
En este documento, se proporciona una descripción general para la administración de cargas de trabajo en Google Distributed Cloud (GDC) aislado. Se tratan los siguientes temas:
Si bien se recomiendan algunos de los diseños de implementación de cargas de trabajo, no es necesario seguirlos exactamente según lo prescrito. Cada universo de GDC tiene requisitos y consideraciones únicos que se deben satisfacer caso por caso.
Este documento está dirigido a administradores de TI dentro del grupo de administradores de la plataforma que son responsables de administrar los recursos dentro de su organización y a desarrolladores de aplicaciones dentro del grupo de operadores de aplicaciones que son responsables de desarrollar y mantener aplicaciones en un universo de GDC.
Para obtener más información, consulta Públicos de la documentación de Google Distributed Cloud aislado.
Dónde implementar cargas de trabajo
En la plataforma de GDC, las operaciones para implementar cargas de trabajo de máquinas virtuales (VM) y cargas de trabajo de contenedores son diferentes. En el siguiente diagrama, se ilustra la separación de cargas de trabajo dentro de la capa del plano de datos de tu organización.
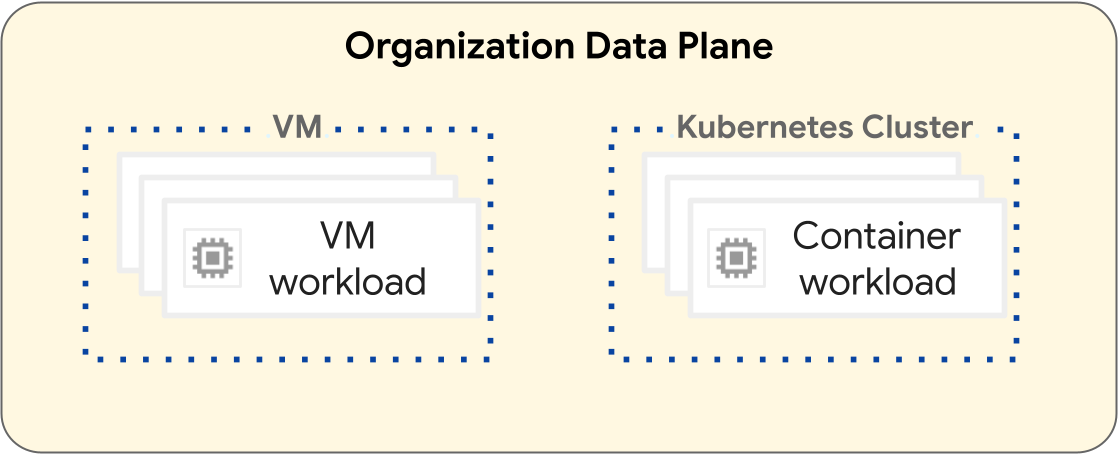
Las cargas de trabajo basadas en VM operan dentro de una VM. Por el contrario, las cargas de trabajo de contenedores operan dentro de un clúster de Kubernetes. La separación fundamental entre las VMs y los clústeres de Kubernetes proporciona límites de aislamiento entre las cargas de trabajo de VM y las cargas de trabajo de contenedores. Para obtener más información, consulta Jerarquía de recursos.
En las siguientes secciones, se presentan las diferencias entre cada tipo de carga de trabajo y su ciclo de vida de implementación.
Cargas de trabajo basadas en VM
Puedes crear VMs para alojar tus cargas de trabajo basadas en VM. Tienes muchas opciones de configuración para la forma y el tamaño de tu VM que te ayudarán a satisfacer mejor los requisitos de tu carga de trabajo basada en VM. Debes crear una VM en un proyecto, que puede tener muchas cargas de trabajo de VM. Las VMs son un recurso secundario de un proyecto. Para obtener más información, consulta la descripción general de las VMs.
Los proyectos que solo contienen cargas de trabajo basadas en VM no requieren un clúster de Kubernetes. Por lo tanto, no es necesario que aprovisiones clústeres de Kubernetes para cargas de trabajo basadas en VM.
Cargas de trabajo basadas en contenedores
Puedes implementar cargas de trabajo basadas en contenedores en un pod en un clúster de Kubernetes. Un clúster de Kubernetes consta de los siguientes tipos de nodos:
Nodo del plano de control: Ejecuta los servicios de administración, como la programación, etcd y un servidor de API.
Nodo trabajador: Ejecuta tus pods y aplicaciones de contenedores.
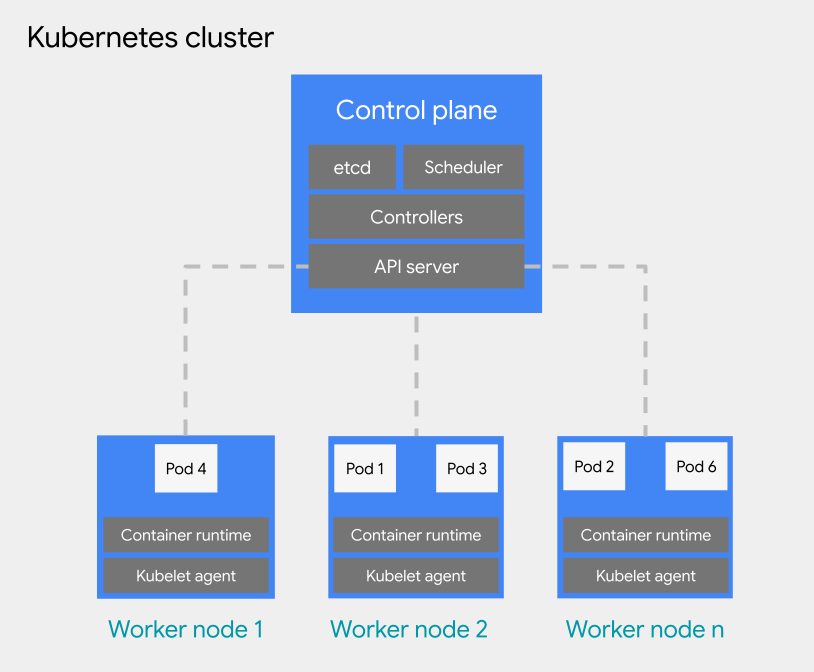
Existen dos tipos de configuración para los clústeres de Kubernetes:
- Clústeres compartidos: Un clúster de Kubernetes con alcance de la organización que puede abarcar varios proyectos y no está administrado por un solo proyecto, sino que está conectado a ellos.
- Clústeres estándar: Un clúster de Kubernetes con alcance de proyecto que administra los recursos del clúster dentro de un proyecto y no puede abarcar varios proyectos.
Para obtener más información, consulta Configuraciones de clústeres de Kubernetes.
Los clústeres de Kubernetes ofrecen varias opciones jerárquicas de recursos, ya que los clústeres compartidos tienen alcance de la organización y los clústeres estándar tienen alcance de proyecto. Esta es una diferencia fundamental que tienen los clústeres de Kubernetes en comparación con las VMs. Una VM es un recurso secundario de un proyecto y no se puede configurar para que opere fuera de un proyecto. Para obtener más información sobre cómo diseñar tu infraestructura de clústeres de Kubernetes, consulta Prácticas recomendadas para diseñar clústeres de Kubernetes.
Para la programación de pods dentro de un clúster de Kubernetes, GDC adopta los conceptos generales de Kubernetes de programación, prioridad y desalojo. Las prácticas recomendadas para programar pods dentro de un clúster varían según los requisitos de tu carga de trabajo.
Para obtener más información sobre los clústeres de Kubernetes, consulta la descripción general de los clústeres de Kubernetes. Para obtener más información sobre cómo administrar tus contenedores en un clúster de Kubernetes, consulta Cargas de trabajo de contenedores en GDC.
Prácticas recomendadas para diseñar clústeres de Kubernetes
En esta sección, se presentan las prácticas recomendadas para diseñar clústeres de Kubernetes:
- Crea clústeres separados por entorno de desarrollo de software
- Crea menos clústeres más grandes
- Crea menos grupos de nodos más grandes dentro de un clúster
Considera cada práctica recomendada para diseñar un diseño de clúster resiliente para el ciclo de vida de tu carga de trabajo de contenedores.
Crea clústeres separados por entorno de desarrollo de software
Además de proyectos separados por entorno de desarrollo de software
,
te recomendamos que diseñes clústeres de Kubernetes separados por entorno de desarrollo de software. Un entorno de desarrollo de software es un área dentro de tu universo de GDC destinada a todas las operaciones que corresponden a una fase designada del ciclo de vida. Por ejemplo, si tienes tres entornos de desarrollo de software llamados development, staging y production en tu organización, puedes crear un conjunto separado de clústeres de Kubernetes para cada entorno y adjuntar proyectos a cada clúster según tus necesidades.
Te recomendamos que uses clústeres estándar en los ciclos de vida de preproducción que tengan un alcance de un solo proyecto, lo que permite que cualquier proceso destructivo relacionado con las pruebas se aísle de los proyectos de producción, mientras que los clústeres compartidos son ideales para entornos de producción que pueden abarcar varios proyectos. Un clúster compartido que aloja cargas de trabajo de producción que abarcan varios proyectos proporciona un área de implementación compartida en la que los clústeres estándar con alcance de un solo proyecto pueden promover sus cargas de trabajo directamente al entorno de producción.
Los clústeres estándar definidos para cada entorno de desarrollo de software suponen que las cargas de trabajo de preproducción dentro de un entorno de desarrollo de software se limitan a ese clúster. Un clúster de Kubernetes se puede subdividir aún más en varios grupos de nodos o usar marcas para el aislamiento de la carga de trabajo.
Si separas los clústeres de Kubernetes por entorno de desarrollo de software, aislarás el consumo de recursos, las políticas de acceso, los eventos de mantenimiento y los cambios de configuración a nivel del clúster entre tus cargas de trabajo de producción y no producción.
En el siguiente diagrama, se muestra un diseño de clúster de Kubernetes de muestra para varias cargas de trabajo que abarcan proyectos, clústeres, entornos de desarrollo de software y clases de máquinas proporcionadas por diferentes grupos de nodos.
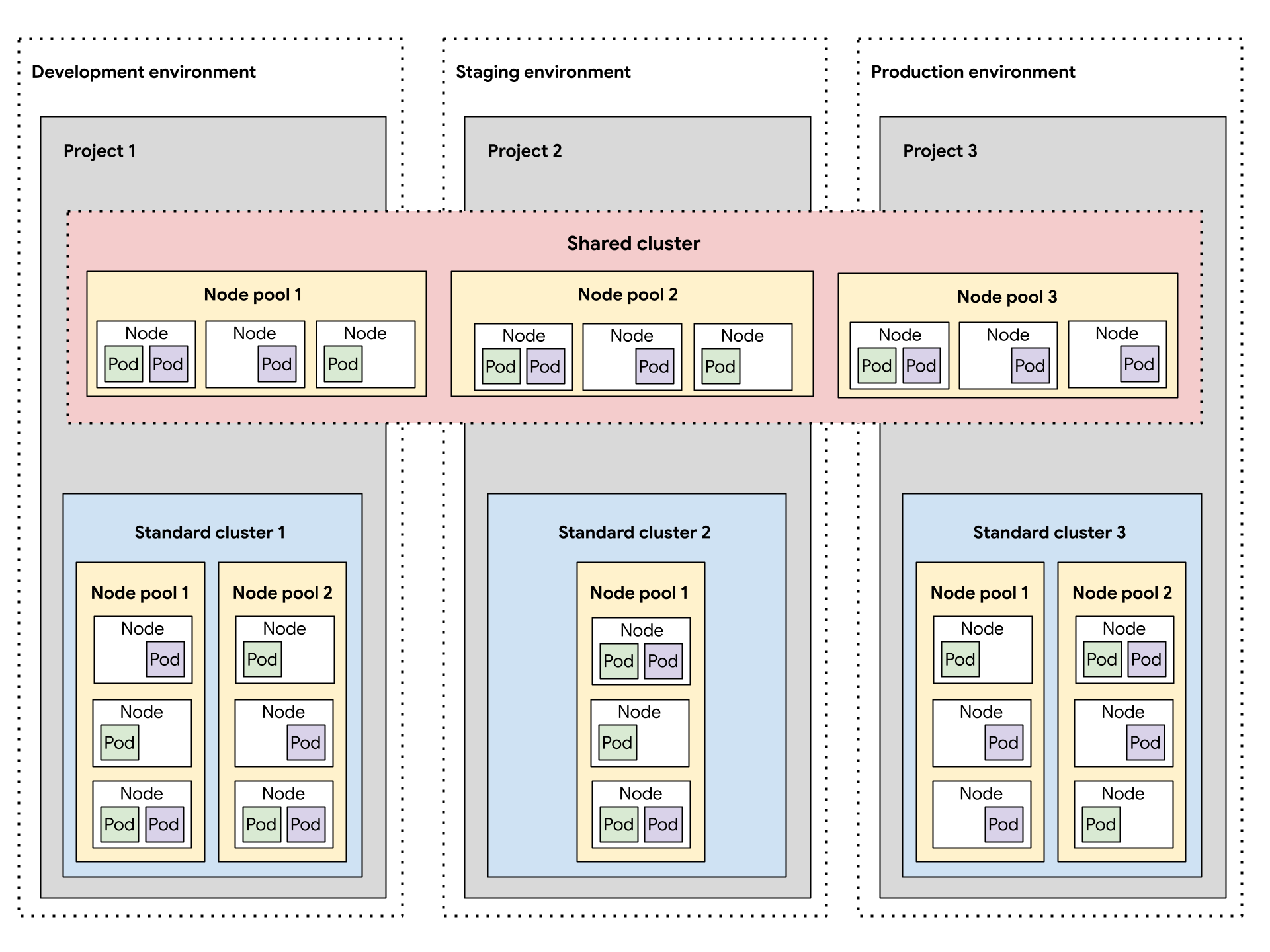
Esta arquitectura de muestra supone que las cargas de trabajo dentro de los entornos de desarrollo, etapa de pruebas y producción de software pueden compartir clústeres. Cada entorno tiene un clúster estándar separado, que se subdivide aún más en varios grupos de nodos para diferentes requisitos de clase de máquina. El clúster compartido abarca todos los entornos de desarrollo de software y proporciona un área de implementación común para todos los entornos.
Como alternativa, diseñar varios clústeres estándar por entorno de desarrollo de software es útil para operaciones de contenedores como las siguientes situaciones:
- Tienes algunas cargas de trabajo fijadas a una versión específica de Kubernetes, por lo que mantienes diferentes clústeres en diferentes versiones.
- Tienes algunas cargas de trabajo que requieren diferentes necesidades de configuración de clúster, como la política de copia de seguridad, por lo que creas varios clústeres con diferentes configuraciones.
- Ejecutas copias de un clúster en paralelo para facilitar las actualizaciones de versiones disruptivas o una estrategia de implementación azul-verde.
- Compilas una carga de trabajo experimental que corre el riesgo de limitar el servidor de API o cualquier otro punto único de falla dentro de un clúster, por lo que lo aíslas de las cargas de trabajo existentes.
Debes adaptar tus entornos de desarrollo de software a los requisitos establecidos por tus operaciones de contenedores.
Crea menos clústeres
Para un uso eficiente de los recursos, te recomendamos que diseñes la menor cantidad de clústeres de Kubernetes que cumplan con tus requisitos para separar los entornos de desarrollo de software y las operaciones de contenedores. Cada clúster adicional genera un consumo de recursos de sobrecarga adicional, como nodos adicionales del plano de control requeridos. Por lo tanto, un clúster más grande con muchas cargas de trabajo utiliza los recursos de procesamiento subyacentes de manera más eficiente que muchos clústeres pequeños.
Cuando hay varios clústeres con configuraciones similares, se crea una sobrecarga de mantenimiento adicional para supervisar la capacidad del clúster y planificar las dependencias entre clústeres.
Si un clúster se acerca a su capacidad, te recomendamos que agregues nodos adicionales a un clúster en lugar de crear uno nuevo.
Crea menos grupos de nodos dentro de un clúster
Para un uso eficiente de los recursos, te recomendamos que diseñes menos grupos de nodos más grandes dentro de un clúster de Kubernetes.
Configurar varios grupos de nodos es útil cuando necesitas programar pods que requieren una clase de máquina diferente a otras. Crea un grupo de nodos para cada clase de máquina que requieran tus cargas de trabajo y configura la capacidad del nodo en el ajuste de escala automático para permitir un uso eficiente de los recursos de procesamiento.
¿Qué sigue?
- Jerarquía de recursos
- Crea una app de contenedor de alta disponibilidad
- Crea una app de VM de alta disponibilidad