
שושלת נתונים ב-Cloud Data Fusion
אפשר להשתמש ב-Cloud Data Fusion data lineage כדי:
זיהוי שורש הבעיה של אירועי נתונים לא תקינים.
לפני שמבצעים שינויים בנתונים, חשוב לבצע ניתוח השפעה.
מומלץ להשתמש בשילוב של מעקב אחר מקורות נתונים ב-Knowledge Catalog. מידע נוסף זמין במאמר הצגת שושלת ב-Knowledge Catalog.
אפשר גם לראות את שושלת הנתונים ברמות קבוצת נתונים ו-field ב-Cloud Data Fusion Studio באמצעות האפשרות Metadata, שבה מוצגת שושלת הנתונים לטווח תאריכים נבחר.
שושלת נתונים ברמת מערך הנתונים מציגה את הקשר בין מערכי נתונים לבין צינורות.
השורה 'מקורות נתונים' מציגה את הפעולות שבוצעו על קבוצה של שדות במערך נתוני המקור כדי ליצור קבוצה שונה של שדות במערך נתוני היעד.
מגרסה Cloud Data Fusion 6.9.2.4 ואילך, אם אתם לא עוקבים אחרי שושלת נתונים ב-Cloud Data Fusion, מומלץ להשבית את הפליטה של שושלת נתונים ברמת השדה במופע שלכם באמצעות השיטה patch:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: מזהה הפרויקט Google Cloud -
REGION: המיקום של Google Cloud הפרויקט -
INSTANCE_ID: מזהה מופע Cloud Data Fusion
תרחיש הדרכה
במדריך הזה תעבדו עם שני צינורות:
בצינור
Shipment Data Cleansingמתבצעת קריאה של נתוני משלוחים גולמיים ממערך נתונים קטן לדוגמה, ומוחלות עליהם טרנספורמציות כדי לנקות את הנתונים.בשלב הבא, צינור העיבוד
Delayed Shipments USAקורא את נתוני המשלוחים אחרי הניקוי, מנתח אותם ומאתר משלוחים בארה"ב שהעיכוב שלהם חרג מסף מסוים.
צינורות העיבוד האלה של הדרכות מדגימים תרחיש אופייני שבו נתונים גולמיים עוברים ניקוי ואז נשלחים לעיבוד בהמשך. אפשר לעקוב אחרי הנתונים האלה, החל מהנתונים הגולמיים, דרך נתוני המשלוחים הנקיים ועד לתוצאות הניתוח, באמצעות התכונה 'השתלשלות נתונים' ב-Cloud Data Fusion.
מטרות
- יצירת שושלת על ידי הרצת צינורות לדוגמה
- עיון בנתוני השושלת ברמת מערך הנתונים והשדה
- איך מעבירים מידע על תהליך ההתחברות מצינור עיבוד נתונים במעלה הזרם לצינור עיבוד נתונים במורד הזרם
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
- Cloud Data Fusion
- Cloud Storage
- BigQuery
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
מפעילים את ממשקי ה-API של Cloud Data Fusion, Cloud Storage, Dataproc ו-BigQuery.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים- יצירת מכונת Cloud Data Fusion
- כדי להוריד את מערכי הנתונים הקטנים לדוגמה למחשב המקומי, לוחצים על הקישורים הבאים:
פתיחת ממשק המשתמש של Cloud Data Fusion
כשמשתמשים ב-Cloud Data Fusion, משתמשים גם ב Google Cloud מסוף וגם בממשק המשתמש הנפרד של Cloud Data Fusion. במסוף Google Cloud , אפשר ליצור פרויקט במסוף, וליצור ולמחוק מופעים של Cloud Data Fusion. Google Cloud בממשק המשתמש של Cloud Data Fusion, אפשר להשתמש בדפים השונים, כמו Lineage, כדי לגשת לתכונות של Cloud Data Fusion.
נכנסים לדף Instances במסוף Google Cloud .
בעמודה פעולות של המופע, לוחצים על הקישור 'הצגת המופע'. ממשק המשתמש של Cloud Data Fusion נפתח בכרטיסייה חדשה בדפדפן.
בחלונית Integrate (שילוב), לוחצים על Studio (סטודיו) כדי לפתוח את הדף Studio (סטודיו) של Cloud Data Fusion.
פריסה והרצה של צינורות עיבוד נתונים
מייבאים את נתוני המשלוח הגולמיים. בדף Studio, לוחצים על ייבוא או על + > צינור נתונים > ייבוא, ואז בוחרים ומייבאים את צינור הנתונים לניקוי נתוני המשלוח שהורדתם בקטע לפני שמתחילים.
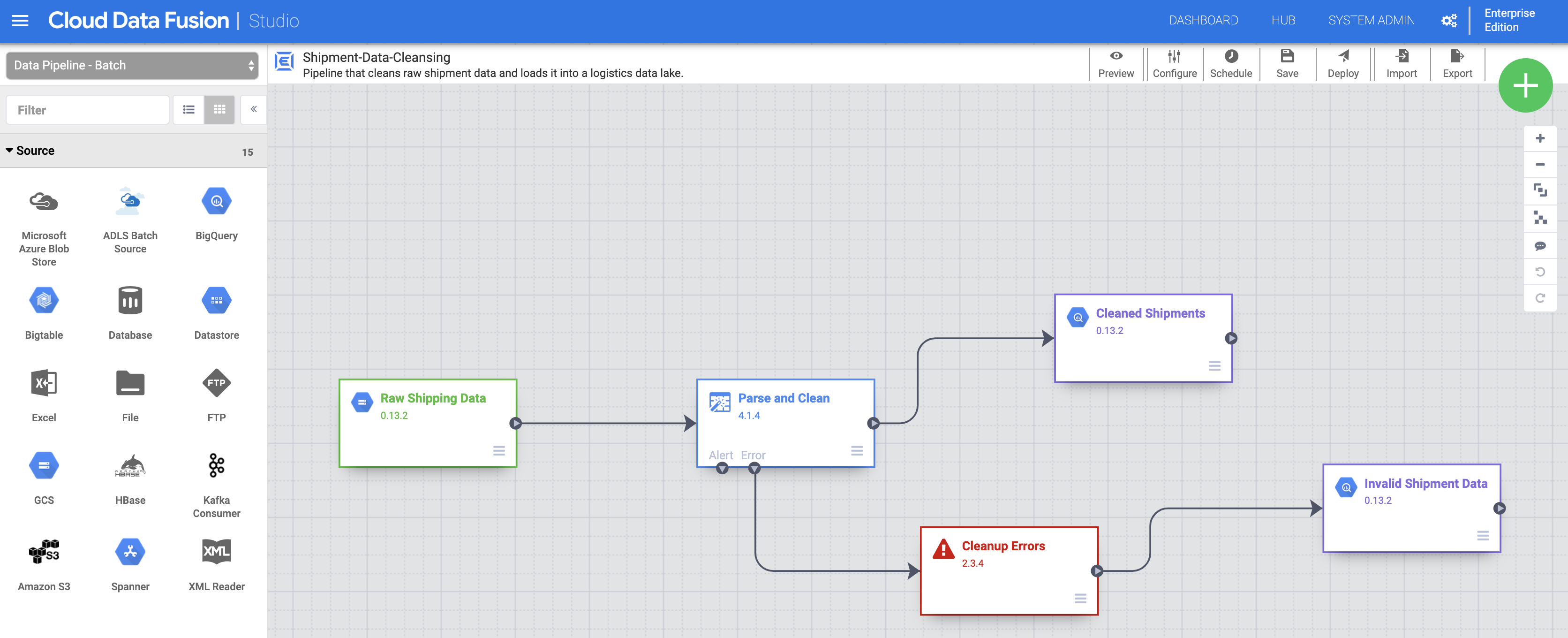
פורסים את צינור עיבוד הנתונים. לוחצים על Deploy (פריסה) בפינה השמאלית העליונה של הדף Studio. אחרי הפריסה, נפתח הדף Pipeline.
מריצים את הפייפליין. לוחצים על 'הפעלה' בחלק העליון המרכזי של הדף Pipeline.
מייבאים, פורסים ומריצים את הנתונים ואת הפייפליין של משלוחים עם עיכוב. אחרי שהסטטוס של ניקוי נתוני המשלוח יהיה הצלחה, צריך לפעול לפי השלבים הקודמים כדי להחיל את השינויים על הנתונים של משלוחים מעוכבים בארה"ב שהורדתם בקטע לפני שמתחילים. חוזרים לדף Studio כדי לייבא את הנתונים, ואז פורסים ומריצים את צינור הנתונים השני הזה מהדף Pipeline. אחרי שהתהליך השני יסתיים בהצלחה, ממשיכים לשלבים הבאים.
גילוי מערכי נתונים
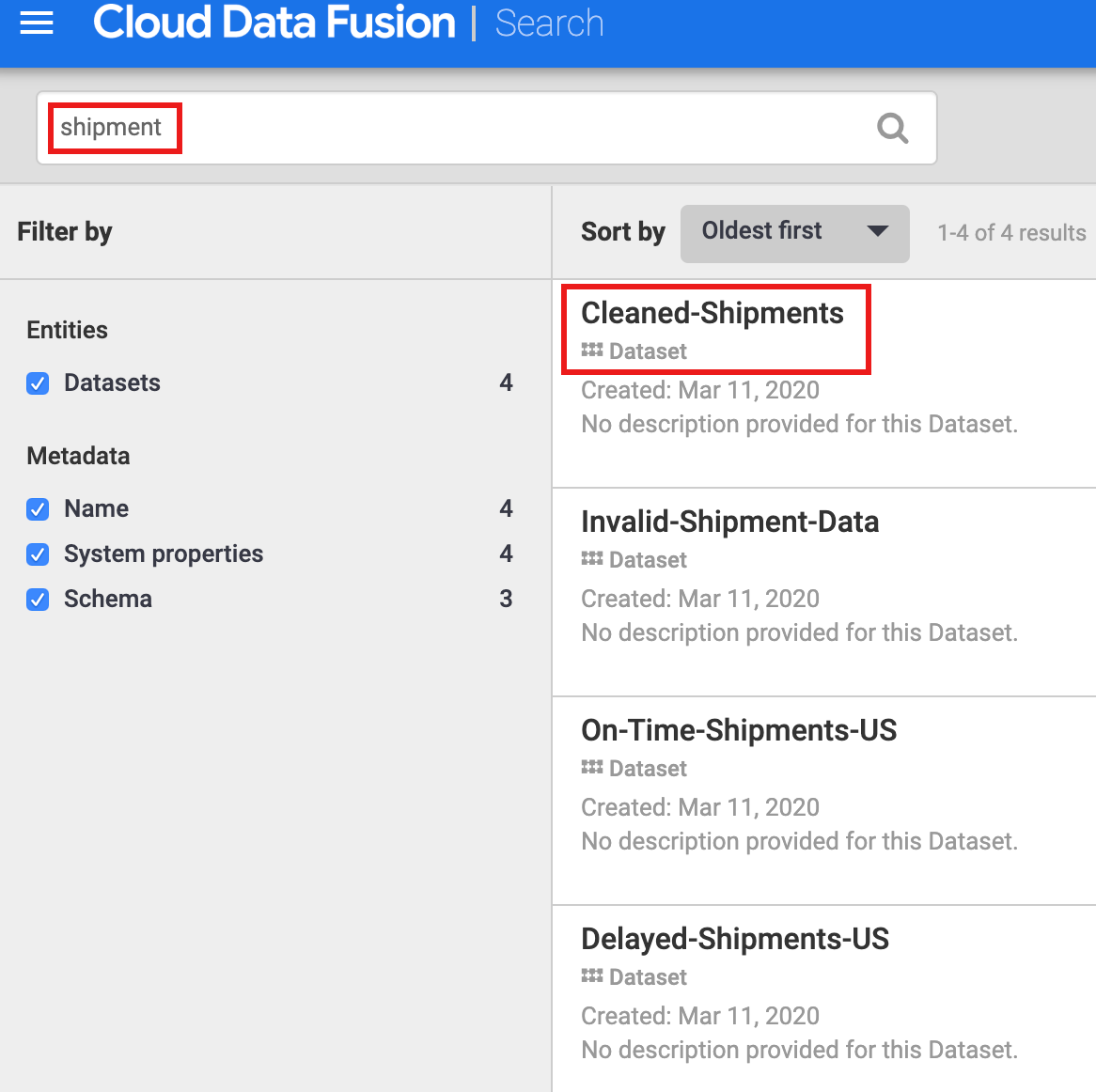
כדי לראות את מקורות הנתונים של מערך נתונים, צריך קודם לגלות אותו. בחלונית הניווט הימנית בממשק המשתמש של Cloud Data Fusion, בוחרים באפשרות מטא-נתונים כדי לפתוח את הדף חיפוש של מטא-נתונים. מכיוון שמערך הנתונים של ניקוי נתוני המשלוח מציין את Cleaned-Shipments כמערך הנתונים להפניה, מזינים shipment בתיבת החיפוש. תוצאות החיפוש כוללות את מערך הנתונים הזה.
שימוש בתגים כדי לגלות מערכי נתונים
חיפוש מטא-נתונים מאפשר לגלות מערכי נתונים שנצרכו, עובדו או נוצרו על ידי צינורות עיבוד נתונים של Cloud Data Fusion. צינורות עיבוד הנתונים פועלים במסגרת מובנית שמייצרת ואוספת מטא-נתונים טכניים ותפעוליים. המטא-נתונים הטכניים כוללים את שם מערך הנתונים, הסוג, הסכימה, השדות, זמן היצירה ופרטי העיבוד. המידע הטכני הזה משמש את התכונות של חיפוש מטא-נתונים ושל שרשרת מקורות ב-Cloud Data Fusion.
Cloud Data Fusion תומך גם בהוספת הערות למערכי נתונים עם מטא-נתונים עסקיים, כמו תגים ומאפיינים של מפתח/ערך, שאפשר להשתמש בהם כקריטריונים לחיפוש. לדוגמה, כדי להוסיף הערה של תג עסק ולחפש אותה במערך הנתונים Raw Shipping Data (נתוני משלוח גולמיים):
לוחצים על הלחצן מאפיינים של הצומת Raw Shipping Data (נתוני משלוח גולמיים) בדף Shipment Data Cleansing (ניקוי נתוני משלוח) של Pipeline (צינור) כדי לפתוח את הדף Cloud Storage Properties (מאפייני Cloud Storage).
לוחצים על View Metadata (הצגת מטא-נתונים) כדי לפתוח את הדף Search (חיפוש).
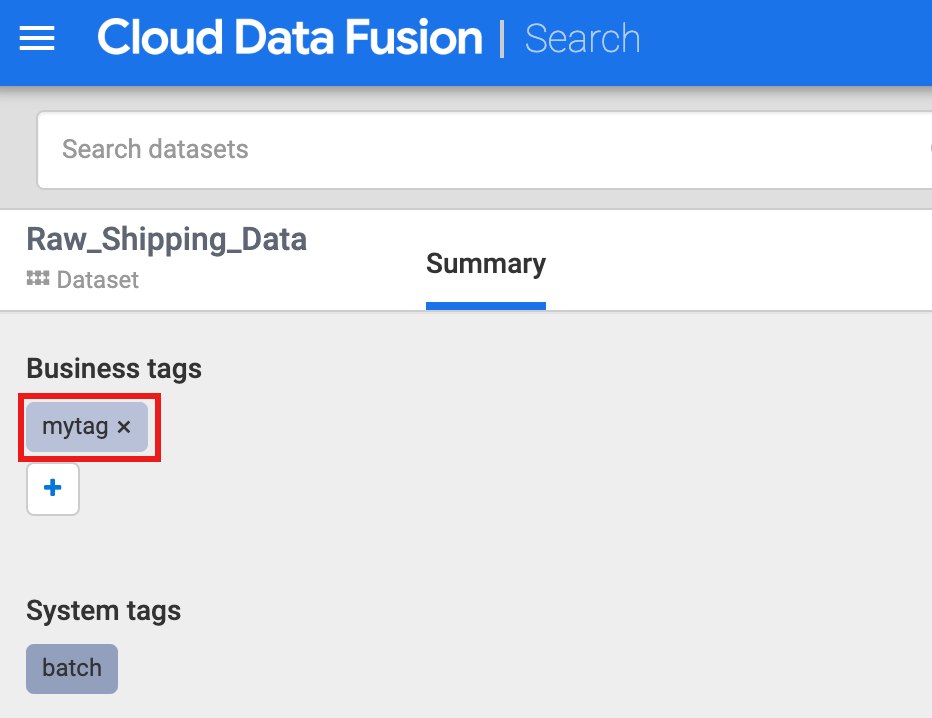
בקטע Business Tags (תגים של העסק), לוחצים על + ואז מזינים שם של תג (מותר להשתמש בתווים אלפאנומריים ובקווים תחתונים) ומקישים על Enter.
עיון בפרטי השושלת
שושלת נתונים ברמת מערך הנתונים
לוחצים על השם של מערך הנתונים Cleaned-Shipments שמופיע בדף החיפוש (מתוך Discover datasets), ואז לוחצים על הכרטיסייה Lineage. תרשים שושלת הנתונים מראה שמערך הנתונים הזה נוצר על ידי צינור עיבוד הנתונים Shipments-Data-Cleansing, שהשתמש במערך הנתונים Raw_Shipping_Data.
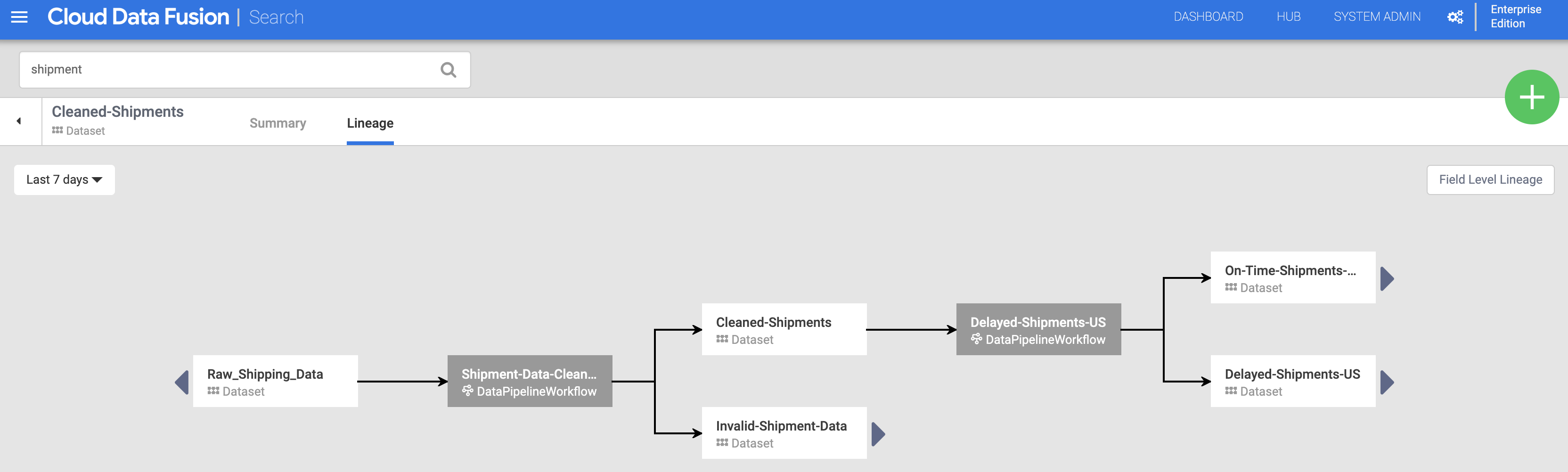
החיצים שמאלה וימינה מאפשרים לנווט אחורה וקדימה בכל שושלת נתונים של קבוצת נתונים קודמת או עוקבת. בדוגמה הזו, בתרשים מוצג שושלת הנתונים המלאה של מערך הנתונים Cleaned-Shipments.
היסטוריית השינויים ברמת השדה
ב-Cloud Data Fusion, שושלת נתונים ברמת השדה מראה את הקשר בין השדות של קבוצת נתונים לבין הטרנספורמציות שבוצעו בקבוצת שדות כדי ליצור קבוצה שונה של שדות. בדומה לשושלת נתונים ברמת קבוצת נתונים, שושלת נתונים ברמת השדה מוגבלת בזמן, והתוצאות שלה משתנות עם הזמן.
ממשיכים מהשלב Dataset level lineage ולוחצים על הלחצן Field Level Lineage בפינה השמאלית העליונה של התרשים Cleaned Shipments dataset-level lineage כדי להציג את התרשים Field Level Lineage.
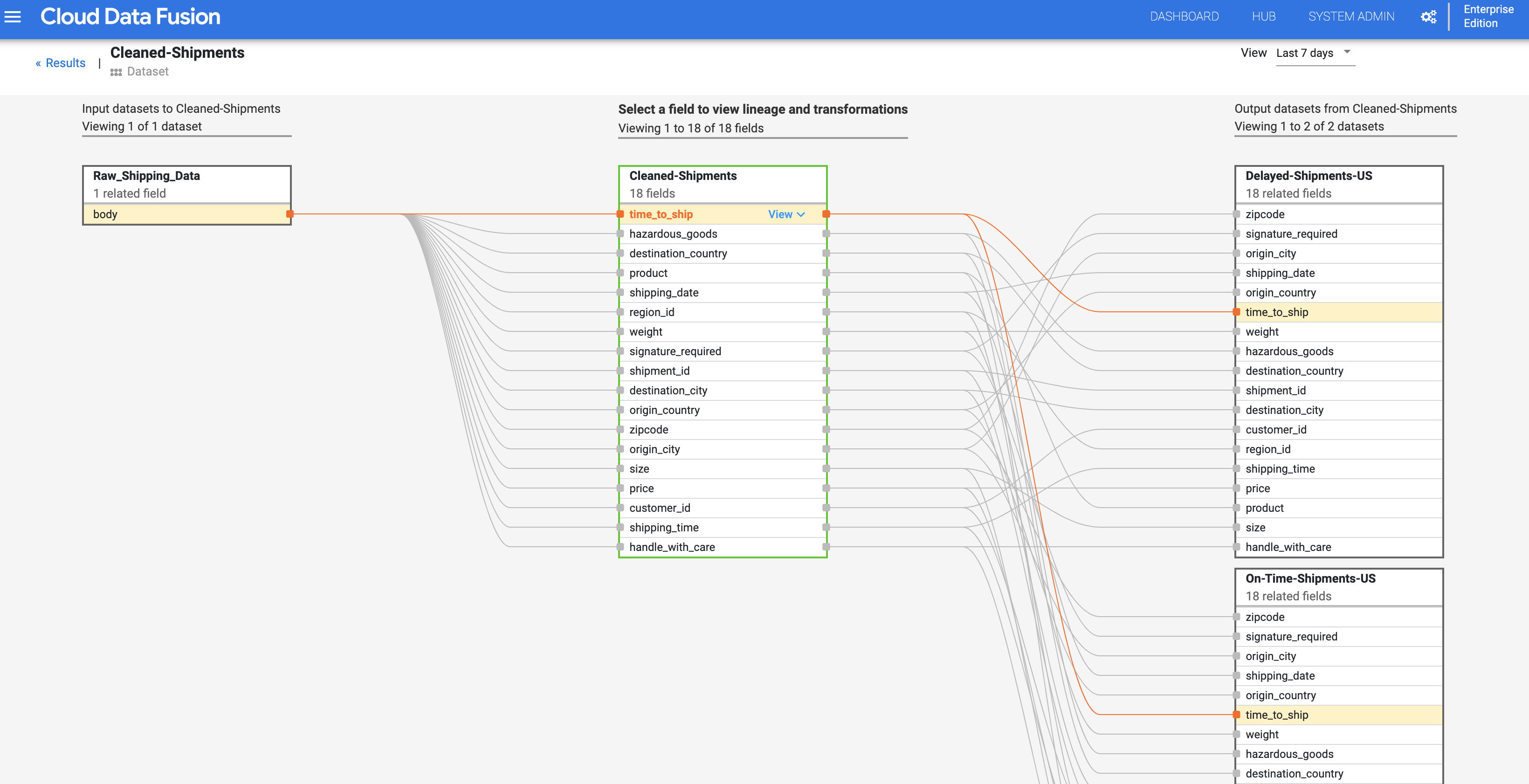
בתרשים של שושלת הנתונים ברמת השדה מוצגים הקשרים בין השדות. אפשר לבחור שדה כדי לראות את שושלת הנתונים שלו. בוחרים באפשרות תצוגה > הצמדת שדה כדי לראות את שושלת הנתונים של השדה הזה בלבד.
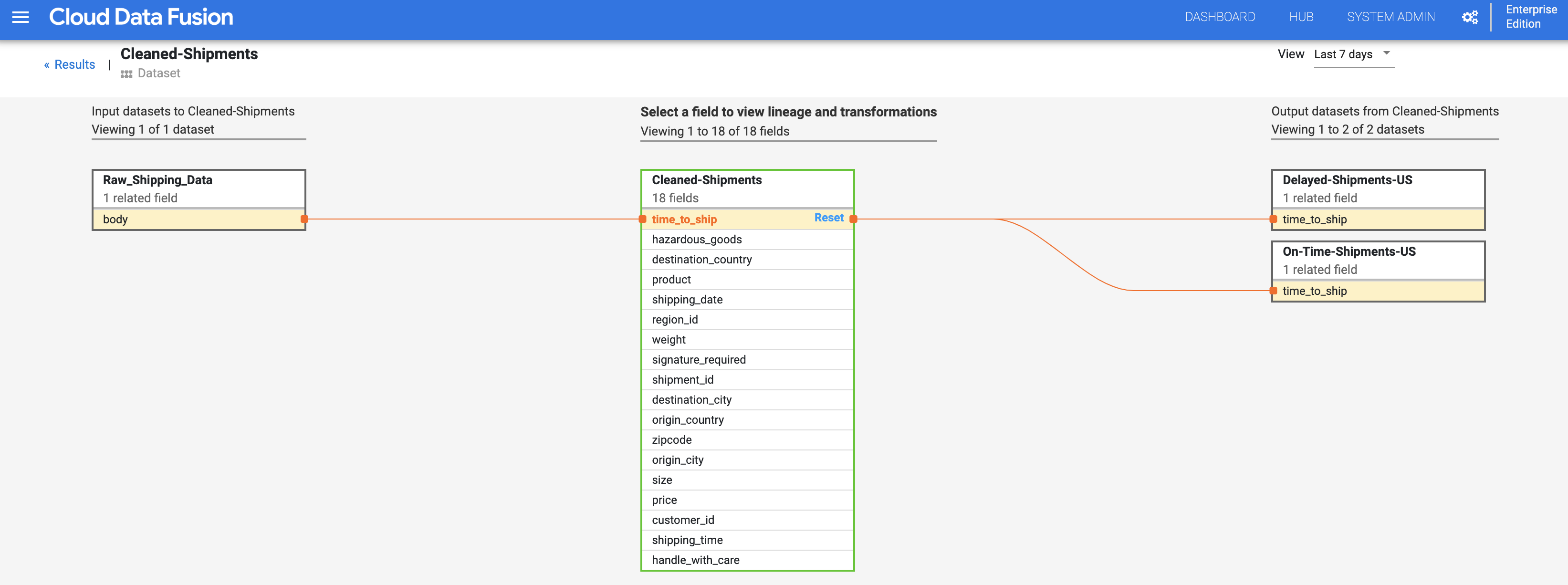
בוחרים באפשרות תצוגה > ניתוח השפעות כדי לבצע ניתוח השפעות.
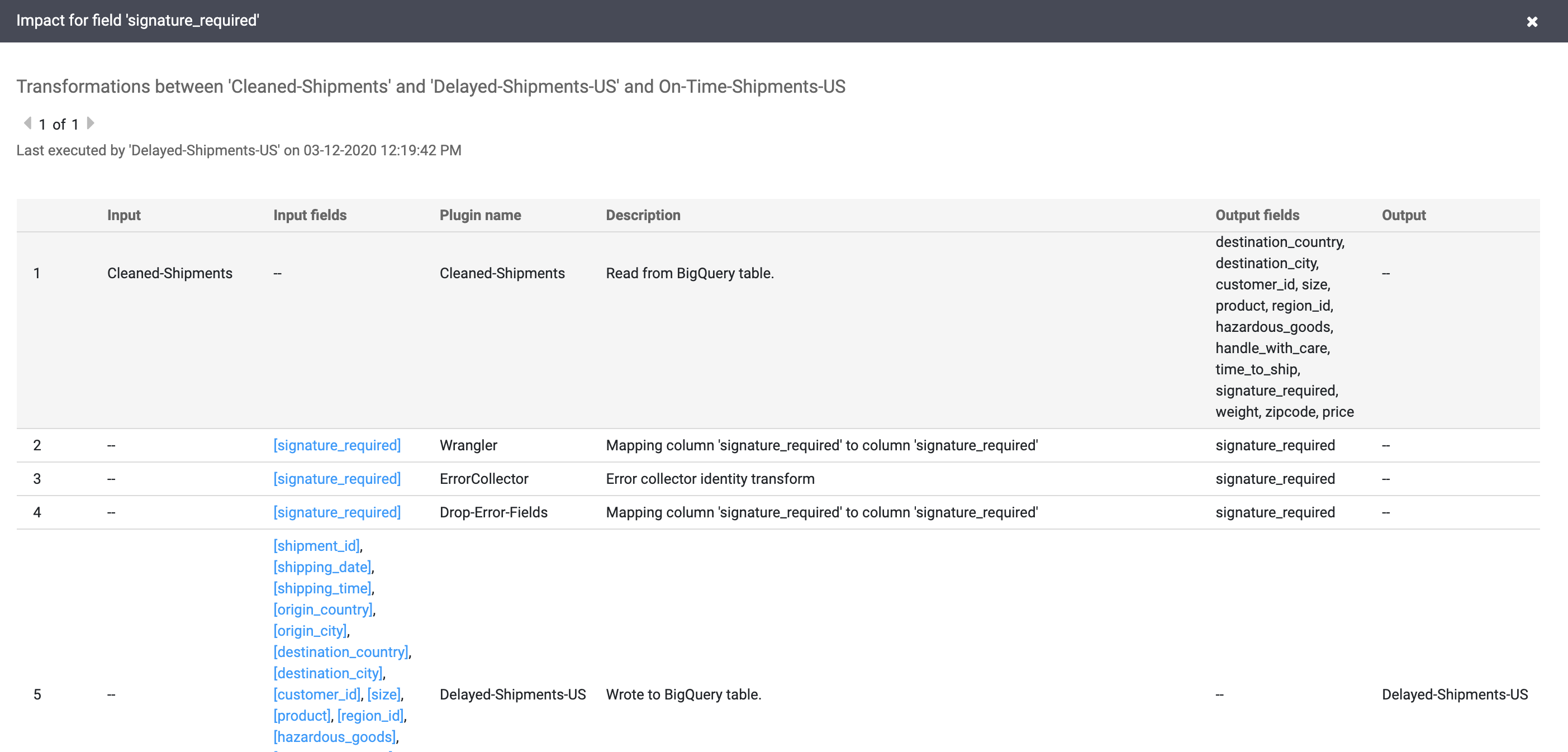
הקישורים 'סיבה' ו'השפעה' מציגים את השינויים שבוצעו בשני הצדדים של שדה בפורמט של ספר חשבונות שקל לקרוא. המידע הזה יכול להיות חיוני לצורך דיווח וניהול.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
בסיום המדריך, חשוב להסיר את המשאבים שיצרתם ב-Google Cloud כדי שלא יתפסו מכסה ולא תחויבו עליהם בעתיד. בסעיפים הבאים מוסבר איך למחוק או להשבית את המשאבים האלו.
מחיקה של מערך הנתונים של המדריך
במדריך הזה יוצרים מערך נתונים logistics_demo עם כמה טבלאות בפרויקט.
אפשר למחוק את מערך הנתונים מממשק האינטרנט של BigQuery ב Google Cloud מסוף.
מחיקת מכונת Cloud Data Fusion
פועלים לפי ההוראות למחיקת מכונת Cloud Data Fusion.
מחיקת הפרויקט
הדרך הקלה ביותר לבטל את החיוב היא למחוק את הפרויקט שיצרתם בשביל המדריך הזה.
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.