
Questa pagina descrive la gestione del controllo dell'accesso quando esegui il deployment e l'esecuzione di una pipeline che utilizza cluster Managed Service for Apache Spark in un altro progetto. Google Cloud
Scenario
Per impostazione predefinita, quando un'istanza Cloud Data Fusion viene avviata in un progettoGoogle Cloud , esegue il deployment e l'esecuzione delle pipeline utilizzando i cluster Managed Service for Apache Spark all'interno dello stesso progetto. Tuttavia, la tua organizzazione potrebbe richiedere l'utilizzo di cluster in un altro progetto. Per questo caso d'uso, devi gestire l'accesso tra i progetti. La pagina seguente descrive come modificare le configurazioni di base (predefinite) e applicare i controlli dell'accesso appropriati.
Prima di iniziare
Per comprendere le soluzioni in questo caso d'uso, devi disporre del seguente contesto:
- Familiarità con i concetti di base di Cloud Data Fusion
- Familiarità con Identity and Access Management (IAM) per Cloud Data Fusion
- Familiarità con il networking di Cloud Data Fusion
Ipotesi e ambito
Questo caso d'uso presenta i seguenti requisiti:
- Un'istanza privata di Cloud Data Fusion. Per motivi di sicurezza, un'organizzazione potrebbe richiedere l'utilizzo di questo tipo di istanza.
- Un'origine e un sink BigQuery.
- Controllo dell'accesso con IAM, non con controllo dell'accesso basato sui ruoli (RBAC).
Soluzione
Questa soluzione confronta l'architettura e la configurazione di base e specifiche del caso d'uso.
Architettura
I seguenti diagrammi confrontano l'architettura del progetto per la creazione di un'istanza di Cloud Data Fusion e l'esecuzione di pipeline quando utilizzi cluster nello stesso progetto (baseline) e in un progetto diverso tramite il VPC del progetto tenant.
Architettura di base
Questo diagramma mostra l'architettura di base dei progetti:
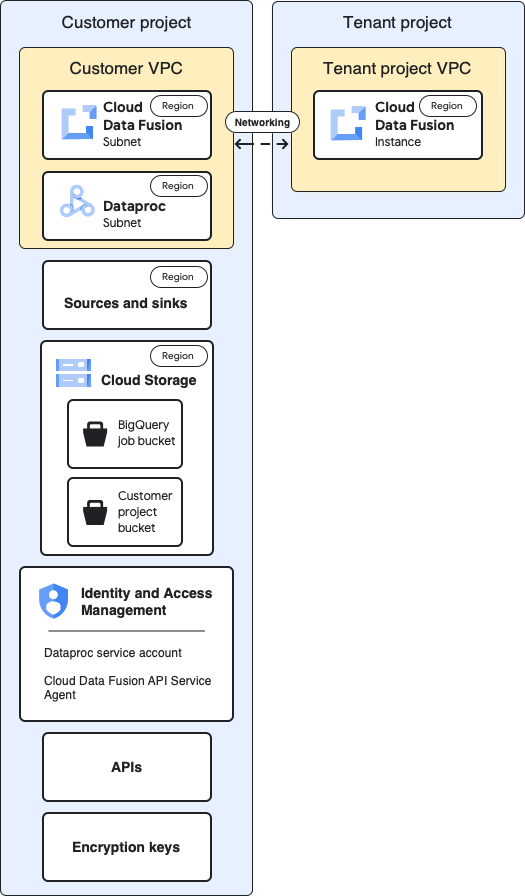
Per la configurazione di base, crea un'istanza privata di Cloud Data Fusion ed esegui una pipeline senza personalizzazioni aggiuntive:
- Utilizzi uno dei profili di calcolo integrati
- L'origine e il sink si trovano nello stesso progetto dell'istanza
- Non sono stati concessi ruoli aggiuntivi a nessuno dei service account
Per saperne di più sui progetti tenant e cliente, consulta Networking.
Architettura del caso d'uso
Questo diagramma mostra l'architettura del progetto quando utilizzi cluster in un altro progetto:

Configurazioni
Le sezioni seguenti confrontano le configurazioni di base con le configurazioni specifiche dello scenario d'uso per l'utilizzo dei cluster Managed Service for Apache Spark in un progetto diverso tramite il VPC predefinito del progetto tenant.
Nelle seguenti descrizioni dei casi d'uso, il progetto cliente è quello in cui viene eseguita l'istanza Cloud Data Fusion e il progetto Managed Service per Apache Spark è quello in cui viene avviato il cluster Managed Service per Apache Spark.
VPC e istanza del progetto tenant
| Base di riferimento | Caso d'uso |
|---|---|
Nel diagramma dell'architettura di base precedente, il progetto tenant
contiene i seguenti componenti:
|
Per questo caso d'uso non è necessaria alcuna configurazione aggiuntiva. |
Progetto cliente
| Base di riferimento | Caso d'uso |
|---|---|
| Il progetto Google Cloud è dove esegui il deployment e l'esecuzione delle pipeline. Per impostazione predefinita, i cluster Managed Service for Apache Spark vengono avviati in questo progetto quando esegui le pipeline. | In questo caso d'uso, gestisci due progetti. In questa pagina, il
progetto cliente si riferisce a dove viene eseguita l'istanza Cloud Data Fusion. Il progetto Managed Service for Apache Spark si riferisce a dove vengono avviati i cluster Managed Service for Apache Spark. |
VPC cliente
| Base di riferimento | Caso d'uso |
|---|---|
Dal tuo punto di vista (quello del cliente), il VPC del cliente è dove si trova logicamente Cloud Data Fusion. Aspetto chiave: puoi trovare i dettagli del VPC del cliente nella pagina Reti VPC del tuo progetto. |
Per questo caso d'uso non è necessaria alcuna configurazione aggiuntiva. |
Subnet Cloud Data Fusion
| Base di riferimento | Caso d'uso |
|---|---|
Dal tuo punto di vista (quello del cliente), questa subnet è la posizione logica di Cloud Data Fusion. Aspetto chiave: la regione di questa subnet è la stessa della posizione dell'istanza Cloud Data Fusion nel progetto tenant. |
Per questo caso d'uso non è necessaria alcuna configurazione aggiuntiva. |
Subnet Managed Service per Apache Spark
| Base di riferimento | Caso d'uso |
|---|---|
La subnet in cui vengono avviati i cluster Managed Service per Apache Spark quando esegui una pipeline. Concetti chiave:
|
Si tratta di una nuova subnet in cui vengono avviati i cluster Managed Service for Apache Spark quando esegui una pipeline. Concetti chiave:
|
Fonti e sink
| Base di riferimento | Caso d'uso |
|---|---|
Le origini da cui vengono estratti i dati e i sink in cui vengono caricati, come le origini e i sink BigQuery. Concetto chiave:
|
Le configurazioni di controllo dell'accesso specifiche per il caso d'uso in questa pagina sono per origini e sink BigQuery. |
Cloud Storage
| Base di riferimento | Caso d'uso |
|---|---|
Il bucket di archiviazione nel progetto del cliente che consente di trasferire i file tra Cloud Data Fusion e Managed Service for Apache Spark. Concetti chiave:
|
Per questo caso d'uso non è necessaria alcuna configurazione aggiuntiva. |
Bucket temporanei utilizzati dall'origine e dal sink
| Base di riferimento | Caso d'uso |
|---|---|
I bucket temporanei creati dai plug-in per le origini e i sink, come i job di caricamento avviati dal plug-in di sink BigQuery. Concetti chiave:
|
Per questo caso d'uso, il bucket può essere creato in qualsiasi progetto. |
Bucket che sono origini o destinazioni dei dati per i plug-in
| Base di riferimento | Caso d'uso |
|---|---|
| Bucket del cliente, che specifichi nelle configurazioni dei plug-in, ad esempio il plug-in Cloud Storage e il plug-in FTP a Cloud Storage. | Per questo caso d'uso non è necessaria alcuna configurazione aggiuntiva. |
IAM: Cloud Data Fusion API Service Agent
| Base di riferimento | Caso d'uso |
|---|---|
Quando l'API Data Fusion è abilitata, il
ruolo Agente di servizio API Data
Fusion
( Concetti chiave:
|
Per questo caso d'uso, concedi il ruolo di service agent API Data Fusion al account di servizio nel progetto Managed Service for Apache Spark. Poi concedi i seguenti ruoli nel progetto:
|
IAM: account di servizio Managed Service for Apache Spark
| Base di riferimento | Caso d'uso |
|---|---|
Il account di servizio utilizzato per eseguire la pipeline come job all'interno del cluster Managed Service for Apache Spark. Per impostazione predefinita, è l'account di servizio Compute Engine. (Facoltativo) Nella configurazione di base, puoi modificare il account di servizio predefinito con un altro account di servizio dello stesso progetto. Concedi i seguenti ruoli IAM al nuovo account di servizio:
|
Questo esempio di caso d'uso presuppone che tu utilizzi il account di servizio Compute Engine predefinito ( Concedi i seguenti ruoli al service account Compute Engine predefinito nel progetto Managed Service for Apache Spark.
Concedi il ruolo Utente service account al service account Cloud Data Fusion nel account di servizio Compute Engine predefinito del progetto Managed Service for Apache Spark. Questa azione deve essere eseguita nel progetto Managed Service for Apache Spark. Aggiungi il account di servizio Compute Engine predefinito del progetto Managed Service for Apache Spark al progetto Cloud Data Fusion. Concedi anche i seguenti ruoli:
|
API
| Base di riferimento | Caso d'uso |
|---|---|
Quando attivi l'API Cloud Data Fusion, vengono attivate anche le seguenti API. Per saperne di più su queste API, vai alla pagina
API e servizi del tuo progetto.
Quando abiliti l'API Data Fusion, i seguenti account di servizio vengono aggiunti automaticamente al tuo progetto:
|
Per questo caso d'uso, abilita le seguenti API nel progetto che
contiene il progetto Managed Service per Apache Spark:
|
Chiavi di crittografia
| Base di riferimento | Caso d'uso |
|---|---|
Nella configurazione di base, le chiavi di crittografia possono essere gestite da Google o CMEK Concetti chiave: Se utilizzi CMEK, la configurazione di base richiede quanto segue:
A seconda dei servizi utilizzati nella pipeline, ad esempio BigQuery o Cloud Storage, ai service account deve essere concesso anche il ruolo Autore crittografia/decrittografia CryptoKey Cloud KMS:
|
Se non utilizzi CMEK, non sono necessarie ulteriori modifiche per questo caso d'uso. Se utilizzi CMEK, il ruolo Autore crittografia/decrittografia CryptoKey Cloud KMS deve essere fornito al seguente account di servizio a livello di chiave nel progetto in cui viene creato:
A seconda dei servizi utilizzati nella pipeline, ad esempio BigQuery o Cloud Storage, anche ad altri service account deve essere concesso il ruolo Autore crittografia/decrittografia CryptoKey Cloud KMS a livello di chiave. Ad esempio:
|
Dopo aver apportato queste configurazioni specifiche per il caso d'uso, la pipeline di dati può iniziare a essere eseguita sui cluster in un altro progetto.
Passaggi successivi
- Scopri di più sul networking in Cloud Data Fusion.
- Consulta il riferimento ai ruoli di base e predefiniti di IAM.