_bytes
- http_requests_total (para un recuento acumulativo sin unidades)
- process_cpu_seconds_total (para un recuento acumulativo con unidad)
- foobar_build_info (para una seudométrica que proporciona metadatos sobre el archivo binario en ejecución)
El nombre de una métrica PUEDE ordenar sus componentes para facilitar la agrupación cuando se ordenan lexicográficamente, siempre que se sigan todas las demás reglas. Las métricas relacionadas suelen tener componentes de nombre comunes que se colocan en primer lugar para asegurarse de que se ordenen juntas.
Ejemplos:
- prometheus_tsdb_head_truncations_closed_total
- prometheus_tsdb_head_truncations_established_total
- prometheus_tsdb_head_truncations_failed_total
- prometheus_tsdb_head_truncations_total
El nombre de una métrica DEBE representar de forma coherente el mismo elemento lógico medido en todas las dimensiones de la etiqueta.
Ejemplos:
- duración de la solicitud
- bytes de transferencia de datos
- uso de recursos instantáneo como porcentaje
Directrices para asignar nombres a las etiquetas
Cuando mida algo, utilice etiquetas para distinguir sus características. Por ejemplo:
- En el caso de las solicitudes HTTP totales de la API (
api_http_requests_total), diferencia por tipo de operación, por ejemplo,create,updateydelete(tipos de solicitud:operation="create|update|delete"). - En el caso de la duración de las solicitudes a la API en segundos (
api_request_duration_seconds), diferencia las solicitudes por fase, por ejemplo,extract,transformyload(fases de la solicitud:stage="extract|transform|load").
No incluyas nombres de etiquetas en el nombre de la métrica, ya que esto crea redundancia y puede generar confusión si esas etiquetas se agregan más adelante.