
As cargas de trabalho em lote e as sessões interativas do Serviço Gerenciado para Apache Spark são executadas com credenciais de usuário final ou de conta de serviço. Quando as credenciais de conta de serviço são usadas, a conta de serviço usada para executar cargas de trabalho em lote ou sessões interativas depende da versão de tempo de execução do lote ou da sessão.
Contas de serviço de ambiente de execução anteriores à versão 3.0
As versões do ambiente de execução do Spark anteriores a 3.0 com credenciais de conta de serviço usam a conta de serviço padrão do Compute Engine ou uma conta de serviço personalizada especificada pelo usuário para enviar uma carga de trabalho em lote ou criar uma sessão interativa.
Contas de serviço do ambiente de execução 3.0 ou mais recente
As versões 3.0 e mais recentes do ambiente de execução do Spark com credenciais de conta de serviço usam uma
conta de serviço personalizada especificada pelo usuário para enviar uma carga de trabalho em lote ou criar uma
sessão interativa.
Os ambientes de execução do Serviço Gerenciado para Apache Spark 3.0 e versões mais recentes criam a conta de serviço Agente de serviço do nó do Dataproc Resource Manager, service-project-number@gcp-sa-dataprocrmnode.iam.gserviceaccount.com, com o papel Agente de serviço do nó do Dataproc Resource Manager em um projeto do usuário do Serviço Gerenciado para Apache Spark Google Cloud . Essa conta de serviço realiza as seguintes operações do sistema em recursos do Serviço Gerenciado para Apache Spark localizados no projeto em que uma carga de trabalho é criada:
- Cloud Logging e Cloud Monitoring
- Operações básicas do Resource Manager no Serviço Gerenciado para Apache Spark, como
get,heartbeatemintOAuthToken
Ver e gerenciar papéis de conta de serviço do IAM
Para ver e gerenciar os papéis concedidos à conta de serviço da sessão ou da carga de trabalho em lote, faça o seguinte:
No console do Google Cloud , acesse a página IAM.
Clique em Incluir atribuições de papel fornecidas pelo Google.
Confira os papéis listados para a carga de trabalho em lote ou a conta de serviço padrão ou personalizada da sessão.
A imagem a seguir mostra o papel Worker do Serviço Gerenciado para Apache Spark necessário listado para a conta de serviço padrão do Compute Engine,
project_number-compute@developer.gserviceaccount.com, que o Serviço Gerenciado para Apache Spark usa por padrão como a conta de serviço da carga de trabalho ou da sessão.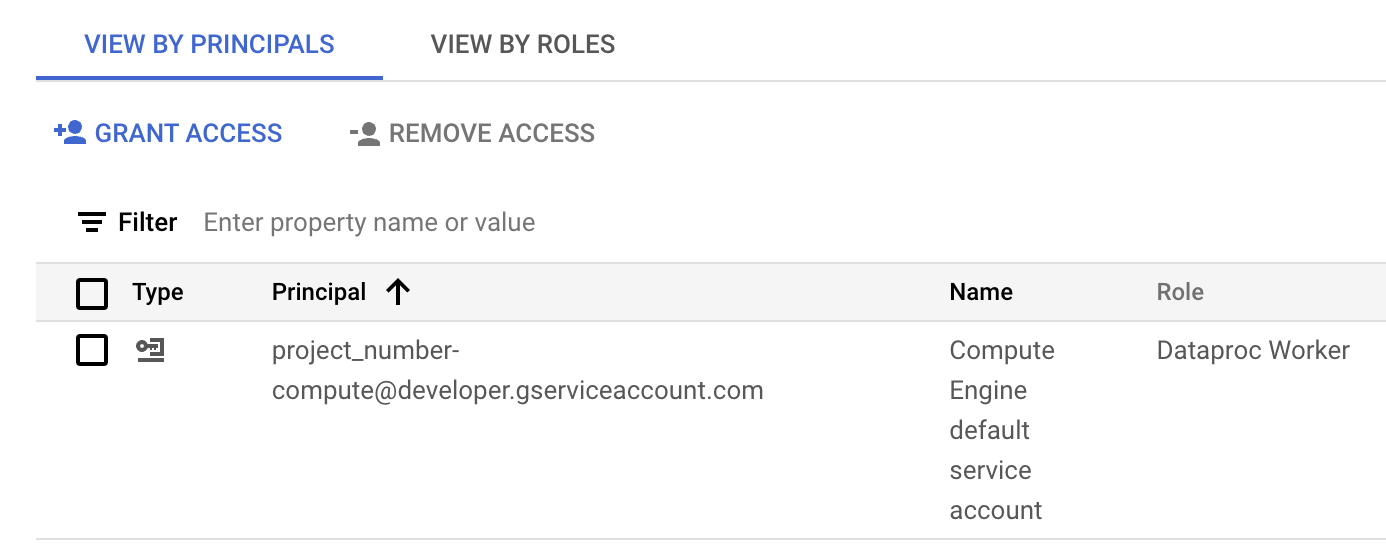
O papel de worker do Serviço Gerenciado para Apache Spark atribuído à conta de serviço padrão do Compute Engine na seção IAM do console do Google Cloud . Clique no ícone de lápis exibido na linha da conta de serviço para conceder ou remover papéis da conta de serviço.
Como usar uma conta de serviço entre projetos
É possível enviar uma carga de trabalho em lote que usa uma conta de serviço de um projeto diferente daquele em que a carga de trabalho em lote está (o projeto em que o lote é enviado). Nesta seção, o projeto em que
a conta de serviço está localizada é chamado de service account project, e o
projeto em que o lote é enviado é chamado de batch project.
Por que usar uma conta de serviço entre projetos para executar uma carga de trabalho em lote? Um motivo possível é se a conta de serviço no outro projeto tiver recebido papéis do IAM que fornecem acesso refinado aos recursos desse projeto.
Etapas da configuração
Os exemplos nesta seção se aplicam ao envio de uma carga de trabalho em lote
executada com uma versão de ambiente de execução anterior a 3.0.
No projeto da conta de serviço:
Ative a API Dataproc.
Funções necessárias para ativar APIs
Para ativar as APIs, é necessário ter o papel do IAM de administrador de uso do serviço (
roles/serviceusage.serviceUsageAdmin), que contém a permissãoserviceusage.services.enable. Saiba como conceder papéis.Conceda à sua conta de e-mail (o usuário que está criando o cluster) o papel de Usuário da conta de serviço no projeto da conta de serviço ou, para um controle mais granular, na conta de serviço do projeto da conta de serviço.
Para mais informações, consulte Gerenciar o acesso a projetos, pastas e organizações para conceder papéis no nível do projeto e Gerenciar o acesso a contas de serviço para conceder papéis no nível da conta de serviço.
Exemplos da CLI gcloud:
O exemplo de comando a seguir concede ao usuário o papel de Usuário da conta de serviço no nível do projeto:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Observações:
USER_EMAIL: informe o endereço de e-mail da sua conta de usuário no formatouser:user-name@example.com.
O exemplo de comando a seguir concede ao usuário o papel de usuário da conta de serviço no nível da conta de serviço:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Observações:
USER_EMAIL: informe o endereço de e-mail da sua conta de usuário no formato:user:user-name@example.com.
Conceda à conta de serviço o papel de Trabalhador do Serviço Gerenciado para Apache Spark no projeto em lote.
Exemplo da CLI gcloud:
gcloud projects add-iam-policy-binding BATCH_PROJECT_ID \ --member=serviceAccount:SERVICE_ACCOUNT_NAME@SERVICE_ACCOUNT_PROJECT_ID.iam.gserviceaccount.com \ --role="roles/dataproc.worker"
No projeto em lote:
Conceda à conta de serviço do agente de serviço do Managed Service for Apache Spark os papéis de Usuário da conta de serviço e Criador de token da conta de serviço no projeto da conta de serviço ou, para um controle mais granular, na conta de serviço no projeto da conta de serviço. Ao fazer isso, você permite que a conta de serviço do agente de serviço do Serviço Gerenciado para Apache Spark no projeto em lote crie tokens para a conta de serviço no projeto da conta de serviço.
Para mais informações, consulte Gerenciar o acesso a projetos, pastas e organizações para conceder papéis no nível do projeto e Gerenciar o acesso a contas de serviço para conceder papéis no nível da conta de serviço.
Exemplos da CLI gcloud:
Os comandos a seguir concedem à conta de serviço do agente de serviço do Serviço Gerenciado para Apache Spark no projeto em lote os papéis de usuário da conta de serviço e criador de token da conta de serviço no nível do projeto:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Os comandos de exemplo a seguir concedem à conta de serviço do agente de serviço do Serviço Gerenciado para Apache Spark no projeto em lote os papéis de usuário da conta de serviço e criador de token da conta de serviço no nível da conta de serviço:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Conceda à conta de serviço do agente de serviço do Compute Engine no projeto em lote o papel Criador de token da conta de serviço no projeto da conta de serviço ou, para um controle mais granular, na conta de serviço no projeto da conta de serviço. Ao fazer isso, você concede à conta de serviço do agente de serviço do Compute Agent no projeto em lote a capacidade de criar tokens para a conta de serviço no projeto da conta de serviço.
Para mais informações, consulte Gerenciar o acesso a projetos, pastas e organizações para conceder papéis no nível do projeto e Gerenciar o acesso a contas de serviço para conceder papéis no nível da conta de serviço.
Exemplos da CLI gcloud:
O exemplo de comando a seguir concede à conta de serviço do agente de serviço do Compute Engine no projeto em lote o papel de criador de token da conta de serviço no nível do projeto:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
O exemplo de comando a seguir concede à conta de serviço do agente de serviço do Compute Engine no projeto do cluster o papel de criador de token da conta de serviço no nível da conta de serviço:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Enviar a carga de trabalho em lote
Depois de concluir as etapas de configuração, você poderá enviar uma carga de trabalho em lote. Especifique a conta de serviço no projeto dela como a conta a ser usada para a carga de trabalho em lote.
Resolver problemas de falhas baseadas em permissões
Permissões incorretas ou insuficientes para a conta de serviço usada pela sua carga de trabalho ou sessão em lote podem causar falhas na criação de lotes ou sessões que informam uma mensagem de erro "Falha na inicialização do nó de computação do driver para lote em 600 segundos". Esse erro indica que o driver do Spark não pôde ser iniciado dentro do período de tempo limite alocado, geralmente devido à falta de acesso necessário aos recursos do Google Cloud .
Para resolver esse problema, verifique se a conta de serviço tem os seguintes papéis ou permissões mínimas:
- Função Managed Service for Apache Spark Worker (
roles/dataproc.worker): concede as permissões necessárias para que o Serviço Gerenciado para Apache Spark gerencie e execute cargas de trabalho e sessões do Spark. - Leitor de objetos do Storage (
roles/storage.objectViewer), Criador de objetos do Storage (roles/storage.objectCreator) ou Administrador de objetos do Storage (roles/storage.admin): se o aplicativo Spark ler ou gravar em buckets do Cloud Storage, a conta de serviço precisará das permissões adequadas para acessar os buckets. Por exemplo, se os dados de entrada estiverem em um bucket do Cloud Storage, será necessárioStorage Object Viewer. Se o aplicativo gravar a saída em um bucket do Cloud Storage, será necessárioStorage Object CreatorouStorage Object Admin. - Editor de dados do BigQuery (
roles/bigquery.dataEditor) ou Leitor de dados do BigQuery (roles/bigquery.dataViewer): se o aplicativo Spark interagir com o BigQuery, verifique se a conta de serviço tem as funções do BigQuery adequadas. - Permissões do Cloud Logging:a conta de serviço precisa de permissões
para gravar registros no Cloud Logging e fazer depuração de maneira eficaz. Normalmente, o papel
Logging Writer(roles/logging.logWriter) é suficiente.
Falhas comuns relacionadas a permissões ou acesso
Função
dataproc.workerausente: sem essa função principal, a infraestrutura do Serviço Gerenciado para Apache Spark não pode provisionar e gerenciar corretamente o nó de driver.Permissões insuficientes do Cloud Storage: se o aplicativo Spark tentar ler dados de entrada ou gravar dados de saída em um bucket do Cloud Storage sem as permissões necessárias da conta de serviço, o driver poderá não ser inicializado por falta de acesso a recursos críticos.
Problemas de rede ou firewall: o VPC Service Controls ou as regras de firewall podem bloquear inadvertidamente o acesso da conta de serviço às APIs ou aos recursos do Google Cloud .
Para verificar e atualizar as permissões da conta de serviço:
- Acesse a página IAM e administrador > IAM no console do Google Cloud .
- Localize a conta de serviço usada para suas sessões ou cargas de trabalho em lote.
- Verifique se os papéis necessários estão atribuídos. Se não estiverem, adicione.
Para uma lista de papéis e permissões do Serviço Gerenciado para Apache Spark, consulte Permissões do Serviço Gerenciado para Apache Spark e papéis do IAM.