
Neste tutorial, mostramos como usar a sintaxe YAML do Apache Beam para criar pipelines de processamento de dados do Dataflow. Você vai aprender a ler dados de um arquivo, aplicar transformações e gravar os resultados em outro arquivo usando a UI do job builder no console Google Cloud . Este tutorial é destinado a desenvolvedores que não conhecem o Apache Beam ou querem aprender a usar a API YAML para criar pipelines.
A tabela a seguir mostra um gráfico de pipeline no console do Google Cloud e a especificação YAML correspondente.
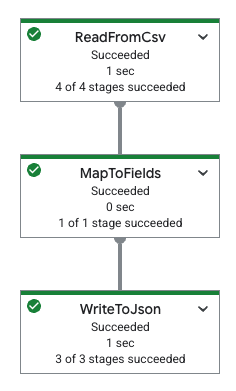
|
pipeline: transforms: - name: ReadFromCsv type: ReadFromCsv config: path: 'gs://[...]/restaurant-data.csv' - name: MapToFields type: MapToFields input: ReadFromCsv config: language: python fields: Lowercase_menu_item: Item.lower() Total_price: Price + Tax append: true - name: WriteToJson type: WriteToJson input: MapToFields config: path: 'gs://[...]/restaurant-data_map-fields.json' |
Objetivos
Neste tutorial, você vai aprender a:
- Criar pipelines YAML do Beam que leem, gravam e transformam dados.
- Filtra dados com base no conteúdo.
- Mapear campos usando expressões Python.
- Use SQL para consultar e agregar dados.
- Crie e execute pipelines Beam YAML usando o formulário de builder na UI do criador de jobs no console Google Cloud .
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Para mais informações, consulte Limpeza.
Antes de começar
Conclua as etapas a seguir antes de executar o pipeline.
Criar o projeto
- Faça login na sua conta do Google Cloud . Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Criar um bucket do Cloud Storage
Antes de executar um pipeline, é necessário criar um bucket do Cloud Storage.
Crie um bucket do Cloud Storage:
- No console do Google Cloud , acesse a página Buckets do Cloud Storage.
- Clique em Criar.
- Na página Criar um bucket, insira as informações do seu bucket. Para ir à próxima
etapa, clique em Continuar.
- Em Nomear o bucket, insira um nome exclusivo. Não inclua informações confidenciais no nome do bucket já que o namespace dele é global e visível para o público.
-
Na seção Escolha onde armazenar seus dados, faça o seguinte:
- Selecione um tipo de local.
- Escolha um local onde os dados do bucket são armazenados permanentemente no menu suspenso Tipo de local.
- Se você selecionar o tipo de local birregional, também poderá ativar a replicação turbo usando a caixa de seleção relevante.
- Para configurar a replicação entre buckets, selecione
Adicionar replicação entre buckets usando o Serviço de transferência do Cloud Storage e
siga estas etapas:
Configurar a replicação entre buckets
- No menu Bucket, selecione um bucket.
Na seção Configurações de replicação, clique em Configurar para definir as configurações do job de replicação.
O painel Configurar a replicação entre buckets aparece.
- Para filtrar objetos a serem replicados por prefixo de nome de objeto, insira um prefixo com que você quer incluir ou excluir objetos e clique em Adicionar um prefixo.
- Para definir uma classe de armazenamento para os objetos replicados, selecione uma classe de armazenamento no menu Classe de armazenamento. Se você pular esta etapa, os objetos replicados vão usar a classe de armazenamento do bucket de destino por padrão.
- Clique em Concluído.
-
Na seção Escolha como armazenar seus dados, faça o seguinte:
- Na seção Definir uma classe padrão, selecione o seguinte: Padrão.
- Para ativar o namespace hierárquico, na seção Otimizar o armazenamento para cargas de trabalho com uso intensivo de dados, selecione Ativar namespace hierárquico neste bucket.
- Na seção Escolha como controlar o acesso a objetos, selecione se o bucket aplica ou não a prevenção de acesso público e selecione um método de controle de acesso para os objetos do bucket.
-
Na seção Escolha como proteger os dados do objeto, faça o
seguinte:
- Selecione qualquer uma das opções em Proteção de dados que
você quer definir para o bucket.
- Para ativar a exclusão reversível, clique na caixa de seleção Política de exclusão reversível (para recuperação de dados) e especifique o número de dias que você quer reter os objetos após a exclusão.
- Para definir o controle de versões de objetos, clique na caixa de seleção Controle de versões de objetos (para controle de versões) e especifique o número máximo de versões por objeto e o número de dias após os quais as versões não atuais expiram.
- Para ativar a política de retenção em objetos e buckets, clique na caixa de seleção Retenção (para compliance) e faça o seguinte:
- Para ativar o bloqueio de retenção de objetos, clique na caixa de seleção Ativar retenção de objetos.
- Para ativar o Bloqueio de buckets, clique na caixa de seleção Definir política de retenção de buckets e escolha uma unidade e um período de armazenamento para a retenção.
- Para escolher como os dados do objeto serão criptografados, expanda a seção Criptografia de dados () e selecione um método de Criptografia de dados.
- Selecione qualquer uma das opções em Proteção de dados que
você quer definir para o bucket.
- Clique em Criar.
Copie o seguinte, conforme necessário em uma seção posterior:
- Seu nome do bucket do Cloud Storage.
- O ID do projeto do Google Cloud .
Para encontrar esse ID, consulte Como identificar projetos.
Rede VPC
Por padrão, cada novo projeto começa com uma rede
padrão. Se a rede padrão do projeto estiver desativada ou tiver sido excluída, você precisará ter uma rede no projeto em que sua conta de usuário tem o papel de usuário da rede do Compute (roles/compute.networkUser).
Ler, gravar e transformar dados
Esta seção mostra como usar a sintaxe do Beam YAML com o Dataflow para ler, gravar e filtrar dados usando o seguinte:
- Desenvolvimento orientado por interface do usuário para criar e executar jobs na UI do criador de jobs no console Google Cloud . Especificamente, você vai usar o formulário de builder na UI do builder de jobs, sem precisar criar os arquivos YAML manualmente.
Dados de arquivos CSV armazenados em um bucket do Cloud Storage visível publicamente. Esses dados contêm dados simulados de cardápios de restaurantes e têm esta aparência:
restaurant-data.csvMenu item,Category,Price,Tax Classic Cheeseburger,Entree,9.99,0.7 Margherita Pizza,Entree,14.50,1.02 Grilled Salmon with Asparagus,Entree,21.99,1.54 Chicken Caesar Salad,Salad,12.75,0.89 Spaghetti Carbonara,Entree,16.25,1.14 Beef Tacos (3),Entree,10.50,0.74 Vegetable Stir-Fry,Entree,13.00,0.91 Shrimp Scampi,Entree,19.75,1.38 Chicken Pot Pie,Entree,15.50,1.09 Steak Frites,Entree,28.00,1.96 Lobster Mac and Cheese,Entree,25.50,1.79 Pork Belly Bao Buns (2),Appetizer/Side,11.25,0.79 Mushroom Risotto,Entree,17.50,1.23 Fish and Chips,Entree,14.00,0.98 Buffalo Wings (6),Appetizer/Side,9.50,0.67 French Onion Soup,Appetizer/Side,7.00,0.49 Tomato Soup with Grilled Cheese,Appetizer/Side,10.00,0.7 Avocado Toast,Appetizer/Side,8.50,0.6 Quesadilla with Chicken,Appetizer/Side,11.75,0.82 Pad Thai,Entree,15.00,1.05 Chicken Tikka Masala,Entree,18.50,1.3 Burrito Bowl,Entree,13.50,0.95 Sushi Combo (8 pieces),Entree,22.00,1.54 Greek Salad,Salad,11.00,0.77 Clam Chowder,Appetizer/Side,8.00,0.56 New York Cheesecake,Dessert,6.50,0.46 Chocolate Lava Cake,Dessert,7.50,0.53 Apple Pie,Dessert,5.00,0.35 Tiramisu,Dessert,8.00,0.56 Crème brûlée,Dessert,7.00,0.49 Iced Coffee,Beverage,3.50,0.25 Lemonade,Beverage,3.00,0.21 Orange Juice,Beverage,4.00,0.28 Soda,Beverage,2.50,0.18 Craft Beer,Beverage,6.00,0.42 Glass of Wine,Beverage,9.00,0.63 Margarita,Beverage,12.00,0.84 Moscow Mule,Beverage,11.50,0.81 Old Fashioned,Beverage,13.00,0.91 Espresso,Beverage,3.00,0.21 Cappuccino,Beverage,4.50,0.32 Latte,Beverage,5.00,0.35 Mocha,Beverage,5.50,0.39 Hot Chocolate,Beverage,4.00,0.28 Breakfast Burrito,Breakfast,10.50,0.74 Pancakes (3),Breakfast,8.00,0.56 Waffles,Breakfast,9.00,0.63 Eggs Benedict,Breakfast,14.00,0.98 Omelette,Breakfast,11.00,0.77 Fruit Salad,Salad,7.50,0.53 Yogurt Parfait,Breakfast,6.00,0.42
Ler e filtrar dados
O exemplo a seguir mostra como ler dados de um arquivo CSV, filtrar informações específicas e gravar os dados filtrados em um arquivo JSON.
Esta amostra usa a transformaçãoFilter, que
permite manter seletivamente os dados que atendem a determinados critérios. O exemplo a seguir filtra um conjunto de dados para manter apenas os registros em que Price é maior ou igual a 20.00.
Para ler os dados CSV e gerar conteúdo JSON filtrado, siga estas etapas:
No console Google Cloud , acesse a página Jobs do Dataflow.
Clique em Criar job no Builder.
Na guia Criador de jobs, deixe Formulário do criador selecionado.
No campo Nome do job, insira
filter-python-job.Em Tipo de serviço, deixe Lote selecionado.
Na seção Fontes:
No campo Nome da fonte do painel Nova fonte, mude o nome para
ReadCsv.Na lista Tipo de origem, selecione CSV do Cloud Storage.
No campo Local do CSV, insira:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvClique em Concluído.
Na seção Transformações:
Clique em Adicionar uma transformação.
No campo Nome da transformação, insira
FilterPrice.Na lista Tipo de transformação, selecione Filtro (Python).
No campo Expressão de filtro do Python, insira
Price >= 20.00.Na lista Etapa de entrada para a transformação, deixe
ReadCsvselecionado.Clique em Concluído.
Na seção Coletores:
No campo Nome do coletor, mude o nome para
WriteJson.Na lista Tipo de coletor, selecione Arquivos JSON no Cloud Storage.
No campo Localização do JSON, insira:
BUCKET_NAME/output/restaurant-data_filtered.jsonSubstitua
BUCKET_NAMEpelo nome do bucket do seu Cloud Storage.Na lista Etapa de entrada para o coletor, deixe
FilterPriceselecionado.Clique em Concluído.
Na seção Opções do Dataflow, clique em Executar job.
Examinar a saída do job
Quando o job for concluído, siga estas etapas para conferir a saída do pipeline:
No console do Google Cloud , acesse a página Buckets do Cloud Storage.
Na lista de buckets, clique no nome do bucket que você criou em Criar um bucket do Cloud Storage.
Clique no arquivo chamado
restaurant-data_filtered.json-00000-of-00001.Na página Detalhes do objeto, clique no URL autenticado para visualizar a saída do pipeline.
A saída será parecida com esta:
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54}
{"Item":"Steak Frites","Category":"Entree","Price":28.0,"Tax":1.96}
{"Item":"Lobster Mac and Cheese","Category":"Entree","Price":25.5,"Tax":1.79}
{"Item":"Sushi Combo (8 pieces)","Category":"Entree","Price":22.0,"Tax":1.54}
Mapear campos usando Python
Com a transformação MapToFields, é possível criar novos campos com base nos atuais. O exemplo a seguir cria uma versão em letras minúsculas de um item de menu, calcula um preço total e anexa os valores depois dos valores atuais.
Acesse a página Jobs do Dataflow no consoleGoogle Cloud .
Clique em Criar job usando o criador.
Na guia Criador de jobs, deixe Formulário do criador selecionado.
No campo Nome do job, insira
map-python-job.Em Tipo de serviço, deixe Lote selecionado.
Na seção Fontes:
No campo Nome da fonte do painel Nova fonte, mude o nome para
ReadFromCsvPy.Na lista Tipo de origem, selecione CSV do Cloud Storage.
No campo Local do CSV, insira:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvClique em Concluído.
Na seção Transformações:
Clique em Adicionar uma transformação.
No campo Nome da transformação, insira
MapToFieldsPy.Na lista Tipo de transformação, selecione Mapear campos (Python).
Deixe a opção Preservar campos atuais selecionada.
Na seção Campos mapeados, clique em Adicionar um campo.
No painel Novo campo que é aberto, coloque
Lowercase_menu_itemcomo o Nome do campo.No campo Expressão Python, insira
Item.lower().Clique em Concluído.
Na mesma seção Campos mapeados, clique em Adicionar um campo novamente.
No painel Novo campo que é aberto, coloque
Total_pricecomo o Nome do campo.No campo Expressão Python, insira
Price + Tax.No painel Novo campo, clique em Concluído.
No painel Nova transformação, clique em Concluído.
Na seção Coletores:
No campo Nome do coletor, mude o nome para
WriteToJsonPy.Na lista Tipo de coletor, selecione Arquivos JSON no Cloud Storage.
No campo Localização do JSON, insira:
BUCKET_NAME/output/restaurant-data_map-fields.jsonSubstitua
BUCKET_NAMEpelo nome do bucket do seu Cloud Storage.Na lista Etapa de entrada para o coletor, deixe
MapToFieldsPyselecionado.Clique em Concluído.
Na seção Opções do Dataflow, clique em Executar job.
Examinar a saída do job
Quando o job for concluído, siga estas etapas para conferir a saída do pipeline:
No console do Google Cloud , acesse a página Buckets do Cloud Storage.
Na lista de buckets, clique no nome do bucket que você criou em Criar um bucket do Cloud Storage.
Clique no arquivo chamado
restaurant-data_map-fields.json-00000-of-00001.Na página Detalhes do objeto, clique no URL autenticado para visualizar a saída do pipeline.
A saída será parecida com esta:
{"Item":"Classic Cheeseburger","Category":"Entree","Price":9.99,"Tax":0.7,"Lowercase_menu_item":"classic cheeseburger","Total_price":10.69}
{"Item":"Margherita Pizza","Category":"Entree","Price":14.5,"Tax":1.02,"Lowercase_menu_item":"margherita pizza","Total_price":15.52}
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54,"Lowercase_menu_item":"grilled salmon with asparagus","Total_price":23.53}
{"Item":"Chicken Caesar Salad","Category":"Salad","Price":12.75,"Tax":0.89,"Lowercase_menu_item":"chicken caesar salad","Total_price":13.64}
{"Item":"Spaghetti Carbonara","Category":"Entree","Price":16.25,"Tax":1.14,"Lowercase_menu_item":"spaghetti carbonara","Total_price":17.39}
{"Item":"Beef Tacos (3)","Category":"Entree","Price":10.5,"Tax":0.74,"Lowercase_menu_item":"beef tacos (3)","Total_price":11.24}
[...]
Transformar dados usando SQL
A transformação Sql
transform
permite executar consultas SQL nos seus dados. O exemplo a seguir agrupa itens de menu por categoria (como Entree, Beverage ou Dessert) e adiciona uma coluna com a contagem de itens em cada categoria.
Para usar a interface do criador de jobs e criar seu pipeline, siga estas etapas:
Acesse a página Jobs do Dataflow no console Google Cloud .
Clique em Criar job usando o criador.
Na guia Criador de jobs, no campo Nome do job, insira
sql-transform-job.Em Tipo de serviço, deixe Lote selecionado.
Na seção Fontes:
No campo Nome da origem, mude o nome para
SqlTransformSource.Na guia Nova origem, em Tipo de origem, selecione CSV do Cloud Storage. O campo Local do CSV é aberto.
Em Local do CSV, insira:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvClique em Concluído.
Na seção Transformações:
Clique em Adicionar uma transformação.
No campo Nome da transformação, atualize o nome para
SqlTransform.Em Tipo de transformação, selecione Transformação de SQL. As opções de transformação de SQL são abertas.
No campo Expressão SQL, insira:
select Category, count(*) as category_count from PCOLLECTION group by CategoryClique em Concluído.
Na seção Coletores:
Em Nome do coletor, insira
SqlTransformSink.Em Tipo de coletor, selecione Arquivos JSON no Cloud Storage. As opções Gravar em arquivos JSON no Cloud Storage são abertas.
Em Local do JSON, insira:
BUCKET_NAME/output/restaurant-data_transform-sql.jsonSubstitua
BUCKET_NAMEpelo nome do bucket do seu Cloud Storage.Clique em Concluído.
Opcional: veja a definição YAML gerada para esse pipeline.
Navegue até a parte de cima da guia "Criador de jobs".
Selecione Editor do YAML. A definição YAML vai aparecer. Ele vai ficar assim:
Especificação YAML gerada
pipeline: transforms: - name: SqlTransformSource type: ReadFromCsv config: path: 'gs://cloud-samples-data/dataflow/tutorials/restaurant-data.csv' - name: SqlTransform type: Sql config: query: >- select Category, count(*) as category_count from PCOLLECTION group by Category input: input0: SqlTransformSource - name: SqlTransformSink type: WriteToJson input: SqlTransform config: path: 'gs://BUCKET_NAME/output/restaurant-data_transform-sql.json'
Na seção Opções do Dataflow, clique em Executar job.
Examinar a saída do job
Quando o job for concluído, siga estas etapas para conferir a saída do pipeline:
No console do Google Cloud , acesse a página Buckets do Cloud Storage.
Na lista de buckets, clique no nome do bucket que você criou em Criar um bucket do Cloud Storage.
Clique no arquivo chamado
restaurant-data_transform-sql.json-00000-of-00001.Na página Detalhes do objeto, clique no URL autenticado para visualizar a saída do pipeline.
A saída será parecida com esta:
{"Category":"Entree","category_count":16}
{"Category":"Beverage","category_count":14}
{"Category":"Appetizer\/Side","category_count":7}
{"Category":"Dessert","category_count":5}
{"Category":"Breakfast","category_count":6}
{"Category":"Salad","category_count":3}
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Excluir o projeto
- No console Google Cloud , acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
Excluir recursos individuais
Se você quiser reutilizar o projeto mais tarde, poderá mantê-lo, mas excluir os recursos criados durante o tutorial.
Pare o pipeline do Dataflow
No console Google Cloud , acesse a página Jobs do Dataflow.
Clique no job que você quer interromper.
Para interromper um job, o status dele precisa serem execução.
Na página de detalhes do job, clique em Parar.
Clique em Cancelar.
Confirme sua escolha clicando em Interromper job.
Exclua o bucket do Cloud Storage
- No console do Google Cloud , acesse a página Buckets do Cloud Storage.
- Clique na caixa de seleção do bucket que você quer excluir.
- Para excluir o bucket, clique em Excluir e siga as instruções.
A seguir
- Saiba mais sobre como criar jobs usando a visão geral da interface do builder de jobs no console Google Cloud .
- Saiba mais sobre jobs personalizados do Job Builder em Criar um job personalizado com o Job Builder.
- Leia a visão geral da API YAML do Beam.
- Confira mais exemplos de YAML do Beam.