
כששולחים עבודת Dataproc, המערכת אוספת אוטומטית את הפלט של העבודה ומאפשרת לכם לגשת אליו. המשמעות היא שאתם יכולים לבדוק במהירות את הפלט של העבודה בלי לשמור על חיבור לאשכול בזמן שהעבודות רצות או לעיין בקובצי יומן מורכבים.
יומני Spark
יש שני סוגים של יומני Spark: יומני Spark driver ויומני Spark executor.
יומני מנהלי התקנים של Spark מכילים פלט של משימות. יומני executor של Spark מכילים פלט של קובץ הפעלה של משימה או של launcher, כמו ההודעה spark-submit "Submitted application xxx", והם יכולים לעזור בניפוי באגים של כשלים במשימות.
הדרייבר של משימת Dataproc, ששונה מהדרייבר של Spark,
הוא כלי להפעלת סוגים רבים של משימות. כשמפעילים משימות Spark, הן פועלות כ-wrapper בקובץ ההפעלה הבסיסי spark-submit, שמפעיל את Spark driver. הדרייבר של Spark מריץ את המשימה באשכול Dataproc במצב Spark
client או cluster:
מצב
client: מנהל ההתקן של Spark מריץ את העבודה בתהליךspark-submit, ויומני Spark נשלחים למנהל ההתקן של העבודה ב-Dataproc.מצב
cluster: מנהל ההתקנים של Spark מפעיל את העבודה בקונטיינר YARN. יומני הרישום של מנהל ההתקן של Spark לא זמינים למנהל ההתקן של עבודת Dataproc.
סקירה כללית של מאפייני משימות Dataproc ו-Spark
| מאפיין (property) | ערך | ברירת מחדל | תיאור |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
נכון או לא נכון | FALSE | צריך להגדיר את הערך הזה בזמן יצירת האשכול. כשמגדירים true, הפלט של מנהל המשימות נמצא ב-Logging, ומשויך למשאב המשימה. כשמגדירים false, הפלט של מנהל המשימות לא נמצא ב-Logging.הערה: כדי להפעיל את היומנים של מנהל העבודות ב-Logging, צריך להגדיר גם את ההגדרות הבאות של מאפייני האשכול. ההגדרות האלה מוגדרות כברירת מחדל כשיוצרים אשכול: dataproc:dataproc.logging.stackdriver.enable=true
ו-dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
נכון או לא נכון | FALSE | צריך להגדיר את הערך הזה בזמן יצירת האשכול.
אם הערך הוא true, יומני המכולות של YARN של המשימה משויכים למשאב המשימה. אם הערך הוא false, יומני המכולות של YARN של המשימה משויכים למשאב האשכול. |
spark:spark.submit.deployMode |
לקוח או אשכול | לקוח | שליטה במצב Spark client או cluster. |
משימות Spark שנשלחו באמצעות Dataproc jobs API
בטבלאות שבקטע הזה מפורטות ההשפעות של הגדרות מאפיינים שונות על היעד של פלט מנהל העבודה של משימת Dataproc, כששולחים משימות דרך Dataproc jobs API, כולל שליחת משימות דרךGoogle Cloud console, ה-CLI של gcloud וספריות לקוח בענן.
אפשר להגדיר את מאפייני Dataproc ו-Spark שמופיעים ברשימה באמצעות הדגל --properties כשיוצרים אשכול, והם יחולו על כל משימות Spark שמופעלות באשכול. אפשר גם להגדיר מאפייני Spark באמצעות הדגל --properties (בלי הקידומת spark:) כששולחים משימה ל-Dataproc jobs API, והם יחולו רק על המשימה.
פלט של מנהל משימות ב-Dataproc
בטבלאות הבאות מפורטת ההשפעה של הגדרות שונות של נכסים על היעד של פלט מנהל המשימות של Dataproc.
dataproc: |
תשובה |
|---|---|
| false (ברירת מחדל) |
|
| TRUE |
|
יומנים של מנהל התקן Spark
בטבלאות הבאות מפורטות ההשפעות של הגדרות שונות של נכסים על היעד של יומני מנהל ההתקן של Spark.
spark: |
dataproc: |
dataproc: |
פלט של דרייבר |
|---|---|---|---|
| לקוח | false (ברירת מחדל) | נכון או לא נכון |
|
| לקוח | TRUE | נכון או לא נכון |
|
| אשכול | false (ברירת מחדל) | FALSE |
|
| אשכול | TRUE | TRUE |
|
יומנים של Spark executor
בטבלאות הבאות מפורטת ההשפעה של הגדרות שונות של נכסים על היעד של יומני Spark executor.
dataproc: |
יומן של מוציא/ה לפועל |
|---|---|
| false (ברירת מחדל) | בקטע Logging: yarn-userlogs מתחת למשאב האשכול |
| TRUE | בקטע Logging dataproc.job.yarn.container מתחת למשאב של המשימה |
משימות Spark שנשלחו בלי להשתמש ב-Dataproc jobs API
בקטע הזה מפורטות ההשפעות של הגדרות שונות של מאפיינים על היעד של יומני משימות Spark, כששולחים משימות בלי להשתמש ב-Dataproc jobs API, למשל כששולחים משימה ישירות בצומת של אשכול באמצעות spark-submit או כשמשתמשים במחברת Jupyter או Zeppelin. למשימות האלה אין מזהי משימות או דרייברים של Dataproc.
יומנים של מנהל התקן Spark
בטבלאות הבאות מפורטות ההשפעות של הגדרות שונות של נכסים על היעד של יומני מנהלי התקנים של Spark למשימות שלא נשלחו דרך Dataproc jobs API.
spark: |
פלט של דרייבר |
|---|---|
| לקוח |
|
| אשכול |
|
יומנים של Spark executor
כשמשימות Spark לא נשלחות דרך Dataproc jobs API, יומני הביצוע נמצאים ב-Logging yarn-userlogs בקטע של משאב האשכול.
הצגת פלט של משימה
אפשר לגשת לפלט של משימות Dataproc במסוף Google Cloud , ב-CLI של gcloud, ב-Cloud Storage או ב-Logging.
המסוף
כדי לראות את הפלט של המשימה, עוברים לקטע Jobs (משימות) של Dataproc בפרויקט ולוחצים על Job ID (מזהה המשימה) כדי לראות את הפלט של המשימה.
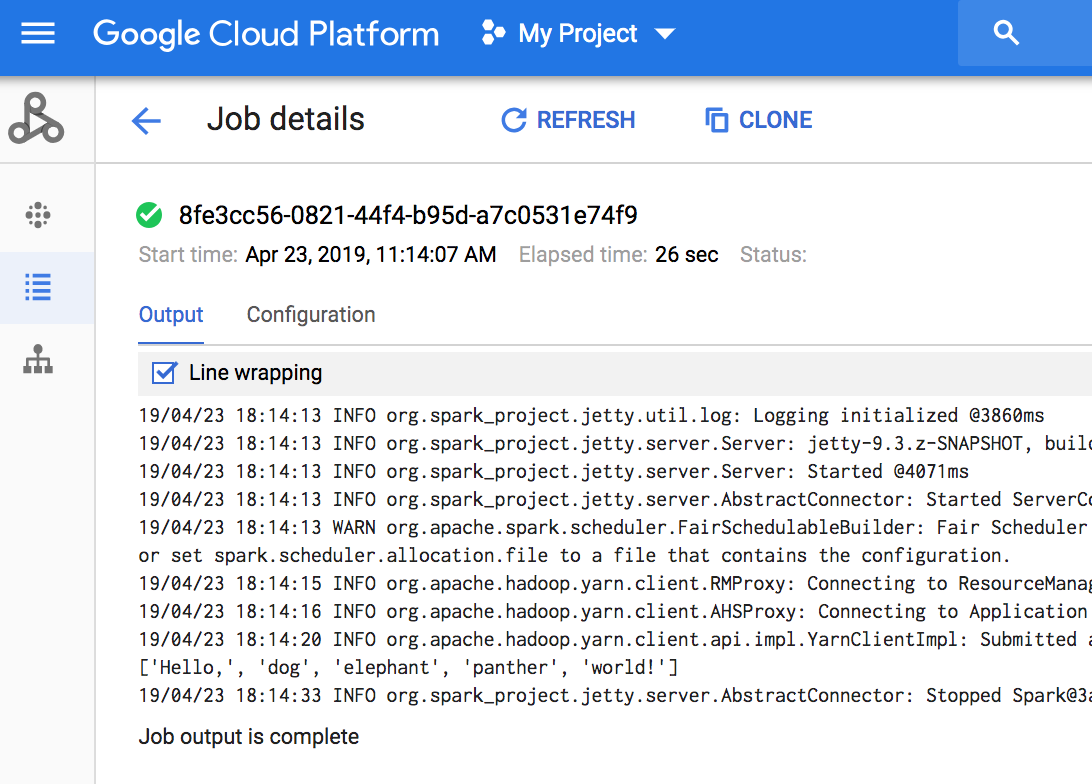
אם המשימה פועלת, הפלט של המשימה מתעדכן מעת לעת עם תוכן חדש.
פקודת gcloud
כששולחים משימה באמצעות הפקודה gcloud dataproc jobs submit, הפלט של המשימה מוצג במסוף. אפשר להצטרף מחדש לפלט מאוחר יותר, במחשב אחר או בחלון חדש, על ידי העברת מזהה העבודה לפקודה gcloud dataproc jobs wait. מזהה המשימה הוא GUID, למשל 5c1754a5-34f7-4553-b667-8a1199cb9cab. נראה דוגמה.
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
הפלט של העבודה מאוחסן ב-Cloud Storage בקטגוריית הביניים או בקטגוריה שציינתם כשנוצר האשכול. קישור לפלט של המשימה ב-Cloud Storage מופיע בשדה Job.driverOutputResourceUri שמוחזר על ידי:
- בקשת API מסוג jobs.get.
- פקודה gcloud dataproc jobs describe job-id.
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...