
אפשר לראות, לחפש, לסנן ולארכב יומנים של משימות ואשכולות של Dataproc ב-Cloud Logging.
כדי להבין את העלויות, אפשר לעיין במחירון של Google Cloud Observability.
מידע על שמירת יומנים מופיע במאמר תקופות שמירה של יומנים.
במאמר החרגות מיומנים מוסבר איך להשבית את כל היומנים או להחריג יומנים מרישום ביומן.
כדי לנתב יומנים מ-Logging אל Cloud Storage, BigQuery או Pub/Sub, אפשר לעיין במאמר סקירה כללית על ניתוב ואחסון.
רמות רישום ביומן של רכיבים
אפשר להגדיר רמות רישום ביומן של Spark, Hadoop, Flink ורכיבים אחרים של Dataproc באמצעות מאפייני אשכול ספציפיים לרכיב log4j, כמו hadoop-log4j, כשיוצרים אשכול. רמות הרישום ביומן של רכיבים מבוססי-אשכול חלות על שדי שירות, כמו YARN ResourceManager, ועל משימות שמופעלות באשכול.
אם מאפייני log4j לא נתמכים ברכיב מסוים, כמו רכיב Presto, צריך לכתוב פעולת אתחול שתערוך את הקובץ log4j.properties או log4j2.properties של הרכיב.
רמות רישום ביומן של רכיבים ספציפיים לעבודה: אפשר גם להגדיר רמות רישום ביומן של רכיבים כששולחים עבודה. רמות הרישום ביומן חלות על העבודה, ויש להן עדיפות על פני רמות הרישום ביומן שהוגדרו כשנוצר האשכול. מידע נוסף זמין במאמר בנושא מאפיינים של אשכול לעומת מאפיינים של משימה.
רמות הרישום ביומן של גרסאות הרכיבים של Spark ו-Hive:
רכיבי Spark 3.3.X ו-Hive 3.X משתמשים במאפייני log4j2, ואילו גרסאות קודמות של הרכיבים האלה משתמשות במאפייני log4j (ראו Apache Log4j2).
כדי להגדיר את רמות הרישום ביומן של Spark באשכול, צריך להשתמש בקידומת spark-log4j:.
דוגמה: Dataproc image version 2.0 with Spark 3.1 to set
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
דוגמה: Dataproc גרסת תמונה 2.1 עם Spark 3.3 להגדרת
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
רמות רישום ביומן של Job Driver
Dataproc משתמש ברמת רישום של INFO כברירת מחדל עבור תוכנות מנהל העבודה. אפשר לשנות את ההגדרה הזו לחבילה אחת או יותר באמצעות האפשרות gcloud dataproc jobs submit עם הדגל --driver-log-levels.
דוגמה:
מגדירים את רמת הרישום ביומן DEBUG כששולחים משימת Spark שקוראת קבצים ב-Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
דוגמה:
מגדירים את רמת כלי הרישום ביומן root לערך WARN, ואת רמת כלי הרישום ביומן com.example לערך INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
רמות רישום ביומן של Spark executor
כדי להגדיר את רמות הרישום ביומן של Spark executor:
הכנת קובץ תצורה של log4j והעלאה שלו ל-Cloud Storage
ומתאימים אותו אישית.כששולחים את העבודה, מציינים את קובץ התצורה.
דוגמה:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark מוריד את קובץ המאפיינים של Cloud Storage לספריית העבודה המקומית של המשימה, שמצוינת כ-file:<name> ב--Dlog4j.configuration.
יומני משימות של Dataproc ב-Logging
במאמר Dataproc job output and logs (פלט ויומנים של משימות Dataproc) מוסבר איך להפעיל יומנים של מנהלי התקנים של משימות Dataproc ב-Logging.
גישה ליומני משימות ב-Logging
אפשר לגשת ליומני משימות של Dataproc באמצעות Logs Explorer, הפקודה gcloud logging או Logging API.
המסוף
יומני מנהל המשימות של Dataproc ויומני מאגרי YARN מופיעים במשאב Cloud Dataproc Job.
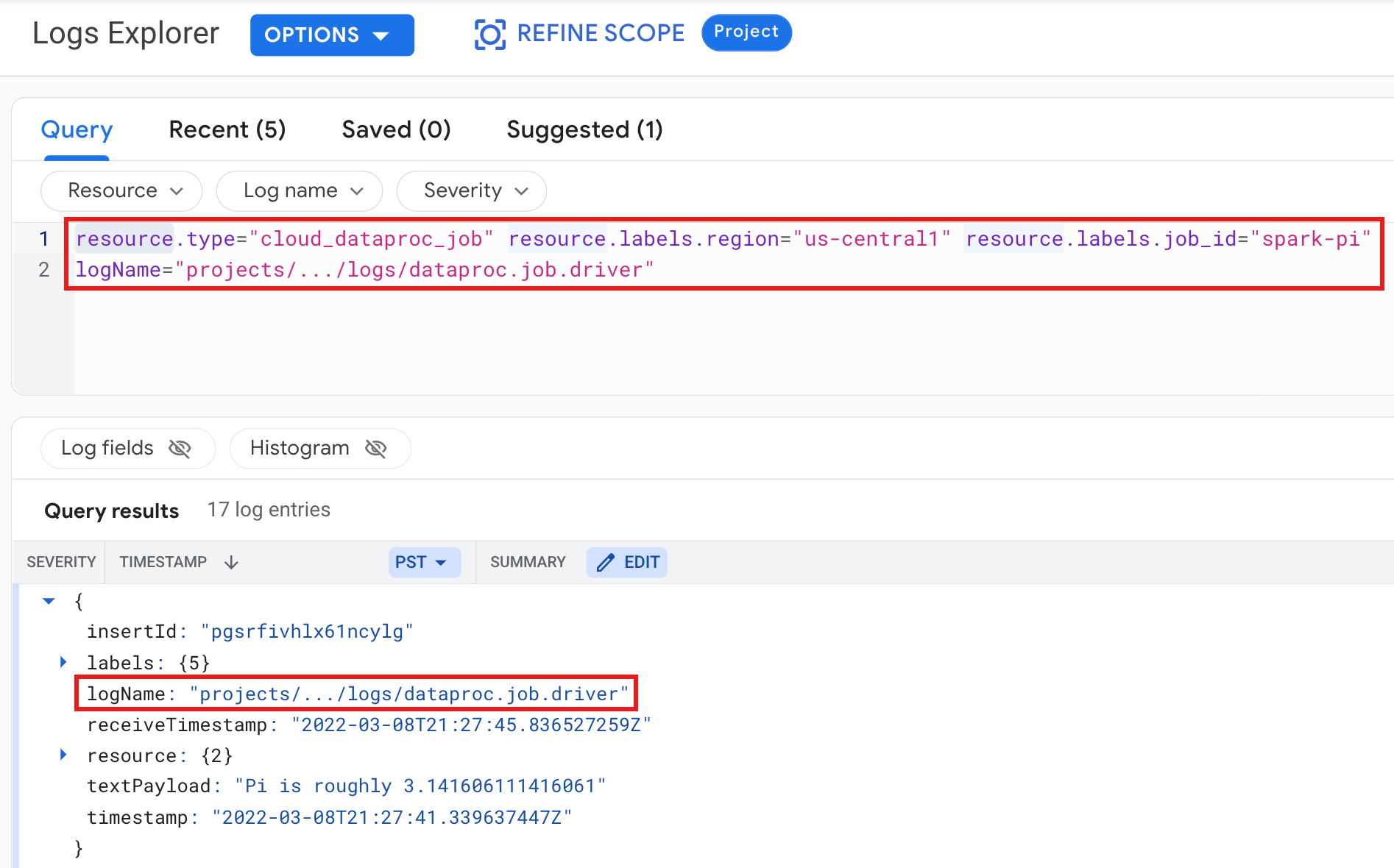
דוגמה: יומן של מנהל משימות אחרי הרצת שאילתה ב-Logs Explorer עם הבחירות הבאות:
- משאב:
Cloud Dataproc Job - שם היומן:
dataproc.job.driver
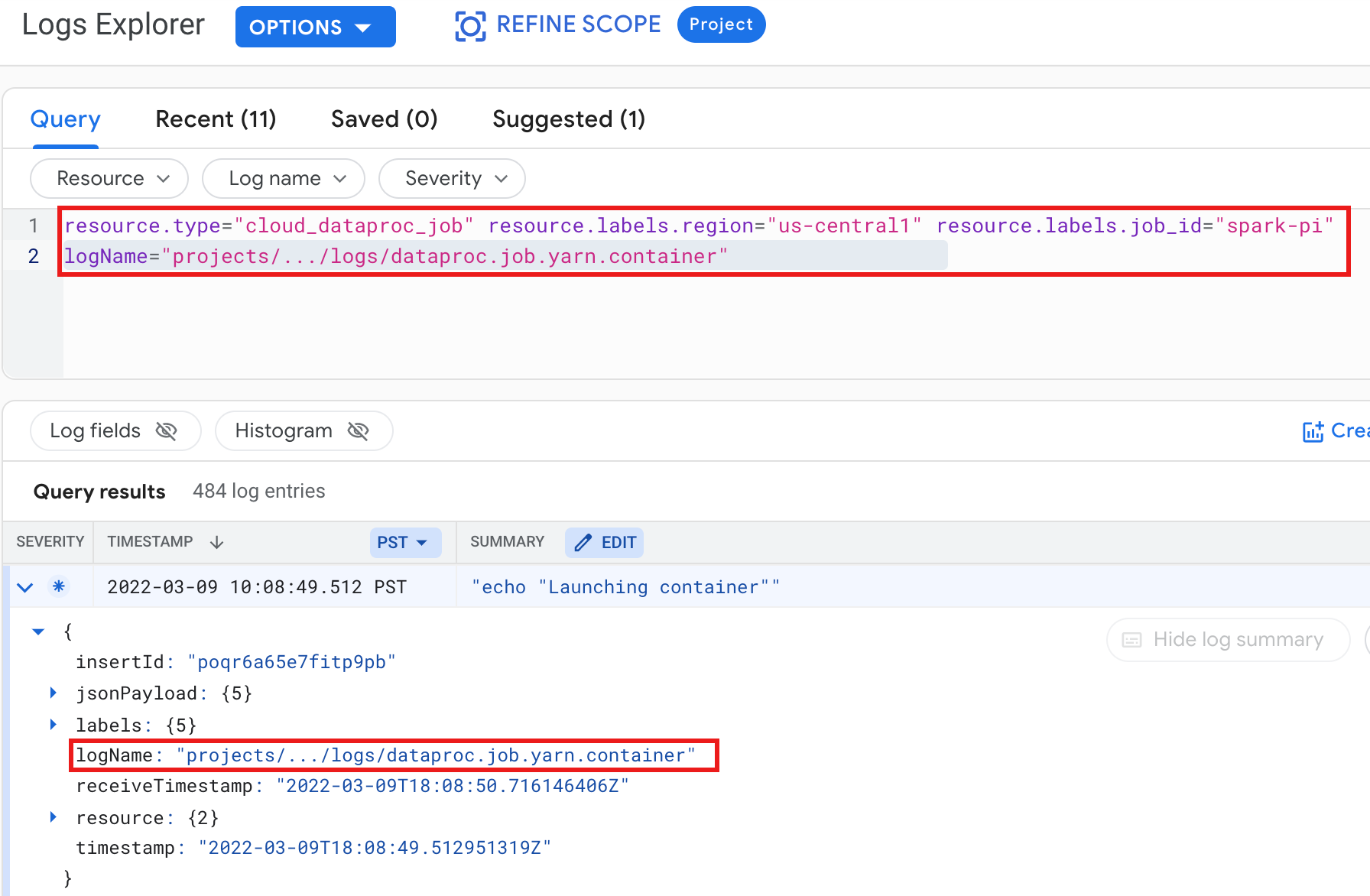
דוגמה: יומן של קונטיינר YARN אחרי הפעלת שאילתה ב-Logs Explorer עם הבחירות הבאות:
- משאב:
Cloud Dataproc Job - שם היומן:
dataproc.job.yarn.container
gcloud
אפשר לקרוא את הרשומות ביומן של המשימה באמצעות הפקודה gcloud logging read. ארגומנטי המשאבים צריכים להיות מוקפים במירכאות ("..."). הפקודה הבאה משתמשת בתוויות של אשכולות כדי לסנן את רשומות היומן שמוחזרות.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
פלט לדוגמה (חלקי):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
API ל-REST
אפשר להשתמש ב-API של רישום ביומן בארכיטקטורת REST כדי להציג רשימה של רשומות ביומן (ראו entries.list).
יומנים של אשכולות Dataproc ב-Logging
Dataproc מייצא את היומנים הבאים של אשכולות Apache Hadoop, Spark, Hive, Zookeeper ויומנים אחרים של אשכולות Dataproc אל Cloud Logging.
| סוג היומן | שם היומן | תיאור | הערות |
|---|---|---|---|
| יומני דמון | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 hadoop-mapred-historyserver zookeeper |
Journal node HDFS namenode HDFS secondary namenode Zookeeper failover controller YARN resource manager YARN timeline server Hive metastore Hive server2 Mapreduce job history server Zookeeper server |
|
| יומנים של שד Worker |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS datanode YARN nodemanager |
|
| יומני מערכת |
autoscaler google.dataproc.agent google.dataproc.startup |
יומן של מידרוג אוטומטי ב-Dataproc יומן של סוכן Dataproc יומן של סקריפט לטעינה בזמן ההפעלה ב-Dataproc + יומן של פעולת אתחול |
|
| יומנים מורחבים (נוספים) |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
כל היומנים בספריות המשנה /var/log/ שתואמות ל:knox (כולל gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
הגדרת המאפיין
dataproc:dataproc.logging.extended.enabled=false משביתה את איסוף היומנים המורחבים באשכול
|
| יומני מערכת של מכונות וירטואליות |
syslog |
יומני Syslog מצמתי המאסטר והעובדים של האשכול |
הגדרת הנכס
dataproc:dataproc.logging.syslog.enabled=false משביתה את איסוף יומני המערכת של המכונה הווירטואלית באשכול
|
גישה ליומני אשכול ב-Cloud Logging
אפשר לגשת ליומנים של אשכול Dataproc באמצעות Logs Explorer, באמצעות הפקודה gcloud logging או באמצעות Logging API.
המסוף
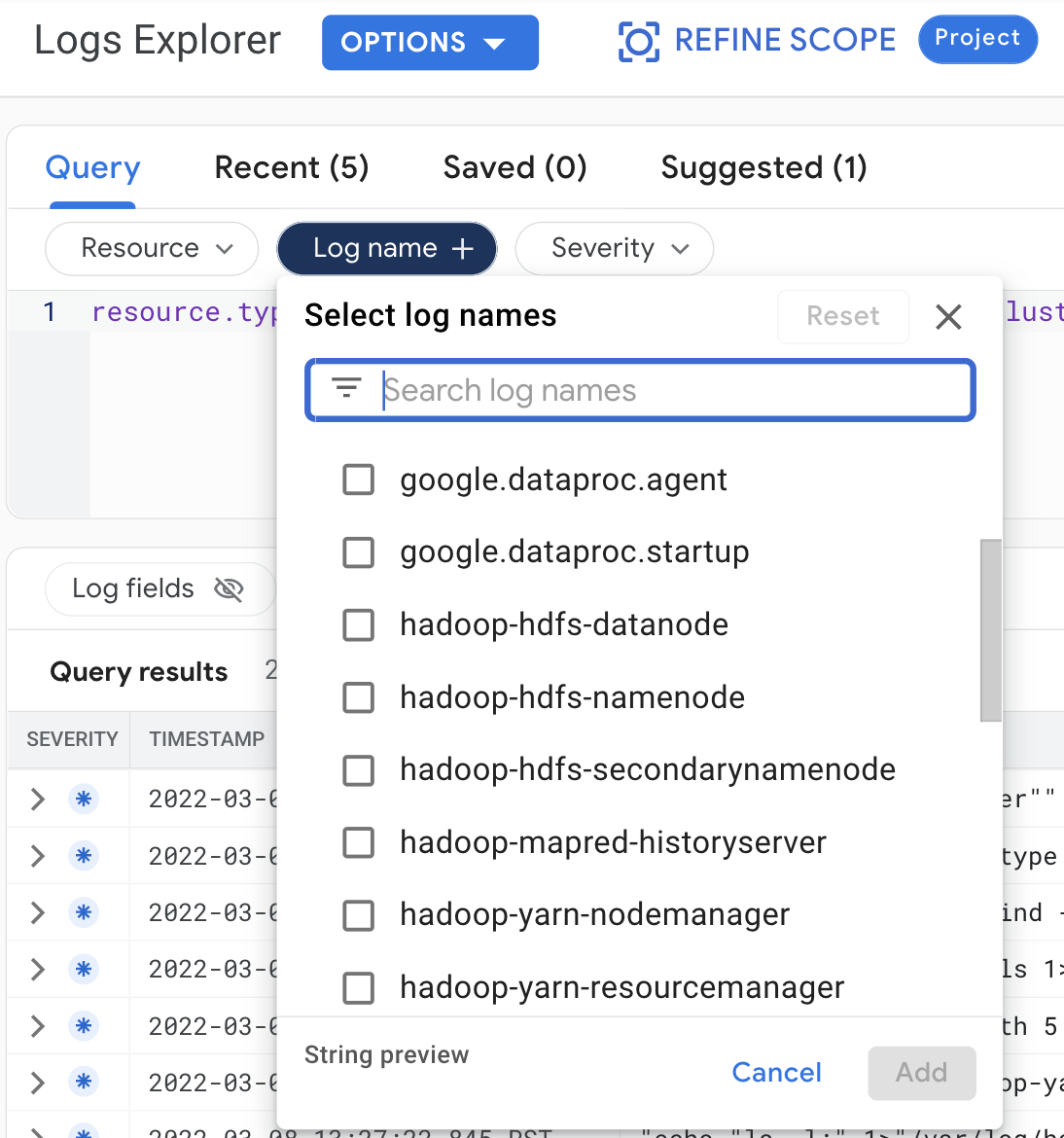
כדי להציג את יומני האשכול ב-Logs Explorer, בוחרים את השאילתות הבאות:
- משאב:
Cloud Dataproc Cluster - שם היומן: log name
gcloud
אפשר לקרוא את הרשומות ביומן של האשכול באמצעות הפקודה gcloud logging read. ארגומנטי המשאבים צריכים להיות מוקפים במירכאות ("..."). הפקודה הבאה משתמשת בתוויות של אשכולות כדי לסנן את רשומות היומן שמוחזרות.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
פלט לדוגמה (חלקי):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
API ל-REST
אפשר להשתמש ב-API של רישום ביומן בארכיטקטורת REST כדי להציג רשימה של רשומות ביומן (ראו entries.list).
הרשאות
כדי לכתוב יומנים ל-Logging, לחשבון השירות של המכונה הווירטואלית ב-Dataproc צריך להיות תפקיד IAM logging.logWriter. חשבון השירות שמוגדר כברירת מחדל ב-Dataproc כולל את התפקיד הזה. אם משתמשים בחשבון שירות בהתאמה אישית, צריך להקצות את התפקיד הזה לחשבון השירות.
הגנה על היומנים
כברירת מחדל, היומנים ב-Logging מוצפנים כל עוד הם מאוחסנים בענן. אפשר להפעיל מפתחות הצפנה בניהול הלקוח (CMEK) כדי להצפין את היומנים. מידע נוסף על תמיכה ב-CMEK זמין במאמרים בנושא ניהול המפתחות שמגנים על נתונים ב-Log Router וניהול המפתחות שמגנים על נתונים באחסון של Logging.