
Cette page explique comment lire plusieurs tables d'une base de données Microsoft SQL Server, à l'aide de la source multi-tables. Utilisez la source multi-tables lorsque vous souhaitez que votre pipeline lise des données à partir de plusieurs tables. Si vous souhaitez que votre pipeline lise des données à partir d'une seule table, consultez la section Lire les données d'une table SQL Server.
La source multi-tables génère des données avec plusieurs schémas et inclut un champ de nom de table indiquant la table de provenance des données. Lorsque vous utilisez la source multi-tables, utilisez l'un des récepteurs multi-tables, à savoir BigQuery multi-tables ou GCS multi-fichiers.
Avant de commencer
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Activez les API Cloud Data Fusion, Cloud Storage, BigQuery et Dataproc.
Rôles requis pour activer les API
Pour activer les API, vous avez besoin du rôle IAM Administrateur Service Usage (
roles/serviceusage.serviceUsageAdmin), qui contient l'autorisationserviceusage.services.enable. Découvrez comment attribuer des rôles.- Créez une instance Cloud Data Fusion.
- Assurez-vous que votre base de données SQL Server peut accepter les connexions depuis Cloud Data Fusion. Pour ce faire, nous vous recommandons de créer une instance Cloud Data Fusion privée.
Afficher votre instance Cloud Data Fusion
Lorsque vous utilisez Cloud Data Fusion, vous utilisez à la fois la console Google Cloud et l'UI distincte de Cloud Data Fusion. Dans la console Google Cloud , vous pouvez créer un projet Google Cloud , et créer et supprimer des instances Cloud Data Fusion. Dans l'interface utilisateur Cloud Data Fusion, vous pouvez utiliser les différentes pages, telles que Studio ou Wrangler, pour utiliser les fonctionnalités de Cloud Data Fusion.
Dans la console Google Cloud , accédez à la page Cloud Data Fusion.
Pour ouvrir l'instance dans Cloud Data Fusion Studio, cliquez sur Instances, puis sur Afficher l'instance.
Stocker votre mot de passe SQL Server en tant que clé sécurisée
Ajoutez votre mot de passe SQL Server en tant que clé sécurisée à chiffrer sur votre instance Cloud Data Fusion. Plus loin dans ce guide, vous veillerez à ce que votre mot de passe soit récupéré à l'aide de Cloud KMS.
En haut à droite de n'importe quelle page Cloud Data Fusion, cliquez sur Administrateur système.
Cliquez sur l'onglet Configuration.
Cliquez sur Envoyer des appels HTTP.

Dans le menu déroulant, sélectionnez PUT.
Dans le champ "Chemin d'accès", saisissez
namespaces/NAMESPACE_ID/securekeys/PASSWORD.Dans le champ Corps, saisissez
{"data":"SQL_SERVER_PASSWORD"}.Cliquez sur Envoyer.
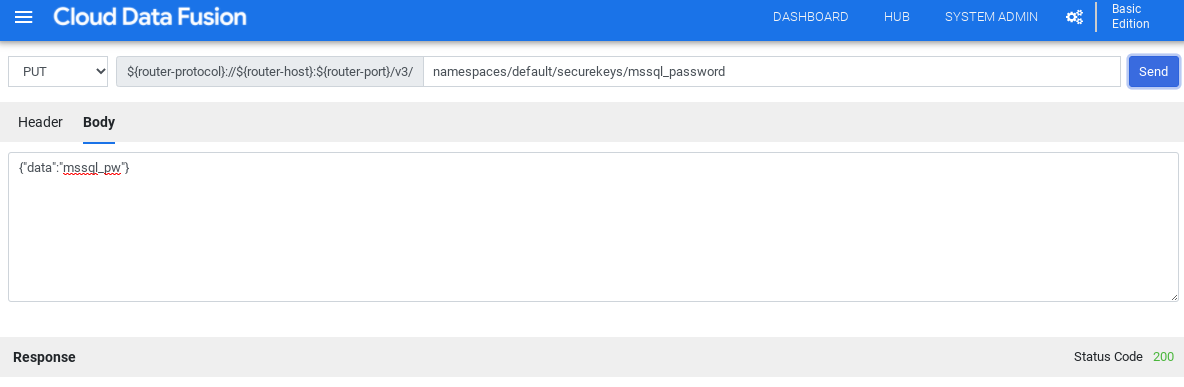
Assurez-vous que la Réponse que vous recevez correspond au code d'état 200.
Obtenir le pilote JDBC pour SQL Server
Utiliser le hub
Dans l'interface utilisateur de Cloud Data Fusion, cliquez sur Hub.
Dans la barre de recherche, saisissez
Microsoft SQL Server JDBC Driver.Cliquez sur Pilote JDBC Microsoft SQL Server.
Cliquez sur Download (Télécharger). Suivez la procédure de téléchargement affichée.
Cliquez sur Déployer. Importez le fichier JAR de l'étape précédente.
Cliquez sur Terminer.
Utiliser Studio
Accédez au site Microsoft.com.
Choisissez votre téléchargement, puis cliquez sur Télécharger.
Dans l'UI de Cloud Data Fusion, cliquez sur Menu, puis accédez à la page Studio.
Cliquez sur Ajouter.
Sous Pilote, cliquez sur Importer.
Importez le fichier JAR téléchargé à l'étape 2.
Cliquez sur Suivant.
Configurez le pilote en saisissant un nom.
Dans le champ Nom de la classe, saisissez
com.microsoft.sqlserver.jdbc.SQLServerDriver.Cliquez sur Terminer.
Déployer les plug-ins multi-tables
Dans l'interface utilisateur Web de Cloud Data Fusion, cliquez sur Hub.
Dans la barre de recherche, saisissez
Multiple table plugins.Cliquez sur Plug-ins multi-tables.
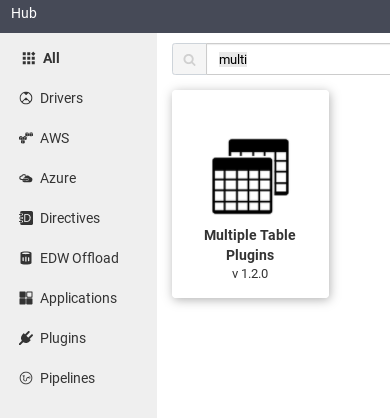
Cliquez sur Déployer.
Cliquez sur Terminer.
Cliquez sur Créer un pipeline.
Se connecter à SQL Server
Dans l'UI de Cloud Data Fusion, cliquez sur Menu, puis accédez à la page Studio.
Dans Studio, développez le menu Source.
Cliquez sur Multiple Database Tables (Tables à plusieurs bases de données).
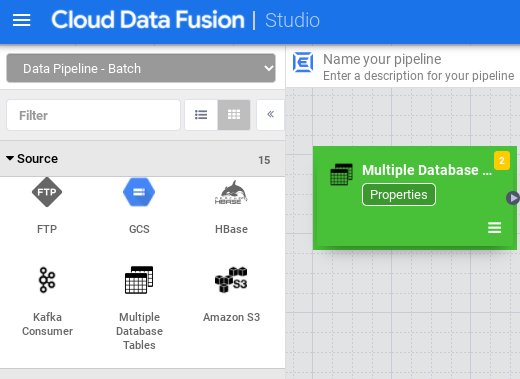
Placez le pointeur sur le nœud Multiple Database Tables (Tables à plusieurs bases de données), puis cliquez sur Properties (Propriétés).
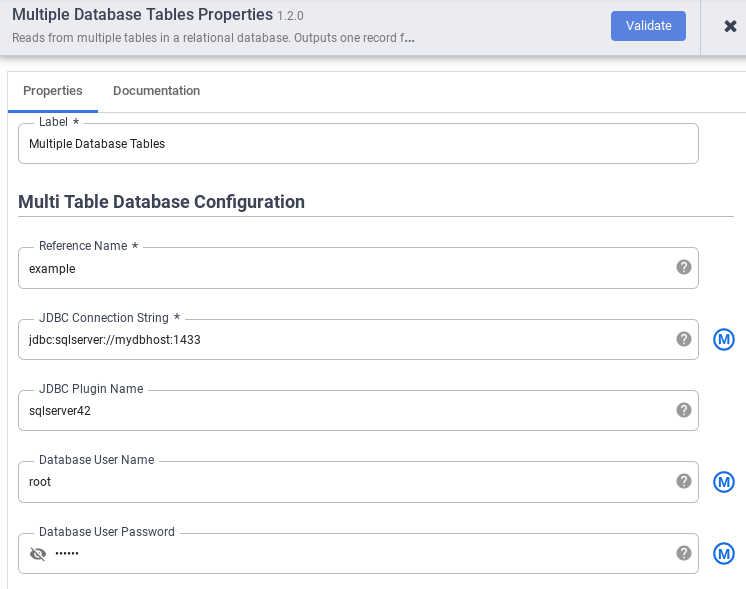
Dans le champ Nom de référence, spécifiez un nom de référence qui servira à identifier votre source SQL Server.
Dans le champ JDBC Connection String (Chaîne de connexion JDBC), saisissez la chaîne de connexion JDBC. Exemple :
jdbc:sqlserver://mydbhost:1433. Pour en savoir plus, consultez Créer l'URL de connexion.Saisissez le nom du plug-in JDBC, le nom d'utilisateur de la base de données et le mot de passe de l'utilisateur de la base de données.
Cliquez sur Valider.
Cliquez sur Fermer.
Se connecter à BigQuery ou Cloud Storage
Dans l'UI de Cloud Data Fusion, cliquez sur Menu, puis accédez à la page Studio.
Développez Sink.
Cliquez sur BigQuery multi-tables ou GCS multi-fichiers.
Connectez le nœud Multiple Database Tables (Tables de base de données multiples) à BigQuery Multi Table (BigQuery multi-tables) ou GCS Multi File (GCS multi-fichiers).
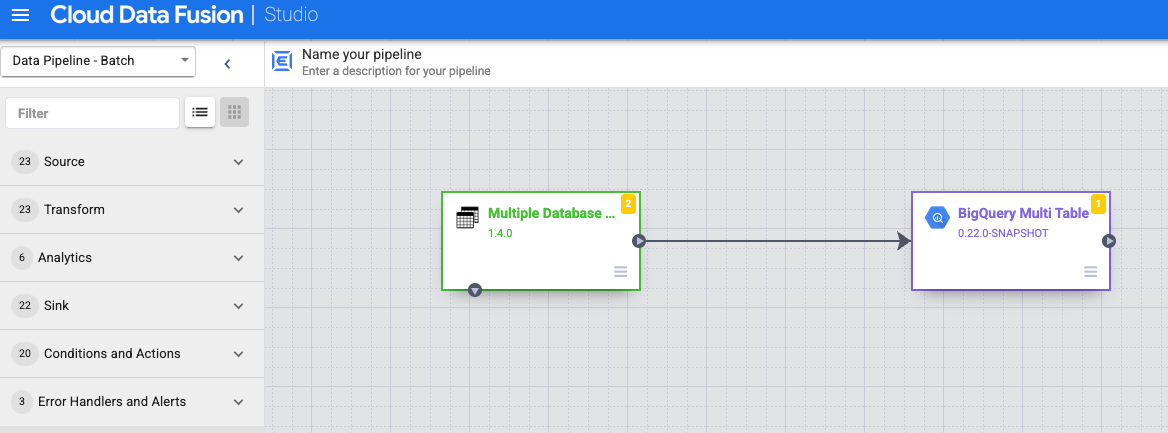
Maintenez le pointeur sur le nœud BigQuery multi-tables ou GCS multi-fichiers, cliquez sur Propriétés, puis configurez le récepteur.
Pour en savoir plus, consultez Récepteur Google BigQuery multi-tables et Récepteur Google Cloud Storage multi-fichiers.
Cliquez sur Valider.
Cliquez sur Fermer.
Exécuter un aperçu du pipeline
Dans l'UI de Cloud Data Fusion, cliquez sur Menu, puis accédez à la page Studio.
Cliquez sur Aperçu.
Cliquez sur Exécuter. Attendez que l'aperçu se termine correctement.
Déployer le pipeline
Dans l'UI de Cloud Data Fusion, cliquez sur Menu, puis accédez à la page Studio.
Cliquez sur Déployer.
Exécuter le pipeline
Dans l'interface utilisateur de Cloud Data Fusion, cliquez sur Menu.
Cliquez sur Liste.
Cliquez sur le pipeline.
Sur la page d'informations du pipeline, cliquez sur Exécuter.
Étapes suivantes
- Apprenez-en plus sur Cloud Data Fusion.
- Suivez l'un des tutoriels.