כדי לשפר את הביצועים בצינורות עיבוד הנתונים, אפשר להעביר חלק מפעולות הטרנספורמציה אל BigQuery במקום אל Apache Spark. המונח 'העברת טרנספורמציה' מתייחס להגדרה שמאפשרת להעביר פעולה בצינור נתונים של Cloud Data Fusion ל-BigQuery כמנוע ביצוע. כתוצאה מכך, הפעולה והנתונים שלה מועברים ל-BigQuery והפעולה מתבצעת שם.
התכונה Transformation Pushdown משפרת את הביצועים של צינורות נתונים שיש בהם כמה JOINפעולות מורכבות או טרנספורמציות נתמכות אחרות. יכול להיות שביצוע טרנספורמציות מסוימות ב-BigQuery יהיה מהיר יותר מאשר ביצוע שלהן ב-Spark.
טרנספורמציות שלא נתמכות וכל הטרנספורמציות של התצוגה המקדימה מבוצעות ב-Spark.
טרנספורמציות נתמכות
התכונה Transformation Pushdown זמינה ב-Cloud Data Fusion מגרסה 6.5.0 ואילך, אבל חלק מהטרנספורמציות הבאות נתמכות רק בגרסאות מאוחרות יותר.
JOIN operations
התכונה Transformation Pushdown זמינה לפעולות
JOINב-Cloud Data Fusion בגרסה 6.5.0 ואילך.יש תמיכה בפעולות בסיסיות (במקלדת) ובפעולות מתקדמות של
JOIN.לצמתי Join צריכים להיות בדיוק שני שלבי קלט כדי שהביצוע יתבצע ב-BigQuery.
הצטרפויות שמוגדרות לטעינת קלט אחד או יותר לזיכרון מבוצעות ב-Spark במקום ב-BigQuery, למעט במקרים הבאים:
- אם חלק מהקלט של פעולת ה-join כבר הועבר למטה.
- אם הגדרתם את הפעולה לביצוע במנוע SQL (ראו את האפשרות Stages to force execution).
יעד ב-BigQuery
התכונה 'העברת טרנספורמציה' זמינה ב-BigQuery Sink ב-Cloud Data Fusion בגרסה 6.7.0 ואילך.
אם רכיב BigQuery Sink מופיע אחרי שלב שהופעל ב-BigQuery, הפעולה שכותבת רשומות ל-BigQuery מתבצעת ישירות ב-BigQuery.
כדי לשפר את הביצועים באמצעות יעד הנתונים הזה, אתם צריכים:
- לחשבון השירות צריכה להיות הרשאה ליצור ולעדכן טבלאות במערך הנתונים שמשמש את BigQuery Sink.
- מערכי הנתונים שמשמשים ל-Transformation Pushdown ול-BigQuery Sink צריכים להיות מאוחסנים באותו מיקום.
- הפעולה חייבת להיות אחת מהפעולות הבאות:
-
Insert(האפשרותTruncate Tableלא נתמכת) UpdateUpsert
-
GROUP BY צבירות
התכונה 'העברת טרנספורמציה למטה' זמינה לצבירות GROUP BY ב-Cloud Data Fusion בגרסה 6.7.0 ואילך.
GROUP BY צבירות ב-BigQuery זמינות לפעולות הבאות:
Avg-
Collect List(ערכי null מוסרים ממערך הפלט) -
Collect Set(ערכי null מוסרים ממערך הפלט) ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
מערכות GROUP BY מבצעות צבירות ב-BigQuery במקרים הבאים:
- הוא מופיע אחרי שלב שכבר הועבר למטה.
- הגדרתם שהיא תופעל ב-SQL Engine (ראו את האפשרות Stages to force execution).
ביטול כפילויות בצבירות
התכונה Transformation Pushdown זמינה לצבירות של ביטול כפילויות ב-Cloud Data Fusion בגרסה 6.7.0 ואילך עבור הפעולות הבאות:
- לא צוינה פעולת סינון
-
ANY(ערך שאינו null בשדה הרצוי) -
MIN(הערך המינימלי בשדה שצוין) -
MAX(הערך המקסימלי בשדה שצוין)
אין תמיכה בפעולות הבאות:
FIRSTLAST
ביטול כפילויות של צבירות מתבצע במנוע ה-SQL במקרים הבאים:
- הוא מופיע אחרי שלב שכבר הועבר למטה.
- הגדרתם שהשאילתה תופעל במנוע SQL (ראו את האפשרות Stages to force execution).
העברת פעולות למקור ב-BigQuery
התכונה BigQuery Source Pushdown זמינה ב-Cloud Data Fusion בגרסה 6.8.0 ואילך.
אם מקור BigQuery מופיע אחרי שלב שתואם להעברת נתונים ל-BigQuery, הצינור יכול להריץ את כל השלבים התואמים ב-BigQuery.
Cloud Data Fusion מעתיק את הרשומות שנדרשות להפעלת צינור הנתונים ב-BigQuery.
כשמשתמשים ב-BigQuery Source Pushdown, מאפייני חלוקת הטבלה למחיצות וקיבוץ הנתונים נשמרים, כך שאפשר להשתמש במאפיינים האלה כדי לבצע אופטימיזציה לפעולות נוספות, כמו הצטרפות.
דרישות נוספות
כדי להשתמש ב-BigQuery Source Pushdown, צריך לעמוד בדרישות הבאות:
לחשבון השירות שהוגדר ל-BigQuery Transformation Pushdown צריכות להיות הרשאות קריאה של טבלאות במערך הנתונים של BigQuery Source.
מערכי הנתונים שמשמשים במקור BigQuery ומערך הנתונים שהוגדר להעברת נתונים לצורך טרנספורמציה צריכים להיות מאוחסנים באותו מיקום.
צבירת נתונים בחלון
התכונה Transformation Pushdown זמינה עבור צבירות של חלונות ב-Cloud Data Fusion בגרסה 6.9 ואילך. צבירות של חלונות ב-BigQuery נתמכות בפעולות הבאות:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
צבירות של חלונות מבוצעות ב-BigQuery במקרים הבאים:
- הוא מופיע אחרי שלב שכבר הועבר למטה.
- הגדרתם שהיא תופעל במנוע SQL (ראו את האפשרות Stages to force pushdown).
Wrangler Filter Pushdown
התכונה Wrangler Filter Pushdown זמינה ב-Cloud Data Fusion בגרסה 6.9 ואילך.
כשמשתמשים בפלאגין Wrangler, אפשר להעביר מסננים, שנקראים Precondition
פעולות, לביצוע ב-BigQuery במקום ב-Spark.
התכונה 'העברת סינון' נתמכת רק במצב SQL של תנאים מוקדמים, שגם הוא הושק בגרסה 6.9. במצב הזה, התוסף מקבל ביטוי של תנאי מוקדם ב-SQL בתקן ANSI.
אם משתמשים במצב SQL לתנאים מוקדמים, הוראות והוראות שהוגדרו על ידי המשתמש מושבתות בתוסף Wrangler, כי הן לא נתמכות עם תנאים מוקדמים במצב SQL.
אין תמיכה במצב SQL לתנאים מוקדמים בתוספים של Wrangler עם כמה קלטים כשהאפשרות Transformation Pushdown מופעלת. אם משתמשים בו עם כמה קלטים, שלב Wrangler הזה עם תנאי סינון SQL מופעל ב-Spark.
מסננים מופעלים ב-BigQuery במקרים הבאים:
- הוא מופיע אחרי שלב שכבר הועבר למטה.
- הגדרתם שהיא תופעל במנוע SQL (ראו את האפשרות Stages to force pushdown).
מדדים
מידע נוסף על המדדים ש-Cloud Data Fusion מספק לגבי החלק בצינור שמופעל ב-BigQuery זמין במאמר מדדים של צינורות להעברת נתונים ב-BigQuery.
מתי כדאי להשתמש ב-Transformation Pushdown
ביצוע טרנספורמציות ב-BigQuery כולל את הפעולות הבאות:
- כתיבת רשומות ל-BigQuery בשלבים נתמכים בצינור העיבוד.
- ביצוע שלבים נתמכים ב-BigQuery.
- קריאת רשומות מ-BigQuery אחרי הפעלת ההמרות הנתמכות, אלא אם הן מופיעות אחרי BigQuery Sink.
בהתאם לגודל של מערכי הנתונים, יכול להיות שיהיה עומס רשת משמעותי, שיכול להשפיע לרעה על משך הביצוע הכולל של צינור עיבוד הנתונים כשמופעלת האפשרות 'העברת טרנספורמציות למטה'.
בגלל התקורה של הרשת, מומלץ להשתמש ב-Transformation Pushdown במקרים הבאים:
- כמה פעולות נתמכות מבוצעות ברצף (ללא שלבים בין השלבים).
- השיפורים בביצועים כתוצאה מהרצת ההמרות ב-BigQuery, בהשוואה ל-Spark, גדולים יותר מההשהיה של העברת הנתונים אל BigQuery וממנו.
איך זה עובד
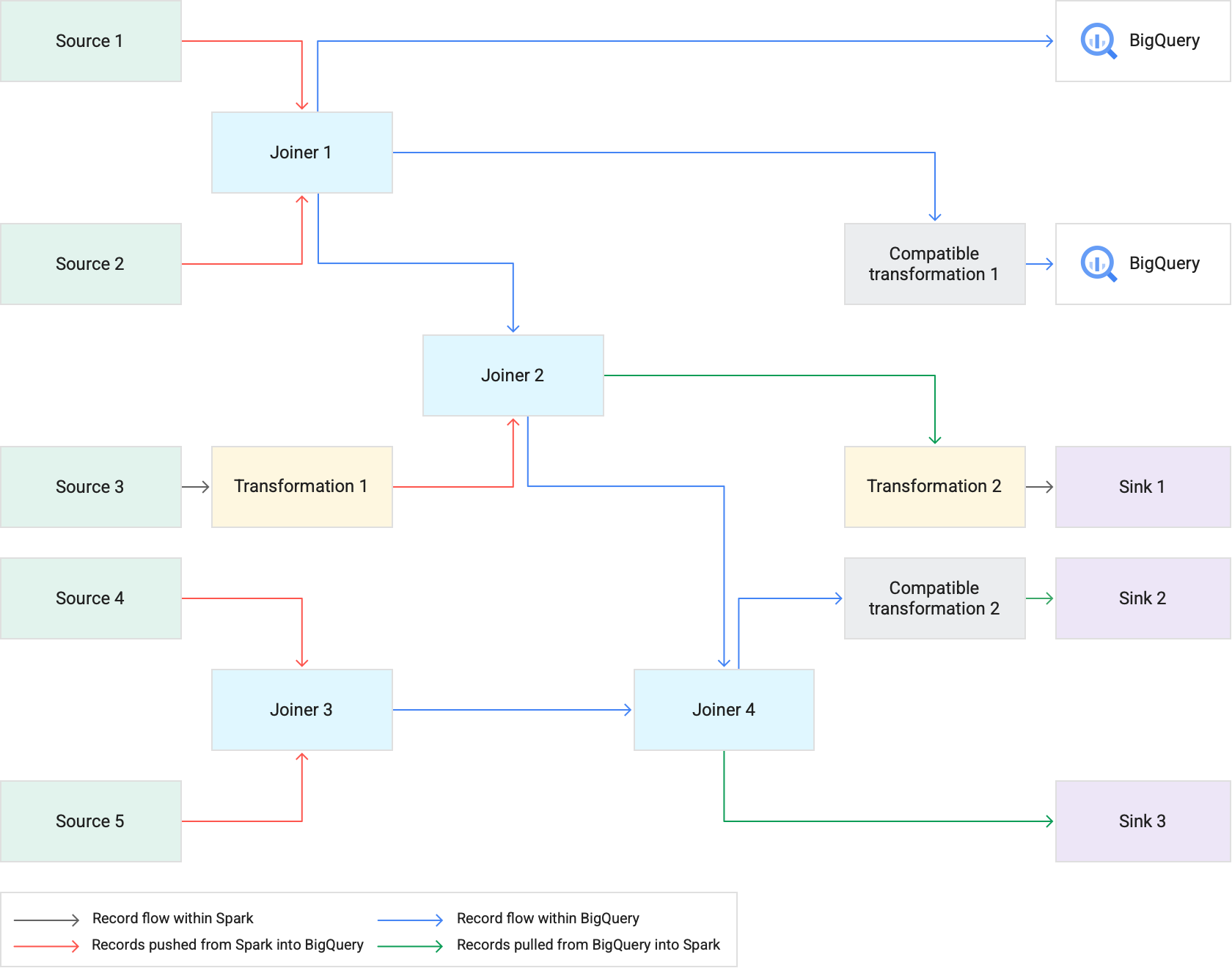
כשמריצים פייפליין שמשתמש ב-Transformation Pushdown, Cloud Data Fusion מבצע שלבי טרנספורמציה נתמכים ב-BigQuery. כל שאר השלבים בצינור העיבוד מבוצעים ב-Spark.
כשמבצעים טרנספורמציות:
Cloud Data Fusion טוען את מערכי הנתונים של הקלט ל-BigQuery על ידי כתיבת רשומות ל-Cloud Storage, ואז מריץ משימת טעינה של BigQuery.
פעולות
JOINוטרנספורמציות נתמכות מבוצעות כעבודות של BigQuery באמצעות הצהרות SQL.אם נדרש עיבוד נוסף אחרי הפעלת העבודות, אפשר לייצא רשומות מ-BigQuery ל-Spark. עם זאת, אם האפשרות Attempt direct copy to BigQuery sinks מופעלת ורכיב BigQuery Sink מופיע אחרי שלב שהופעל ב-BigQuery, הרשומות נכתבות ישירות לטבלת היעד של רכיב BigQuery Sink.
בתרשים הבא מוצג אופן הביצוע של טרנספורמציות נתמכות ב-BigQuery במקום ב-Spark באמצעות Transformation Pushdown.
שיטות מומלצות
שינוי הגודל של האשכולות והמבצעים
כדי לבצע אופטימיזציה של ניהול המשאבים בצינור, צריך:
שימוש במספר הנכון של עובדי אשכול (צמתים) לעומס עבודה. במילים אחרות, תוכלו להפיק את המרב מאשכול Managed Service for Apache Spark שהוקצה לכם על ידי שימוש מלא במעבד ובזיכרון שזמינים למופע שלכם, וגם ליהנות ממהירות הביצוע של BigQuery למשימות גדולות.
כדי לשפר את ההרצה המקבילית בצינורות שלכם, כדאי להשתמש באשכולות עם שינוי גודל אוטומטי.
משנים את הגדרות המשאבים בשלבים של צינור עיבוד הנתונים שבהם הרשומות נדחפות או נמשכות מ-BigQuery במהלך ההפעלה של צינור עיבוד הנתונים.
מומלץ: כדאי להתנסות בהגדלת מספר הליבות של המעבד (CPU) עבור משאבי ההפעלה (עד למספר הליבות של המעבד שמשמש את צומת העובד). ה-executors מבצעים אופטימיזציה של השימוש במעבד במהלך שלבי הסריאליזציה והדה-סריאליזציה, כשהנתונים נכנסים ל-BigQuery ויוצאים ממנו. מידע נוסף זמין במאמר בנושא הגדרת גודל האשכול.
יתרון בהרצת טרנספורמציות ב-BigQuery הוא שאפשר להריץ את צינורות הנתונים באשכולות קטנים יותר של Managed Service for Apache Spark. אם פעולות ה-join הן הפעולות הכי עתירות משאבים בצינור, אפשר להתנסות בגדלים קטנים יותר של אשכולות, כי פעולות ה-JOIN הכבדות מתבצעות עכשיו ב-BigQuery, וכך אפשר להפחית את עלויות החישוב הכוללות.
שליפת נתונים מהירה יותר באמצעות BigQuery Storage Read API
אחרי ש-BigQuery מבצע את ההמרות, יכול להיות שיהיו עוד שלבים בצינור להרצה ב-Spark. ב-Cloud Data Fusion בגרסה 6.7.0 ואילך, התכונה Transformation Pushdown תומכת ב-BigQuery Storage Read API, שמשפרת את זמן האחזור ומאפשרת פעולות קריאה מהירות יותר ל-Spark. היא יכולה לקצר את זמן הביצוע הכולל של צינור הנתונים.
ה-API קורא רשומות במקביל, ולכן מומלץ להתאים את גודל ה-executor בהתאם. אם פעולות שדורשות הרבה משאבים מבוצעות ב-BigQuery, כדאי להקטין את הקצאת הזיכרון ל-executors כדי לשפר את המקביליות כשצינור הנתונים פועל (ראו התאמה של גודל האשכול וה-executor).
BigQuery Storage Read API מושבת כברירת מחדל. אפשר להפעיל אותו בסביבות הפעלה שבהן מותקנת Scala 2.12 (כולל Managed Service for Apache Spark 2.0 ו-Managed Service for Apache Spark 1.5).
התייחסות לגודל מערך הנתונים
כדאי לשים לב לגודל של מערכי הנתונים בפעולות JOIN. בפעולות JOIN
שיוצרות מספר גדול של רשומות פלט, כמו פעולה שדומה לפעולת JOIN, גודל מערך הנתונים שמתקבל עשוי להיות גדול פי כמה ממערך הנתונים של הקלט. בנוסף, כדאי לקחת בחשבון את התקורה של שליפת הרשומות האלה בחזרה ל-Spark כשמתבצע עיבוד נוסף של Spark לרשומות האלה, כמו טרנספורמציה או יעד, בהקשר של הביצועים הכוללים של צינור הנתונים.
צמצום הטיה בנתונים
פעולות JOIN על נתונים עם הטיה חזקה עלולות לגרום לחריגה של משימת BigQuery ממגבלות השימוש במשאבים, ולגרום לכשל בפעולת JOIN. כדי למנוע את זה, עוברים להגדרות של התוסף Joiner ומזהים את הקלט המוטה בשדה Skewed Input Stage. כך Cloud Data Fusion יכול לסדר את הקלט באופן שמקטין את הסיכון שההצהרה של BigQuery תחרוג מהמגבלות.