
Questa pagina presenta Cloud Data Fusion: Studio, un'interfaccia visiva di tipo fai clic e trascina per creare pipeline di dati da una libreria di plug-in predefiniti e un'interfaccia in cui configurare, eseguire e gestire le pipeline. La creazione di una pipeline in Studio in genere segue questa procedura:
- Connettiti a un'origine dati on-premise o cloud.
- Prepara e trasforma i dati.
- Connettiti alla destinazione.
- Testa la pipeline.
- Esegui la pipeline.
- Pianifica e attiva le pipeline.
Dopo aver progettato ed eseguito la pipeline, puoi gestirla nella pagina Pipeline Studio di Cloud Data Fusion:
- Riutilizza le pipeline parametrizzandole con preferenze e argomenti di runtime.
- Gestisci l'esecuzione della pipeline personalizzando i profili di calcolo, gestendo le risorse e ottimizzando il rendimento della pipeline.
- Gestisci il ciclo di vita della pipeline modificandola.
- Gestisci il controllo del codice sorgente della pipeline utilizzando l'integrazione di Git.
Prima di iniziare
- Attiva l'API Data Fusion.
- Crea un'istanza Cloud Data Fusion.
- Comprendi il controllo dell'accesso in Cloud Data Fusion.
- Comprendi i concetti e i termini chiave di Cloud Data Fusion.
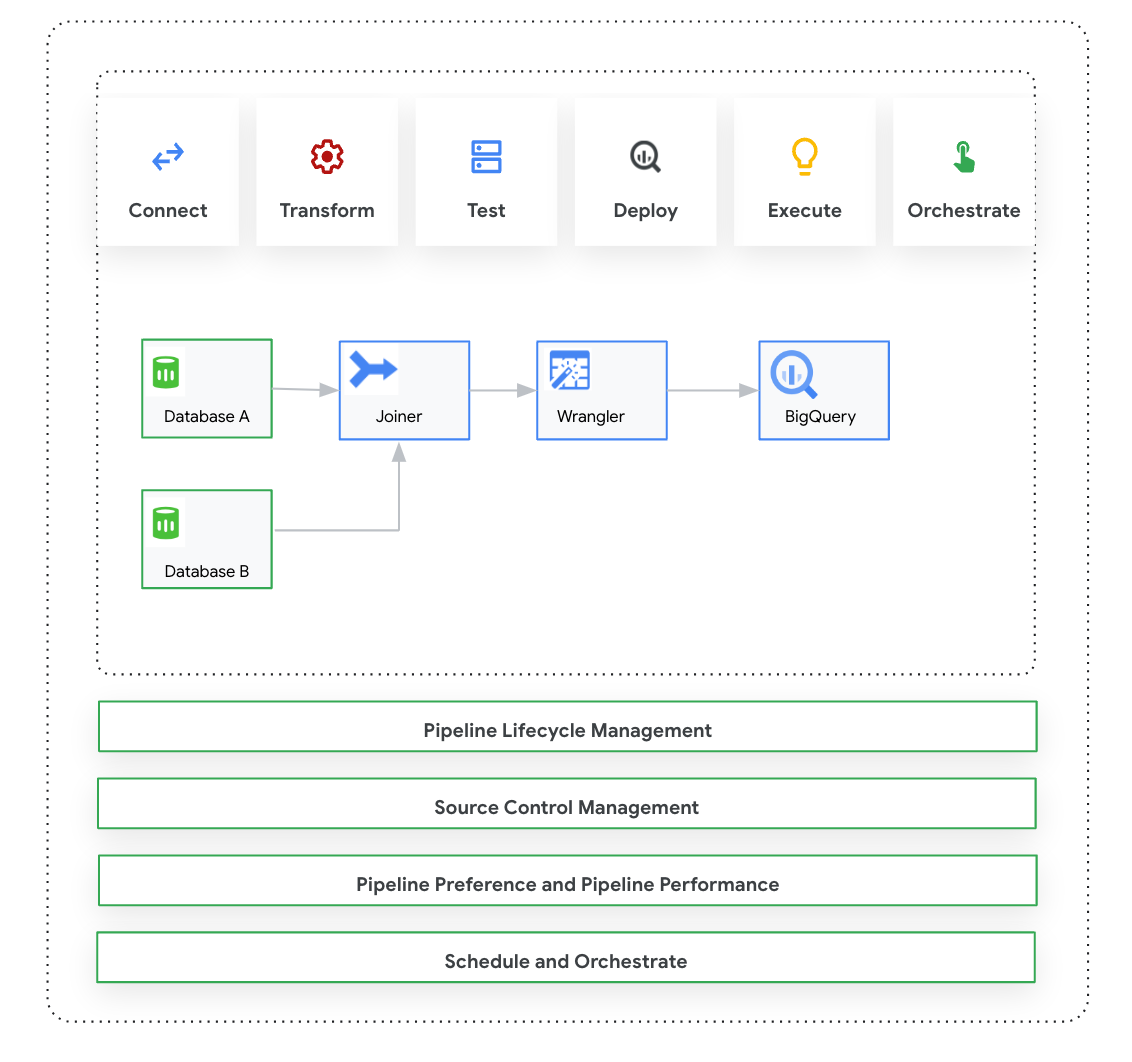
Panoramica di Cloud Data Fusion: Studio
Studio include i seguenti componenti.
Amministrazione
Cloud Data Fusion ti consente di avere più spazi dei nomi in ogni istanza. In Studio, gli amministratori possono gestire centralmente tutti gli spazi dei nomi o ogni spazio dei nomi singolarmente.
Studio fornisce i seguenti controlli amministratore:
- Amministrazione di sistema
- Il modulo Amministratore di sistema in Studio ti consente di creare nuovi spazi dei nomi e definire le configurazioni centrali dei profili di calcolo a livello di sistema, che sono applicabili a ogni spazio dei nomi in quell'istanza. Per saperne di più, consulta Gestire l'amministrazione di Studio.
- Amministrazione dello spazio dei nomi
- Il modulo Amministratore dello spazio dei nomi in Studio ti consente di gestire le configurazioni per lo spazio dei nomi specifico. Per ogni spazio dei nomi, puoi definire profili di calcolo, preferenze di runtime, driver, account di servizio e configurazioni Git. Per saperne di più, consulta Gestire l'amministrazione di Studio.
Pipeline Design Studio
Progetti ed esegui le pipeline in Pipeline Design Studio nell'interfaccia web di Cloud Data Fusion. La progettazione e l'esecuzione di pipeline di dati includono i seguenti passaggi:
- Connettiti a un'origine: Cloud Data Fusion consente le connessioni a origini dati on-premise e cloud. L'interfaccia di Studio include plug-in di sistema predefiniti, preinstallati in Studio. Puoi scaricare plug-in aggiuntivi da un repository di plug-in, noto come Hub. Per saperne di più, consulta la panoramica sui plug-in.
- Preparazione dei dati: Cloud Data Fusion ti consente di preparare i tuoi dati utilizzando il suo potente plug-in di preparazione dei dati: Wrangler. Wrangler ti aiuta a visualizzare, esplorare e trasformare un piccolo campione dei tuoi dati in un unico posto prima di eseguire la logica sull'intero set di dati in Studio. In questo modo, puoi applicare rapidamente le trasformazioni per capire come influiscono sull'intero set di dati. Puoi creare più trasformazioni e aggiungerle a una formula. Per saperne di più, consulta la panoramica di Wrangler.
- Trasforma: i plug-in di trasformazione modificano i dati dopo che sono stati caricati da un' origine. Ad esempio, puoi clonare un record, modificare il formato del file in JSON o utilizzare il plug-in Javascript per creare una trasformazione personalizzata. Per saperne di più, consulta la panoramica sui plug-in.
- Connettiti a una destinazione: dopo aver preparato i dati e applicato le trasformazioni, puoi connetterti alla destinazione in cui prevedi di caricare i dati. Cloud Data Fusion supporta le connessioni a più destinazioni. Per saperne di più, consulta la panoramica sui plug-in.
- Anteprima: dopo aver progettato la pipeline, per eseguire il debug dei problemi prima di eseguire il deployment e l'esecuzione di una pipeline, esegui un job di anteprima. Se riscontri errori, puoi correggerli in modalità Bozza. Studio utilizza le prime 100 righe del set di dati di origine per generare l'anteprima. Studio mostra lo stato e la durata del job di anteprima. Puoi interrompere il job in qualsiasi momento. Puoi anche monitorare gli eventi di log durante l'esecuzione del job di anteprima. Per saperne di più, consulta Visualizzare l'anteprima dei dati.
Gestisci le configurazioni della pipeline: dopo aver visualizzato l'anteprima dei dati, puoi eseguire il deployment della pipeline e gestire le seguenti configurazioni della pipeline:
- Configurazione di calcolo: puoi modificare il profilo di calcolo che esegue la pipeline. Ad esempio, potresti voler eseguire la pipeline su un cluster Managed Service per Apache Spark personalizzato anziché sul cluster Managed Service per Apache Spark predefinito.
- Configurazione della pipeline: per ogni pipeline, puoi attivare o disattivare la strumentazione, ad esempio le metriche di temporizzazione. Per impostazione predefinita, la strumentazione è attivata.
- Configurazione del motore: Spark è il motore di esecuzione predefinito. Puoi passare parametri personalizzati per Spark.
- Risorse: puoi specificare la memoria e il numero di CPU per il driver e l'executor di Spark. Il driver orchestra il job Spark. L'executor gestisce l'elaborazione dei dati in Spark.
- Avviso pipeline: puoi configurare la pipeline in modo che invii avvisi e avvii attività di post-elaborazione al termine dell'esecuzione della pipeline. Crea avvisi pipeline quando progetti la pipeline. Dopo aver eseguito il deployment della pipeline, puoi visualizzare gli avvisi. Per modificare le impostazioni degli avvisi, puoi modificare la pipeline.
- Pushdown di trasformazione: puoi attivare il pushdown di trasformazione se vuoi che una pipeline esegua determinate trasformazioni in BigQuery.
Per saperne di più, consulta Gestire le configurazioni della pipeline.
Riutilizza le pipeline utilizzando macro, preferenze e argomenti di runtime: Cloud Data Fusion ti consente di riutilizzare le pipeline di dati. Con le pipeline di dati riutilizzabili, puoi avere una singola pipeline in grado di applicare un pattern di integrazione dei dati a una varietà di casi d'uso e set di dati. Le pipeline riutilizzabili offrono una migliore gestibilità. Ti consentono di impostare la maggior parte della configurazione di una pipeline in fase di esecuzione, anziché codificarla in modo rigido in fase di progettazione. In Pipeline Design Studio, puoi utilizzare le macro per aggiungere variabili alle configurazioni dei plug-in in modo da poter specificare le sostituzioni delle variabili in fase di runtime. Per saperne di più, consulta Gestire macro, preferenze e argomenti di runtime.
Esegui: dopo aver esaminato le configurazioni della pipeline, puoi avviare l'esecuzione della pipeline. Puoi vedere la modifica dello stato durante le fasi di esecuzione della pipeline, ad esempio provisioning, avvio, esecuzione e operazione.
Pianifica e orchestra: le pipeline di dati batch possono essere impostate per l'esecuzione in base a una pianificazione e una frequenza specificate. Dopo aver creato ed eseguito il deployment di una pipeline, puoi creare una pianificazione. In Pipeline Design Studio, puoi orchestrare le pipeline creando un trigger su una pipeline di dati batch per eseguirla al completamento di una o più esecuzioni di pipeline. Queste sono chiamate pipeline downstream e upstream. Crea un trigger sulla pipeline downstream in modo che venga eseguita in base al completamento di una o più pipeline upstream.
Consigliato: puoi anche utilizzare Composer per orchestrare le pipeline in Cloud Data Fusion. Per saperne di più, consulta Pianificare le pipeline e Orchestrare le pipeline.
Modifica le pipeline: Cloud Data Fusion ti consente di modificare una pipeline di cui è stato eseguito il deployment. Quando modifichi una pipeline di cui è stato eseguito il deployment, viene creata una nuova versione della pipeline con lo stesso nome e viene contrassegnata come la versione più recente. In questo modo, puoi sviluppare le pipeline in modo iterativo anziché duplicarle, il che crea una nuova pipeline con un nome diverso. Per saperne di più, consulta Modificare le pipeline.
Logging e monitoraggio: per monitorare le metriche e i log della pipeline, ti consigliamo di attivare il servizio di logging Stackdriver per utilizzare Cloud Logging con la pipeline Cloud Data Fusion.
Passaggi successivi
- Scopri di più sulla gestione dell'amministrazione di Studio.