사용 사례: 다른 프로젝트의 Apache Spark용 관리형 서비스 클러스터에 대한 액세스 제어
컬렉션을 사용해 정리하기
내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요.
이 페이지에서는 다른 Google Cloud 프로젝트의 Managed Service for Apache Spark 클러스터를 사용하는 파이프라인
을 배포하고 실행할 때 액세스 제어를 관리하는 방법을 설명합니다.
시나리오
기본적으로 Cloud Data Fusion 인스턴스가
Google Cloud 프로젝트에서 실행되면 같은 프로젝트 내에서
Managed Service for Apache Spark 클러스터를 사용하여 파이프라인을 배포하고 실행합니다. 그러나 조직에서 다른 프로젝트의 클러스터를 사용하도록 요구할 수도 있습니다. 이 사용 사례에서는 프로젝트 사이에서 액세스 권한을 관리해야 합니다. 다음 페이지에서는 기준 (기본) 구성을 변경하고 적절한 액세스 제어를 적용하는 방법을 설명합니다.
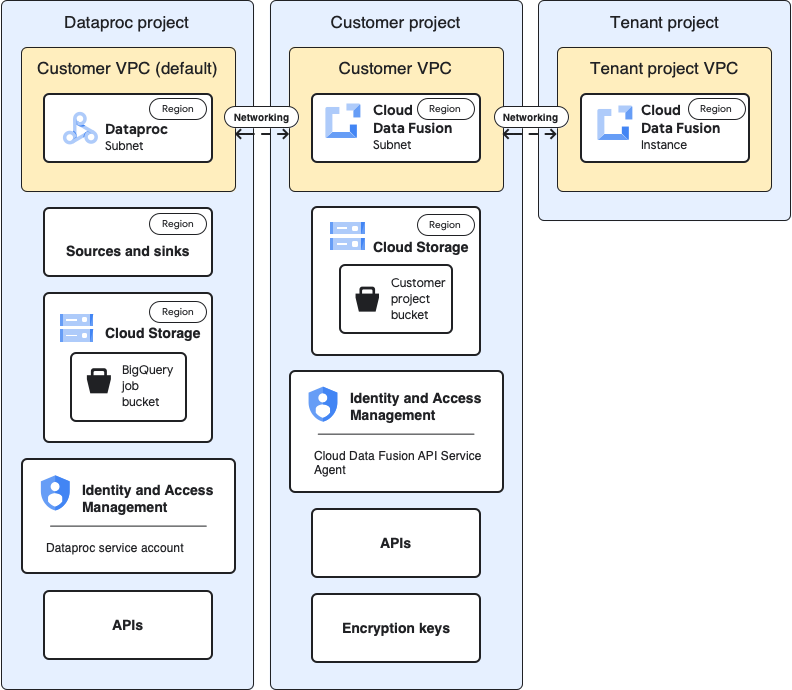
다음 다이어그램은 다른 프로젝트에서 클러스터를 사용하는 경우의 프로젝트 아키텍처를 보여줍니다.
구성
다음 섹션에서는 기준 구성을 기본 테넌트 프로젝트 VPC를 통해 다른 프로젝트의 Managed Service for Apache Spark 클러스터를 사용하기 위한 사용 사례별 구성과 비교합니다.
다음 사용 사례 설명에서 고객 프로젝트 는 Cloud Data Fusion 인스턴스가 실행되는 곳이고 Managed Service for Apache Spark 프로젝트 는 Managed Service for Apache Spark 클러스터가 실행되는 위치입니다.
테넌트 프로젝트 VPC 및 인스턴스
기준
사용 사례
앞선 기준 아키텍처 다이어그램에서는 테넌트 프로젝트에 다음 구성요소가 포함됩니다.
자동으로 생성되는 기본 VPC
Cloud Data Fusion 인스턴스의 실제 배포
이 사용 사례에는 추가 구성이 필요하지 않습니다.
고객 프로젝트
기준
사용 사례
프로젝트는 파이프라인을 배포하고 실행하는 위치입니다. Google Cloud
기본적으로 파이프라인을 실행하면 이
프로젝트에서 Managed Service for Apache Spark 클러스터가 실행됩니다.
이 사용 사례에서는 두 프로젝트를 관리합니다. 이 페이지에서
고객 프로젝트 는 Cloud Data Fusion
인스턴스가 실행되는 위치를 나타냅니다. Managed Service for Apache Spark 프로젝트 는
Managed Service for Apache Spark 클러스터가 실행되는 위치를 나타냅니다.
고객 VPC
기준
사용 사례
고객 관점에서 고객 VPC는 Cloud Data Fusion이 논리적으로 위치하는 곳입니다.
핵심 내용: 고객 VPC 세부정보는 프로젝트의 VPC 네트워크 페이지에서 확인할 수 있습니다.
이 역할에는 BigQuery 및
Managed Service for Apache Spark와 같이 인스턴스와 동일한 프로젝트의 서비스에 대한 권한이 포함됩니다. 지원되는 모든 서비스는
역할
세부정보를 참조하세요.
Cloud Data Fusion 서비스 계정에서는 다음을 수행합니다.
다른 서비스 (예: 설계 시 Cloud Storage, BigQuery, Datastream과 통신)와의 데이터 영역 (파이프라인 설계 및 실행) 통신을 수행합니다.
Managed Service for Apache Spark 클러스터를 프로비저닝합니다.
Oracle 소스에서 복제하는 경우 작업이 실행되는 프로젝트의 Datastream 관리자 및 스토리지 관리자 역할이 이 서비스 계정
에도 부여되어야 합니다. 이 페이지에서는 복제 사용 사례를 다루지 않습니다.
이 사용 사례의 경우 Managed Service for Apache Spark 프로젝트의 서비스 계정에 Cloud Data Fusion API 서비스 에이전트 역할
을 부여합니다. 그런 다음 해당 프로젝트의 다음 역할을 부여합니다.
Compute 네트워크 사용자 역할
Dataproc 편집자 역할
IAM: Managed Service for Apache Spark 서비스 계정
기준
사용 사례
파이프라인을
Managed Service for Apache Spark 클러스터 내 작업으로 실행하는 데 사용되는 서비스 계정입니다. 기본적으로
Compute Engine 서비스 계정입니다.
선택사항: 기준 구성에서 기본 서비스 계정을 같은 프로젝트의 다른 서비스 계정으로 변경할 수 있습니다. 새 서비스 계정에 다음 IAM 역할을 부여합니다.
Cloud Data Fusion 실행자 역할. 이 역할을 사용하면
Managed Service for Apache Spark에서 Cloud Data Fusion API와 통신할 수 있습니다.
Dataproc 작업자 역할 이 역할을 통해
Managed Service for Apache Spark 클러스터에서 작업을 실행할 수 있습니다.
핵심 내용:
서비스 API 에이전트에서 Managed Service for Apache Spark 클러스터를 실행하는 데 사용할 수 있도록 새 서비스의 API 에이전트 서비스 계정에 Managed Service for Apache Spark 서비스 계정에 대한 서비스 계정 사용자 역할을 부여해야 합니다.
이 사용 사례 예시에서는 Managed Service for Apache Spark 프로젝트의 기본
Compute Engine 서비스 계정 (PROJECT_NUMBER-compute@developer.gserviceaccount.com)
을 사용한다고 가정합니다.
Managed Service for Apache Spark 프로젝트의 기본 Compute Engine 서비스 계정에 다음 역할을 부여합니다.
Dataproc 작업자 역할
Managed Service for Apache Spark이 BigQuery를 위한 임시 버킷을 만들 수 있도록 하는 스토리지 관리자 역할 (또는 최소한
`storage.buckets.create` 권한)
BigQuery 작업 사용자 역할. 이 역할을 사용하면 Managed Service for Apache Spark
에서 로드 작업을 만들 수 있습니다. 작업은 기본적으로 Managed Service for Apache Spark
프로젝트에 생성됩니다.
BigQuery 데이터 세트 편집자 역할. 이 역할을 사용하면
Managed Service for Apache Spark에서 데이터를 로드하는 동안 데이터 세트를 만들 수 있습니다.
Managed Service for Apache Spark 프로젝트의 기본 Compute Engine 서비스 계정에 대한 서비스 계정 사용자 역할을 Cloud Data Fusion
서비스 계정에 부여합니다. Managed Service for Apache Spark 프로젝트에서 이 작업을 수행해야 합니다.
Managed Service for Apache Spark 프로젝트의 기본 Compute Engine 서비스 계정을 Cloud Data Fusion 프로젝트에 추가합니다.
다음 역할도 부여합니다.
Cloud Data Fusion 소비자 버킷에서 파이프라인 작업 관련
아티팩트를 검색할 수 있는 스토리지 객체 뷰어 역할
Managed Service for Apache Spark
클러스터가 실행되는 동안 Cloud Data Fusion과 통신할 수 있도록 하는 Cloud Data Fusion 실행자 역할입니다.
API
기준
사용 사례
Cloud Data Fusion API를 사용 설정하면 다음 API도 사용 설정됩니다. 이러한 API에 대한 자세한 내용은 프로젝트의 API 및 서비스 페이지를 참조하세요.