
Knowledge Catalog הוא קטלוג נתונים מבוסס-Gemini שמספק הקשר עסקי אוניברסלי וניהול לכלל נכסי הנתונים שלכם. הוא בונה גרף הקשר דינמי שמבסס את סוכני ה-AI על האמת הארגונית ומפחית את ההזיות, על ידי חילוץ אוטומטי של סמנטיקה מנתונים מובְנים ומלא מובְנים. צוותי נתונים ומפתחי AI משתמשים ב-Knowledge Catalog כדי לגלות נתונים, לאכוף מדיניות ולאחזר הקשר עשיר גם לניתוח וגם לאפליקציות אוטונומיות. לצפייה בהדרכה מפורטת על Knowledge Catalog, אפשר לראות את הסרטון שמוטמע כאן.
Dataplex Universal Catalog נקרא עכשיו Knowledge Catalog
כדי לשקף טוב יותר את החזון של איחוד ניהול הנתונים עם יכולות של AI גנרטיבי, Dataplex Universal Catalog נקרא עכשיו Knowledge Catalog. השינוי בשם המוצר מייצג מעבר ממאגר נתונים פסיבי רגיל של מטא-נתונים לגרף הקשר פעיל מבוסס-AI.
למה Dataplex הפך ל-Knowledge Catalog
ככל שהארגונים מאיצים את האימוץ של AI גנרטיבי, סוכני AI צריכים הקשר עסקי מעמיק כדי לספק תשובות מדויקות ומבוססות. Knowledge Catalog מגשר על הפער בין משילות מידע ארגוני לבין תהליכי עבודה של סוכני AI.
מה ההבדל בין Dataplex לבין Knowledge Catalog
העדכונים ב-Knowledge Catalog משקפים יכולות חדשות שמבוססות על AI. בניגוד לקטלוגים פסיביים רגילים, Knowledge Catalog אוסף באופן אוטומטי מטא-נתונים, לוגיקה עסקית ויחסי נתונים לגרף הקשר מאוחד. הגרף הזה מספק את ה-Enterprise Truth האמינה שהסוכנים של AI צריכים כדי להריץ משימות מורכבות בצורה מדויקת. הוא משתמש בתכונות כמו אוצרות הקשר אוטומטי, שאילתות לדוגמה מאומתות ושילובים מקומיים ומרוחקים של Model Context Protocol (MCP).
מה לא ישתנה
הפריסות, ממשקי ה-API וההגדרות הקיימים של Dataplex ימשיכו לפעול. התכונות המרכזיות כמו גילוי נתונים, שושלת, איכות נתונים ומילוני מונחים עסקיים לא השתנו ונתמכות. הנתונים הקיימים שלכם, ההיבטים וההגדרות עוברים לחוויה החדשה של קטלוג הידע בלי שתצטרכו לבצע העברה ידנית, להעביר נתונים או לחוות השבתה.
ממשקי API וספריות לקוח
המיתוג מחדש ל-Knowledge Catalog לא משנה את נקודות הקצה הקיימות של ה-API, את הפקודות או את ספריות הלקוח.gcloud dataplex אתם יכולים להמשיך להשתמש בממשקי Knowledge Catalog API ובספריות הלקוח כדי ליצור אינטראקציה עם Knowledge Catalog:
API בארכיטקטורת REST. מאמרי עזרה בנושא Knowledge Catalog REST API
ספריות לקוח. מתחילים להשתמש ב-Knowledge Catalog בשפה הרצויה באמצעות ספריות הלקוח של Knowledge Catalog.
פקודות gcloud. ניהול משאבים ב-Knowledge Catalog באמצעות קבוצת הפקודות
gcloud dataplex. אפשר לעיין במדריך העזר לפקודות gcloud Dataplex.
איך Knowledge Catalog עובד
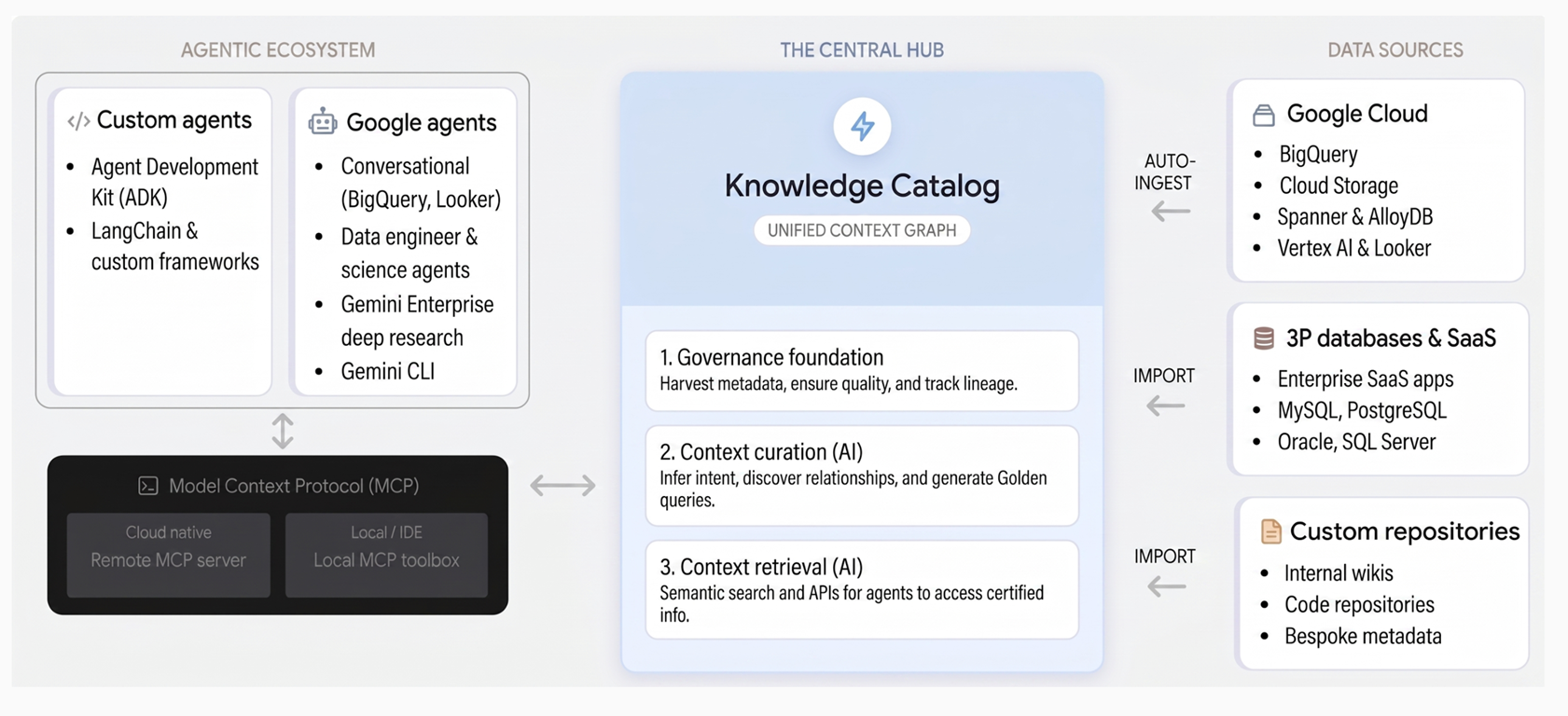
Knowledge Catalog מאחד את הממשל וההקשר באמצעות שלושה עקרונות מרכזיים:
בסיס לממשל. Knowledge Catalog אוסף באופן אוטומטי מטא-נתונים טכניים משירותים כמו BigQuery, AlloyDB ל-PostgreSQL ו-Spanner, וגם ממערכות של צד שלישי. Google Cloud הוא יוצר בסיס נתונים מהימן באמצעות מילון המונחים הארגוני מרכזי, בדיקות של איכות הנתונים, זיהוי אנומליות ומשילות מבוססת-מדיניות.
התאמה להקשר השירות משתמש ב-Gemini כדי להסיק כוונות עסקיות על ידי ניתוח סכימות, יומני שאילתות ומודלים סמנטיים בנתונים שלכם. הוא יוצר תיאורים בשפה טבעית, מגלה קשרים ומציע תבניות SQL מאומתות בצורה של שאילתות לדוגמה שמציגות לוגיקה עסקית מורכבת.
אחזור הקשר. סוכני AI ואפליקציות יכולים לגלות נכסים באופן מיידי ולאחזר הקשר מועשר באמצעות חיפוש סמנטי וכלים שתומכים ב-Model Context Protocol (MCP). כך סוכנים יכולים לגשת לנתונים הארגוניים כדי לקבל החלטות מהימנות.
הדיאגרמה הבאה ממחישה את הארכיטקטורה של Knowledge Catalog ואיך הוא מאחד בין משילות מידע (data governance) לבין תהליכי עבודה של בינה מלאכותית גנרטיבית:
תרחישים נפוצים לדוגמה
Knowledge Catalog עוזר למהנדסי נתונים, למדעני נתונים ולמפתחי AI לפתור אתגרים שקשורים לניהול נתונים ולפיתוח AI:
העשרת נתונים ל-AI. אפשר להשתמש בתובנות לגבי נתונים לא מובְנים כדי לחלץ באופן אוטומטי מטא-נתונים וישויות מקבצים לא מובְנים כמו קובצי PDF ב-Cloud Storage. כך מודלים של AI יכולים לגשת לנתונים לא פעילים ולידע ארגוני.
הפחתת הזיות של AI. מספקים לסוכני AI דוגמאות מאומתות מראש של שאילתות ומגבלות סמנטיות, כדי לאפשר להם לבצע אחזור מורכב של נתונים ברמת דיוק גבוהה יותר.
האצת גילוי הנתונים. שימוש בחיפוש סמנטי ובגרף הקשר המרכזי כדי לאתר נכסי נתונים רלוונטיים במקורות שונים לצורך ניתוח ותהליכי עבודה של מדעי הנתונים.
יצירה אוטומטית של מוצרי נתונים. הסקת קשרים בין הנתונים בנכסי הנתונים שלכם כדי לארוז נכסים במוצרי נתונים עצמאיים עם הסכמי רמת שירות (SLA) מובנים ומגבלות ניהול.
דוגמאות לתהליכי עבודה ב-Knowledge Catalog
כדי להבין איך אפשר ליצור את תרשים ההקשר ולנהל את נכסי הנתונים, כדאי לעיין בדוגמה הבאה שממחישה איך חברת קמעונאות אונליין יכולה להשתמש בתכונות הבאות של Knowledge Catalog:
גילוי וקטלוג של נתונים. הקמעונאי מבצע אוטומטית המרה של נתוני עסקאות ואוסף מטא-נתונים משירותים כמו Google Cloud BigQuery, Pub/Sub ו-Cloud Storage. בנוסף, השירות מייבא מטא-נתונים ממסדי נתונים מותאמים אישית של מלאי כדי ליצור תצוגה מאוחדת של כל נתוני הקמעונאות. מידע נוסף מופיע במאמר בנושא גילוי נתונים.
חיפוש נכסי נתונים מדען נתונים מוצא את נכסי נתוני הלקוחות שהוא צריך באמצעות מנוע החיפוש של Knowledge Catalog עם סינון לפי מאפיינים, חיפוש סמנטי בשפה טבעית ואופרטורים לוגיים. מידע נוסף מופיע במאמר חיפוש נכסי נתונים.
העשרת הנתונים בהקשר עסקי. צוות ניהול הנתונים מגדיר מונחים מעולם הקמעונאות (כמו 'ערך חיי המשתמש' או 'מק"ט') באמצעות מילוני מונחים עסקיים, ומשתמש בתובנות מבוססות-AI כדי ליצור באופן אוטומטי תיאורים לטבלאות מוצרים חדשות. הם גם מוסיפים באופן ידני מטא-נתונים מובְנים ותגים (היבטים) מותאמים אישית באופן אחיד לכל הנכסים שלהם. מידע נוסף זמין במאמרים ניהול היבטים והוספת מטא-נתונים וניהול מילון המונחים הארגוני.
הבנת הקשרים בין נתונים באמצעות שושלת נתונים. צוות ההנדסה עוקב באופן אוטומטי אחר שרשרת מקורות הנתונים כדי לראות איך נתוני ההזמנות עוברים, איך הם משתנים ואיך הם נצרכים במערכות שלהם. הם משתמשים בגרפים של שושלת נתונים כדי לפתור בעיות בפייפליינים של דיווח, לבצע ניתוח של שורש הבעיה בשגיאות בתהליך התשלום ולהבטיח תאימות. מידע נוסף זמין במאמר סקירה כללית על שרשרת מקורות הנתונים.
נתוני הפרופיל ומדידת האיכות הקמעונאי משתמש בפרופיל נתונים אוטומטי כדי לזהות דפוסים וחריגות בטבלאות התמחור שלו ב-BigQuery. הם מגדירים ומריצים בדיקות של איכות הנתונים כדי לוודא שהכתובות למשלוח של הלקוחות מדויקות, מלאות ומהימנות עבור עומסי עבודה של AI ושל מילוי הזמנות בהמשך. מידע נוסף זמין במאמרים סקירה כללית על פרופיל נתונים וסקירה כללית על איכות נתונים אוטומטית.
אצירת מוצרי נתונים ושיתוף שלהם. צוות פלטפורמת הנתונים אורז נכסי מכירות אזוריים ואת המטא-נתונים, ציוני האיכות והשיוך שלהם למוצרים מותאמים אישית של נתוני 'תצוגה של 360 מעלות של הלקוח', שצוותי השיווק והמלאי מגלים ומשתמשים בהם. מידע נוסף זמין במאמר סקירה כללית על מוצרי נתונים.
Knowledge Catalog בסביבת Google Cloud העבודה
כשמקימים בסיס נתונים, חשוב להבין איך Knowledge Catalog משתלב עם שירותים קשורים:Google Cloud
| שירות | תפקיד ראשי | מתי משתמשים |
|---|---|---|
| Knowledge Catalog | הקשר של סוכן ומשילות מידע (data governance) | השירות משמש לקטלוג מטא-נתונים, לניהול איכות הנתונים ולספק בסיס סמנטי לסוכני AI. |
| BigQuery | מחסן נתונים ארגוני | השימוש ב-BigQuery מאפשר לאחסן, להריץ שאילתות ולנתח מערכי נתונים גדולים. ב-Knowledge Catalog אפשר להוסיף הקשר עסקי לנתונים ב-BigQuery. |
| Vertex AI | פלטפורמה ל-AI ולמידת מכונה | הפלטפורמה משמשת ליצירה ולפריסה של מודלים של למידת מכונה וסוכני AI. סוכנים משתמשים בממשקי Knowledge Catalog API כדי לאחזר הקשר ארגוני מדויק. |
| Cloud Storage | אחסון של נתונים לא מובנים | משמש לאחסון קובצי RAW. Knowledge Catalog סורק קטגוריות של Cloud Storage כדי לחלץ מטא-נתונים וישויות שאפשר לחפש. |
מושגי ליבה
כדי להשתמש ביעילות ב-Knowledge Catalog, חשוב להבין את המושגים המרכזיים הבאים:
תרשים הקשרים. מפה דינמית ומאוחדת שמציגה את הקשר בין הנתונים לעסק שלכם. הוא מקשר בין סכימות טכניות לבין ישויות עסקיות וידע לא מובנה.
שאילתות לדוגמה דפוסי SQL מאומתים שנוצרו מראש וכוללים לוגיקה עסקית מורכבת. השאילתות האלה מאפשרות גם לבני אדם וגם לסוכני AI לשאול שאילתות על נתונים בצורה מדויקת בלי ליצור מחדש איחודים מורכבים של טבלאות.
Model Context Protocol (MCP) תקן פתוח שמאפשר לסוכני AI לגלות כלים זמינים ולהשתמש בהם באופן מותאם. Knowledge Catalog משתמש בכלים של MCP כדי להעביר ישירות לסוכנים מידע מאומת מהארגון, ומציע שרתי MCP מקומיים ומרוחקים כדי להתאים לדרישות הנגישות והאבטחה.
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
הטמעות נתונים
מערכת Knowledge Catalog מעכלת באופן אוטומטי מטא-נתונים מהGoogle Cloud מקורות הבאים. בשירותים מסוימים, כמו AlloyDB ל-PostgreSQL ו-Cloud SQL, צריך קודם להפעיל את השילוב עם Knowledge Catalog כדי שאפשר יהיה להטמיע מטא-נתונים:
Analytics ו-lakehouse
- מערכי נתונים, טבלאות, תצוגות, מודלים, שגרות, חיבורים ומערכי נתונים מקושרים ב-BigQuery
- שיתוף ב-BigQuery (לשעבר Analytics Hub) – חילופי נתונים ורישומים
- מאגרי Dataform ונכסי קוד
- שירותים, מסדי נתונים וטבלאות של Dataproc Metastore
טבלאות של קטלוג REST של Iceberg (כולל Google Cloud קטלוג זמן ריצה של Lakehouse IRC, Databricks Unity IRC, AWS Glue Data Catalog IRC ו-Snowflake Horizon IRC)
AI ולמידת מכונה
- מודלים, מערכי נתונים, קבוצות תכונות, תצוגות תכונות ומופעים של חנות וירטואלית ב-Vertex AI
בינה עסקית
- מכונות, מרכזי בקרה, רכיבים של מרכזי בקרה, תצוגות, פרויקטים של LookML, מודלים, ניתוחים ותצוגות ב-Looker (Google Cloud Core) (תצוגה מקדימה)
מסדי נתונים
- מופעים, אשכולות וטבלאות של Bigtable (כולל פרטים על משפחות עמודות)
- מכונות, מסדי נתונים, טבלאות ותצוגות של Spanner
סטרימינג והעברת הודעות
- נושאים ב-Pub/Sub
נתונים לא מובְנים
מסדי נתונים תפעוליים
- אשכולות, מכונות, מסדי נתונים, סכימות, טבלאות ותצוגות של AlloyDB ל-PostgreSQL (תצוגה מקדימה). Knowledge Catalog מאחזר מטא-נתונים רק ממכונות ראשיות של AlloyDB ל-PostgreSQL ולא מרפליקות לקריאה. מידע נוסף זמין במאמר בנושא ניהול משאבי AlloyDB ל-PostgreSQL באמצעות Knowledge Catalog.
- מכונות, מסדי נתונים, סכימות, טבלאות ותצוגות של Cloud SQL. Knowledge Catalog מאחזר מטא-נתונים רק ממופעים ראשיים של Cloud SQL ולא ממופעים משוכפלים לקריאה. מידע נוסף מופיע במאמר ניהול משאבי Cloud SQL באמצעות Knowledge Catalog.
כדי לייבא מטא-נתונים ממקור של צד שלישי אל Knowledge Catalog, אפשר להשתמש במחברים של Knowledge Catalog או בצינור קישוריות מנוהל. מידע נוסף זמין במאמרים מידע על מחברים של Knowledge Catalog וסקירה כללית על קישוריות מנוהלת.
מגבלות
כשמתכננים את הפריסה, חשוב לקחת בחשבון את המגבלות הבאות:
שילובים נתמכים. אמנם Knowledge Catalog תומך במערכות עיקריות של צד שלישי, אבל יכול להיות שחלק מהחילוצים הסמנטיים האוטומטיים יוגבלו לשירותים מובנים Google Cloud .
מגבלות מכסה. המכסות הרגילות של Google Cloud API חלות על פעולות של אחזור הקשר וחילוץ מטא-נתונים.