
In diesem Dokument wird beschrieben, wie Sie den Zugriff auf Knowledge Catalog-Lakes (früher Dataplex Universal Catalog) sichern und verwalten.
Mit dem Sicherheitsmodell von Knowledge Catalog können Sie Nutzerberechtigungen für die folgenden Aufgaben verwalten:
- Lake verwalten (Assets, Zonen und zusätzliche Lakes erstellen und anhängen)
- Zugriff auf Daten, die über das Mapping-Asset mit einem Lake verbunden sind (z. B.Google Cloud -Ressourcen wie Cloud Storage-Buckets und BigQuery-Datasets)
- Auf Metadaten zu den mit einem Data Lake verbundenen Daten zugreifen
Ein Administrator für einen Lake steuert den Zugriff auf Knowledge Catalog-Ressourcen wie Lakes, Zonen und Assets, indem er die grundlegenden und vordefinierten Rollen zuweist.
Vordefinierte Rollen
Google Cloud verwaltet die vordefinierten Rollen, die einen genau definierten Zugriff auf den Knowledge Catalog ermöglichen.
Knowledge Catalog-Rollen
| Rolle | Beschreibung |
|---|---|
| Dataplex-Betrachter ( roles/dataplex.viewer) |
Berechtigung zum Ansehen (aber nicht zum Bearbeiten) des Lakes und seiner konfigurierten Zonen und Assets. |
| Dataplex-Bearbeiter ( roles/dataplex.editor) |
Sie können den Lake bearbeiten. Kann Lakes, Zonen, Assets und Aufgaben erstellen und konfigurieren. |
| Dataplex-Administrator ( roles/dataplex.administrator) |
Möglichkeit, einen Lake vollständig zu verwalten. |
| Dataplex-Entwickler ( roles/dataplex.developer) |
Möglichkeit, Arbeitslasten zur Datenanalyse in einem Lake auszuführen. Dazu gehört das Erstellen und Konfigurieren von Inhalten und Aufgaben sowie das Ausführen von Code in den konfigurierten Umgebungen. Mit dieser Rolle werden keine Berechtigungen zum Erstellen von BigQuery-Tabellen oder zum Ausführen von Spark-Jobs gewährt. * |
Wenn Sie einen Spark-Job ausführen möchten, erstellen Sie Managed Service for Apache Spark-Cluster und senden Sie Managed Service for Apache Spark-Jobs in dem Projekt, dem die Rechenleistung zugeordnet werden soll.
Metadatenrollen
Mit Metadatenrollen können Metadaten wie Tabellenschemas aufgerufen werden.
| Rolle | Beschreibung |
|---|---|
| Autor von Dataplex-Metadaten ( roles/dataplex.metadataWriter) |
Metadaten einer bestimmten Ressource aktualisieren |
| Dataplex-Metadatenleser ( roles/dataplex.metadataReader) |
Ermöglicht das Lesen der Metadaten (z. B. zum Abfragen einer Tabelle). |
Datenrollen
Wenn Sie einem Hauptkonto Datenrollen zuweisen, kann es Daten in den zugrunde liegenden Ressourcen lesen oder schreiben, auf die die Assets des Data Lakes verweisen.
Im Knowledge Catalog werden die Rollen den Datenrollen für jede zugrunde liegende Speicherressource wie Cloud Storage und BigQuery zugeordnet.
Knowledge Catalog übersetzt und überträgt Knowledge Catalog-Datenrollen an die zugrunde liegende Speicherressource und legt die richtigen Rollen für jede Speicherressource fest. Sie können eine einzelne Knowledge Catalog-Datenrolle auf der Lake-Hierarchieebene (z. B. für einen Lake) zuweisen. Knowledge Catalog behält den angegebenen Zugriff auf Daten für alle Ressourcen bei, die mit diesem Lake verbunden sind. Auf Cloud Storage-Buckets und BigQuery-Datasets wird beispielsweise über Assets in den zugrunde liegenden Zonen verwiesen.
Wenn Sie einem Hauptkonto beispielsweise die Rolle dataplex.dataWriter für einen Lake zuweisen, erhält das Hauptkonto Schreibzugriff auf alle Daten im Lake, in den zugehörigen Zonen und Assets. Auf einer niedrigeren Ebene (Zone) gewährte Datenzugriffsrollen werden in der Lake-Hierarchie an die zugrunde liegenden Assets vererbt.
| Rolle | Beschreibung |
|---|---|
| Dataplex-Datenleser ( roles/dataplex.dataReader) |
Daten aus dem an Assets angehängten Speicher lesen, einschließlich Speicher-Buckets und BigQuery-Datasets (und deren Inhalt). * |
| Dataplex Data Writer ( roles/dataplex.dataWriter) |
Kann in die zugrunde liegenden Ressourcen schreiben, auf die das Asset verweist. * |
| Dataplex-Dateninhaber ( roles/dataplex.dataOwner) |
Gewährt die Rolle „Owner“ für die zugrunde liegenden Ressourcen, einschließlich der Möglichkeit, untergeordnete Ressourcen zu verwalten. Als Dateninhaber eines BigQuery-Datasets können Sie beispielsweise die zugrunde liegenden Tabellen verwalten. |
Lakes schützen
Sie können den Zugriff auf Ihren Lake und die damit verbundenen Daten sichern und verwalten. Verwenden Sie in der Google Cloud Console eine der folgenden Ansichten:
- Die Ansicht Verwalten im Knowledge Catalog auf dem Tab Berechtigungen
- Die Ansicht Knowledge Catalog Secure
Ansicht Verwalten verwenden
Auf dem Tab Berechtigungen können Sie alle Berechtigungen für eine Lake-Ressource verwalten. Dort wird eine ungefilterte Ansicht aller Berechtigungen angezeigt, einschließlich der geerbten.
So schützen Sie Ihren See:
Rufen Sie in der Google Cloud Console die Seite Lakes des Knowledge Catalog auf.
Klicken Sie auf den Namen des von Ihnen erstellten Data Lakes.
Klicken Sie auf den Tab Berechtigungen.
Klicken Sie auf den Tab Nach Rollen ansehen.
Klicken Sie auf Hinzufügen, um eine neue Rolle hinzuzufügen. Fügen Sie die Rollen Dataplex-Datenleser, Datenschreiber und Dateneigentümer hinzu.
Prüfen Sie, ob die Rollen Dataplex Data Reader, Data Writer und Data Owner angezeigt werden.
Ansicht Sicher verwenden
Die Ansicht Sicher im Knowledge Catalog in der Google Cloud Console bietet Folgendes:
- Eine filterbare Ansicht nur der Knowledge Catalog-Rollen, die sich auf eine bestimmte Ressource beziehen
- Datenrollen von Rollen für Lake-Ressourcen trennen

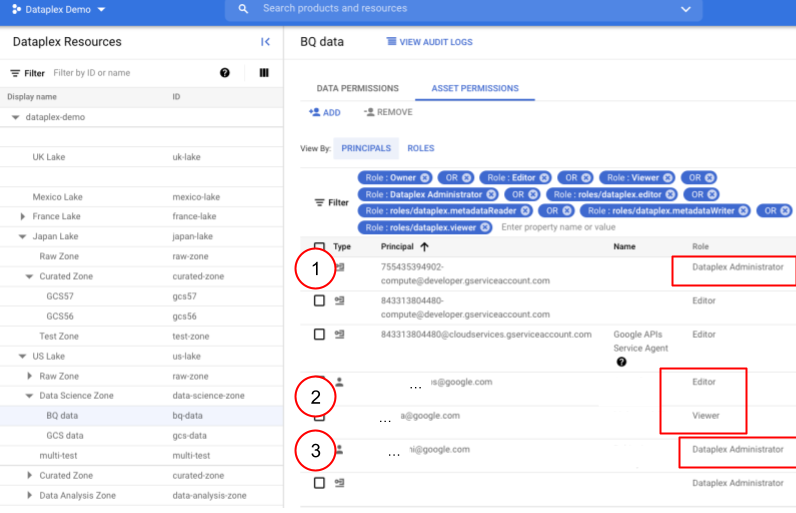
- Ein Dienstkonto, das die Rolle „Dataplex-Administrator“ vom Projekt erbt.
- Hauptkonten (E‑Mail-Adresse), die die Rollen „Dataplex-Bearbeiter“ und „Dataplex-Betrachter“ vom Projekt übernehmen. Dies sind die Rollen, die für alle Ressourcen gelten.
- Ein Hauptkonto (E-Mail-Adresse), das die Rolle „Dataplex-Administrator“ vom Projekt erbt.
Richtlinienverwaltung
Nachdem Sie Ihre Sicherheitsrichtlinie angegeben haben, werden die Berechtigungen in Knowledge Catalog auf die IAM-Richtlinien der verwalteten Ressourcen übertragen.
Die auf Lake-Ebene konfigurierte Sicherheitsrichtlinie wird auf alle in diesem Lake verwalteten Ressourcen übertragen. Knowledge Catalog bietet den Weiterleitungsstatus und Einblick in diese groß angelegten Weiterleitungen auf dem Tab Knowledge Catalog > Verwalten > Berechtigungen. Es überwacht die verwalteten Ressourcen kontinuierlich auf Änderungen an der IAM-Richtlinie außerhalb von Knowledge Catalog.
Nutzer, die bereits Berechtigungen für eine Ressource haben, behalten diese auch, nachdem eine Ressource an einen Knowledge Catalog-Lake angehängt wurde. Entsprechend bleiben nicht Knowledge Catalog-bezogene Rollenbindungen, die nach dem Anhängen der Ressource an Knowledge Catalog erstellt oder aktualisiert werden, unverändert.
Richtlinien auf Spalten-, Zeilen- und Tabellenebene festlegen
Cloud Storage-Bucket-Assets sind externe BigQuery-Tabellen zugeordnet.
Sie können ein Cloud Storage-Bucket-Asset aktualisieren. In diesem Fall werden die angehängten externen Tabellen aus dem Knowledge Catalog entfernt und stattdessen Google Cloud Lakehouse-Tabellen angehängt.
Sie können Google Cloud Lakehouse-Tabellen anstelle von externen Tabellen verwenden, um eine differenzierte Zugriffssteuerung zu ermöglichen, einschließlich Steuerung auf Zeilenebene, Steuerung auf Spaltenebene und Maskierung von Spaltendaten.
Metadatensicherheit
Metadaten beziehen sich hauptsächlich auf Schemainformationen, die mit Nutzerdaten in Ressourcen verknüpft sind, die von einem Data Lake verwaltet werden.
Bei Knowledge Catalog Discovery werden die Daten in verwalteten Ressourcen untersucht und tabellarische Schemainformationen extrahiert. Diese Tabellen werden in BigQuery, Dataproc Metastore und Data Catalog (eingestellt) veröffentlicht.
BigQuery
Jeder gefundenen Tabelle ist eine in BigQuery registrierte Tabelle zugeordnet. Für jede Zone gibt es ein zugehöriges BigQuery-Dataset, in dem alle externen Tabellen registriert sind, die mit Tabellen verknüpft sind, die in dieser Datenzone ermittelt wurden.
Die erkannten Cloud Storage-basierten Tabellen werden im Dataset registriert, das für die Zone erstellt wurde.
Dataproc Metastore
Datenbanken und Tabellen werden im Dataproc Metastore verfügbar gemacht, der mit der Knowledge Catalog-Lake-Instanz verknüpft ist. Jeder Datenzone ist eine Datenbank zugeordnet und jedem Asset können eine oder mehrere Tabellen zugeordnet sein.
Die Daten in einem Dataproc Metastore-Dienst werden durch die Konfiguration Ihres VPC-SC-Netzwerks geschützt. Die Dataproc Metastore-Instanz wird Knowledge Catalog beim Erstellen des Data Lakes bereitgestellt. Dadurch ist sie bereits eine vom Nutzer verwaltete Ressource.
Data Catalog
Jeder erkannten Tabelle ist ein Eintrag im Data Catalog (wird nicht mehr unterstützt) zugeordnet, um die Suche und Erkennung zu ermöglichen.
Für Data Catalog sind IAM-Richtliniennamen beim Erstellen von Einträgen erforderlich. Daher stellt Knowledge Catalog den IAM-Richtliniennamen der Knowledge Catalog-Asset-Ressource bereit, mit der der Eintrag verknüpft werden soll. Die Berechtigungen für den Knowledge Catalog-Eintrag werden daher durch die Berechtigungen für die Asset-Ressource bestimmt.
Weisen Sie der Asset-Ressource die Rolle „Dataplex Metadata Reader“ (roles/dataplex.metadataReader) und die Rolle „Dataplex Metadata Writer“ (roles/dataplex.metadataWriter) zu.
Nächste Schritte
- Weitere Informationen zu IAM für Knowledge Catalog
- Weitere Informationen zu IAM-Rollen für den Knowledge Catalog
- Weitere Informationen zu IAM-Berechtigungen für Knowledge Catalog