
Este documento descreve as ferramentas e os arquivos que podem ser usados para monitorar e solucionar problemas de cargas de trabalho em lote do Serverless para Apache Spark .
Solucionar problemas de cargas de trabalho no Google Cloud console
Quando um job em lote falha ou tem desempenho ruim, uma primeira etapa recomendada é abrir a página Detalhes do lote na página Lotes no Google Cloud console.
Usar a guia "Resumo": seu hub de solução de problemas
A guia Resumo, que é selecionada por padrão quando a página Detalhes do lote é aberta, mostra métricas importantes e registros filtrados para ajudar você a fazer uma avaliação inicial rápida da integridade do lote. Após essa avaliação inicial, é possível realizar uma análise mais detalhada usando ferramentas mais especializadas disponíveis na página Detalhes do lote, como a interface do Spark, a Análise de registros e o Gemini Cloud Assist.
Destaques das métricas de lote
A guia Resumo na página Detalhes do lote inclui gráficos que mostram valores importantes de métricas de carga de trabalho em lote. Os gráficos de métricas são preenchidos após a conclusão e oferecem uma indicação visual de possíveis problemas, como contenção de recursos, distorção de dados ou pressão de memória.
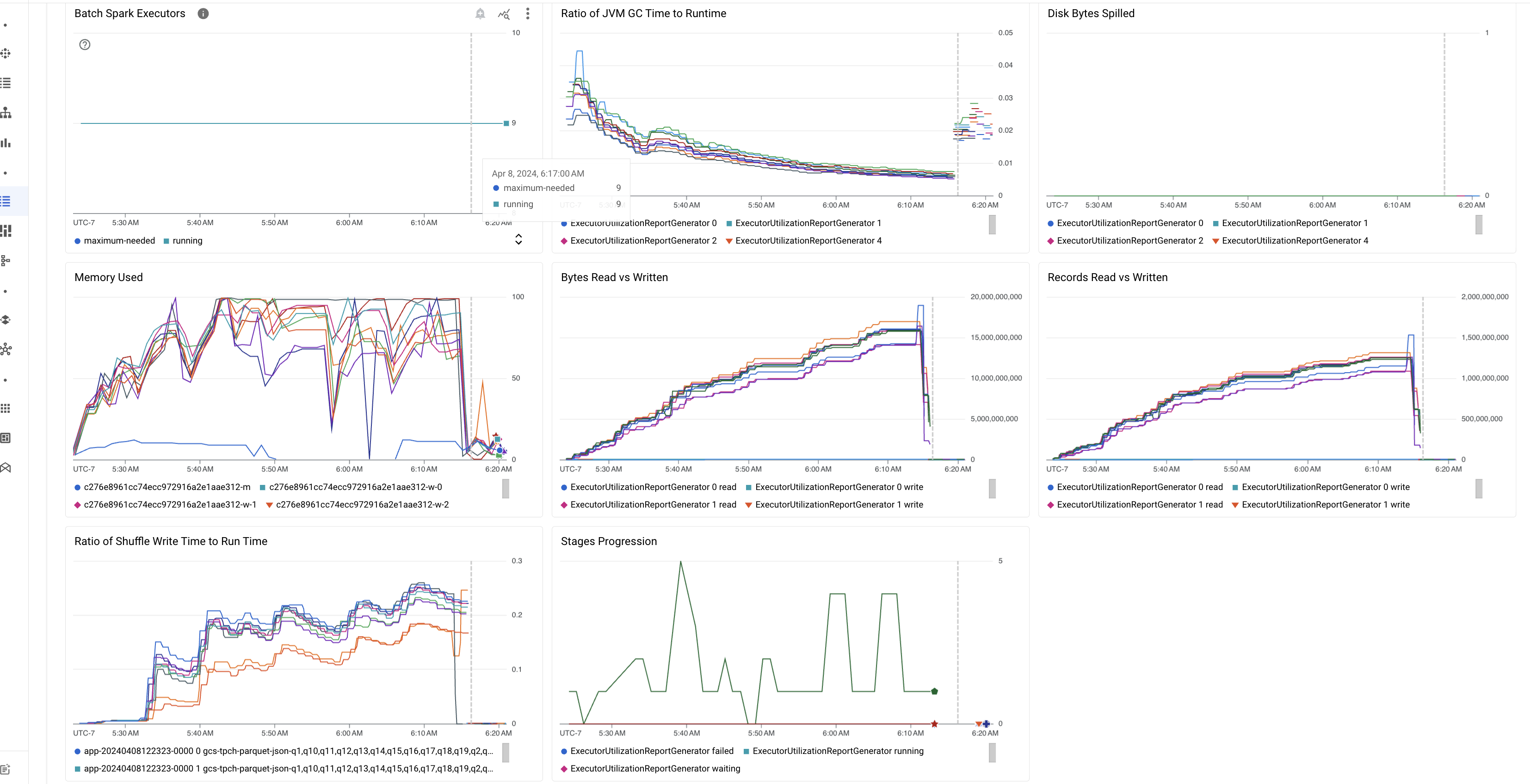
A tabela a seguir lista as métricas de carga de trabalho do Spark mostradas na página Detalhes do lote no Google Cloud console e descreve como os valores das métricas podem fornecer insights sobre o status e o desempenho da carga de trabalho.
| Métrica | O que ela mostra? |
|---|---|
| Métricas no nível do executor | |
| Proporção do tempo de GC da JVM para o tempo de execução | Essa métrica mostra a proporção do tempo de GC (coleta de lixo) da JVM para o tempo de execução por executor. Proporções altas podem indicar vazamentos de memória em tarefas executadas em executores específicos ou estruturas de dados ineficientes, o que pode levar a uma alta rotatividade de objetos. |
| Bytes de disco espalhados | Essa métrica mostra o número total de bytes de disco espalhados em diferentes executores. Se um executor mostrar bytes de disco espalhados, isso poderá indicar distorção de dados. Se a métrica aumentar ao longo do tempo, isso poderá indicar que há estágios com pressão de memória ou vazamentos de memória. |
| Bytes lidos e gravados | Essa métrica mostra os bytes gravados em comparação com os bytes lidos por executor. Grandes discrepâncias nos bytes lidos ou gravados podem indicar cenários em que junções replicadas levam à amplificação de dados em executores específicos. |
| Registros lidos e gravados | Essa métrica mostra os registros lidos e gravados por executor. Grandes números de registros lidos com poucos registros gravados podem indicar um gargalo na lógica de processamento em executores específicos, levando à leitura de registros durante a espera. Executores que ficam consistentemente atrasados em leituras e gravações podem indicar contenção de recursos nesses nós ou ineficiências de código específicas do executor. |
| Proporção do tempo de gravação de embaralhamento para o tempo de execução | A métrica mostra a quantidade de tempo que o executor passou no tempo de execução de embaralhamento em comparação com o tempo de execução geral. Se esse valor for alto para alguns executores, isso poderá indicar distorção de dados ou serialização de dados ineficiente. É possível identificar estágios com tempos de gravação de embaralhamento longos na interface do Spark. Procure tarefas atípicas nesses estágios que levam mais tempo do que o tempo médio para serem concluídas. Verifique se os executores com tempos de gravação de embaralhamento altos também mostram alta atividade de E/S de disco. A serialização mais eficiente e as etapas de particionamento adicionais podem ajudar. Gravações de registros muito grandes em comparação com leituras de registros podem indicar duplicação de dados não intencional devido a junções ineficientes ou transformações incorretas. |
| Métricas no nível do aplicativo | |
| Progressão de fases | Essa métrica mostra o número de fases com falha, em espera e em execução. Um grande número de fases com falha ou em espera pode indicar distorção de dados. Verifique as partições de dados e depure o motivo da falha da fase usando a guia Fases na interface do Spark. |
| Executores do Spark em lote | Essa métrica mostra o número de executores que podem ser necessários em comparação com o número de executores em execução. Uma grande diferença entre os executores necessários e em execução pode indicar problemas de escalonamento automático. |
| Métricas no nível da VM | |
| Memória usada | Essa métrica mostra a porcentagem de memória da VM em uso. Se a porcentagem principal for alta, isso poderá indicar que o driver está sob pressão de memória. Para outros nós de VM, uma porcentagem alta pode indicar que os executores estão ficando sem memória, o que pode levar a um alto vazamento de disco e a um tempo de execução de carga de trabalho mais lento. Use a interface do Spark para analisar executores e verificar se há tempo de GC alto e falhas de tarefas altas. Também depure o código do Spark para armazenamento em cache de conjuntos de dados grandes e transmissão desnecessária de variáveis. |
Registros do job
A página Detalhes do lote inclui uma seção Registros do job que lista avisos e erros filtrados dos registros do job (carga de trabalho em lote). Esse recurso permite a identificação rápida de problemas críticos sem a necessidade de analisar manualmente arquivos de registro extensos. É possível selecionar uma gravidade de registro (por exemplo, Error) no menu suspenso e adicionar um filtro de texto para restringir os resultados. Para realizar uma análise mais detalhada, clique no ícone Ver na Análise de registros
para abrir os registros de lote selecionados na Análise de registros.
Exemplo: a Análise de registros é aberta depois de escolher Errors no seletor de gravidade
na página Detalhes do lote no Google Cloud console.

Interface do Spark
A interface do Spark coleta detalhes de execução do Apache Spark de cargas de trabalho em lote do Serverless para Apache Spark. Não há cobrança pelo recurso da interface do Spark, que é ativado por padrão.
Os dados coletados pelo recurso da interface do Spark são mantidos por 90 dias. É possível usar essa interface da Web para monitorar e depurar cargas de trabalho do Spark sem precisar criar um servidor de histórico persistente.
Permissões e papéis de gerenciamento de identidade e acesso necessários
As permissões a seguir são necessárias para usar o recurso da interface do Spark com cargas de trabalho em lote.
Permissão de coleta de dados:
dataproc.batches.sparkApplicationWrite. Essa permissão precisa ser concedida à conta de serviço que executa cargas de trabalho em lote. Essa permissão está incluída noDataproc Workerpapel, que é concedido automaticamente à conta de serviço padrão do Compute Engine que o Serverless para Apache Spark usa por padrão (consulte Conta de serviço do Serverless para Apache Spark). No entanto, se você especificar uma conta de serviço personalizada para sua carga de trabalho em lote, será necessário adicionar adataproc.batches.sparkApplicationWritepermissão a essa conta de serviço (normalmente, concedendo à conta de serviço o papelWorkerdo Dataproc).Permissão de acesso à interface do Spark:
dataproc.batches.sparkApplicationRead. Essa permissão precisa ser concedida a um usuário para acessar a interface do Spark no Google Cloud console. Essa permissão está incluída nosDataproc Viewer,Dataproc EditoreDataproc Administratorpapéis. Para abrir a interface do Spark no Google Cloud console, é necessário ter um desses papéis ou um papel personalizado que inclua essa permissão.
Abrir a interface do Spark
A página da interface do Spark está disponível nas cargas de trabalho em lote do Google Cloud console.
Acesse a página Sessões interativas do Serverless para Apache Spark.
Clique em um ID do lote para abrir a página Detalhes do lote.
Clique em Ver interface do Spark no menu superior.
O botão Ver interface do Spark fica desativado nos seguintes casos:
- Se uma permissão necessária não for concedida
- Se você desmarcar a caixa de seleção Ativar interface do Spark na página Detalhes do lote
- Se você definir a propriedade
spark.dataproc.appContext.enabledcomofalsequando você enviar uma carga de trabalho em lote
Registros do Serverless para Apache Spark
O registro está ativado por padrão no Serverless para Apache Spark, e os registros de carga de trabalho persistem após a
conclusão de uma carga de trabalho. O Serverless para Apache Spark coleta registros de carga de trabalho em Cloud Logging.
É possível acessar os registros do Serverless para Apache Spark no recurso
Cloud Dataproc Batch na Análise de registros.
Consultar registros do Serverless para Apache Spark
A Análise de registros no Google Cloud console fornece um painel de consulta para ajudar você a criar uma consulta para examinar os registros de carga de trabalho em lote. Confira as etapas que podem ser seguidas para criar uma consulta para examinar os registros de carga de trabalho em lote:
- O projeto atual está selecionado. É possível clicar em Refinar projeto de escopo para selecionar um projeto diferente.
Defina uma consulta de registros em lote.
Use os menus de filtro para filtrar uma carga de trabalho em lote.
Em Todos os recursos, selecione o recurso Lote do Cloud Dataproc.
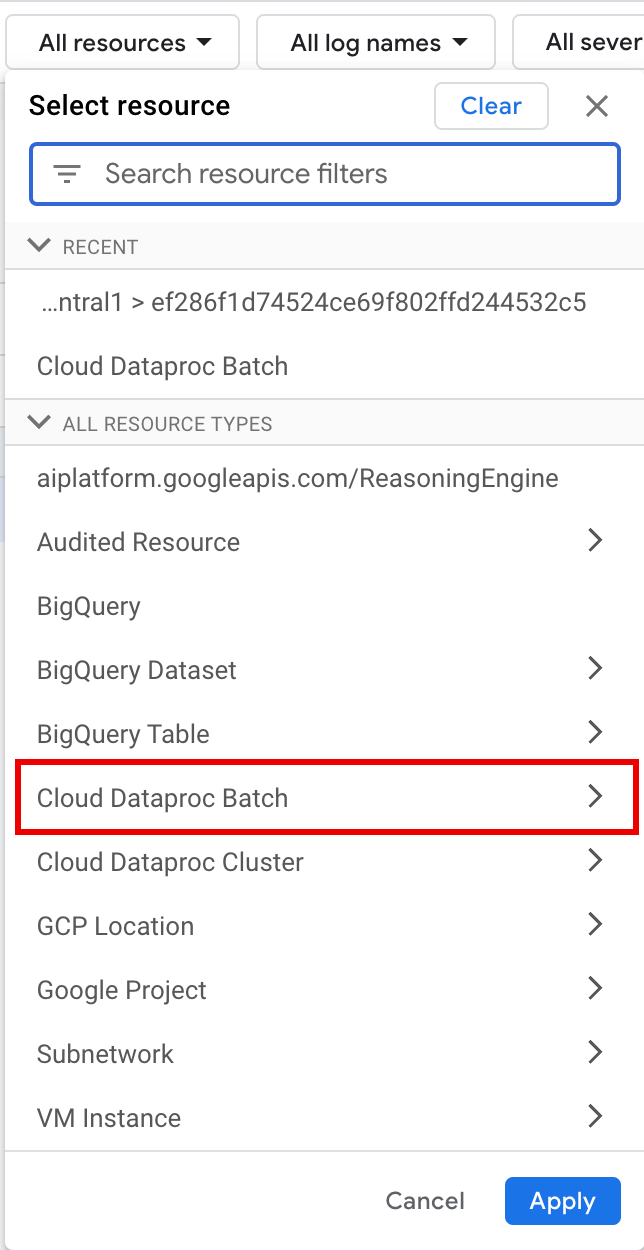
No painel Selecionar recurso , selecione o LOCAL do lote e o ID DO LOTE. Esses parâmetros de lote estão listados na página **Lotes** do Dataproc no Google Cloud console.
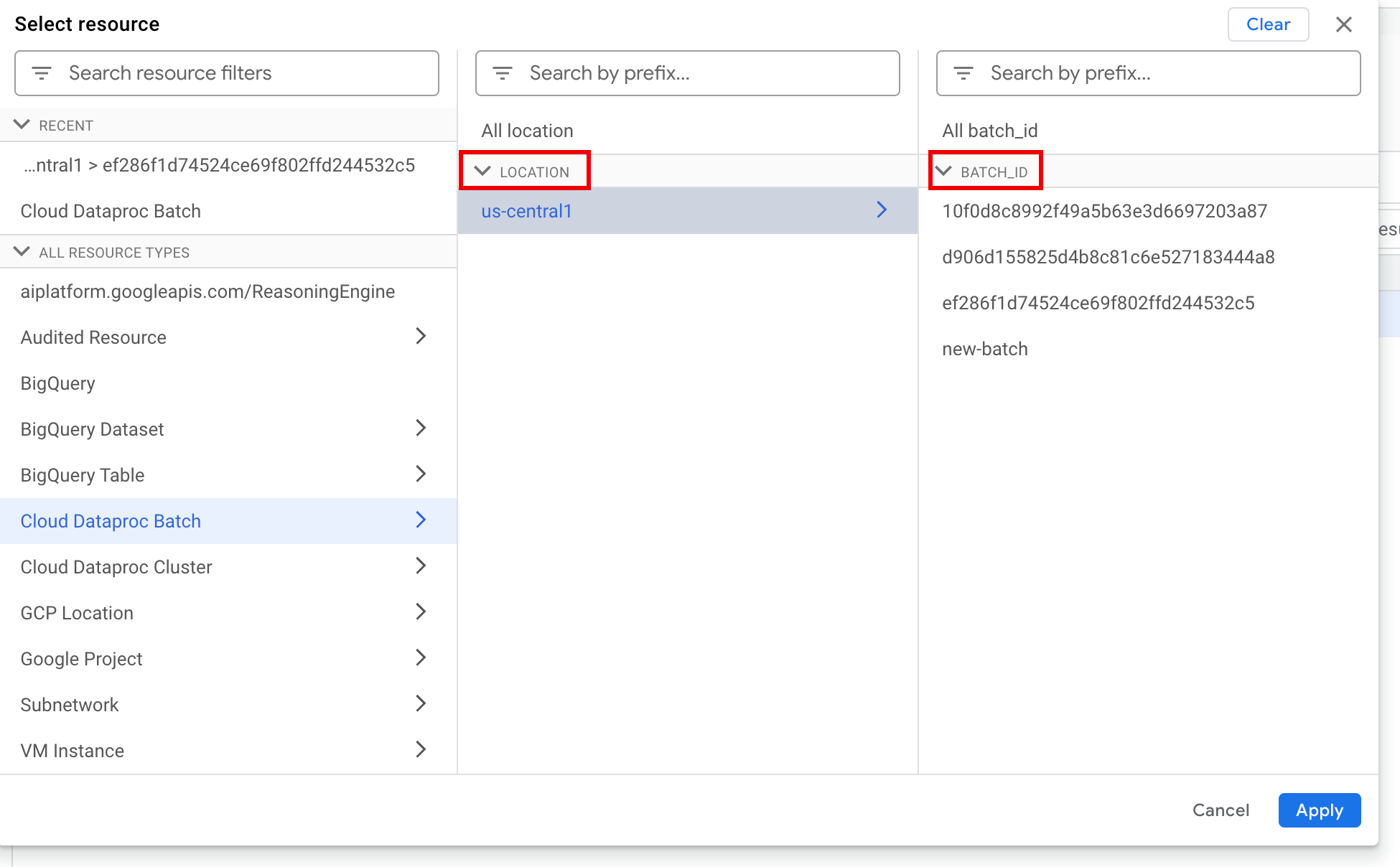
Clique em Aplicar.
Em Selecionar nomes de registros, digite
dataproc.googleapis.comna caixa Pesquisar nomes de registros para limitar os tipos de registro a serem consultados. Selecione um ou mais dos nomes de arquivos de registro listados.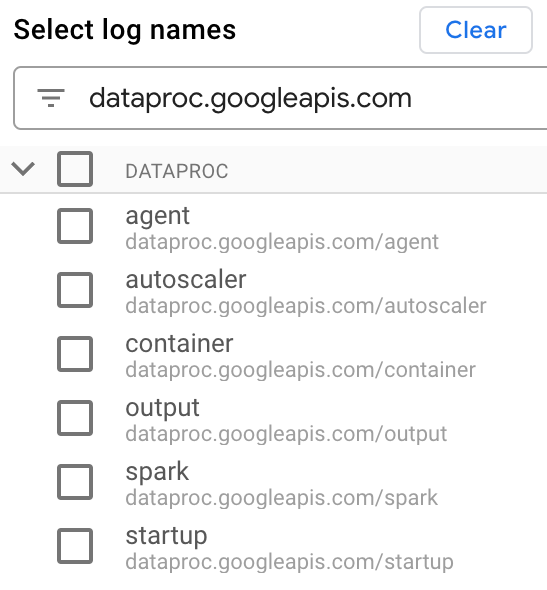
Use o editor de consultas para filtrar registros específicos da VM.
Especifique o tipo de recurso e o nome do recurso da VM, conforme mostrado no exemplo a seguir:
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
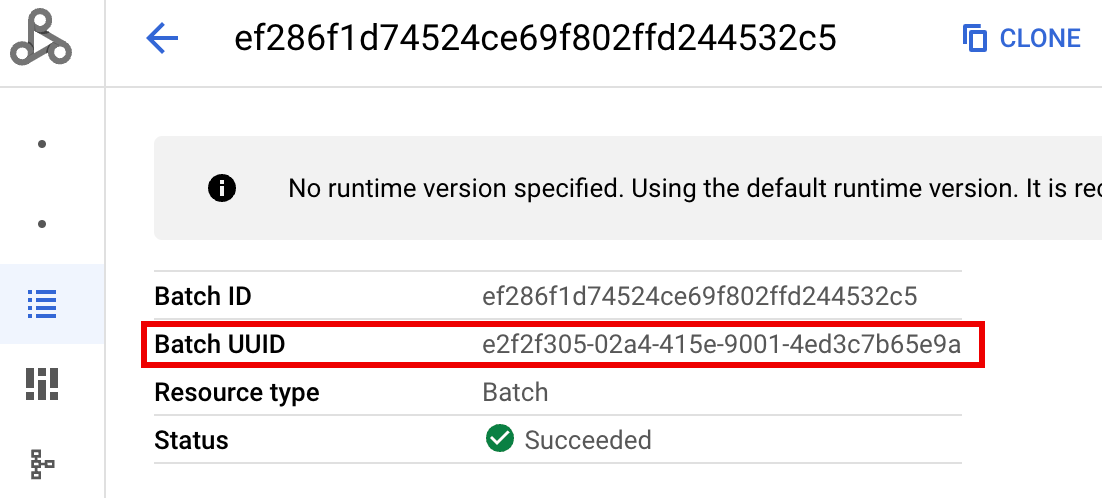
- BATCH_UUID: o UUID do lote está listado na página "Detalhes do lote"
no Google Cloud console, que é aberta quando você clica no
ID do lote na página Lotes.
Os registros em lote também listam o UUID do lote no nome do recurso da VM. Confira um exemplo de um batch driver.log:
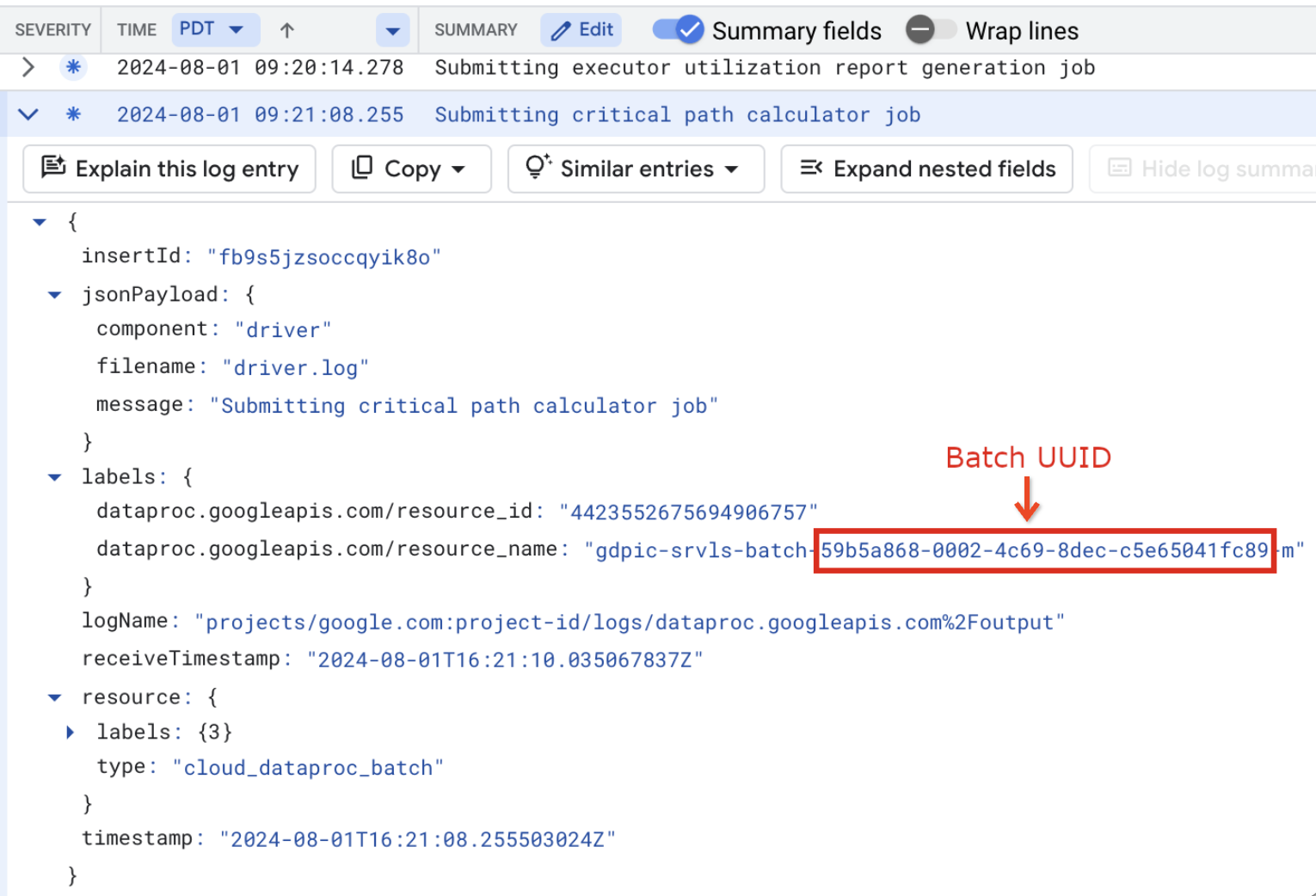
- BATCH_UUID: o UUID do lote está listado na página "Detalhes do lote"
no Google Cloud console, que é aberta quando você clica no
ID do lote na página Lotes.
Clique em Executar consulta.
Tipos de registro do Serverless para Apache Spark e consultas de exemplo
A lista a seguir descreve diferentes tipos de registro do Serverless para Apache Spark e fornece consultas de exemplo da Análise de registros para cada tipo de registro.
dataproc.googleapis.com/output: esse arquivo de registro contém a saída da carga de trabalho em lote. O Serverless para Apache Spark transmite a saída do lote para o namespaceoutput, e define o nome do arquivo comoJOB_ID.driver.log.Exemplo de consulta da Análise de registros para registros de saída:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark: o namespacesparkagrega registros do Spark para daemons e executores em execução nas VMs mestre e de worker do cluster do Dataproc. Cada entrada de registro inclui um rótulo de componentemaster,workerouexecutorpara identificar a origem do registro, da seguinte maneira:executor: registros de executores de código do usuário. Normalmente, esses são registros distribuídos.master: registros do mestre do gerenciador de recursos independente do Spark, que são semelhantes aos registros do YARN do Dataproc no Compute EngineResourceManagerworker: registros do worker do gerenciador de recursos independente do Spark, que são semelhantes aos registros do YARN do Dataproc no Compute EngineNodeManager.
Exemplo de consulta da Análise de registros para todos os registros no namespace
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
Exemplo de consulta da Análise de registros para registros de componentes independentes do Spark no
sparknamespace:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup: o namespacestartupinclui os registros de inicialização do lote (cluster). Todos os registros de script de inicialização estão incluídos. Os componentes são identificados por rótulo, por exemplo:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent: O namespaceagentagrega registros do agente do Dataproc. Cada entrada de registro inclui um rótulo de nome de arquivo que identifica a origem do registro.Exemplo de consulta da Análise de registros para registros de agente gerados por uma VM de worker especificada:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler: o namespaceautoscaleragrega registros do escalonador automático do Serverless para Apache Spark.Exemplo de consulta da Análise de registros para registros de agente gerados por uma VM de worker especificada:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
Para mais informações, consulte Registros do Dataproc.
Para informações sobre os registros de auditoria do Serverless para Apache Spark, consulte Registro de auditoria do Dataproc.
Métricas de carga de trabalho
O Serverless para Apache Spark fornece métricas de lote e do Spark que podem ser visualizadas na Análise de métricas ou na página Detalhes do lote no Google Cloud console.
Métricas de lote
As métricas de recursos batch do Dataproc fornecem insights sobre recursos de lote,
como o número de executores de lote. As métricas de lote são prefixadas com
dataproc.googleapis.com/batch.

Métricas do Spark
Por padrão, o Serverless para Apache Spark ativa a coleta de métricas do Spark disponíveis, a menos que você use propriedades de coleta de métricas do Spark para desativar ou substituir a coleta de uma ou mais métricas do Spark.
As métricas do Spark disponíveis
incluem métricas de driver e executor do Spark e métricas do sistema. As métricas do Spark disponíveis são prefixadas
com custom.googleapis.com/.

Configurar alertas de métricas
É possível criar alertas de métricas do Dataproc para receber avisos de problemas de carga de trabalho.
Criar tabelas
É possível criar gráficos que visualizam métricas de carga de trabalho usando a
Análise de métricas no
Google Cloud console. Por exemplo, é possível
criar um gráfico para mostrar disk:bytes_used e, em seguida, filtrar por batch_id.
Cloud Monitoring
O Monitoring usa metadados e métricas de carga de trabalho para fornecer insights sobre a integridade e o desempenho das cargas de trabalho do Serverless para Apache Spark. As métricas de carga de trabalho incluem métricas do Spark, métricas de lote e métricas de operação.
É possível usar Cloud Monitoring no Google Cloud console para explorar métricas, adicionar gráficos, criar painéis e criar alertas.
Criar painéis
É possível criar um painel para monitorar cargas de trabalho usando métricas de vários projetos e produtos diferentes Google Cloud . Para mais informações, consulte Criar e gerenciar painéis personalizados.
Servidor de histórico persistente
O Serverless para Apache Spark cria os recursos de computação necessários para executar uma carga de trabalho, executa a carga de trabalho nesses recursos e exclui os recursos quando a carga de trabalho é concluída. As métricas e os eventos de carga de trabalho não persistem após a conclusão de uma carga de trabalho. No entanto, é possível usar um servidor de histórico persistente (PHS, na sigla em inglês) para manter o histórico de aplicativos de carga de trabalho (registros de eventos) no Cloud Storage.
Para usar um PHS com uma carga de trabalho em lote, faça o seguinte:
Criar um servidor de histórico persistente (PHS) do Dataproc.
Especifique o PHS ao enviar uma carga de trabalho.
Use o Gateway de componentes para se conectar ao PHS e conferir detalhes do aplicativo, fases do programador, detalhes no nível da tarefa e informações do ambiente e do executor.
Ajuste automático
- Ativar o ajuste automático para o Serverless para Apache Spark: é possível ativar o ajuste automático para o Serverless para Apache Spark ao enviar cada carga de trabalho em lote recorrente do Spark usando o Google Cloud console, a CLI gcloud ou a API Dataproc.
Console
Siga as etapas abaixo para ativar o ajuste automático em cada carga de trabalho em lote recorrente do Spark:
No Google Cloud console, acesse a página Lotes do Dataproc.
Para criar uma carga de trabalho em lote, clique em Criar.
Na seção Contêiner, preencha o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A análise assistida pelo Gemini é aplicada à segunda e às cargas de trabalho subsequentes enviadas com esse nome de coorte. Por exemplo, especifique
TPCH-Query1como o nome da coorte para uma carga de trabalho programada que executa uma consulta TPC-H diária.Preencha outras seções da página Criar lote conforme necessário e clique em Enviar. Para mais informações, consulte Enviar uma carga de trabalho em lote.
gcloud
Execute o comando da CLI gcloud a seguir localmente em uma janela de terminal ou no Cloud Shell
para ativar o ajuste automático em cada carga de trabalho em lote recorrente do Spark:gcloud dataproc batches submit
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
Substitua:
- COMMAND: o tipo de carga de trabalho do Spark, como
Spark,PySpark,Spark-Sql, ouSpark-R. - REGION: a região em que a carga de trabalho será executada.
- COHORT: o nome da coorte, que
identifica o lote como um de uma série de cargas de trabalho recorrentes.
A análise assistida pelo Gemini é aplicada à segunda e às cargas de trabalho subsequentes enviadas
com esse nome de coorte. Por exemplo, especifique
TPCH Query 1como o nome da coorte para uma carga de trabalho programada que executa uma consulta TPC-H diária.
API
Inclua o RuntimeConfig.cohort
nome em uma solicitação batches.create
para ativar o ajuste automático em cada carga de trabalho em lote recorrente do Spark. O ajuste automático é aplicado à segunda e às cargas de trabalho subsequentes enviadas com esse nome de coorte. Por exemplo, especifique TPCH-Query1 como o nome da coorte para uma carga de trabalho programada que executa uma consulta TPC-H diária.
Exemplo:
...
runtimeConfig:
cohort: TPCH-Query1
...