
Halaman ini menjelaskan cara mengubah versi image Managed Service untuk Apache Spark yang digunakan oleh instance Cloud Data Fusion Anda. Anda dapat mengubah image di tingkat instance, namespace, atau pipeline.
Sebelum memulai
Hentikan semua pipeline real-time dan tugas replikasi di instance Cloud Data Fusion. Jika pipeline real-time atau replikasi berjalan saat Anda mengubah versi image Managed Service untuk Apache Spark, perubahan tersebut tidak akan diterapkan ke eksekusi pipeline.
Untuk pipeline real-time, jika checkpointing diaktifkan, menghentikan pipeline tidak akan menyebabkan kehilangan data. Untuk tugas replikasi, selama log database tersedia, menghentikan dan memulai tugas replikasi tidak akan menyebabkan kehilangan data.
Konsol
Buka halaman Instances Cloud Data Fusion dan buka instance tempat Anda perlu menghentikan pipeline.
Buka setiap pipeline real-time di Pipeline Studio, lalu klik Stop.
Buka setiap tugas replikasi di halaman Replicate , lalu klik Stop.
REST API
Untuk mengambil semua pipeline, gunakan panggilan REST API berikut:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps"Ganti
NAMESPACE_IDdengan nama namespace Anda.Untuk menghentikan pipeline real-time, gunakan panggilan REST API berikut:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/PIPELINE_NAME/spark/DataStreamsSparkStreaming/stop"Ganti NAMESPACE_ID dengan nama namespace Anda dan PIPELINE_NAME dengan nama pipeline real-time.
Untuk menghentikan tugas replikasi, gunakan panggilan REST API berikut:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/REPLICATION_JOB_NAME/workers/DeltaWorker/stop"Ganti NAMESPACE_ID dengan nama Namespace Anda dan REPLICATION_JOB_NAME dengan nama tugas replikasi.
Untuk mengetahui informasi selengkapnya, lihat menghentikan pipeline real-time dan menghentikan tugas replikasi.
Memeriksa dan mengganti versi default Managed Service untuk Apache Spark di Cloud Data Fusion
Klik System Admin > Configuration > System Preferences.
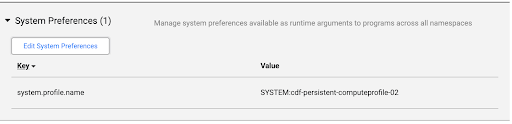
Jika image Managed Service untuk Apache Spark tidak ditentukan di System Preferences, atau untuk mengubah preferensi, klik Edit System Preferences.
Masukkan teks berikut di kolom Key:
system.profile.properties.imageVersionMasukkan image Managed Service untuk Apache Spark yang dipilih di Value field, seperti
2.1.Klik Save &Close.
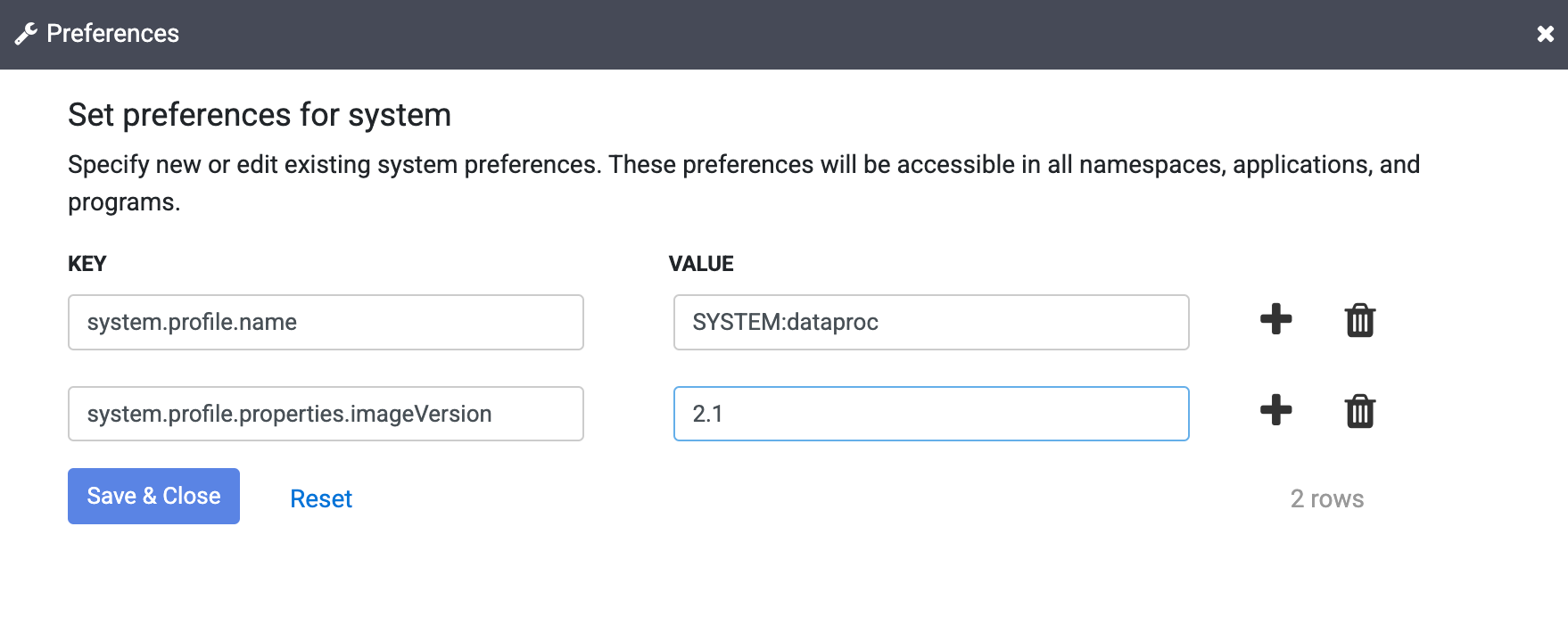
Perubahan ini memengaruhi seluruh instance Cloud Data Fusion, termasuk semua Namespace dan proses pipeline-nya, kecuali jika properti versi image diganti di Namespace, pipeline, atau Argumen Runtime di instance Anda.
Mengubah versi image Managed Service untuk Apache Spark
Versi image dapat ditetapkan di antarmuka web Cloud Data Fusion di Konfigurasi Compute, Preferensi Namespace, atau Argumen Runtime Pipeline.
Mengubah image di Preferensi Namespace
Jika Anda telah mengganti versi image di properti Namespace, ikuti langkah-langkah berikut:
Klik System Admin > Configuration > Namespaces.
Buka setiap namespace, lalu klik Preferences.
Pastikan tidak ada penggantian dengan kunci
system.profile.properties.imageVersiondengan nilai versi image yang salah.Klik Finish.
Mengubah image di Profil Compute Sistem
Klik System Admin > Configuration.
Klik System Compute Profiles > Create New Profile.
Pilih penyedia Managed Service untuk Apache Spark.
Buat profil untuk Managed Service untuk Apache Spark. Di kolom Image Version, masukkan versi image Managed Service untuk Apache Spark.
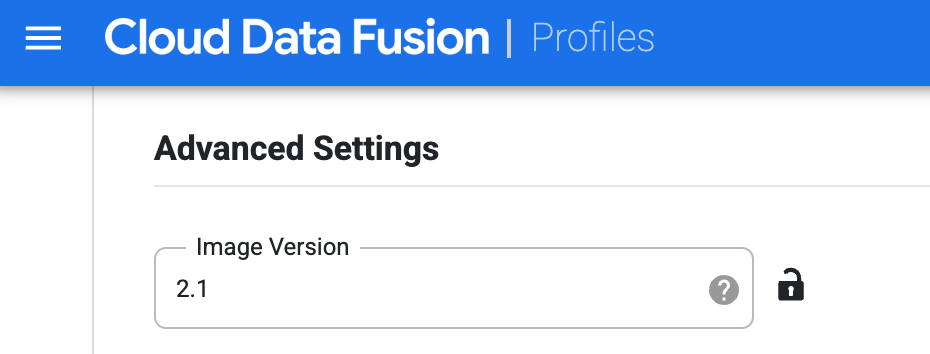
Pilih profil komputasi ini saat menjalankan pipeline di halaman Studio. Di halaman proses pipeline, klik Configure > Compute config , lalu pilih profil ini.
Pilih profil Managed Service untuk Apache Spark, lalu klik Save.
Klik Finish.
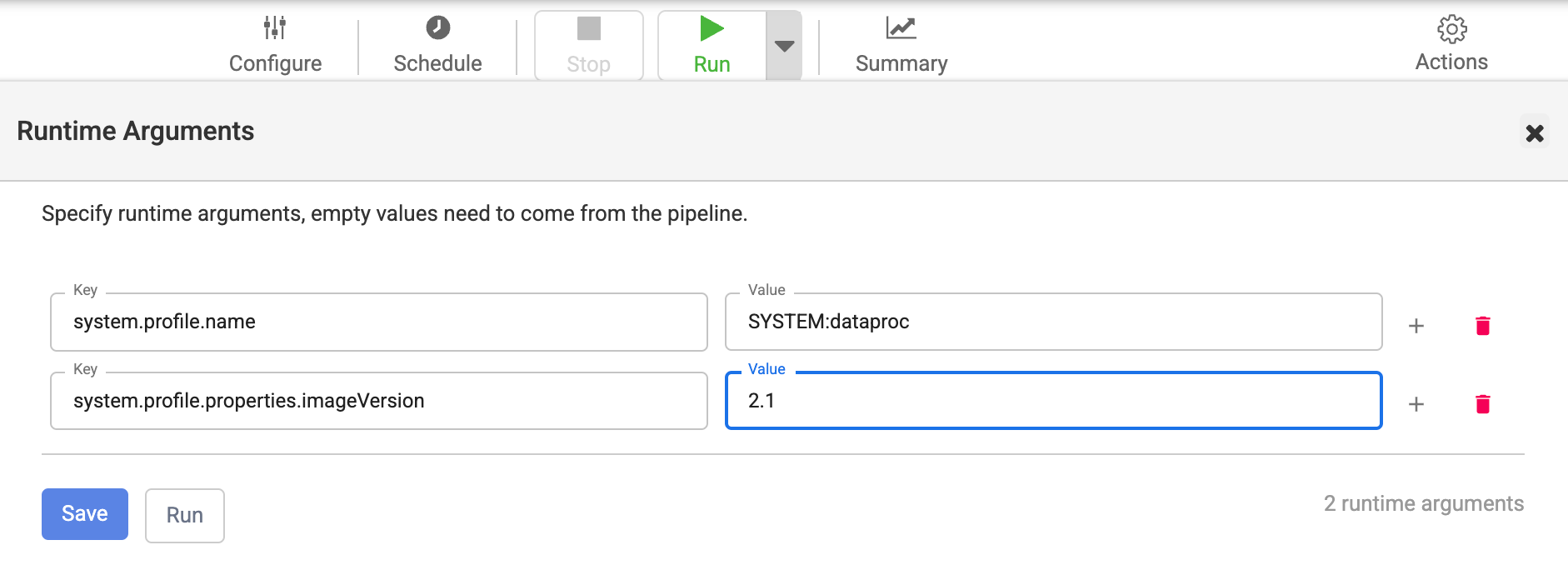
Mengubah image di Argumen Runtime Pipeline
Jika Anda telah mengganti versi image dengan properti di Argumen Runtime pipeline, ikuti langkah-langkah berikut:
Klik menu Menu > List.
Di halaman List, pilih pipeline yang ingin Anda perbarui.
Pipeline akan terbuka di halaman Studio.
Untuk meluaskan opsi Run, klik panah peluas.
Jendela Runtime Arguments akan terbuka.
Pastikan tidak ada penggantian dengan kunci
system.profile.properties.imageVersiondengan versi image yang salah sebagai nilainya.Klik Save.
Membuat ulang cluster Managed Service untuk Apache Spark statis yang digunakan oleh Cloud Data Fusion dengan versi image yang dipilih
Jika Anda menggunakan cluster Managed Service untuk Apache Spark yang ada dengan Cloud Data Fusion, ikuti panduan Managed Service untuk Apache Spark untuk membuat ulang cluster dengan versi image Managed Service untuk Apache Spark yang dipilih untuk versi Cloud Data Fusion Anda.
Atau, Anda dapat membuat cluster Managed Service untuk Apache Spark baru dengan versi image Managed Service untuk Apache Spark yang dipilih, lalu menghapus dan membuat ulang profil komputasi di Cloud Data Fusion dengan nama profil komputasi yang sama dan nama cluster Managed Service untuk Apache Spark yang diperbarui. Dengan cara ini, pipeline batch yang berjalan dapat menyelesaikan eksekusi di cluster yang ada dan proses pipeline berikutnya akan berjalan di cluster Managed Service untuk Apache Spark yang baru. Anda dapat menghapus cluster Managed Service untuk Apache Spark lama setelah mengonfirmasi bahwa semua proses pipeline telah selesai.
Memeriksa apakah versi image Managed Service untuk Apache Spark telah diperbarui
Konsol
Di Google Cloud konsol, buka halaman Clusters Managed Service untuk Apache Spark.
Buka halaman Cluster details untuk cluster baru yang dibuat Cloud Data Fusion saat Anda menentukan versi baru.
Kolom Image version memiliki nilai baru yang Anda tentukan di Cloud Data Fusion.
REST API
Dapatkan daftar cluster dengan metadatanya:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION_ID/clustersGanti kode berikut:
PROJECT_IDdengan nama namespace AndaREGION_IDdengan nama region tempat cluster Anda berada
Cari nama pipeline Anda (nama cluster).
Di bagian objek JSON tersebut, lihat image di
config > softwareConfig > imageVersion.
Mengubah image Managed Service untuk Apache Spark ke versi 2.1 atau yang lebih baru
Cloud Data Fusion versi 6.9.1 dan yang lebih baru mendukung image Managed Service untuk Apache Spark 2.1 Compute Engine, yang berjalan di Java 11. Di versi 6.10.0 dan yang lebih baru, image 2.1 adalah default.
Jika Anda beralih ke image 2.1 atau yang lebih baru, dari image sebelumnya, agar pipeline batch dan tugas replikasi berhasil, driver JDBC yang digunakan plugin database di instance tersebut harus kompatibel dengan Java 11.
Image Managed Service untuk Apache Spark 2.2 dan 2.1 memiliki batasan berikut di Cloud Data Fusion:
- Tugas map reduce tidak didukung.
- Versi driver JDBC yang digunakan dalam plugin database di instance Anda harus diperbarui agar memiliki dukungan untuk Java 11. Lihat tabel berikut untuk mengetahui versi driver yang berfungsi dengan Managed Service untuk Apache Spark 2.2, 2.1, dan Java 11:
| Driver JDBC | Versi sebelumnya dihapus dari Cloud Data Fusion 6.9.1 | Versi yang didukung Java 8 dan Java 11 yang berfungsi dengan Managed Service untuk Apache Spark 2.2, 2.1, atau 2.0 |
|---|---|---|
| Driver JDBC Cloud SQL untuk MySQL | - | 1.0.16 |
| Driver JDBC Cloud SQL untuk PostgreSQL | - | 1.0.16 |
| Driver JDBC Microsoft SQL Server | Driver Microsoft JDBC 6.0 | Driver Microsoft JDBC 9.4 |
| Driver JDBC MySQL | 5.0.8, 5.1.39 | 8.0.25 |
| Driver JDBC PostgreSQL | 9.4.1211.jre7, 9.4.1211.jre8 | 42.6.0.jre8 |
| Driver JDBC Oracle | ojdbc7 | ojdbc8 (12c dan yang lebih baru) |
Penggunaan memori saat menggunakan Managed Service untuk Apache Spark 2.1 atau yang lebih baru
Penggunaan memori mungkin meningkat untuk pipeline yang menggunakan Managed Service untuk Apache Spark 2.1 atau yang lebih baru. Jika Anda mengupgrade instance ke versi 6.10 atau yang lebih baru, dan pipeline sebelumnya gagal karena masalah memori, tingkatkan memori driver dan eksekutor menjadi 2048 MB dalam konfigurasi Resources untuk pipeline.
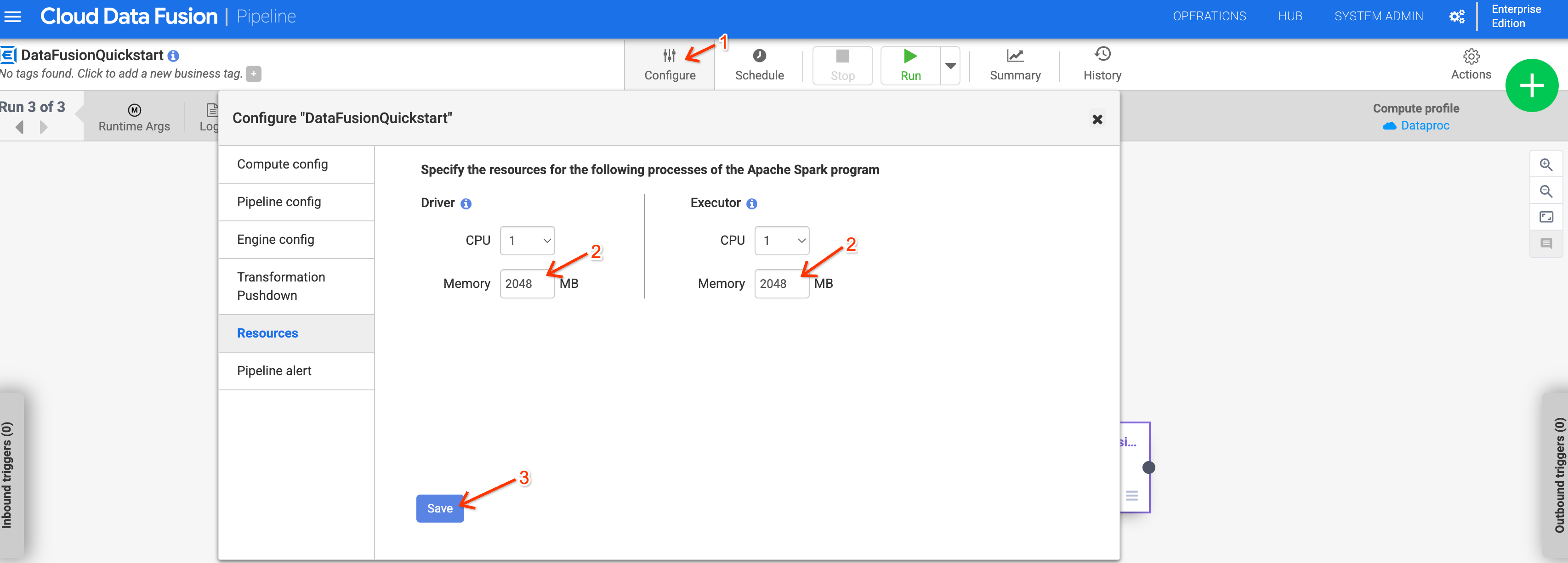
Atau, Anda dapat mengganti versi Managed Service untuk Apache Spark dengan menetapkan argumen runtime system.profile.properties.imageVersion ke 2.0-debian10.