
Questo documento fornisce una panoramica della gestione dei carichi di lavoro in Google Distributed Cloud (GDC) con air gap. Vengono trattati i seguenti argomenti:
Sebbene alcuni dei progetti di deployment dei carichi di lavoro siano consigliati, non è necessario seguirli esattamente come prescritto. Ogni universo GDC ha requisiti e considerazioni unici che devono essere soddisfatti caso per caso.
Questo documento è destinato agli amministratori IT del gruppo di amministratori della piattaforma responsabili della gestione delle risorse all'interno della propria organizzazione e agli sviluppatori di applicazioni del gruppo di operatori di applicazioni responsabili dello sviluppo e della manutenzione delle applicazioni in un universo GDC.
Per saperne di più, consulta Pubblici per la documentazione di GDC con air gap.
Dove eseguire il deployment dei carichi di lavoro
Sulla piattaforma GDC, le operazioni per il deployment dei carichi di lavoro delle macchine virtuali (VM) e dei carichi di lavoro dei container sono diverse. Il seguente diagramma illustra la separazione dei carichi di lavoro all'interno del livello del piano dati della tua organizzazione.
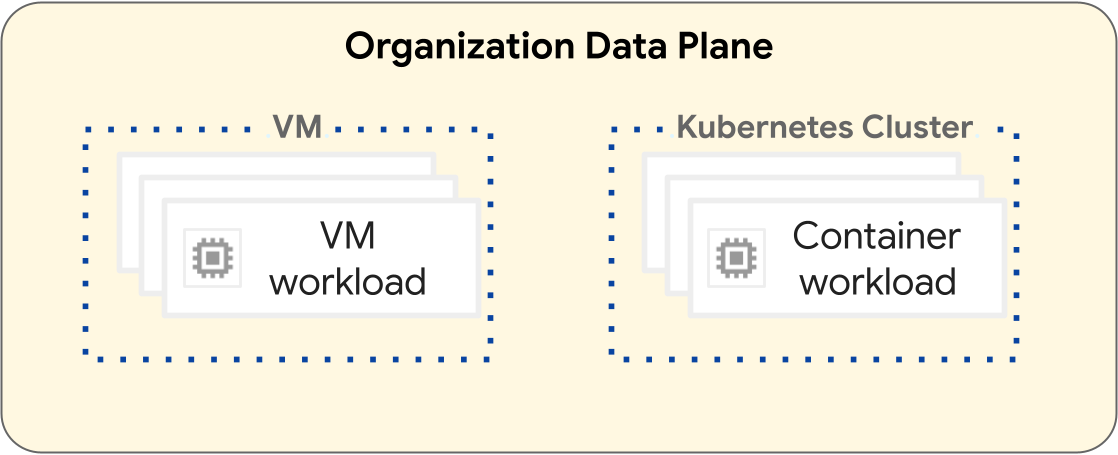
I carichi di lavoro basati su VM vengono eseguiti all'interno di una VM. Al contrario, i carichi di lavoro dei container vengono eseguiti all'interno di un cluster Kubernetes. La separazione fondamentale tra VM e cluster Kubernetes fornisce limiti di isolamento tra i carichi di lavoro delle VM e i carichi di lavoro dei container. Per saperne di più, consulta Gerarchia delle risorse.
Le seguenti sezioni introducono le differenze tra ogni tipo di carico di lavoro e il relativo ciclo di vita del deployment.
Carichi di lavoro basati su VM
Puoi creare VM per ospitare i carichi di lavoro basati su VM. Sono disponibili molte opzioni di configurazione per la forma e le dimensioni della VM per soddisfare al meglio i requisiti dei carichi di lavoro basati su VM. Devi creare una VM in un progetto, che può avere molti carichi di lavoro delle VM. Le VM sono una risorsa secondaria di un progetto. Per saperne di più, consulta la panoramica delle VM.
I progetti che contengono solo carichi di lavoro basati su VM non richiedono un cluster Kubernetes. Pertanto, non è necessario eseguire il provisioning dei cluster Kubernetes per i carichi di lavoro basati su VM.
Carichi di lavoro basati su container
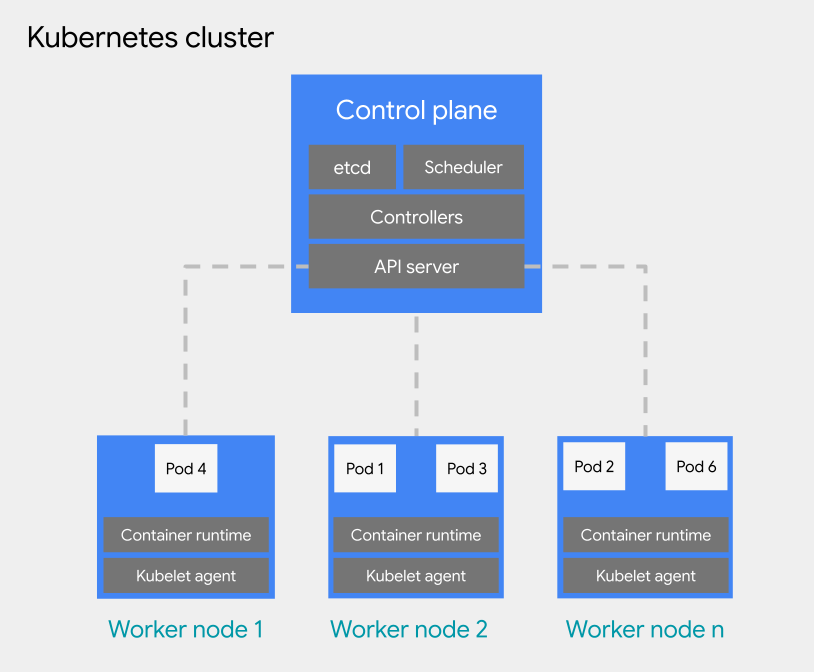
Puoi eseguire il deployment dei carichi di lavoro basati su container in un pod su un cluster Kubernetes. Un cluster Kubernetes è costituito dai seguenti tipi di nodi:
Nodo del piano di controllo: esegue i servizi di gestione, come lo scheduler, etcd e un server API.
Nodo worker: esegue i pod e le applicazioni containerizzate.
Esistono due tipi di configurazione per i cluster Kubernetes:
- Cluster condivisi: un cluster Kubernetes con ambito organizzazione che può estendersi a più progetti e non è gestito da un singolo progetto, ma è collegato a questi.
- Cluster standard: un cluster Kubernetes con ambito progetto che gestisce le risorse del cluster all'interno di un progetto e non può estendersi a più progetti.
Per saperne di più, consulta Configurazione dei cluster Kubernetes.
I cluster Kubernetes offrono varie opzioni gerarchiche delle risorse, poiché i cluster condivisi hanno ambito organizzazione e i cluster standard hanno ambito progetto. Questa è una differenza fondamentale tra i cluster Kubernetes e le VM. Una VM è una risorsa secondaria di un progetto e non può essere configurata per funzionare al di fuori di un progetto. Per saperne di più su come progettare l'infrastruttura del cluster Kubernetes, consulta Best practice per la progettazione di cluster Kubernetes.
Per la pianificazione dei pod all'interno di un cluster Kubernetes, GDC adotta i concetti generali di Kubernetes di pianificazione, prerilascio ed eliminazione. Le best practice per la pianificazione dei pod all'interno di un cluster variano in base ai requisiti del carico di lavoro.
Per saperne di più sui cluster Kubernetes, consulta la panoramica dei cluster Kubernetes. Per saperne di più sulla gestione dei container in un cluster Kubernetes, consulta Carichi di lavoro dei container in GDC.
Best practice per la progettazione di cluster Kubernetes
Questa sezione introduce le best practice per la progettazione di cluster Kubernetes:
- Crea cluster separati per ambiente di sviluppo software
- Crea meno cluster, ma più grandi
- Crea meno node pool, ma più grandi all'interno di un cluster
Tieni conto di ogni best practice per progettare un cluster resiliente per il ciclo di vita del carico di lavoro dei container.
Crea cluster separati per ambiente di sviluppo software
Oltre a progetti separati per ambiente di sviluppo
software,
ti consigliamo di progettare cluster Kubernetes separati per ambiente di sviluppo software. Un ambiente di sviluppo software è un'area all'interno del tuo universo GDC destinata a tutte le operazioni che corrispondono a una fase del ciclo di vita designata. Ad esempio, se nella tua organizzazione hai tre ambienti di sviluppo software denominati development, staging e production, puoi creare un insieme separato di cluster Kubernetes per ogni ambiente e collegare i progetti a ogni cluster in base alle tue esigenze.
Ti consigliamo di utilizzare cluster standard nei cicli di vita di pre-produzione con ambito di un singolo progetto, in modo che tutti i processi distruttivi correlati ai test siano isolati dai progetti di produzione, mentre i cluster condivisi sono ideali per gli ambienti di produzione che possono estendersi a più progetti. Un cluster condiviso che ospita carichi di lavoro di produzione che si estendono a più progetti fornisce un'area di deployment condivisa in cui i cluster standard con ambito di un singolo progetto possono promuovere i propri carichi di lavoro direttamente nell'ambiente di produzione.
I cluster standard definiti per ogni ambiente di sviluppo software presuppongono che i carichi di lavoro di pre-produzione all'interno di un ambiente di sviluppo software siano limitati a quel cluster. Un cluster Kubernetes può essere ulteriormente suddiviso in multiple node pool o utilizzare i taint per l'isolamento dei carichi di lavoro.
Separando i cluster Kubernetes per ambiente di sviluppo software, isoli il consumo di risorse, i criteri di accesso, gli eventi di manutenzione e le modifiche alla configurazione a livello di cluster tra i carichi di lavoro di produzione e non di produzione.
Il seguente diagramma mostra un esempio di progettazione di cluster Kubernetes per più carichi di lavoro che si estendono a progetti, cluster, ambienti di sviluppo software e classi di macchine forniti da diversi node pool.

Questa architettura di esempio presuppone che i carichi di lavoro all'interno degli ambienti di sviluppo software, gestione temporanea e produzione possano condividere i cluster. Ogni ambiente ha un cluster standard separato, ulteriormente suddiviso in più node pool per diversi requisiti di classe di macchine. Il cluster condiviso si estende a tutti gli ambienti di sviluppo software, fornendo un'area di deployment comune per tutti gli ambienti.
In alternativa, la progettazione di più cluster standard per ambiente di sviluppo software è utile per le operazioni dei container come i seguenti scenari:
- Alcuni carichi di lavoro sono associati a una versione specifica di Kubernetes, quindi mantieni cluster diversi in versioni diverse.
- Alcuni carichi di lavoro richiedono esigenze di configurazione del cluster diverse, ad esempio il criterio di backup, quindi crei più cluster con configurazioni diverse.
- Esegui copie di un cluster in parallelo per facilitare gli upgrade di versione distruttivi o una strategia di deployment blu/verde.
- Crei un carico di lavoro sperimentale che rischia di limitare il server API o altri punti di errore singoli all'interno di un cluster, quindi lo isoli dai carichi di lavoro esistenti.
Devi adattare gli ambienti di sviluppo software ai requisiti impostati dalle operazioni dei container.
Crea meno cluster
Per un utilizzo efficiente delle risorse, ti consigliamo di progettare il minor numero di cluster Kubernetes che soddisfino i requisiti per la separazione degli ambienti di sviluppo software e delle operazioni dei container. Ogni cluster aggiuntivo comporta un consumo di risorse aggiuntivo, ad esempio i nodi del piano di controllo aggiuntivi richiesti. Pertanto, un cluster più grande con molti carichi di lavoro utilizza le risorse di calcolo sottostanti in modo più efficiente rispetto a molti cluster di piccole dimensioni.
Quando sono presenti più cluster con configurazioni simili, si crea un overhead di manutenzione aggiuntivo per monitorare la capacità del cluster e pianificare le dipendenze tra cluster.
Se un cluster si sta avvicinando alla capacità, ti consigliamo di aggiungere altri nodi a un cluster anziché crearne uno nuovo.
Crea meno node pool all'interno di un cluster
Per un utilizzo efficiente delle risorse, ti consigliamo di progettare meno node pool, ma più grandi all'interno di un cluster Kubernetes.
La configurazione di più node pool è utile quando devi pianificare i pod che richiedono una classe di macchine diversa dalle altre. Crea un pool di nodi per ogni classe di macchine richiesta dai carichi di lavoro e imposta la capacità dei nodi sulla scalabilità automatica per consentire un utilizzo efficiente delle risorse di calcolo.
Passaggi successivi
- Gerarchia delle risorse
- Crea un'app containerizzata ad alta disponibilità
- Crea un'app VM ad alta disponibilità