
Panduan ini menjelaskan cara men-deploy, mengonfigurasi, dan menjalankan pipeline data yang menggunakan plugin SAP OData.
Anda dapat menggunakan SAP sebagai sumber untuk ekstraksi data berbasis batch di Cloud Data Fusion menggunakan Open Data Protocol (OData). Plugin SAP OData membantu Anda mengonfigurasi dan menjalankan transfer data dari Layanan Katalog SAP OData tanpa coding apa pun.
Untuk mengetahui informasi selengkapnya tentang Layanan Katalog SAP OData dan DataSource yang didukung, lihat detail dukungan. Untuk mengetahui informasi selengkapnya tentang SAP di Google Cloud, lihat Ringkasan SAP di Google Cloud.
Tujuan
- Konfigurasi sistem SAP ERP (aktifkan DataSources di SAP).
- Deploy plugin di lingkungan Cloud Data Fusion Anda.
- Download transpor SAP dari Cloud Data Fusion dan instal di SAP.
- Gunakan Cloud Data Fusion dan SAP OData untuk membuat pipeline data guna mengintegrasikan data SAP.
Sebelum memulai
Untuk menggunakan plugin ini, Anda memerlukan pengetahuan domain di bidang berikut:
- Membuat pipeline di Cloud Data Fusion
- Pengelolaan akses dengan IAM
- Mengonfigurasi SAP Cloud dan sistem enterprise resource planning (ERP) on-premise
Peran pengguna
Tugas di halaman ini dilakukan oleh orang dengan peran berikut di Google Cloud atau di sistem SAP mereka:
| Jenis pengguna | Deskripsi |
|---|---|
| Google Cloud Admin | Pengguna yang diberi peran ini adalah administrator akun Google Cloud. |
| Pengguna Cloud Data Fusion | Pengguna yang diberi peran ini diberi otorisasi untuk mendesain dan menjalankan pipeline data. Mereka diberi, minimal, peran Data Fusion Viewer
(
roles/datafusion.viewer). Jika menggunakan kontrol akses berbasis peran, Anda mungkin memerlukan peran tambahan.
|
| Admin SAP | Pengguna yang diberi peran ini adalah administrator sistem SAP. Mereka memiliki akses untuk mendownload software dari situs layanan SAP. Ini bukan peran IAM. |
| Pengguna SAP | Pengguna yang diberi peran ini diberi otorisasi untuk terhubung ke sistem SAP. Ini bukan peran IAM. |
Prasyarat untuk ekstraksi OData
Layanan Katalog OData harus diaktifkan di sistem SAP.
Data harus diisi di layanan OData.
Prasyarat untuk sistem SAP Anda
Di SAP NetWeaver 7.02 hingga rilis SAP NetWeaver 7.31, fungsi OData dan SAP Gateway disediakan dengan komponen software SAP berikut:
IW_FNDGW_COREIW_BEP
Pada rilis SAP NetWeaver 7.40 dan yang lebih baru, semua fungsi tersedia di komponen
SAP_GWFND, yang harus tersedia di SAP NetWeaver.
Opsional: Menginstal file transport SAP
Komponen SAP yang diperlukan untuk panggilan load balancing ke SAP dikirimkan sebagai file transport SAP yang diarsipkan sebagai file ZIP (satu permintaan transport, yang terdiri dari satu cofile dan satu file data). Anda dapat menggunakan langkah ini untuk membatasi beberapa panggilan paralel ke SAP, berdasarkan proses tugas yang tersedia di SAP.
Download file ZIP tersedia saat Anda men-deploy plugin di Hub Cloud Data Fusion.
Saat Anda mengimpor file transport ke SAP, project SAP OData berikut akan dibuat:
Project OData
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
Node layanan ICF:
GOOG
Untuk menginstal transport SAP, ikuti langkah-langkah berikut:
Langkah 1: Upload file permintaan transportasi
- Login ke sistem operasi Instance SAP.
- Gunakan kode transaksi SAP
AL11untuk mendapatkan jalur folderDIR_TRANS. Biasanya, jalurnya adalah/usr/sap/trans/. - Salin cofile ke folder
DIR_TRANS/cofiles. - Salin file data ke folder
DIR_TRANS/data. - Tetapkan Pengguna dan Grup data dan cofile ke
<sid>admdansapsys.
Langkah 2: Impor file permintaan transpor
Administrator SAP dapat mengimpor file permintaan transpor menggunakan salah satu opsi berikut:
Opsi 1: Mengimpor file permintaan transpor menggunakan sistem pengelolaan transpor SAP
- Login ke sistem SAP sebagai administrator SAP.
- Masukkan STMS transaksi.
- Klik Ringkasan > Impor.
- Di kolom Antrean, klik dua kali SID saat ini.
- Klik Tambahan > Permintaan lainnya > Tambahkan.
- Pilih ID permintaan transpor, lalu klik Lanjutkan.
- Pilih permintaan transpor di antrean impor, lalu klik Minta > Impor.
- Masukkan nomor Klien.
Pada tab Options, pilih Overwrite originals dan Ignore invalid component version (jika tersedia).
(Opsional) Untuk menjadwalkan impor ulang transpor di lain waktu, pilih Biarkan permintaan transpor dalam antrean untuk impor nanti dan Impor permintaan transpor lagi. Hal ini berguna untuk upgrade sistem SAP dan pemulihan cadangan.
Klik Lanjutkan.
Untuk memverifikasi impor, gunakan transaksi apa pun, seperti
SE80danSU01.
Opsi 2: Mengimpor file permintaan transpor di tingkat sistem operasi
- Login ke sistem SAP sebagai administrator sistem SAP.
Tambahkan permintaan yang sesuai ke buffer impor dengan menjalankan perintah berikut:
tp addtobuffer TRANSPORT_REQUEST_ID SIDContoh:
tp addtobuffer IB1K903958 DD1Impor permintaan transpor dengan menjalankan perintah berikut:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Ganti
NNNdengan nomor klien. Contoh:tp import IB1K903958 DD1 client=800 U1238Pastikan modul fungsi dan peran otorisasi berhasil diimpor menggunakan transaksi yang sesuai, seperti
SE80danSU01.
Mendapatkan daftar kolom yang dapat difilter untuk layanan katalog SAP
Hanya beberapa kolom DataSource yang dapat digunakan untuk kondisi filter (ini adalah batasan SAP berdasarkan desain).
Untuk mendapatkan daftar kolom yang dapat difilter untuk layanan katalog SAP, ikuti langkah-langkah berikut:
- Login ke sistem SAP.
- Buka t-code
SEGW. Masukkan nama Project OData, yang merupakan substring dari Nama layanan. Misalnya:
- Nama layanan:
MM_PUR_POITEMS_MONI_SRV - Nama project:
MM_PUR_POITEMS_MONI
- Nama layanan:
Klik Enter.
Buka entitas yang ingin Anda filter, lalu pilih Properties.
Anda dapat menggunakan kolom yang ditampilkan di Properti sebagai filter. Operasi yang didukung adalah Sama dengan dan Di antara (Rentang).

Untuk mengetahui daftar operator yang didukung dalam bahasa ekspresi, lihat dokumentasi open source OData: Konvensi URI (OData Versi 2.0).
Contoh URI dengan filter:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
Mengonfigurasi sistem SAP ERP
Plugin SAP OData menggunakan layanan OData yang diaktifkan di setiap Server SAP tempat data diekstrak. Layanan OData ini dapat berupa layanan standar yang disediakan oleh SAP atau layanan OData kustom yang dikembangkan di sistem SAP Anda.
Langkah 1: Instal SAP Gateway 2.0
Administrator SAP (Basis) harus memverifikasi bahwa komponen SAP Gateway 2.0 tersedia di sistem sumber SAP, bergantung pada rilis NetWeaver. Untuk mengetahui informasi selengkapnya tentang cara menginstal SAP Gateway 2.0, login ke SAP ONE Support Launchpad dan lihat Note 1569624 (login diperlukan) .
Langkah 2: Aktifkan layanan OData
Aktifkan layanan OData yang diperlukan di sistem sumber. Untuk mengetahui informasi selengkapnya, lihat Server front-end: Mengaktifkan layanan OData.
Langkah 3: Buat Peran Otorisasi
Untuk terhubung ke DataSource, buat Peran Otorisasi dengan otorisasi yang diperlukan di SAP, lalu berikan kepada pengguna SAP.
Untuk membuat Peran Otorisasi di SAP, ikuti langkah-langkah berikut:
- Di SAP GUI, masukkan kode transaksi PFCG untuk membuka jendela Role Maintenance.
Di kolom Role, masukkan nama untuk peran tersebut.
Contoh:
ZODATA_AUTHKlik Peran Tunggal.
Jendela Create Roles akan terbuka.
Di kolom Deskripsi, masukkan deskripsi, lalu klik Simpan.
Misalnya:
Authorizations for SAP OData plugin.Klik tab Otorisasi. Judul jendela akan berubah menjadi Ubah Peran.
Di bagian Edit Data Otorisasi dan Buat Profil, klik Ubah Data Otorisasi.
Jendela Pilih Template akan terbuka.
Klik Jangan pilih template.
Jendela Ubah peran: Otorisasi akan terbuka.
Klik Secara Manual.
Berikan otorisasi yang ditampilkan dalam tabel Otorisasi SAP berikut.
Klik Simpan.
Untuk mengaktifkan Peran Otorisasi, klik ikon Buat.
Otorisasi SAP
| Class Objek | Teks Class Objek | Objek otorisasi | Teks objek otorisasi | Otorisasi | Teks | Nilai |
|---|---|---|---|---|---|---|
| AAAB | Objek Otorisasi Lintas Aplikasi | S_SERVICE | Memeriksa di Awal Layanan Eksternal | SRV_NAME | Nama modul program, transaksi, atau fungsi | * |
| AAAB | Objek Otorisasi Lintas Aplikasi | S_SERVICE | Memeriksa di Awal Layanan Eksternal | SRV_TYPE | Jenis Flag Pemeriksaan dan Nilai Default Otorisasi | HT |
| FI | Akuntansi Keuangan | F_UNI_HIER | Akses Hierarki Universal | ACTVT | Aktivitas | 03 |
| FI | Akuntansi Keuangan | F_UNI_HIER | Akses Hierarki Universal | HRYTYPE | Jenis Hierarki | * |
| FI | Akuntansi Keuangan | F_UNI_HIER | Akses Hierarki Universal | HRYID | ID Hierarki | * |
Untuk mendesain dan menjalankan pipeline data di Cloud Data Fusion (sebagai pengguna Cloud Data Fusion), Anda memerlukan kredensial pengguna SAP (nama pengguna dan sandi) untuk mengonfigurasi plugin agar terhubung ke DataSource.
Pengguna SAP harus berjenis Communications atau Dialog. Untuk menghindari penggunaan
resource dialog SAP, sebaiknya gunakan jenis Communications. Pengguna dapat dibuat menggunakan kode transaksi SU01 SAP.
Opsional: Langkah 4: Amankan koneksi
Anda dapat mengamankan komunikasi melalui jaringan antara instance Cloud Data Fusion pribadi dan SAP.
Untuk mengamankan koneksi, ikuti langkah-langkah berikut:
- Administrator SAP harus membuat sertifikat X509. Untuk membuat sertifikat, lihat Membuat PSE Server SSL.
- Admin Google Cloud harus menyalin file X509 ke bucket Cloud Storage yang dapat dibaca dalam project yang sama dengan instance Cloud Data Fusion dan memberikan jalur bucket kepada pengguna Cloud Data Fusion, yang akan memasukkannya saat mengonfigurasi plugin.
- Admin harus memberikan akses baca untuk file X509 kepada pengguna Cloud Data Fusion yang mendesain dan menjalankan pipeline. Google Cloud
Opsional: Langkah 5: Buat layanan OData kustom
Anda dapat menyesuaikan cara data diekstrak dengan membuat layanan OData kustom di SAP:
- Untuk membuat layanan OData kustom, lihat Pembuatan layanan OData untuk pemula.
- Untuk membuat layanan OData kustom menggunakan tampilan layanan data inti (CDS), lihat Cara Membuat layanan OData dan Mengekspos Tampilan CDS sebagai layanan OData.
- Setiap layanan OData kustom harus mendukung kueri
$top,$skip, dan$count. Kueri ini memungkinkan plugin mempartisi data untuk ekstraksi berurutan dan paralel. Jika digunakan, kueri$filter,$expand, atau$selectjuga harus didukung.
Menyiapkan Cloud Data Fusion
Pastikan komunikasi diaktifkan antara instance Cloud Data Fusion dan server SAP. Untuk instance pribadi, siapkan peering jaringan. Setelah peering jaringan dibuat dengan project tempat Sistem SAP dihosting, tidak ada konfigurasi tambahan yang diperlukan untuk terhubung ke instance Cloud Data Fusion Anda. Sistem SAP dan instance Cloud Data Fusion harus berada dalam project yang sama.
Langkah 1: Siapkan lingkungan Cloud Data Fusion Anda
Untuk mengonfigurasi lingkungan Cloud Data Fusion Anda untuk plugin:
Buka detail instance:
Di konsol Google Cloud , buka halaman Cloud Data Fusion.
Klik Instance, lalu klik nama instance untuk membuka halaman Instance details.
Pastikan instance telah diupgrade ke versi 6.4.0 atau yang lebih baru. Jika instance berada di versi yang lebih lama, Anda harus mengupgradenya.
Klik Lihat instance. Saat UI Cloud Data Fusion terbuka, klik Hub.
Pilih tab SAP > SAP OData.
Jika tab SAP tidak terlihat, lihat Memecahkan masalah integrasi SAP.
Klik Deploy SAP OData Plugin.
Plugin kini muncul di menu Source di halaman Studio.
Langkah 2: Konfigurasi plugin
Plugin SAP OData membaca konten SAP DataSource.
Untuk memfilter data, Anda dapat mengonfigurasi properti berikut di halaman SAP OData Properties.
| Nama properti | Deskripsi |
|---|---|
| Basic | |
| Reference Name | Nama yang digunakan untuk mengidentifikasi sumber ini secara unik untuk silsilah atau anotasi metadata. |
| URL Dasar SAP OData | URL Dasar OData SAP Gateway (gunakan jalur URL lengkap, mirip dengan
https://ADDRESS:PORT/sap/opu/odata/sap/).
|
| Versi OData | Versi SAP OData yang didukung. |
| Nama Layanan | Nama layanan SAP OData yang entitasnya ingin Anda ekstrak. |
| Nama Entitas | Nama entitas yang sedang diekstrak, seperti Results. Anda dapat menggunakan awalan, seperti C_PurchaseOrderItemMoni/Results. Kolom ini mendukung parameter Kategori dan Entitas. Contoh:
|
| Kredensial* | |
| Jenis SAP | Dasar (melalui Nama Pengguna dan Sandi). |
| Nama Pengguna SAP Logon | Nama Pengguna SAP Direkomendasikan: Jika Nama Pengguna Login SAP berubah secara berkala, gunakan makro . |
| Sandi SAP Logon | Sandi Pengguna SAP Direkomendasikan: Gunakan makro aman untuk nilai sensitif, seperti sandi. |
| Sertifikat Klien X.509 SAP (Lihat Menggunakan Sertifikat Klien X.509 di Server Aplikasi SAP NetWeaver untuk ABAP. |
|
| ID Project GCP | ID unik global untuk project Anda. Kolom ini wajib diisi jika kolom Jalur Cloud Storage Sertifikat X.509 tidak berisi nilai makro. |
| Jalur GCS | Jalur bucket Cloud Storage yang berisi sertifikat X.509 yang diupload pengguna, yang sesuai dengan server aplikasi SAP untuk panggilan aman berdasarkan persyaratan Anda (lihat langkah Amankan koneksi). |
| Frasa sandi | Frasa sandi yang sesuai dengan sertifikat X.509 yang diberikan. |
| Tombol Get Schema | Membuat skema berdasarkan metadata dari SAP, dengan pemetaan otomatis jenis data SAP ke jenis data Cloud Data Fusion yang sesuai (fungsi yang sama dengan tombol Validasi). |
| Lanjutan | |
| Opsi Filter | Menunjukkan nilai yang harus dimiliki kolom agar dapat dibaca. Gunakan kondisi filter ini untuk membatasi volume data output. Misalnya: `Price Gt 200` memilih rekaman dengan nilai kolom `Price` yang lebih besar dari `200`. (Lihat Mendapatkan daftar kolom yang dapat difilter untuk layanan katalog SAP.) |
| Pilih Kolom | Kolom yang akan dipertahankan dalam data yang diekstrak (misalnya: Kategori, Harga, Nama, Pemasok/Alamat). |
| Perluas Kolom | Daftar kolom kompleks yang akan diperluas dalam data output yang diekstrak (misalnya: Produk/Pemasok). |
| Jumlah Baris yang Akan Dilewati | Jumlah total baris yang akan dilewati (misalnya: 10). |
| Jumlah Baris yang Akan Diambil | Jumlah total baris yang akan diekstrak. |
| Jumlah Pemisahan yang Akan Dibuat | Jumlah pemisahan yang digunakan untuk mempartisi data input. Lebih banyak partisi
meningkatkan tingkat paralelisme, tetapi memerlukan lebih banyak resource dan
overhead. Jika dibiarkan kosong, plugin akan memilih nilai yang optimal (direkomendasikan). |
| Ukuran Batch | Jumlah baris yang akan diambil di setiap panggilan jaringan ke SAP. Ukuran kecil menyebabkan
panggilan jaringan yang sering mengulangi overhead terkait. Ukuran yang besar
dapat memperlambat pengambilan data dan menyebabkan penggunaan resource yang berlebihan di SAP.
Jika nilainya ditetapkan ke 0, nilai defaultnya adalah
2500, dan batas baris yang akan diambil dalam setiap batch adalah
5000. |
| Waktu Tunggu Baca | Waktu, dalam detik, untuk menunggu layanan SAP OData. Nilai defaultnya adalah 300. Untuk tanpa batas waktu, setel ke 0. |
Jenis OData yang didukung
Tabel berikut menunjukkan pemetaan antara jenis data OData v2 yang digunakan dalam aplikasi SAP dan jenis data Cloud Data Fusion.
| Jenis OData | Deskripsi (SAP) | Jenis data Cloud Data Fusion |
|---|---|---|
| Numerik | ||
| SByte | Nilai bilangan bulat 8-bit bertanda | int |
| Byte | Nilai bilangan bulat 8-bit tanpa tanda | int |
| Int16 | Nilai bilangan bulat 16-bit bertanda | int |
| Int32 | Nilai bilangan bulat 32-bit bertanda | int |
| Int64 | Nilai bilangan bulat 64-bit yang telah ditandatangani dan ditambahkan dengan karakter: 'L' Contoh: 64L, -352L |
long |
| Sekali | Bilangan floating point dengan presisi 7 digit yang dapat merepresentasikan nilai dengan perkiraan rentang ± 1,18e -38 hingga ± 3,40e +38, yang ditambahkan dengan karakter: 'f' Contoh: 2.0f |
float |
| Ganda | Bilangan floating point dengan presisi 15 digit yang dapat merepresentasikan nilai
dengan rentang perkiraan ± 2,23e -308 hingga ± 1,79e +308, ditambahkan
dengan karakter: 'd' Contoh: 1E+10d, 2.029d, 2.0d |
double |
| Desimal | Nilai numerik dengan presisi dan skala tetap yang mendeskripsikan nilai numerik
yang berkisar dari negatif 10^255 + 1 hingga positif 10^255 -1, yang ditambahkan dengan
karakter: 'M' atau 'm' Contoh: 2.345M |
decimal |
| Karakter | ||
| Guid | Nilai ID unik 16 byte (128 bit), yang dimulai dengan
karakter: 'guid' Contoh: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| String | Data karakter dengan panjang tetap atau variabel yang dienkode dalam UTF-8 | string |
| Byte | ||
| Biner | Data biner dengan panjang tetap atau variabel, yang dimulai dengan 'X' atau
'binary' (keduanya peka huruf besar/kecil) Contoh: X'23AB', binary'23ABFF' |
bytes |
| Logika | ||
| Boolean | Konsep matematika logika bernilai biner | boolean |
| Date/Time | ||
| Tanggal/Waktu | Tanggal dan waktu dengan nilai mulai dari 00.00.00 pada 1 Januari 1753 hingga 23.59.59 pada 31 Desember 9999 | timestamp |
| Waktu | Waktu dalam sehari dengan nilai mulai dari 0:00:00.x hingga 23:59:59.y, dengan 'x' dan 'y' bergantung pada presisi | time |
| DateTimeOffset | Tanggal dan waktu sebagai Offset, dalam menit dari GMT, dengan nilai yang berkisar dari 00.00.00 pada 1 Januari 1753 hingga 23.59.59 pada 31 Desember 9999 | timestamp |
| Kompleks | ||
| Properti Navigasi dan Non-Navigasi (multiplicity = *) | Koleksi suatu jenis, dengan multiplisitas one-to-many. | array,string,int. |
| Properti (multiplisitas = 0,1) | Referensi ke jenis kompleks lainnya dengan multiplisitas satu-ke-satu | record |
Validasi
Klik Validasi di kanan atas atau Dapatkan Skema.
Plugin memvalidasi properti dan menghasilkan skema berdasarkan metadata dari SAP. Plugin ini otomatis memetakan jenis data SAP ke jenis data Cloud Data Fusion yang sesuai.
Menjalankan pipeline data
- Setelah men-deploy pipeline, klik Configure di panel tengah atas.
- Pilih Sumber.
- Jika perlu, ubah CPU Eksekutor dan Memori berdasarkan ukuran data keseluruhan dan jumlah transformasi yang digunakan dalam pipeline.
- Klik Simpan.
- Untuk memulai pipeline data, klik Run.
Performa
Plugin ini menggunakan kemampuan paralelisasi Cloud Data Fusion. Panduan berikut dapat membantu Anda mengonfigurasi lingkungan runtime sehingga Anda menyediakan resource yang memadai untuk mesin runtime guna mencapai tingkat paralelisme dan performa yang diinginkan.
Mengoptimalkan konfigurasi plugin
Direkomendasikan: Kecuali jika Anda memahami setelan memori sistem SAP, biarkan Number of Splits to Generate dan Batch Size kosong (tidak ditentukan).
Untuk performa yang lebih baik saat menjalankan pipeline, gunakan konfigurasi berikut:
Number of Splits to Generate: nilai antara
8dan16direkomendasikan. Namun, nilai tersebut dapat meningkat menjadi32, atau bahkan64, dengan konfigurasi yang sesuai di sisi SAP (mengalokasikan resource memori yang sesuai untuk proses kerja di SAP). Konfigurasi ini meningkatkan paralelisme di sisi Cloud Data Fusion. Mesin runtime membuat jumlah partisi (dan koneksi SAP) yang ditentukan saat mengekstrak data.Jika Layanan Konfigurasi (yang disertakan dengan plugin saat Anda mengimpor file transport SAP) tersedia: plugin secara default menggunakan konfigurasi sistem SAP. Pembagiannya adalah 50% dari proses tugas dialog yang tersedia di SAP. Catatan: Layanan Konfigurasi hanya dapat diimpor dari sistem S4HANA.
Jika Layanan Konfigurasi tidak tersedia, defaultnya adalah pemisahan
7.Dalam kedua kasus tersebut, jika Anda menentukan nilai yang berbeda, nilai yang Anda berikan akan lebih diutamakan daripada nilai pemisahan default,kecuali jika dibatasi oleh proses dialog yang tersedia di SAP, dikurangi dua pemisahan.
Jika jumlah rekaman yang akan diekstrak kurang dari
2500, jumlah pemisahan adalah1.
Ukuran Batch: ini adalah jumlah kumpulan data yang akan diambil di setiap panggilan jaringan ke SAP. Ukuran batch yang lebih kecil menyebabkan panggilan jaringan yang sering, yang mengulangi overhead terkait. Secara default, jumlah minimum adalah
1000dan jumlah maksimum adalah50000.
Untuk mengetahui informasi selengkapnya, lihat Batas entitas OData.
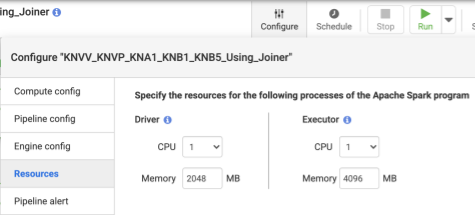
Setelan resource Cloud Data Fusion
Direkomendasikan: Gunakan 1 CPU dan memori 4 GB per Eksekutor (nilai ini berlaku untuk setiap proses Eksekutor). Tetapkan ini dalam dialog Konfigurasi > Resource.
Setelan cluster Managed Service untuk Apache Spark
Direkomendasikan: Setidaknya, alokasikan total CPU (di seluruh pekerja) yang lebih besar dari jumlah pemisahan yang diinginkan (lihat Konfigurasi plugin).
Setiap pekerja harus memiliki memori yang dialokasikan sebesar 6,5 GB atau lebih per CPU di setelan Managed Service for Apache Spark (ini berarti 4 GB atau lebih tersedia per Cloud Data Fusion Executor). Setelan lainnya dapat dipertahankan pada nilai default.
Direkomendasikan: Gunakan cluster Managed Service for Apache Spark yang persisten untuk mengurangi waktu proses pipeline data (tindakan ini menghilangkan langkah Penyediaan yang mungkin memerlukan beberapa menit atau lebih). Tetapkan ini di bagian konfigurasi Compute Engine.
Contoh konfigurasi dan throughput
Bagian berikut menjelaskan contoh konfigurasi pengembangan dan produksi serta throughput.
Contoh konfigurasi pengembangan dan pengujian
- Cluster Managed Service for Apache Spark dengan 8 pekerja, masing-masing dengan 4 CPU dan memori 26 GB. Buat hingga 28 pemisahan.
- Cluster Managed Service for Apache Spark dengan 2 pekerja, masing-masing dengan 8 CPU dan memori 52 GB. Buat hingga 12 pemisahan.
Contoh konfigurasi dan throughput produksi
- Cluster Managed Service untuk Apache Spark dengan 8 pekerja, masing-masing dengan 8 CPU dan memori 32 GB. Buat hingga 32 pemisahan (setengah dari CPU yang tersedia).
- Cluster Managed Service for Apache Spark dengan 16 pekerja, masing-masing dengan 8 CPU dan memori 32 GB. Buat hingga 64 pemisahan (setengah dari CPU yang tersedia).
Contoh throughput untuk sistem sumber produksi SAP S4HANA 1909
Tabel berikut memiliki contoh throughput. Throughput yang ditampilkan adalah tanpa opsi filter kecuali ditentukan lain. Saat menggunakan opsi filter, throughput akan berkurang.
| Ukuran batch | Membagi | Layanan OData | Total baris | Baris yang diekstrak | Throughput (baris per detik) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5,37 M | 5,37 M | 1069 |
| 2500 | 10 | ZACDOCA_CDS | 5,37 M | 5,37 M | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 5,37 M | 5,37 M | 4630 |
| 5000 | 9 | ZACDOCA_CDS | 5,37 M | 5,37 M | 4817 |
Contoh throughput untuk sistem sumber produksi cloud SAP S4HANA
| Ukuran batch | Membagi | Layanan OData | Total baris | Baris yang diekstrak | Throughput (GB/jam) |
|---|---|---|---|---|---|
| 2500 | 40 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 JT | 25,48 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 JT | 26,78 |
Detail dukungan
Plugin ini mendukung kasus penggunaan berikut.
Produk dan versi SAP yang didukung
Sumber yang didukung mencakup SAP S4/HANA 1909 dan yang lebih baru, S4/HANA di SAP Cloud, dan aplikasi SAP apa pun yang dapat mengekspos Layanan OData.
File transport yang berisi layanan OData kustom untuk menyeimbangkan beban panggilan ke SAP harus diimpor di S4/HANA 1909 dan yang lebih baru. Layanan ini membantu menghitung jumlah pemisahan (partisi data) yang dapat dibaca plugin secara paralel (lihat jumlah pemisahan).
OData versi 2 didukung.
Plugin ini diuji dengan server SAP S/4HANA yang di-deploy di Google Cloud.
Layanan Katalog SAP OData didukung untuk ekstraksi
Plugin ini mendukung jenis DataSource berikut:
- Data transaksi
- Tampilan CDS yang diekspos melalui OData
Data master
- Atribut
- Teks
- Hierarki
Catatan SAP
Tidak ada catatan SAP yang diperlukan sebelum ekstraksi, tetapi sistem SAP harus memiliki SAP Gateway yang tersedia. Untuk mengetahui informasi selengkapnya, lihat Catatan 1560585 (situs eksternal ini memerlukan login SAP).
Batasan pada volume data atau lebar rekaman
Tidak ada batas yang ditentukan untuk volume data yang diekstrak. Kami telah menguji dengan hingga 6 juta baris yang diekstrak dalam satu panggilan, dengan lebar rekaman 1 KB. Untuk SAP S4/HANA di cloud, kami telah melakukan pengujian dengan hingga 10 juta baris yang diekstrak dalam satu panggilan, dengan lebar rekaman 1 KB.
Throughput plugin yang diharapkan
Untuk lingkungan yang dikonfigurasi sesuai dengan panduan di bagian Performa, plugin dapat mengekstrak sekitar 38 GB per jam. Performa aktual dapat bervariasi dengan beban sistem Cloud Data Fusion dan SAP atau traffic jaringan.
Ekstraksi delta (data yang diubah)
Ekstraksi delta tidak didukung.
Skenario error
Saat runtime, plugin menulis entri log di log pipeline data Cloud Data Fusion. Entri ini diawali dengan CDF_SAP untuk identifikasi.
Pada waktu desain, saat Anda memvalidasi setelan plugin, pesan akan ditampilkan di tab Properti dan ditandai dengan warna merah.
Daftar berikut menjelaskan beberapa error:
| ID Pesan | Pesan | Tindakan yang disarankan |
|---|---|---|
| Tidak ada | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
Masukkan nilai sebenarnya atau variabel makro. |
| Tidak ada | Invalid value for property 'PROPERTY_NAME'. |
Masukkan bilangan bulat non-negatif (0 atau lebih besar, tanpa desimal) atau variabel makro. |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
Pastikan nilai makro yang diberikan sudah benar. |
| T/A | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
Pastikan jalur Cloud Storage yang diberikan sudah benar. |
| CDF_SAP_ODATA_01532 | Kode error generik yang terkait dengan masalah konektivitas SAP ODataFailed to call given SAP OData service. Root Cause:
MESSAGE. |
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
| CDF_SAP_ODATA_01534 | Kode error umum yang terkait dengan error layanan SAP OData.Service validation failed. Root Cause: MESSAGE. |
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
Periksa penyebab utama yang ditampilkan dalam pesan dan ambil tindakan yang sesuai. |
Langkah berikutnya
- Pelajari lebih lanjut Cloud Data Fusion.
- Pelajari lebih lanjut SAP di Google Cloud.