
Le pipeline di connettività gestita importano i metadati da origini di terze parti in Knowledge Catalog (precedentemente Dataplex Universal Catalog). Puoi utilizzare queste pipeline per importare i metadati in Knowledge Catalog su larga scala per estrarre i dati dalle tue origini. Le pipeline creano anche gruppi di voci di Knowledge Catalog nel tuo progettoGoogle Cloud , se necessario. Con questo approccio, puoi orchestrare i flussi di lavoro e pianificare i job di importazione in base ai tuoi requisiti.
Crea connettori personalizzati per estrarre i metadati da varie origini di terze parti, tra cui MySQL, SQL Server, Oracle, Snowflake e Databricks. In alternativa, puoi utilizzare connettori personalizzati forniti dalla community per una gamma più ampia di origini.
Come funziona la connettività gestita
Il seguente diagramma mostra una pipeline di connettività gestita.
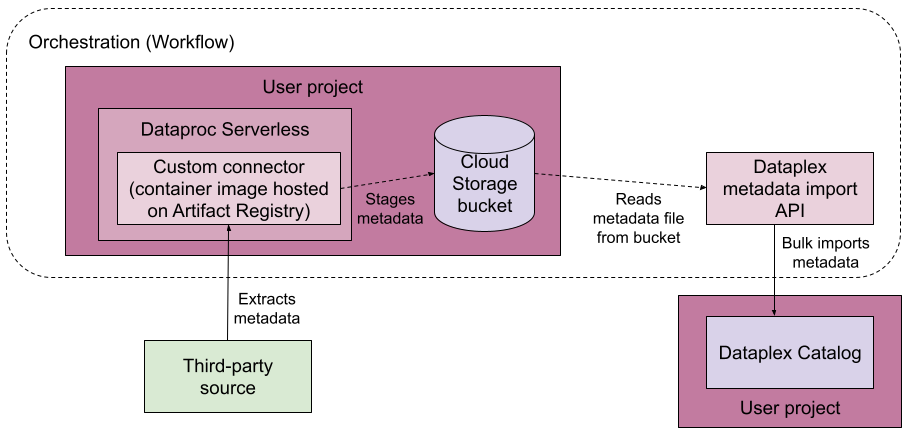
A livello generale, ecco come funziona la connettività gestita:
Crea un connettore per l'origine dati.
Il connettore deve essere un'immagine di Artifact Registry che può essere eseguita su Managed Service for Apache Spark.
Esegui la pipeline di connettività gestita in Workflows, una piattaforma di orchestrazione.
La pipeline di connettività gestita esegue le seguenti azioni:
- Crea un gruppo di voci di destinazione in base alla configurazione, se il gruppo di voci non esiste.
- Esegue il connettore. Il connettore estrae i metadati dall'origine dati e genera un file di importazione dei metadati che può essere importato in Knowledge Catalog.
- Monitora l'avanzamento dell'estrazione dei metadati.
- Esegue un job di importazione dei metadati per importarli in Knowledge Catalog.
- Monitora l'avanzamento del job di importazione dei metadati.
La pipeline di connettività gestita utilizza Managed Service for Apache Spark per eseguire il connettore e i metodi dell'API di importazione dei metadati di Knowledge Catalog per eseguire il job di importazione dei metadati.
I metadati che importi sono costituiti da voci di Knowledge Catalog e dai relativi aspetti. Per saperne di più sui metadati di Knowledge Catalog, consulta Informazioni sulla gestione dei metadati in Knowledge Catalog.
Connettori personalizzati forniti dalla community
Per importare i metadati da origini di terze parti, puoi utilizzare connettori personalizzati forniti dalla community. Consulta il file README di ciascun connettore per istruzioni di configurazione e ulteriori informazioni sul connettore.
| Origine dati | Repository |
|---|---|
| MySQL | mysql-connector |
| Oracle | oracle-connector |
| PostgreSQL | postgresql-connector |
| Snowflake | snowflake-connector |
| SQL Server | sql-server-connector |
Passaggi successivi
- Importare metadati da un'origine personalizzata utilizzando Workflows
- Sviluppa un connettore personalizzato per l'importazione dei metadati
- Importare i metadati utilizzando una pipeline personalizzata