
Cette page explique comment attribuer le rôle Utilisateur du compte de service sur le compte de service Dataproc à l'agent de service Cloud Data Fusion pour lui permettre de provisionner et d'exécuter des pipelines sur des clusters Dataproc.
Pour les comptes de service utilisés par Dataproc, vous devez également accorder l'autorisation datafusion.instances.runtime pour accéder aux ressources d'exécution Cloud Data Fusion.
Que vous utilisiez un compte de service géré par l'utilisateur ou le compte de service Compute Engine par défaut sur les machines virtuelles d'un cluster, vous devez attribuer le rôle "Utilisateur du compte de service" à Cloud Data Fusion. Sinon, Cloud Data Fusion ne peut pas provisionner un cluster Dataproc et l'erreur suivante s'affiche lorsque vous exécutez un pipeline de données :
PROVISION task failed in REQUESTING_CREATE state for program run [pipeline-name] due to Dataproc operation failure: INVALID_ARGUMENT: User not authorized to act as service account '[service-account-name]'
Obtenir le nom du compte de service
- Dans la console Google Cloud , accédez à la page "Identity and Access Management".
Accéder à la page IAM - Dans le sélecteur de projet en haut de la page, sélectionnez le projet, le dossier ou l'organisation auxquels appartient l'instance Cloud Data Fusion.
- Recherchez et copiez le nom du compte de service Cloud Data Fusion. Utilisez le format suivant :
service-[project-number]@gcp-sa-datafusion.iam.gserviceaccount.com.
Accorder l'autorisation Utilisateur du compte de service
- Dans la console Google Cloud , accédez à la page Comptes de service.
Accéder à la page Comptes de service - Cliquez sur Sélectionner un projet, choisissez un projet dans lequel se trouve le compte de service que vous souhaitez utiliser pour le cluster Dataproc, puis cliquez sur Ouvrir.
Cliquez sur l'adresse e-mail du compte de service Dataproc.
Cliquez sur l'onglet Comptes principaux avec accès. La page affiche la liste des comptes principaux auxquels des rôles ont été attribués sur le compte de service.
Cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, collez le nom du compte de service Cloud Data Fusion que vous avez copié précédemment.
Sélectionnez le rôle Utilisateur de compte de service.
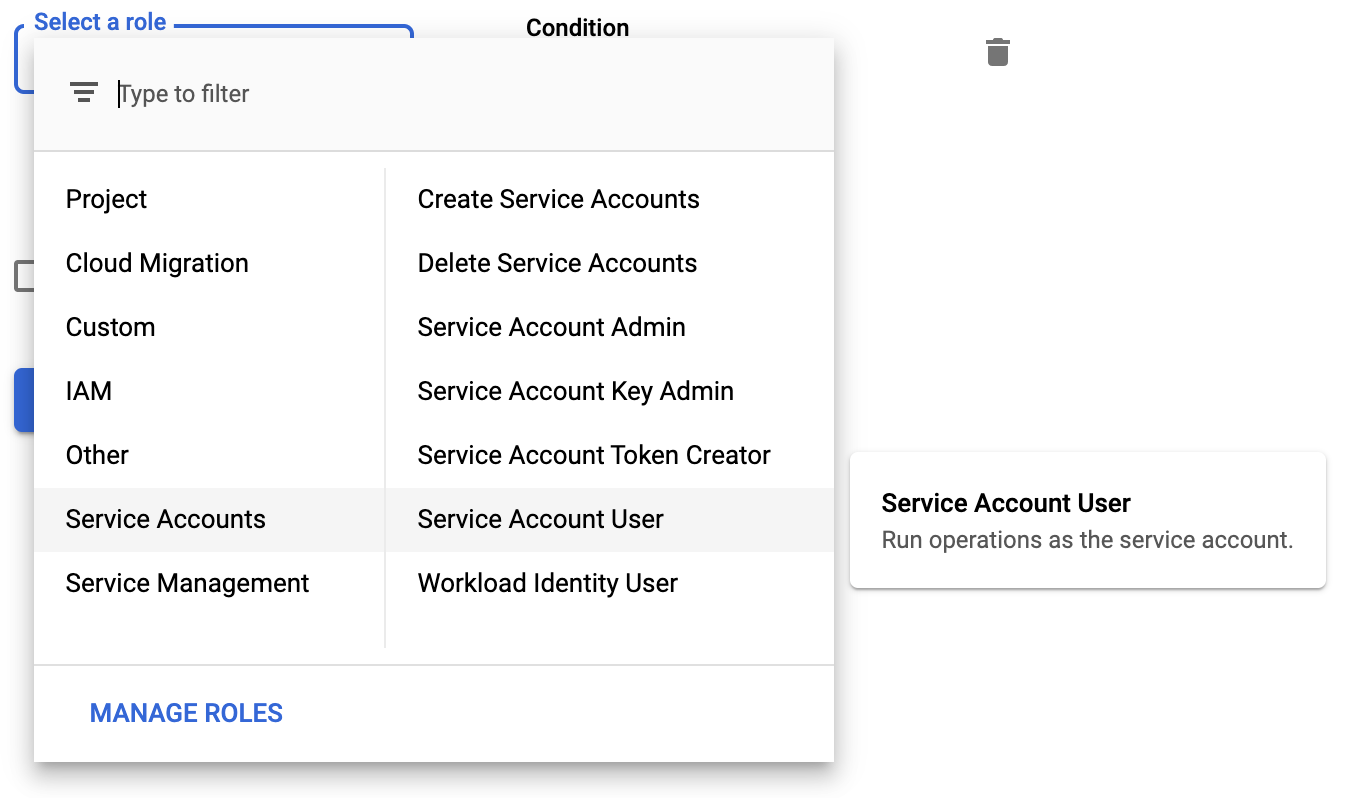
Cliquez sur Enregistrer.
Attribuer des rôles aux comptes de service Dataproc
Accorder l'autorisation de rôle "Exécutant"
Accordez le rôle d'exécuteur Cloud Data Fusion (roles/datafusion.runner) aux comptes de service utilisés par Dataproc. Cela autorise le compte de service Dataproc à exécuter des pipelines Cloud Data Fusion dans votre projet.
Pour en savoir plus, consultez Exiger l'autorisation de rattacher des comptes de service aux ressources.
Accorder l'autorisation d'administrateur Cloud Storage
Dans Cloud Data Fusion version 6.2.0 et ultérieure, accordez le rôle Administrateur Cloud Storage (roles/storage.admin) aux comptes de service utilisés par Dataproc dans votre projet.
Étapes suivantes
- En savoir plus sur le contrôle des accès dans Cloud Data Fusion
- En savoir plus sur les comptes de service Cloud Data Fusion