
Mit Data Lineage können Sie nachvollziehen, wie Daten durch Ihre Systeme fließen, indem Sie die Beziehungen zwischen Daten-Assets und den Prozessen verfolgen, die sie transformieren. Sie können diese Lineage-Informationen als Diagramme und Listen in der Google Cloud Console ansehen.
In diesem Dokument werden die Granularität der Datenherkunft auf Tabellen- und Spaltenebene beschrieben und Anleitungen zur Verwendung von Diagramm- und Listenansichten zum Untersuchen der Datenherkunft in der Google Cloud Console gegeben.
Details zum zugrunde liegenden Datenmodell finden Sie unter dem Datenherkunftsmodell.
Unterschiede zwischen Lineage auf Tabellen- und Spaltenebene
Mit Data Lineage können Sie den Ursprung und den Transformationspfad Ihrer Daten sowohl auf Tabellen- als auch auf Spaltenebene nachverfolgen.
Wann sollte Lineage auf Tabellenebene verwendet werden?
Die Lineage auf Tabellenebene bietet einen allgemeinen Überblick über Ihre Datenpipelines, indem die Beziehungen zwischen gesamten Tabellen dargestellt werden. Verwenden Sie die Lineage auf Tabellenebene für Aufgaben auf Makroebene, z. B.:
Data Discovery. Ein Analyst, der ein neues Dashboard erstellt, kann die Lineage auf Tabellenebene verwenden, um eine Zusammenfassungstabelle zu ihren Quellen zurückzuverfolgen und zu bestätigen, dass die Daten aus einer autoritativen Datenbank stammen.
Migrationsplanung. Ein Datenbankadministrator, der die Migration einer Kerndatenbank plant, kann die Lineage auf Tabellenebene verwenden, um alle nachgelagerten Berichte und Dashboards zu identifizieren, die davon abhängen.
Überprüfung und Governance. Ein Data Governor kann die Lineage auf Tabellen- und Spaltenebene verwenden, um zu prüfen, wie Daten aus einer Tabelle mit personenbezogenen Daten durch eine Pipeline fließen.
Wann sollte Lineage auf Spaltenebene verwendet werden?
Die Lineage auf Spaltenebene bietet eine detailliertere Ansicht, indem der Datenfluss zwischen einzelnen Spalten nachverfolgt wird. In dieser Ansicht stellen die Links in einem Lineage-Ereignis die Beziehung zwischen einer Quellspalte und einer Zielspalte dar. Jeder dieser Links auf Spaltenebene hat einen Abhängigkeitstyp, der die Transformation beschreibt:
Exact copy: Werte werden zwischen Spalten kopiert.Other: andere Arten von Abhängigkeiten zwischen Spalten.
Verwenden Sie die Lineage auf Spaltenebene für Aufgaben wie die folgenden:
Ursachenanalyse. Wenn ein Data Analyst einen falschen Wert in einer Spalte findet, kann er die Lineage auf Spaltenebene verwenden, um ihn zu den Quellspalten zurückzuverfolgen und die Ursache zu finden.
Wirkungsanalyse. Bevor ein Data Engineer eine Spalte einstellt, kann er die Lineage auf Spaltenebene verwenden, um alle nachgelagerten Spalten zu finden, die davon abhängen.
Überprüfung der Datenquelle für Messwerte. Ein Data Analyst kann die Lineage auf Spaltenebene verwenden, um zu ermitteln, welche Quellspalten zur Berechnung eines Messwerts verwendet werden, ohne eine komplexe SQL-Abfrage entschlüsseln zu müssen.
Die Lineage auf Spaltenebene wird automatisch für die folgenden Arten von BigQuery-Jobs erfasst:
Für Managed Service for Apache Spark-Jobs hängt die Unterstützung vom Typ und der Version der Open Lineage-Abhängigkeit ab, die von Managed Service for Apache Spark verwendet wird. Die mindestens unterstützte Version ist 1.34. Die folgenden Versionen von Managed Service for Apache Spark-Cluster-Images werden mindestens unterstützt:
- 3.0.3
- 2.3.22
- 2.2.75
- 2.1.107
Die folgenden Versionen der Managed Service for Apache Spark-Laufzeit werden mindestens unterstützt:
- 3.0.3
- 2.3.20
Lineage-Ansichten in der Google Cloud Console
Mit Data Lineage in der Google Cloud Console können Sie auf zwei Arten mit Lineage-Informationen interagieren: Sie können das Lineage-Diagramm in mehreren verfügbaren Regionen untersuchen oder den Bereich Lineage Explorer verwenden, um eine detailliertere Ansicht in einer bestimmten Region zu erhalten. Sie können auch zwischen der Diagrammansicht und der Listenansicht wechseln, um den Datenfluss auf verschiedenen Detailebenen zu analysieren.
Lineage-Ansichten sind nur für Knowledge Catalog-Einträge (ehemals Dataplex Universal Catalog), BigQuery-Assets und Vertex AI-Ressourcen (Modelle, Datasets, Feature Store -Ansichten und Featuregruppen) verfügbar.
Informationen zu den verschiedenen Ansichten, die in diesem Dokument beschrieben werden, finden Sie unter Data Lineage mit Google Cloud Systemen verwenden.
Lineage-Diagrammansicht
In der Diagrammansicht werden der Daten-Asset-Fluss und die Beziehungen zwischen Systemen und Regionen visualisiert. So können Sie die Datenarchitektur besser verstehen, Ursprünge und Ziele nachverfolgen und Muster erkennen. Diese Lineage-Diagramme, die vom Data Lineage API-Dienst für einen bestimmten Knowledge Catalog-Eintrag generiert werden, zeigen, wie Daten im Laufe der Zeit transformiert werden. Dabei werden Upstream-, Downstream- oder beide Flüsse von einem ausgewählten Root-Eintrag angezeigt.
Die Data Lineage API empfängt automatisch Asset-Informationen von unterstützten Systemen und über API-Aufrufe für benutzerdefinierte Quellen.
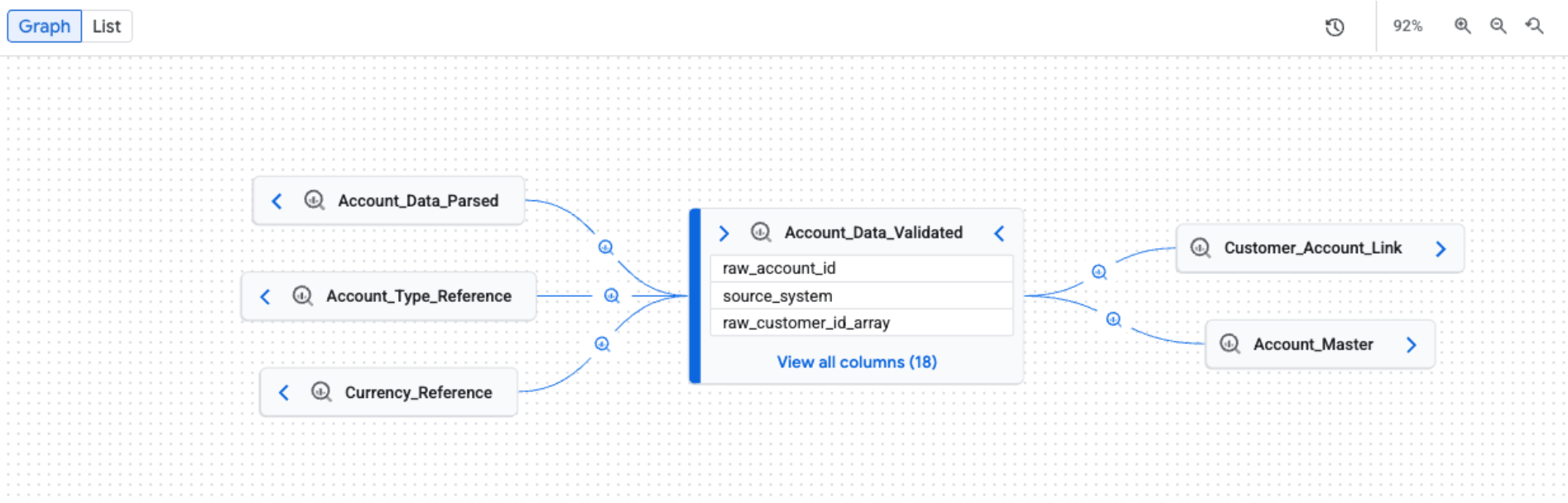
Die wichtigsten Elemente im Diagramm sind:
Knoten. Knoten stellen die Datenentitäten dar. In einer Ansicht auf Tabellenebene zeigt ein Knoten den Tabellennamen und seine Spalten. In einer Ansicht auf Spaltenebene stellt jeder Knoten eine bestimmte Tabelle und Spalte dar.
Kanten. Kanten sind die Linien, die Knoten verbinden und die Prozesse darstellen, die zwischen ihnen stattfinden. Das Aussehen einer Kante hängt von der Lineage-Ansicht ab:
- In der Ansicht auf Tabellenebene haben Kanten Symbole, die Datentransformationen angeben.
- In der Ansicht auf Spaltenebene haben Kanten Labels, die Datentransformationen angeben. Ein Kantenlabel kann beispielsweise
Exact copyenthalten, um zu beschreiben, wie eine Quellspalte in eine Zielspalte kopiert wurde.
Prozesssymbole und ‑labels. Prozesssymbole und ‑labels werden auf Kanten angezeigt, um weitere Informationen zur Transformation zu liefern.
- Symbole. Symbole stellen den Transformationsprozess dar. Wenn Sie das Diagramm manuell untersuchen, stellen Symbole auf Kanten das Quellsystem des Prozesses dar (z. B. BigQuery oder Vertex AI). Wenn mehrere Prozesse beteiligt sind, wird ein Symbol für mehrere Prozesse angezeigt. Wenn das Quellsystem des Prozesses unbekannt ist, wird ein Zahnradsymbol verwendet. Wenn Sie Filter anwenden, wird für alle Prozesse ein Zahnradsymbol verwendet.
- Labels. In der Lineage-Ansicht auf Spaltenebene beschreibt ein Label den Typ der Abhängigkeit zwischen Spalten:
Exact copyoderOther.
Lineage-Diagramm untersuchen
Wenn Sie den Tab Lineage öffnen, wird die Standardansicht Diagramm angezeigt. Die Standardansicht bietet einen allgemeinen Überblick über Systeme und Regionen hinweg. Das Diagramm kann manuell und inkrementell erweitert werden, wobei jeweils fünf Knoten geladen werden können. Prozesssymbole auf Kanten stellen das Quellsystem dar oder geben an, dass mehrere Prozesse beteiligt sind.
Lineage-Ansichten filtern und hervorheben
Bei großen und komplexen Lineage-Diagrammen können Sie Filter oder Hervorhebungen anwenden, um visuelle Störungen zu reduzieren und sich auf die Untersuchung der Lineage in einer bestimmten Region zu konzentrieren. Legen Sie Ihre Kriterien im Bereich Lineage Explorer fest. Wenn Filter angewendet werden, wird oben in den Ansichten Diagramm und Liste eine Filterleiste angezeigt, in der Ihre aktiven Filter als Chips dargestellt werden.
Sie haben folgende Möglichkeiten, die Lineage-Visualisierung zu verfeinern:
Hervorheben: Übereinstimmende Knoten werden mit Farben und Rahmen visuell hervorgehoben, während das gesamte Diagramm sichtbar bleibt. So können Sie bestimmte Assets finden, ohne den Gesamtkontext des Lineage-Diagramms zu verlieren.
Filtern: Nicht übereinstimmende Knoten werden ausgeblendet und das Diagramm wird vereinfacht, sodass nur übereinstimmende Knoten und die Pfade zwischen ihnen angezeigt werden. Alle nicht übereinstimmenden Assets, die Teil eines Pfads zwischen übereinstimmenden Knoten sind, werden in minimierten Knoten gruppiert. Dieser Modus ist nützlich, um die Komplexität zu reduzieren und sich nur auf relevante Assets und ihre direkten Beziehungen zu konzentrieren.
Verwenden Sie die folgenden Kriterien, um die Lineage zu filtern oder hervorzuheben:
- Projekt: Nach Google Cloud Projekt-ID filtern.
- System: Nach dem System filtern, in dem sich das Daten-Asset befindet (z. B. BigQuery oder Cloud Storage).
- Entitätsname: Nach Asset-Name filtern. Sie können
*für Platzhaltersuchen verwenden (nur Präfix und Suffix, z. B.*tableodertest*). - Untertyp: Nach Asset-Untertyp filtern (z. B.
dashboardodermodel). - Spaltenname: Lineage nach Spaltenname filtern, um Details auf Spaltenebene zu sehen.
- Richtung: Upstream- oder Downstream-Lineage oder beides anzeigen.
- Zeitraum: Lineage nach einer bestimmten Start- oder Endzeit filtern.
- Abhängigkeitstyp: Lineage auf Spaltenebene nach Abhängigkeitstyp filtern.
Beispiele für verfügbare Optionen sind
AlloderExact copy.
Um die Übersichtlichkeit weiter zu verbessern, können Sie Temporäre BigQuery-Tabellen ausblenden auswählen, um temporäre Assets auszublenden, die von BigQuery erstellt wurden, z. B. Tabellen in Datasets mit Namen, die mit _script beginnen.
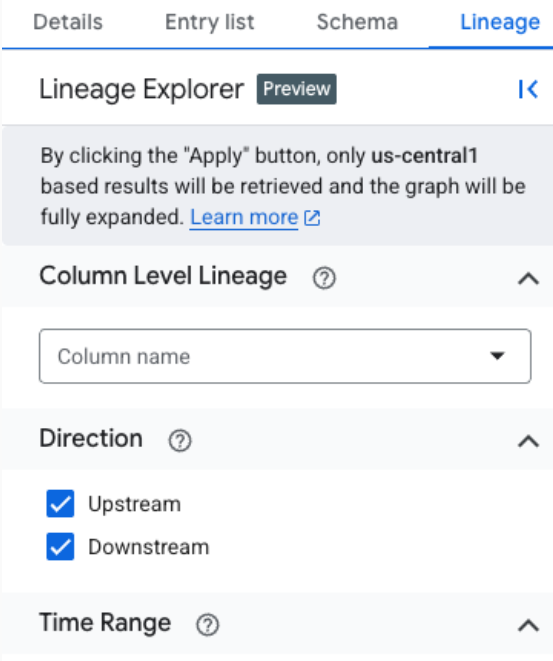
In der fokussierten Ansicht auf dem Tab Diagramm wird das Diagramm automatisch auf bis zu drei Ebenen erweitert und die gesamte Lineage geladen, die den Filterkriterien entspricht. Lineage Explorer ruft bis zu 10 Ebenen des Lineage-Diagramms ab, aber standardmäßig werden nur die ersten drei Ebenen erweitert. Sie können das Diagramm erweitern, um die restlichen Ebenen zu sehen, indem Sie auf die Pfeile klicken.
Die fokussierte Ansicht unterstützt sowohl die Lineage auf Tabellen- als auch auf Spaltenebene, einschließlich der Pfadvisualisierung von jedem ausgewählten Knoten zurück zum Root. In dieser fokussierten Ansicht wird für alle Prozesse ein generisches Zahnradsymbol verwendet.

Verwenden Sie eine der folgenden Methoden, um die Lineage auf Spaltenebene anzusehen:
Klicken Sie in einer fokussierten Diagrammansicht auf das Spaltensymbol in einer Tabelle, um zur Lineage auf Spaltenebene zu wechseln.
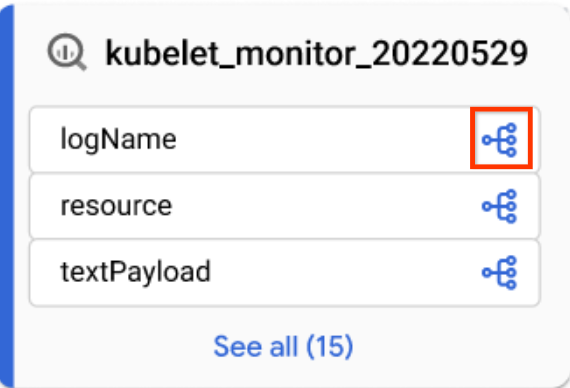
Spaltensymbol Wenden Sie in der Standardansicht Diagramm oder der fokussierten Diagrammansicht einen Spaltennamen im Bereich Lineage Explorer an.

Wenn Sie alle Filter entfernen und zur Standardansicht zurückkehren möchten, klicken Sie auf Zurücksetzen.
Informationen zum Wechseln zwischen Hervorhebungs- und Filtermodus finden Sie unter Lineage-Visualisierung verfeinern.
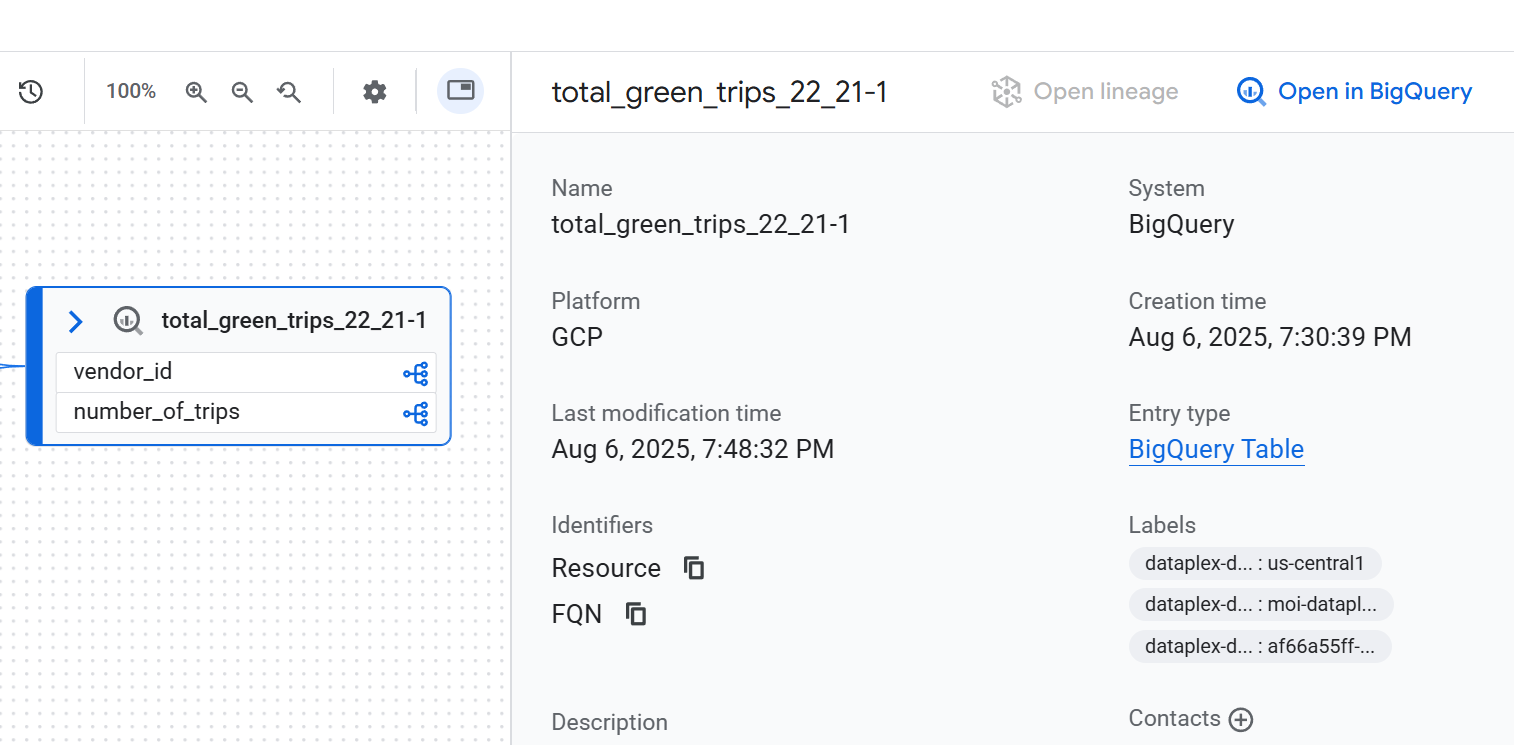
Details zu Lineage-Knoten ansehen
Wenn Sie die Details eines Knotens sehen möchten, klicken Sie auf den Knoten. Eine Seitenleiste wird angezeigt und enthält detaillierte Informationen zum ausgewählten Daten-Asset. Wenn Sie beispielsweise in einer Lineage-Ansicht auf Tabellenebene auf einen Knoten klicken, werden Informationen wie der voll qualifizierte Name, der Typ und andere relevante Attribute des Assets angezeigt.
Verlauf von Lineage-Ausführungen ansehen
Ein vollständiges Lineage-Diagramm ist das Ergebnis von Ausführungen aus vielen verschiedenen Jobs. Jeder Job erstellt einen bestimmten Link im Diagramm. Mehrere Ausführungen werden als neue Ausführungen protokolliert, ändern aber nicht das statische Aussehen des Diagramms.
Wenn Sie die Details dieser einzelnen Ausführungen sehen möchten, klicken Sie auf eine Kante mit einem Prozess im Diagramm. Klicken Sie im daraufhin angezeigten Bereich Abfrage auf den Tab Ausführungen.
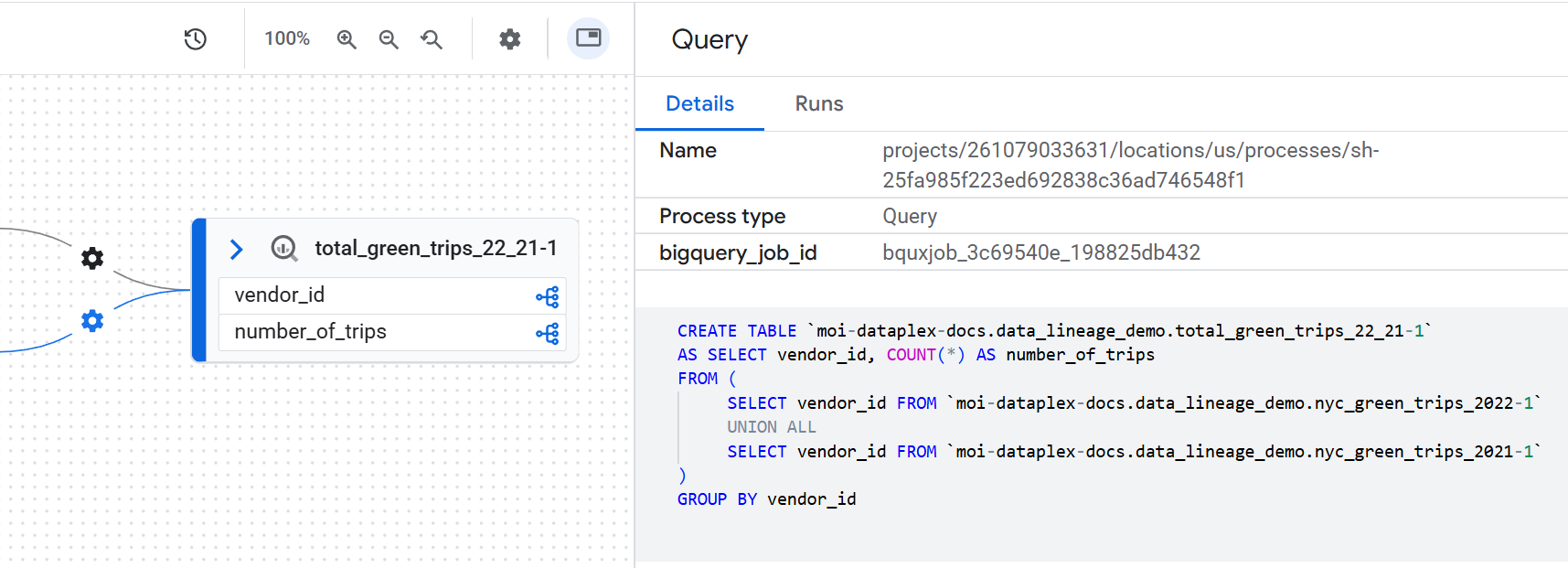
Datentransformationslogik prüfen
Wenn Sie die Geschäftslogik einer Transformation verstehen möchten, ohne nach dem Code zu suchen, können Sie die genaue SQL-Abfrage ansehen, die ausgeführt wurde. Klicken Sie dazu auf eine Kante mit einem Prozess im Diagramm. Klicken Sie in der daraufhin angezeigten Seitenleiste auf den Tab Details.
Datenherkunftspfad visualisieren
Mit der Visualisierung des Lineage-Pfads können Sie den Pfad von jedem ausgewählten Knoten im Diagramm zurück zum Root-Eintrag nachverfolgen. Wenn Sie einen Knoten auswählen und auf Pfad visualisieren klicken, werden im Diagramm nur die Knoten und Prozesse hervorgehoben, die den direkten Lineage-Pfad zum Root-Eintrag bilden.
Wenn Sie die Visualisierung des Lineage-Pfads sehen möchten, wenden Sie im Bereich Lineage Explorer einen Filter an, um eine fokussierte Diagrammansicht zu erstellen. Wählen Sie dann in der fokussierten Diagrammansicht einen Knoten aus. Klicken Sie im Detailbereich für den ausgewählten Knoten auf Pfad visualisieren.
Die Visualisierung des Lineage-Pfads ist für die Lineage auf Tabellen- und Spaltenebene verfügbar. Sie können die Visualisierung des Lineage-Pfads auch in der Listenansicht verwenden.
Lineage-Listenansicht
Die Listenansicht bietet eine tabellarische, strukturierte Darstellung der Lineage, die mit der Diagrammansicht synchronisiert ist. So können Sie Daten-Assets sortieren, filtern und herunterladen. Diese Ansicht eignet sich ideal zum Analysieren von Beziehungen zwischen Quelle und Ziel, zum Detaillieren der beteiligten Assets und zum Exportieren von Lineage-Daten.
Die Listenansicht ist sowohl für die Lineage auf Tabellen- als auch auf Spaltenebene verfügbar. Sie können zwischen den folgenden detaillierten und vereinfachten Listenansichten wechseln:
Vereinfachte Listenansicht: Diese Ansicht ist nützlich, um eine komprimierte, eindeutige Liste aller Assets zu erhalten, die an der Lineage beteiligt sind. In den Spalten wie System, Projekt, Entität, Voll qualifizierter Name (Fully Qualified Name, FQN), Richtung und Tiefe sehen Sie alle Daten-Assets in der Lineage, ihren Speicherort, ihre ursprüngliche Quelle und ihre Entfernung vom zentralen Asset, das analysiert wird. Sie eignet sich ideal für einen allgemeinen Überblick über alle Entitäten, die am Datenfluss beteiligt sind. Das ist die Standardansicht.
Detaillierte Listenansicht: Diese Ansicht ist für die Analyse einzelner Beziehungen zwischen Quelle und Ziel konzipiert. Durch separate Spalten für Quelle und Ziel können Sie jeden spezifischen Link für die Datentransformation sehen. Diese Ansicht eignet sich ideal für Aufgaben, die ein tiefes Verständnis dafür erfordern, wie Daten zwischen bestimmten Asset-Paaren verschoben werden, z. B. Überprüfung einzelner Datenflüsse, Verständnis von Abhängigkeiten zwischen Tabellen oder Exportieren detaillierter Lineage-Einträge für jede Verbindung.
Listenansicht der Lineage auf Tabellenebene
In dieser Ansicht werden Beziehungen zwischen Tabellen als Ganzes dargestellt. Verwenden Sie die bereitgestellten Filter, um die gewünschten Spalten auszuwählen.

Maximieren Sie die folgenden Abschnitte, um die Spalten zu sehen, die in den Listenansichten auf Tabellenebene verfügbar sind.
In der vereinfachten Listenansicht auf Tabellenebene verfügbare Spalten
- System: Das System, in dem sich das Daten-Asset befindet. Beispiele: [BigQuery](/bigquery/docs).
- Projekt: Die Google Cloud Projekt-ID, die das Daten-Asset enthält.
- Entität: Der Name des Daten-Assets. Beispiele: ein Tabellenname.
- FQN: Der FQN der ursprünglichen Quellentität oder ‑spalte.
- Richtung: Gibt an, ob das aufgeführte Asset im Lineage-Fluss Upstream (Quelle) oder Downstream (Ziel) ist.
- Tiefe: Die Anzahl der Lineage-Schritte vom zentralen Asset, das analysiert wird.
In der detaillierten Listenansicht auf Tabellenebene verfügbare Spalten
- Quellsystem: Das System, in dem sich das Quelldaten-Asset befindet. Beispiele: BigQuery.
- Quellprojekt: Die Google Cloud Projekt-ID, die das Quelldaten Asset enthält.
- Quelle: Der Name des Quelldaten-Assets. Beispiele: ein Tabellen name.
- Voll qualifizierter Name der Quelle (Source FQN): Der FQN der Quellentität.
- Zielsystem: Das System, in dem sich das Zieldaten-Asset befindet. Beispiele: BigQuery.
- Zielprojekt: die Google Cloud Projekt-ID, die das Zieldaten- Asset enthält.
- Ziel: Der Name des Zieldaten-Assets. Beispiele: ein Tabellen name.
- Voll qualifizierter Name des Ziels (Target FQN): Der FQN der Zielentität.
- Richtung: Gibt an, ob das aufgeführte Asset im Lineage-Fluss Upstream (Quelle) oder Downstream (Ziel) ist.
- Tiefe: Die Anzahl der Lineage-Schritte vom zentralen Asset, das analysiert wird.
Listenansicht der Lineage auf Spaltenebene
In dieser Ansicht werden Beziehungen zwischen einzelnen Spalten in den Quell- und Zieltabellen dargestellt. Verwenden Sie die bereitgestellten Filter, um die gewünschten Spalten auszuwählen.
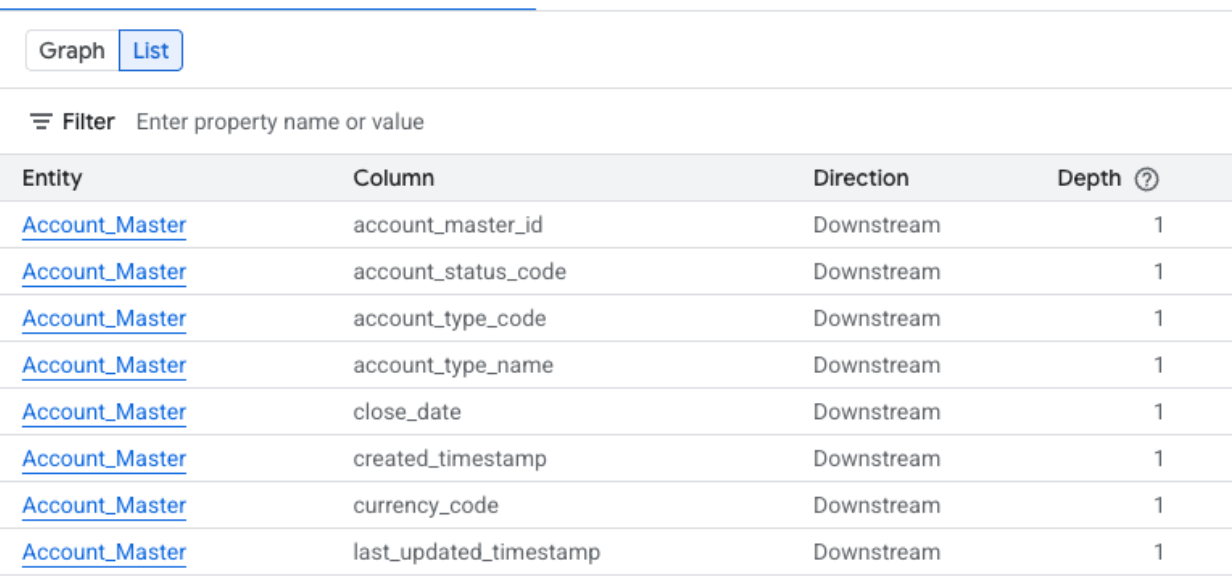
Maximieren Sie die folgenden Abschnitte, um die Spalten zu sehen, die in den Listenansichten auf Spaltenebene verfügbar sind.
In der vereinfachten Listenansicht auf Spaltenebene verfügbare Spalten
- System: Das System, in dem sich das Daten-Asset befindet. Beispiele: BigQuery.
- Projekt: Die Google Cloud Projekt-ID, die das Daten-Asset enthält.
- Entität: Der Name des Daten-Assets. Beispiele: ein Tabellenname.
- Spalte: Die spezifische Spalte, die im Bereich Lineage Explorer innerhalb der Entität ausgewählt wurde.
- FQN: Der FQN der ursprünglichen Quellentität oder ‑spalte.
- Richtung: Gibt an, ob das aufgeführte Asset im Lineage-Fluss Upstream (Quelle) oder Downstream (Ziel) ist.
- Tiefe: Die Anzahl der Lineage-Schritte vom zentralen Asset, das analysiert wird.
In der detaillierten Listenansicht auf Spaltenebene verfügbare Spalten
- Quellsystem: Das System, in dem sich das Quelldaten-Asset befindet.
- Quellprojekt: Die Google Cloud Projekt-ID, die das Quelldaten-Asset enthält.
- Voll qualifizierter Name der Quelle (Source FQN): Der FQN der Quellspalte.
- Zielsystem: Das System, in dem sich das Zieldaten-Asset befindet.
- Zielprojekt: die Google Cloud Projekt-ID, die das Zieldaten-Asset enthält.
- Voll qualifizierter Name des Ziels (Target FQN): Der FQN der Zielspalte.
- Richtung: Gibt an, ob der Datenfluss Upstream oder Downstream ist.
- Abhängigkeitstypen: Beschreibt die Art der Beziehung zwischen den Spalten.
- Tiefe: Die Anzahl der Lineage-Schritte vom zentralen Asset, das analysiert wird.
Nächste Schritte
Informationen zu Lineage-Quellen.
Informationen zum Nachverfolgen der Datenherkunft für BigQuery-Tabellenkopien und Abfragejobs.
Informationen zur Verwendung von Data Lineage mit Google Cloud Systemen.