
É possível usar a infraestrutura de geração de registros integrada do SDK do Apache Beam para registrar informações ao executar o pipeline. Use o consoleGoogle Cloud para monitorar as informações de geração de registros durante e após a execução do pipeline.
Adicionar mensagens de registro ao pipeline
Java
O SDK do Apache Beam para Java recomenda gerar registros de mensagens do worker por meio da biblioteca de código aberto Simple Logging Facade for Java (SLF4J). O SDK do Apache Beam para Java implementa a infraestrutura de geração de registros obrigatória. Dessa maneira, o código Java só precisa importar a API SLF4J. Em seguida, ele cria instâncias de um Logger para ativar a geração de registros de mensagens no código do pipeline.
Para código ou bibliotecas preexistentes, o SDK do Apache Beam para Java configura uma infraestrutura de geração de registros extra. As mensagens de registro produzidas pelas seguintes bibliotecas de geração de registros para Java são capturadas:
Python
O SDK do Apache Beam para Python fornece o pacote de biblioteca logging, que permite que os workers do pipeline enviem mensagens de registro. Para usar as funções da biblioteca, é necessário importá-la:
import logging
Go
O SDK do Apache Beam para Go fornece o pacote de biblioteca log, que permite que os workers do pipeline enviem mensagens de registro. Para usar as funções da biblioteca, é necessário importá-la:
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
Exemplo de código de mensagem de registro do worker
Java
O exemplo a seguir usa o SLF4J para geração de registros do Dataflow. Para saber mais sobre como configurar o SLF4J para geração de registros do Dataflow, consulte o artigo Dicas de Java.
O exemplo WordCount do Apache Beam pode ser modificado para resultar em uma mensagem de registro quando a palavra “love” for localizada em uma linha do texto processado. O código adicionado está indicado em negrito no exemplo a seguir. O código entre parênteses foi incluído para contextualização.
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
É possível modificar o exemplo wordcount.py do Apache Beam para resultar em uma mensagem de registro quando a palavra “love” for localizada em uma linha do texto processado.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
É possível modificar o exemplo wordcount.py do Apache Beam para resultar em uma mensagem de registro quando a palavra “love” for localizada em uma linha do texto processado.
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
Se o pipeline WordCount modificado for executado localmente usando o DirectRunner padrão com a saída enviada para um arquivo local (--output=./local-wordcounts), a saída do console incluirá as mensagens de registro adicionadas:
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
Por padrão, apenas linhas de registros marcadas como INFO e superiores são enviadas para o Cloud Logging. Para mudar esse comportamento, consulte
Como configurar níveis de registro do worker do pipeline.
Python
Se o pipeline WordCount modificado for executado localmente usando o DirectRunner padrão com a saída enviada para um arquivo local (--output=./local-wordcounts), a saída do console incluirá as mensagens de registro adicionadas:
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
Por padrão, apenas linhas de registros marcadas como INFO e superiores são enviadas para o Cloud Logging. Para mudar esse comportamento, consulte
Como configurar níveis de registro do worker do pipeline.
Não substitua a configuração de geração de registros com funções logging.config, porque isso pode desativar os manipuladores de registros pré-configurados que transmitem os registros do pipeline para o Dataflow e o Cloud Logging.
Go
Se o pipeline WordCount modificado for executado localmente usando o DirectRunner padrão com a saída enviada para um arquivo local (--output=./local-wordcounts), a saída do console incluirá as mensagens de registro adicionadas:
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
Por padrão, apenas linhas de registros marcadas como INFO e superiores são enviadas para o Cloud Logging.
Adicionar contexto estruturado e pesquisável aos registros usando MDC
É possível usar o contexto de diagnóstico mapeado (MDC, na sigla em inglês) para adicionar pares de chave-valor estruturados aos registros do Dataflow. Isso facilita a consulta e a análise das mensagens no Cloud Logging.
O Contexto de diagnóstico mapeado (MDC, na sigla em inglês) é um recurso padrão em frameworks de geração de registros Java, como SLF4J e Logback. Ele permite melhorar as instruções de registro com informações contextuais gerenciadas por thread. Por exemplo, você pode adicionar um ID de transação, um nome de arquivo ou uma chave específica da empresa aos seus registros, semelhante a este: "custom_data": { "transactionId": "xyz-123", "sourceFile":
"customers.csv" }.
Integração do MDC do Dataflow
Quando você ativa o MDC para seu pipeline do Dataflow, o
executor do Dataflow captura automaticamente o contexto do MDC no
momento em que uma mensagem de registro é gerada e a encaminha para o Logging. Os atributos personalizados aparecem em um mapa custom_data no jsonPayload da entrada de registro do Logging. Isso os torna campos filtráveis de nível superior.
Confira um exemplo de entrada de registro com dados personalizados do MDC:
{ "jsonPayload": { "custom_data": { "messageId": "232323232" }, "message": "LOG_MESSAGE", "pipelineName": "PIPELINE_NAME", [...] } }
Pré-requisitos
- Um pipeline do Dataflow usando o SDK do Apache Beam para Java.
- Para o Runner não portátil (em lote) / Java de streaming (streaming), use a versão 2.69.0 ou mais recente do SDK do Apache Beam.
- Para o Portable Runner, o recurso é compatível por padrão.
- Uma fachada de geração de registros, como SLF4J, configurada no projeto.
Ativar e usar o MDC
Para ativar o MDC, adicione a seguinte opção de pipeline ao iniciar o job:
--logMdc=true
O exemplo de código a seguir mostra como usar o MDC para adicionar um messageId aos registros
de um job do Dataflow que lê mensagens do Pub/Sub.
import org.apache.beam.sdk.Pipeline; import org.apache.beam.sdk.io.gcp.pubsub.PubsubMessage; import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO; import org.apache.beam.sdk.options.Description; import org.apache.beam.sdk.options.PipelineOptionsFactory; import org.apache.beam.sdk.options.SdkHarnessOptions; import org.apache.beam.sdk.transforms.DoFn; import org.apache.beam.sdk.transforms.ParDo; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.slf4j.MDC; public class SimpleDataflowJobMDC { public interface SimpleDataflowJobOptions extends SdkHarnessOptions { @Description("The Pub/Sub subscription to read from.") String getInputSubscription(); void setInputSubscription(String value); } public static class MessageReaderFn extends DoFn<PubsubMessage, Void> { private transient Logger logger; @Setup public void setup() { logger = LoggerFactory.getLogger(MessageReaderFn.class); } @ProcessElement public void processElement(ProcessContext c) { PubsubMessage message = c.element(); String messageId = message.getMessageId(); try (MDC.MDCCloseable ignored = MDC.putCloseable("messageId", messageId)) { String payload = new String(message.getPayload()); logger.info("Received message with payload: " + payload); // This is the example task logger.info("Executing example task..."); } catch (Exception e) { logger.info("failure"); } } } public static void main(String[] args) { SimpleDataflowJobOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(SimpleDataflowJobOptions.class); // options.setRunner(DirectRunner.class); options.setLogMdc(true); Pipeline p = Pipeline.create(options); p.apply( "Read Messages from Pub/Sub", PubsubIO.readMessagesWithAttributes().fromSubscription(options.getInputSubscription())) .apply("Process Message", ParDo.of(new MessageReaderFn())); p.run(); } }
O comando mvn a seguir mostra como executar o pipeline com o argumento --logMdc=true:
mvn -Pdataflow-runner compile exec:java \ -Dexec.mainClass=com.sample.SimpleDataflowJobMDC \ -Dexec.args=" \ [...] \ --logMdc=true \ [...]
Controlar o volume de registros
Você também pode reduzir o volume de registros gerados mudando os níveis de registro do pipeline. Se você não quiser continuar ingerindo alguns ou todos os registros do Dataflow, adicione uma exclusão do Logging para excluir registros do Dataflow. Em seguida, exporte os registros para um destino diferente, como BigQuery, Cloud Storage ou Pub/Sub. Para mais informações, consulte Controlar a ingestão de registros do Dataflow.
Limites da geração de registros
As mensagens de registro do worker são limitadas a 15.000 mensagens a cada 30 segundos, por worker. Se esse limite for atingido, uma única mensagem de registro do worker será adicionada, dizendo que a geração de registros é limitada:
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
Nenhuma outra mensagem é registrada até o fim do intervalo de 30 segundos. Esse limite é compartilhado por mensagens de registro geradas pelo SDK do Apache Beam e pelo código do usuário.
Armazenamento e retenção de registros
Os registros operacionais são armazenados no
bucket de registros _Default. O nome do serviço da API Logging é dataflow.googleapis.com. Para mais informações
sobre os Google Cloud tipos de recursos monitorados e os serviços usados no
Cloud Logging, consulte Recursos e
serviços monitorados.
Para saber detalhes sobre o período de retenção das entradas de registro no Logging, consulte as informações sobre retenção em Cotas e limites: períodos de armazenamento de registros.
Para informações sobre como visualizar registros operacionais, consulte Monitorar e visualizar registros de pipeline.
Monitorar e visualizar registros de pipeline
Ao executar o pipeline no serviço do Dataflow, use a interface de monitoramento do Dataflow para ver os registros emitidos pelo pipeline.
Exemplo de registro de worker do Dataflow
É possível executar o pipeline WordCount modificado na nuvem com as seguintes opções:
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Ver registros
Como o canal da nuvem do WordCount usa a execução de bloqueio, as mensagens do console são exibidas durante a execução do canal. Quando o job for iniciado, um link para a página do consoleGoogle Cloud será enviado ao console seguido pelo ID do job do pipeline:
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
O URL do console leva à Interface de monitoramento do Dataflow com uma página de resumo para o job enviado. Ela mostra um gráfico de execução dinâmica à esquerda, com resumos à direita. Clique em keyboard_capslock no painel inferior para expandir o painel de registros.
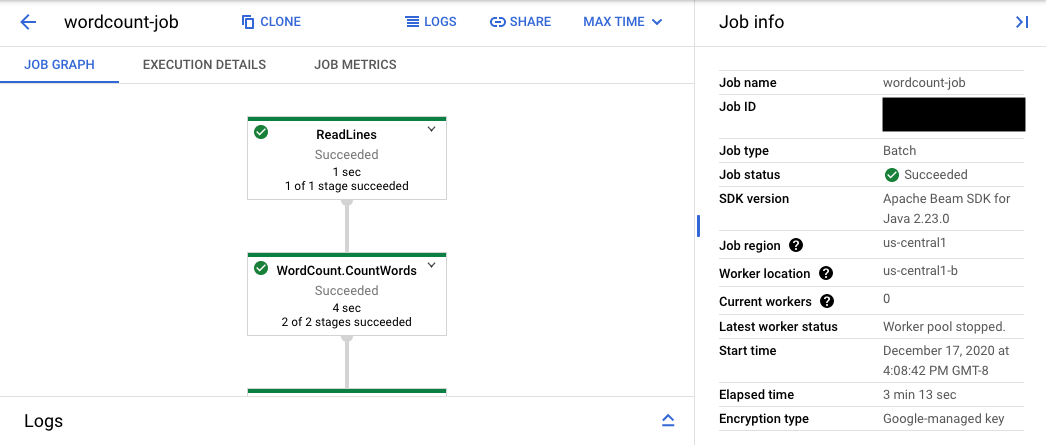
O painel de registros exibe como padrão Registros de jobs, que informa o status do job como um todo. É possível filtrar as mensagens que aparecem no painel de registros clicando em Informaçõesarrow_drop_down e filter_listFiltrar registros.
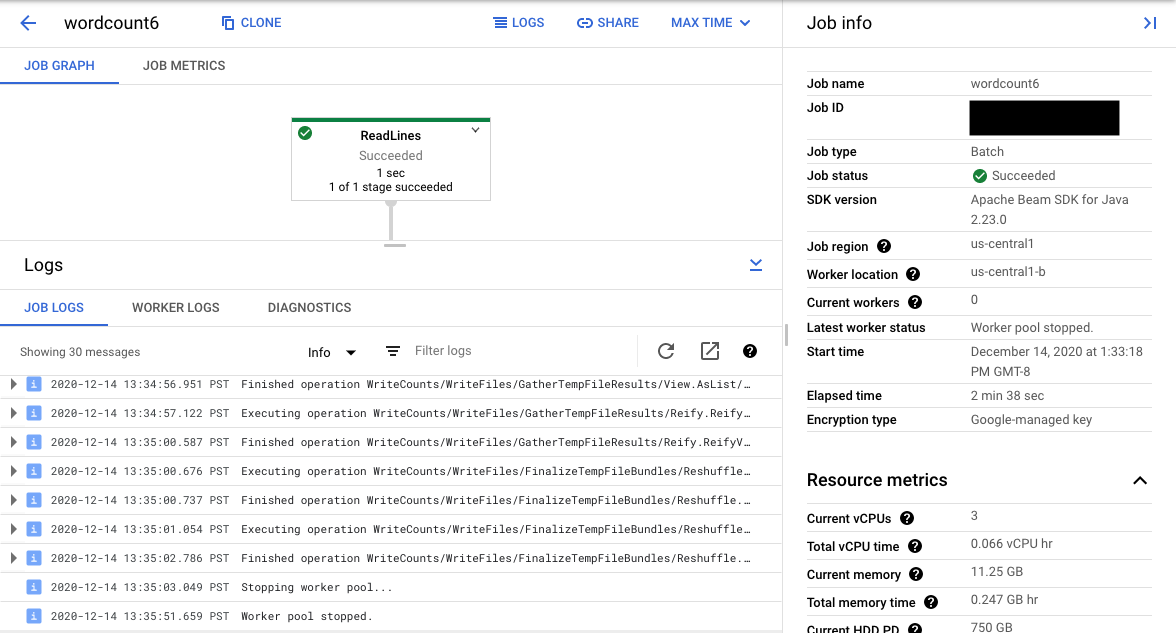
A seleção de uma etapa no gráfico modifica a visualização de Registros de etapas gerados pelo código e também o código de execução gerado na etapa de canal.
Para voltar aos Registros do job, clique fora do gráfico ou use o botão Desmarcar etapa no painel lateral à direita.
Acesse a Análise de registros
Para abrir a Análise de registros e selecionar diferentes tipos, no painel de registros, Clique em Ver na Análise de registros (o botão do link externo).
Na Análise de registros, para mostrar o painel com diferentes tipos de registro, clique na opção Campos de registro.
Na página Análise de registros, a consulta pode filtrar os registros por etapa do job ou por tipo de registro. Para remover filtros, clique no botão de alternância Mostrar consulta e edite a consulta.
Para acessar todos os registros disponíveis para um job, siga estas etapas:
No campo Consulta, digite a seguinte consulta:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"Substitua JOB_ID pelo ID do job.
Clique em Run query.
Se você usar essa consulta e não encontrar os registros do job, clique em Editar horário.
Ajuste o horário de início e de término e clique em Aplicar.
Tipos de registro
A Análise de registros também inclui registros de infraestrutura para seu pipeline. Use registros de erros e avisos para diagnosticar problemas observados no pipeline. Erros e avisos nos registros de infraestrutura que não estão relacionados a um problema de pipeline não indicam necessariamente um problema.
Este é um resumo dos diferentes tipos de registro disponíveis para visualização na página Análise de registros:
- Os registros job-message contêm mensagens no nível de job que vários componentes do Dataflow geram. Os exemplos incluem a configuração de escalonamento automático, o momento em que os workers são inicializados ou desligados, o progresso na etapa do job e erros no job. Os erros no nível do worker que são originados de falha no código de usuário e que estão presentes em registros dworker também se propagam para os registros jobs-message.
- Os registros worker são produzidos por workers do Dataflow. Os workers fazem a maior parte do trabalho do pipeline. Por exemplo, aplicar
ParDos aos dados. Os registros worker contêm mensagens registradas pelo seu código e pelo Dataflow. - Os registros worker-startup estão presentes na maioria dos jobs do Dataflow e podem capturar mensagens relacionadas ao processo de inicialização. O processo de inicialização inclui o download dos jars do job do Cloud Storage e a inicialização dos workers. Se houver um problema ao iniciar os workers, esses logs são um bom local para procurar.
- Os registros harness contêm mensagens do arcabouço de execução do Portable Runner.
- Registros de shuffler contêm mensagens de workers que consolidam os resultados das operações paralelas do canal.
- Registros system contêm mensagens dos sistemas operacionais do host das VMs de worker. Em alguns cenários, eles podem capturar falhas de processos ou eventos de falta de memória (OOM).
- Os registros docker e kubelet contêm mensagens relacionadas a essas tecnologias públicas, que são usadas em workers do Dataflow.
- Os registros nvidia-mps contêm mensagens sobre operações do NVIDIA Multi-Process Service (MPS).
Definir níveis de registro do worker do pipeline
Java
O nível padrão de geração de registros SLF4J definido nos workers pelo SDK do Apache Beam para Java é INFO. Todas as mensagens de registro de INFO ou superior (INFO, WARN, ERROR) serão emitidas. Defina um nível de registro padrão diferente para dar suporte a níveis de geração de registros SLF4J (TRACE ou DEBUG) mais baixos ou crie diferentes níveis de registro para diferentes pacotes de classes no código.
As opções de pipeline a seguir são fornecidas para permitir a definição de níveis de registro do worker na linha de comando ou de maneira programática:
--defaultSdkHarnessLogLevel=<level>: use esta opção para definir todos os loggers no nível padrão especificado. Por exemplo, a seguinte opção de linha de comando substituirá o nível de registro padrãoINFOdo Dataflow e o configurará comoDEBUG:
--defaultSdkHarnessLogLevel=DEBUG--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: use esta opção para criar o nível de geração de registros para classes ou pacotes especificados. Por exemplo, para substituir o nível de registro de pipeline padrão para o pacoteorg.apache.beam.runners.dataflowe defini-lo comoTRACE:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
Para fazer várias substituições, forneça um mapa JSON:
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...}).- As opções de pipeline
defaultSdkHarnessLogLevelesdkHarnessLogLevelOverridesnão têm suporte nos pipelines que usam o SDK do Apache Beam versão 2.50.0 e versões anteriores sem o Portable Runner. Nesse caso, use as opções de pipeline--defaultWorkerLogLevel=<level>e--workerLogLevelOverrides={"<package or class>":"<level>"}. Para usar várias substituições, forneça um mapa JSON:
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
O exemplo a seguir define de maneira programática as opções de geração de registros do pipeline com valores padrão que podem ser substituídas na linha de comando:
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
O nível de geração de registros padrão definido nos workers pelo SDK do Apache Beam para Python é
INFO. Todas as mensagens de registro de INFO ou superior (INFO,
WARNING, ERROR, CRITICAL) serão emitidas.
Você pode definir um nível de registro padrão diferente para dar suporte a níveis de registro menores (DEBUG)
ou definir diferentes níveis de registro para diferentes módulos no código.
São fornecidas duas opções de pipeline para criar níveis de registro de worker pela linha de comando ou de maneira programática:
--default_sdk_harness_log_level=<level>: use esta opção para definir todos os loggers no nível padrão especificado. Por exemplo, a opção de linha de comando a seguir substitui o nível de registroINFOpadrão do Dataflow e o define comoDEBUG:
--default_sdk_harness_log_level=DEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: use esta opção para definir o nível de geração de registros para módulos especificados. Por exemplo, para substituir o nível de registro do canal padrão para o móduloapache_beam.runners.dataflowe defini-lo comoDEBUG:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
Para fazer várias substituições, forneça um mapa JSON:
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...}).
No exemplo a seguir, a classe WorkerOptions é usada para definir programaticamente as opções de geração de registros do pipeline que podem ser modificadas na linha de comando:
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
Substitua:
PROJECT_NAME: o nome do projeto.JOB_NAME: o nome do jobSTORAGE_BUCKET: o nome do Cloud StorageDATAFLOW_REGION: a região onde você quer implantar o job do DataflowA sinalização
--regionsubstitui a região padrão definida no servidor de metadados, no cliente local ou nas variáveis de ambiente.
Go
Esse recurso não está disponível no SDK do Apache Beam para Go.
Visualizar o registro de jobs iniciados do BigQuery
Ao usar o BigQuery no pipeline do Dataflow, os jobs do BigQuery são iniciados para executar várias ações em seu nome. Essas ações podem incluir o carregamento e a exportação de dados, entre outras tarefas semelhantes. Para fins de solução de problemas e monitoramento, a interface de monitoramento do Dataflow tem mais informações sobre esses jobs do BigQuery disponíveis no painel Registros.
As informações de jobs do BigQuery exibidas no painel Registros são armazenadas e carregadas em uma tabela do sistema do BigQuery. Um custo de faturamento é gerado quando a tabela subjacente do BigQuery é consultada.
Ver os detalhes do job do BigQuery
Para ver as informações dos jobs do BigQuery, o pipeline precisa usar o Apache Beam 2.24.0 ou posterior.
Para listar os jobs do BigQuery, abra a guia Jobs do BigQuery e selecione o local desses jobs. Em seguida, clique em Carregar jobs do BigQuery e confirme a caixa de diálogo. Após a conclusão da consulta, a lista de jobs é exibida.

São disponibilizadas informações básicas sobre cada job, incluindo ID, tipo, duração e outros detalhes.
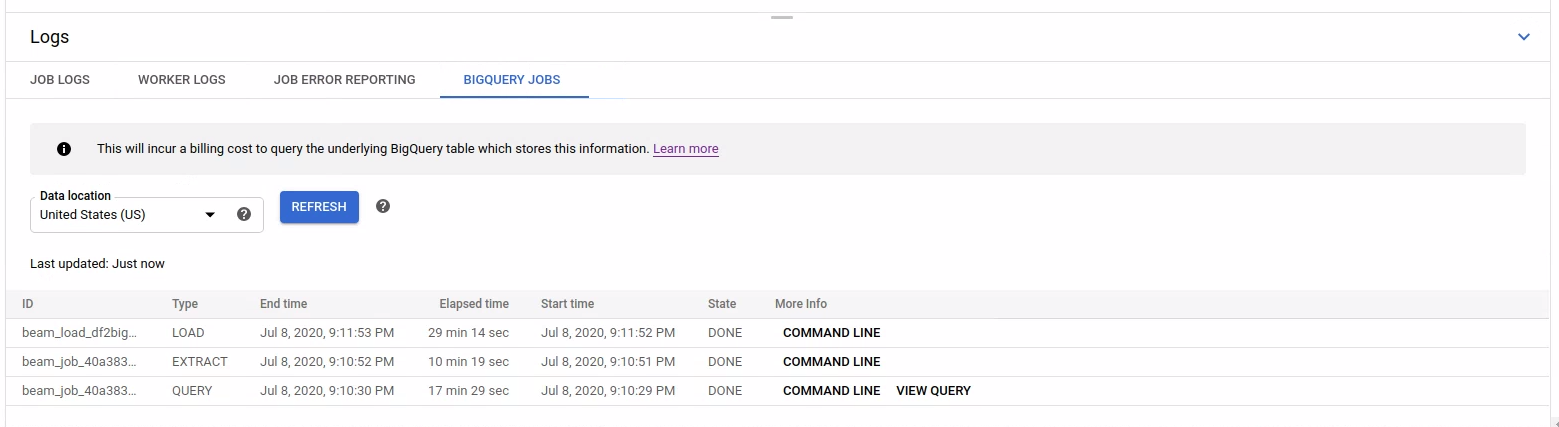
Para informações mais detalhadas sobre um job específico, clique em Linha de comando na coluna Mais informações.
Na janela modal da linha de comando, copie o comando bq jobs describe e execute-o localmente ou no Cloud Shell.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
O comando bq jobs describe gera JobStatistics, que fornece mais detalhes úteis para diagnosticar um job lento ou travado do BigQuery.
Como alternativa, ao usar o BigQueryIO com uma consulta SQL, um job de consulta é emitido. Para ver a consulta SQL usada pelo job, clique em Visualizar consulta na coluna Mais informações.
Ver diagnósticos
A guia Diagnóstico do painel Registros coleta e exibe determinadas entradas de registro produzidas nos pipelines. Isso inclui mensagens que indicam um provável problema com o pipeline e mensagens de erro com stack traces. As entradas de registros coletadas são eliminadas e combinadas em grupos de erros.
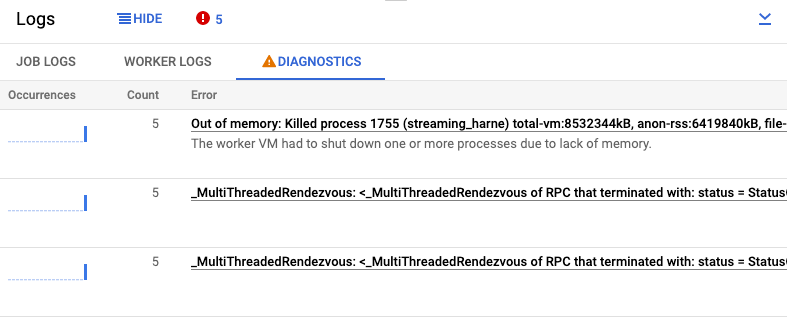
O relatório de erros inclui as seguintes informações:
- Uma lista de erros com mensagens de erro
- O número de vezes que cada erro ocorreu
- um histograma indicando quando ocorreu cada erro;
- A hora em que o erro ocorreu recentemente
- A hora em que o erro ocorreu pela primeira vez
- O status do erro
Para visualizar o relatório de um erro específico, clique na descrição na coluna Erros. Será exibida a página Relatórios de erros. Se o erro for relacionado a um erro no serviço, um link para o Guia de solução de problemas vai aparecer.
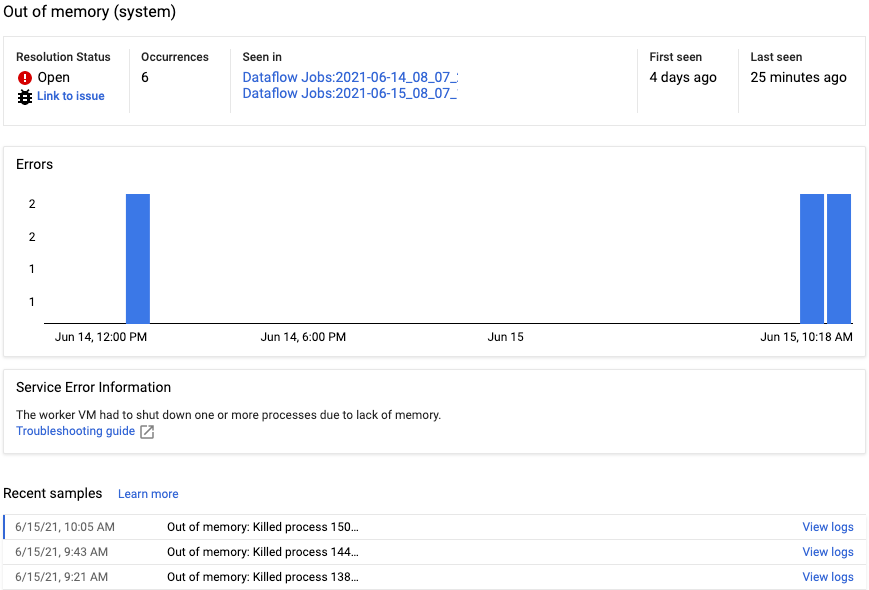
Para saber mais sobre a página, consulte Ver e filtrar erros.
Silenciar um erro
Para silenciar uma mensagem de erro, siga estas etapas:
- Abra a guia Diagnóstico.
- Clique no erro que você quer silenciar.
- Abra o menu de status da resolução. Os status têm os seguintes rótulos: Aberto, Confirmado, Resolvido ou Silenciado.
- Selecione Silenciados.
Usar um provedor de geração de registros SLF4J diferente
Por padrão, o SDK do Apache Beam para Java usa java.util.logging como o provedor de geração de registros SLF4J. Quando um pipeline é iniciado, o Dataflow
adiciona automaticamente os JARs necessários ao classpath do Java para configurar esse
ambiente de geração de registros.
Para usar um provedor de geração de registros SLF4J diferente, como
Reload4J ou Logback,
evite que os JARs padrão sejam adicionados ao caminho de classe, porque
o SLF4J só oferece suporte a um provedor de geração de registros no tempo de execução. Adicione
o seguinte experimento às opções de pipeline:
--experiments=use_custom_logging_libraries. Essa opção só está disponível para
pipelines que usam o Portable Runner desde o SDK do Apache Beam
2.63.0.
Ao ativar esse experimento, você pode agrupar seu provedor de geração de registros SLF4J preferido com os JARs do pipeline.