
Lignaggio dei dati di Cloud Data Fusion
Puoi utilizzare la tracciabilità dei dati di Cloud Data Fusion per:
Rileva la causa principale degli eventi di dati errati.
Esegui un'analisi dell'impatto prima di apportare modifiche ai dati.
Ti consigliamo di utilizzare l'integrazione della tracciabilità degli asset in Knowledge Catalog. Per ulteriori informazioni, consulta Visualizza la tracciabilità in Knowledge Catalog.
Puoi anche visualizzare la tracciabilità a livello di set di dati e campo in Cloud Data Fusion Studio utilizzando l'opzione Metadati, che mostra la tracciabilità per un intervallo di tempo selezionato.
La derivazione a livello di set di dati mostra la relazione tra set di dati e pipeline.
La tracciabilità a livello di campo mostra le operazioni eseguite su un insieme di campi nel set di dati di origine per produrre un insieme diverso di campi nel set di dati di destinazione.
A partire da Cloud Data Fusion 6.9.2.4, se non monitori la tracciabilità in
Cloud Data Fusion, ti consigliamo di disattivare l'emissione della tracciabilità a livello di campo
nella tua istanza utilizzando il metodo
patch:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Sostituisci quanto segue:
PROJECT_ID: l' Google Cloud ID progettoREGION: la posizione del progetto Google CloudINSTANCE_ID: l'ID istanza Cloud Data Fusion
Scenario del tutorial
In questo tutorial, lavorerai con due pipeline:
La pipeline
Shipment Data Cleansinglegge i dati di spedizione non elaborati da un piccolo set di dati di esempio e applica le trasformazioni per pulire i dati.La pipeline
Delayed Shipments USAlegge quindi i dati di spedizione puliti, li analizza e trova le spedizioni negli Stati Uniti che hanno subito ritardi superiori a una soglia.
Queste pipeline tutorial mostrano uno scenario tipico in cui i dati non elaborati vengono puliti e poi inviati per l'elaborazione downstream. Questo percorso dei dati, dai dati non elaborati ai dati di spedizione puliti fino all'output di dati e analisi, può essere esplorato utilizzando la funzionalità di tracciabilità di Cloud Data Fusion.
Obiettivi
- Genera la tracciabilità eseguendo pipeline di esempio
- Esplora la derivazione a livello di set di dati e di campo
- Scopri come trasferire le informazioni di handshake dalla pipeline upstream alla pipeline downstream
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
- Cloud Data Fusion
- Cloud Storage
- BigQuery
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
- Accedi al tuo account Google Cloud . Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Attiva le API Cloud Data Fusion, Cloud Storage, Dataproc e BigQuery.
Ruoli richiesti per abilitare le API
Per abilitare le API, devi disporre dell'autorizzazione
serviceusage.services.enable. Se hai creato il progetto, probabilmente disponi già di questa autorizzazione tramite il ruolo Proprietario (roles/owner). In caso contrario, puoi ottenere questa autorizzazione tramite il ruolo Amministratore utilizzo dei servizi (roles/serviceusage.serviceUsageAdmin). Scopri come concedere i ruoli.- Crea un'istanza Cloud Data Fusion.
- Fai clic sui seguenti link per scaricare questi piccoli set di dati di esempio sul tuo computer locale:
Apri la UI di Cloud Data Fusion
Quando utilizzi Cloud Data Fusion, utilizzi sia la console Google Cloud che la UI di Cloud Data Fusion separata. Nella console Google Cloud , puoi creare un progetto della console Google Cloud e creare ed eliminare istanze Cloud Data Fusion. Nella UI di Cloud Data Fusion, puoi utilizzare le varie pagine, ad esempio Tracciabilità, per accedere alle funzionalità di Cloud Data Fusion.
Nella console Google Cloud , apri la pagina Istanze.
Nella colonna Azioni per l'istanza, fai clic sul link Visualizza istanza. L'interfaccia utente di Cloud Data Fusion si apre in una nuova scheda del browser.
Nel riquadro Integra, fai clic su Studio per aprire la pagina Studio di Cloud Data Fusion.
Eseguire il deployment delle pipeline ed eseguirle
Importa i dati di spedizione non elaborati. Nella pagina Studio, fai clic su Importa o fai clic su + > Pipeline > Importa, quindi seleziona e importa la pipeline di pulizia dei dati di spedizione che hai scaricato nella sezione Prima di iniziare.
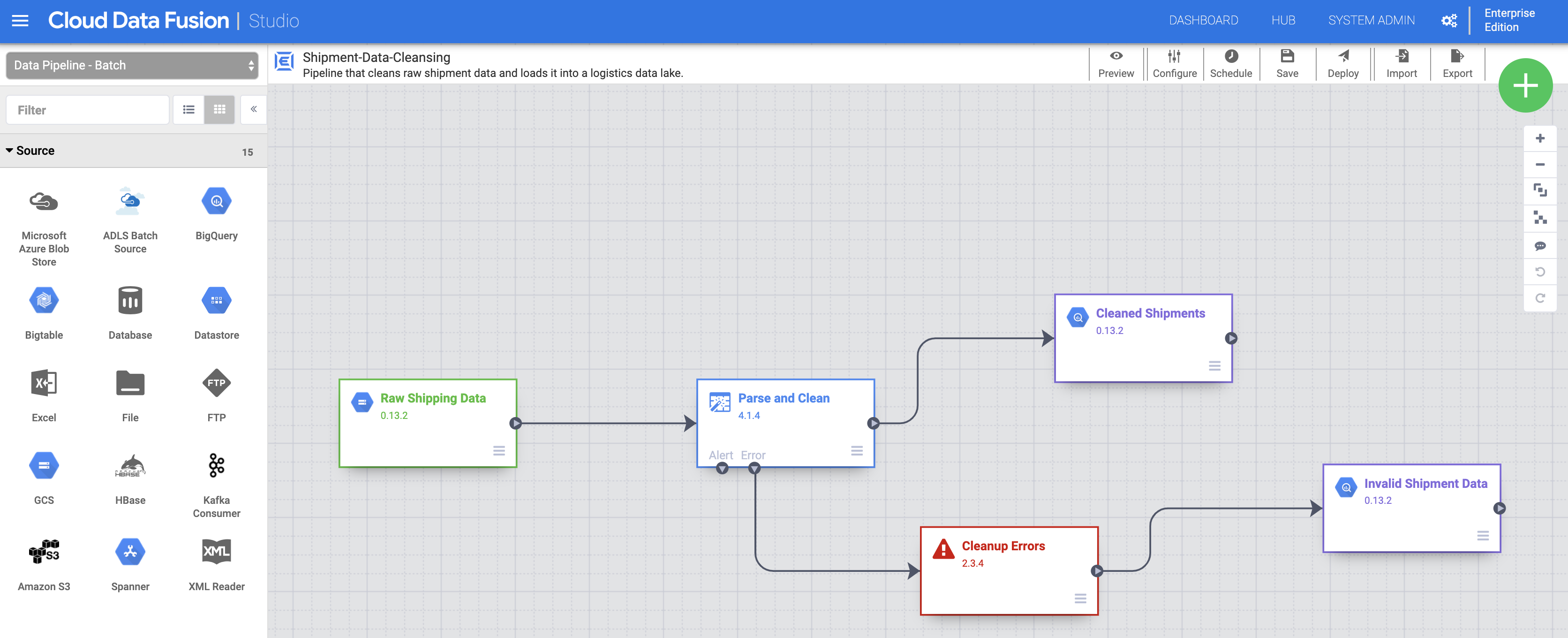
Esegui il deployment della pipeline. Fai clic su Esegui il deployment in alto a destra nella pagina Studio. Dopo il deployment, si apre la pagina Pipeline.
Esegui la pipeline. Fai clic su Esegui nella parte superiore centrale della pagina Pipeline.
Importa, esegui il deployment ed esegui i dati e la pipeline delle spedizioni ritardate. Dopo che lo stato della pulizia dei dati di spedizione mostra Riuscito, applica i passaggi precedenti ai dati delle spedizioni ritardate negli Stati Uniti che hai scaricato in Prima di iniziare. Torna alla pagina Studio per importare i dati, quindi implementa ed esegui questa seconda pipeline dalla pagina Pipeline. Una volta completata correttamente la seconda pipeline, procedi con i passaggi rimanenti.
Scopri i set di dati
Devi scoprire un set di dati prima di esplorarne la tracciabilità. Seleziona Metadati dal pannello di navigazione a sinistra della UI di Cloud Data Fusion per aprire la pagina Ricerca dei metadati. Poiché il set di dati Pulizia dei dati di spedizione ha specificato Cleaned-Shipments come set di dati di riferimento, inserisci shipment nella casella di ricerca. I risultati di ricerca includono questo set di dati.
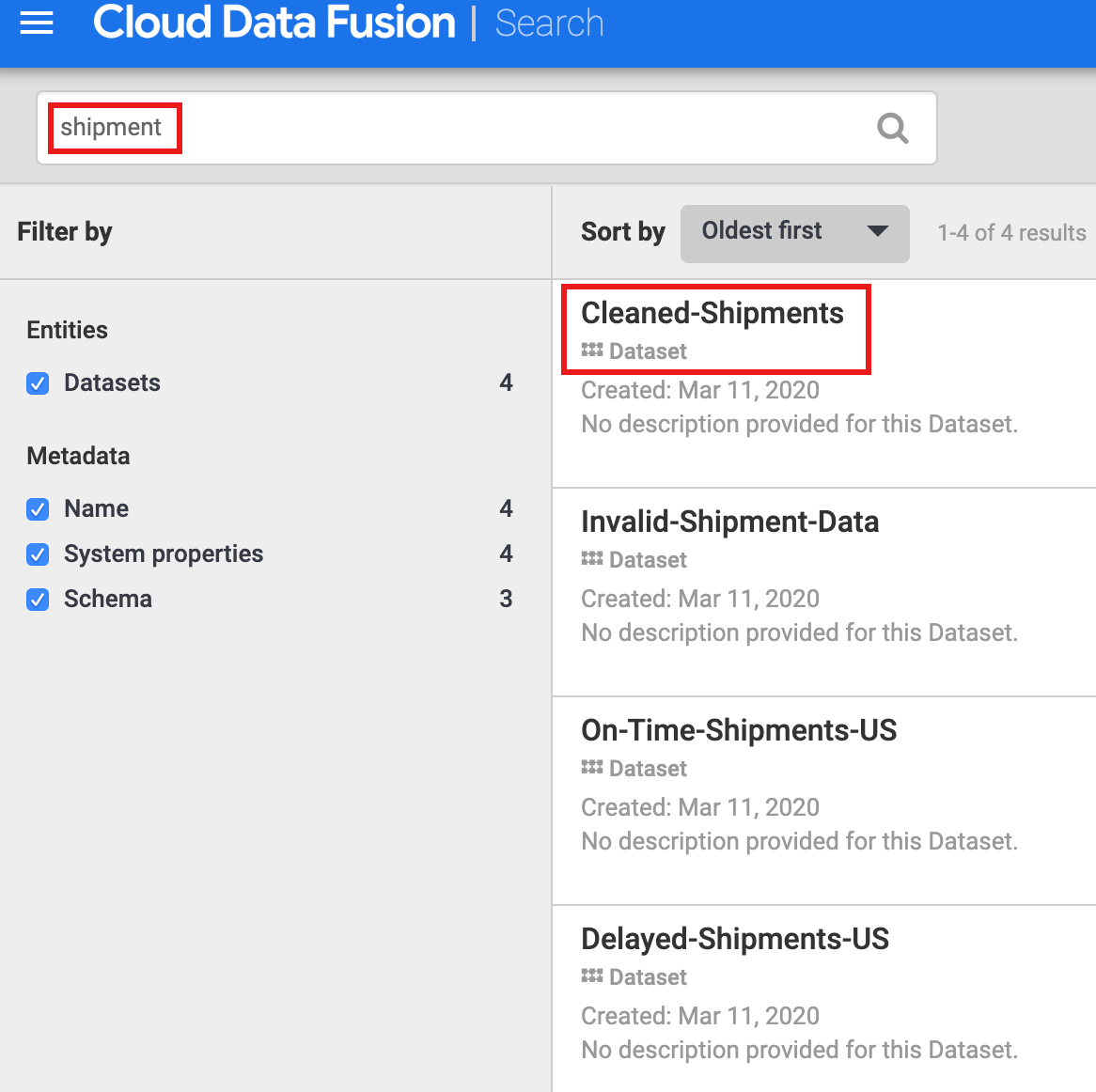
Utilizzare i tag per scoprire i set di dati
Una ricerca di metadati rileva i set di dati utilizzati, elaborati o generati dalle pipeline di Cloud Data Fusion. Le pipeline vengono eseguite su un framework strutturato che genera e raccoglie metadati tecnici e operativi. I metadati tecnici includono nome, tipo, schema, campi, ora di creazione e informazioni di elaborazione del set di dati. Queste informazioni tecniche vengono utilizzate dalle funzionalità di ricerca e tracciabilità dei metadati di Cloud Data Fusion.
Cloud Data Fusion supporta anche l'annotazione dei set di dati con metadati aziendali, come tag e proprietà chiave-valore, che possono essere utilizzati come criteri di ricerca. Ad esempio, per aggiungere e cercare un'annotazione di tag aziendale nel set di dati Dati di spedizione non elaborati:
Fai clic sul pulsante Proprietà del nodo Dati di spedizione non elaborati nella pagina Pipeline di pulizia dei dati di spedizione per aprire la pagina Proprietà di Cloud Storage.
Fai clic su Visualizza metadati per aprire la pagina Cerca.
In Tag dell'attività, fai clic su + e poi inserisci un nome tag (sono consentiti caratteri alfanumerici e trattini bassi) e premi Invio.

Esplora la derivazione
Tracciabilità a livello di set di dati
Fai clic sul nome del set di dati Spedizioni pulite elencato nella pagina di ricerca (da Scopri set di dati), quindi fai clic sulla scheda Lineage. Il grafico della tracciabilità mostra che questo set di dati è stato generato dalla pipeline Shipments-Data-Cleansing, che aveva utilizzato il set di dati Raw_Shipping_Data.
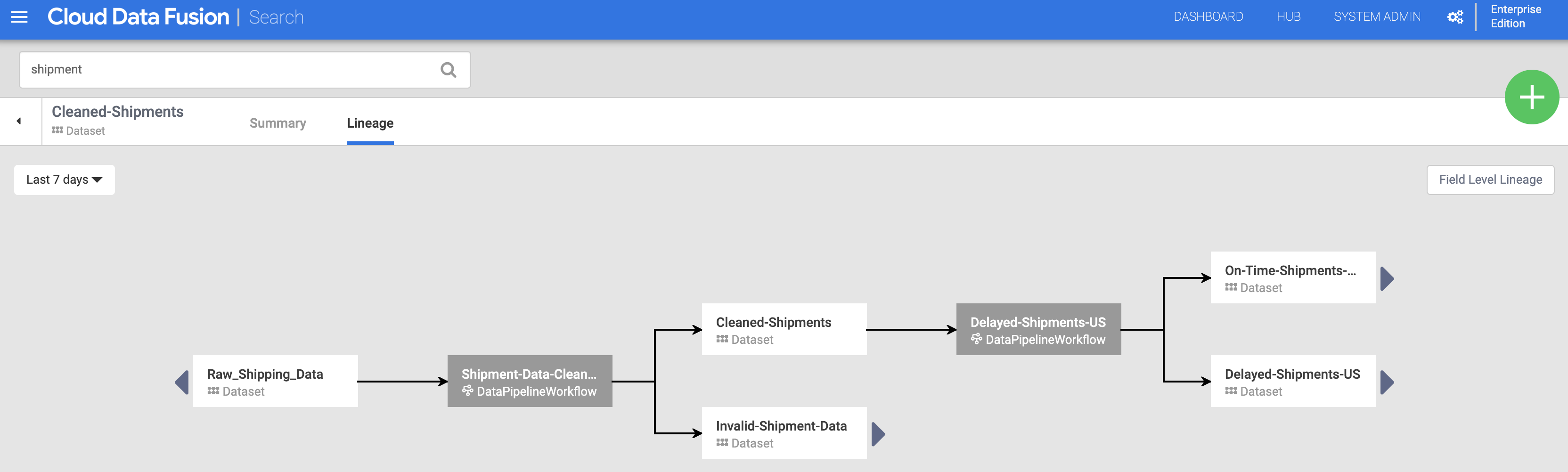
Le frecce sinistra e destra ti consentono di spostarti avanti e indietro nella tracciabilità di qualsiasi set di dati precedente o successivo. In questo esempio, il grafico mostra la tracciabilità completa del set di dati Cleaned-Shipments.
Tracciabilità a livello di campo
La derivazione a livello di campo di Cloud Data Fusion mostra la relazione tra i campi di un set di dati e le trasformazioni eseguite su un insieme di campi per produrre un insieme diverso di campi. Come la derivazione a livello di set di dati, la derivazione a livello di campo è vincolata al tempo e i suoi risultati cambiano nel tempo.
Continuando dal passaggio Derivazione a livello di set di dati, fai clic sul pulsante Derivazione a livello di campo in alto a destra del grafico della derivazione a livello di set di dati Spedizioni pulite per visualizzare il grafico della derivazione a livello di campo.
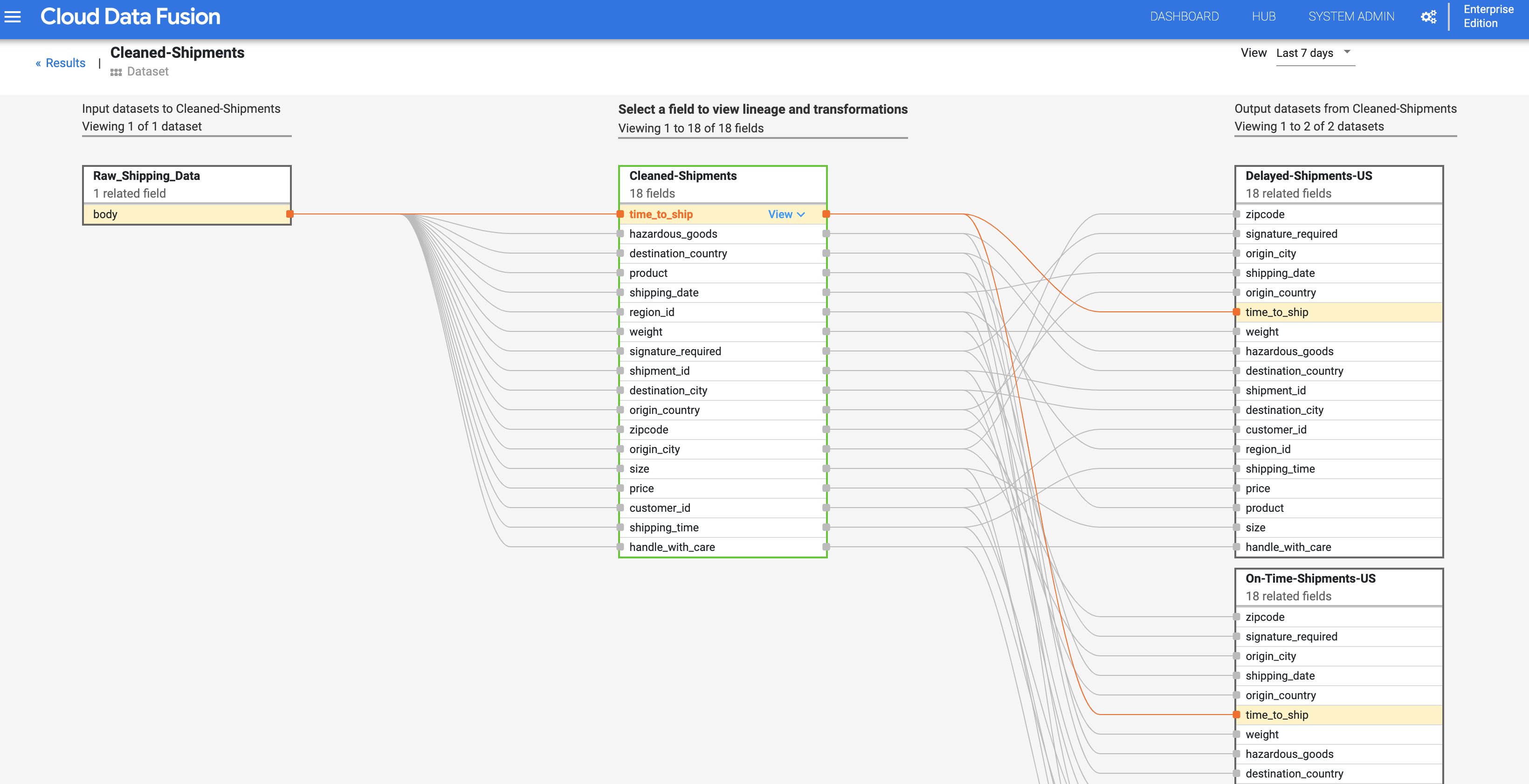
Il grafico della derivazione a livello di campo mostra le connessioni tra i campi. Puoi selezionare un campo per visualizzarne la tracciabilità. Seleziona Visualizza > Blocca campo per visualizzare solo la derivazione di quel campo.
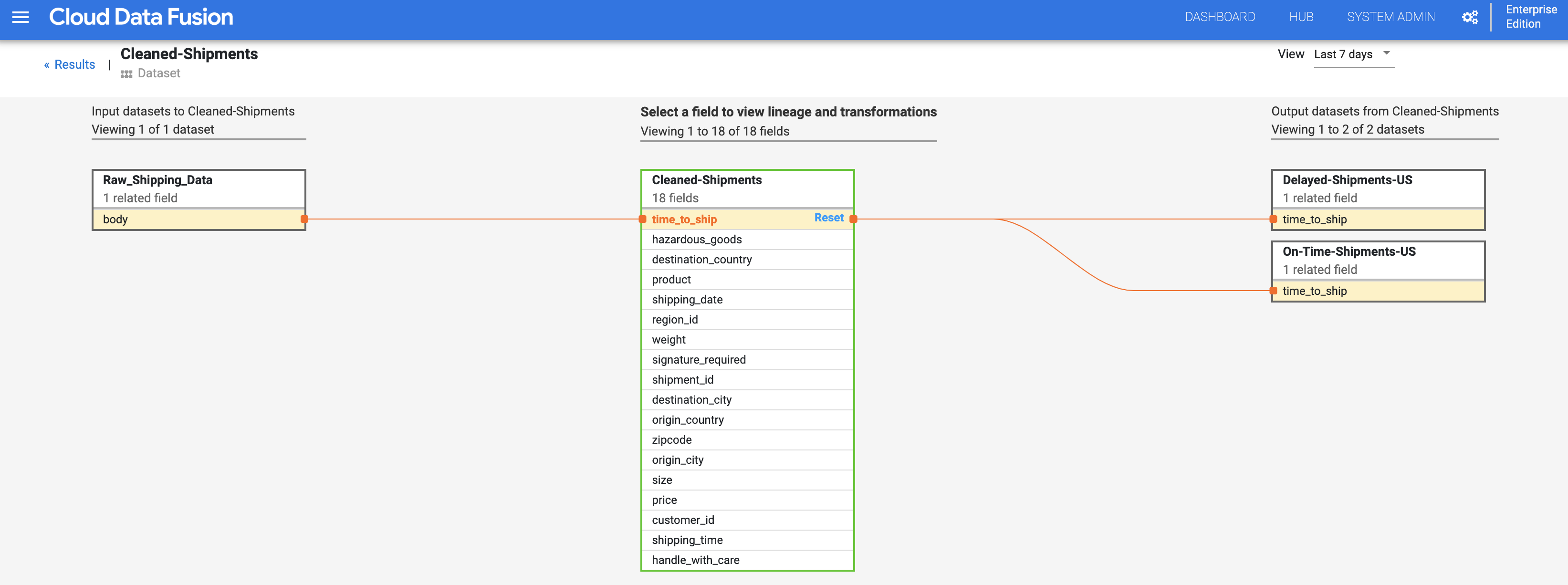
Seleziona Visualizza > Vedi impatto per eseguire un'analisi dell'impatto.
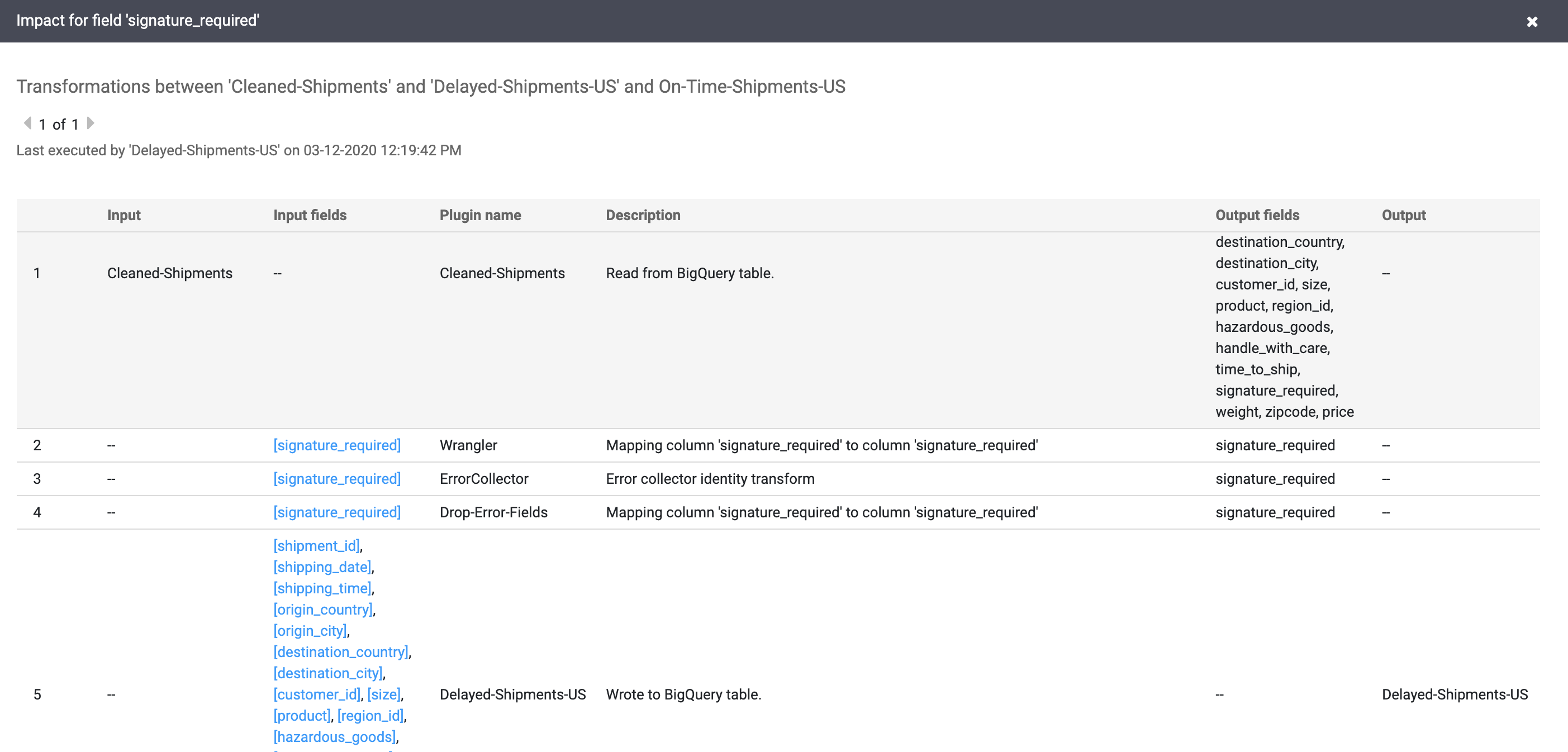
I link a causa e impatto mostrano le trasformazioni eseguite su entrambi i lati di un campo in un formato di registro leggibile. Queste informazioni possono essere essenziali per la reportistica e la governance.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Al termine del tutorial, libera spazio dalle risorse create suGoogle Cloud in modo che non occupino quota e non ti vengano addebitate in futuro. Le seguenti sezioni descrivono come eliminare o disattivare queste risorse.
Elimina il set di dati del tutorial
Questo tutorial crea un set di dati logistics_demo con diverse tabelle nel tuo progetto.
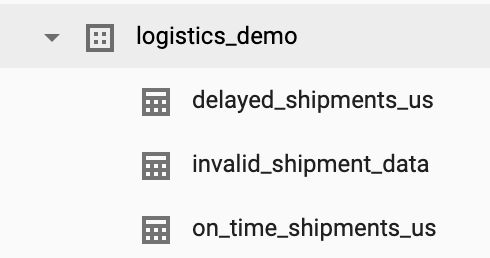
Puoi eliminare il set di dati dall'UI web di BigQuery nella console Google Cloud .
Elimina l'istanza Cloud Data Fusion.
Segui le istruzioni per eliminare l'istanza Cloud Data Fusion.
Elimina il progetto
Il modo più semplice per eliminare la fatturazione è eliminare il progetto creato per il tutorial.
Per eliminare il progetto:
- Nella console Google Cloud , vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona quello che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
Passaggi successivi
- Leggi le guide illustrative
- Completa un altro tutorial