
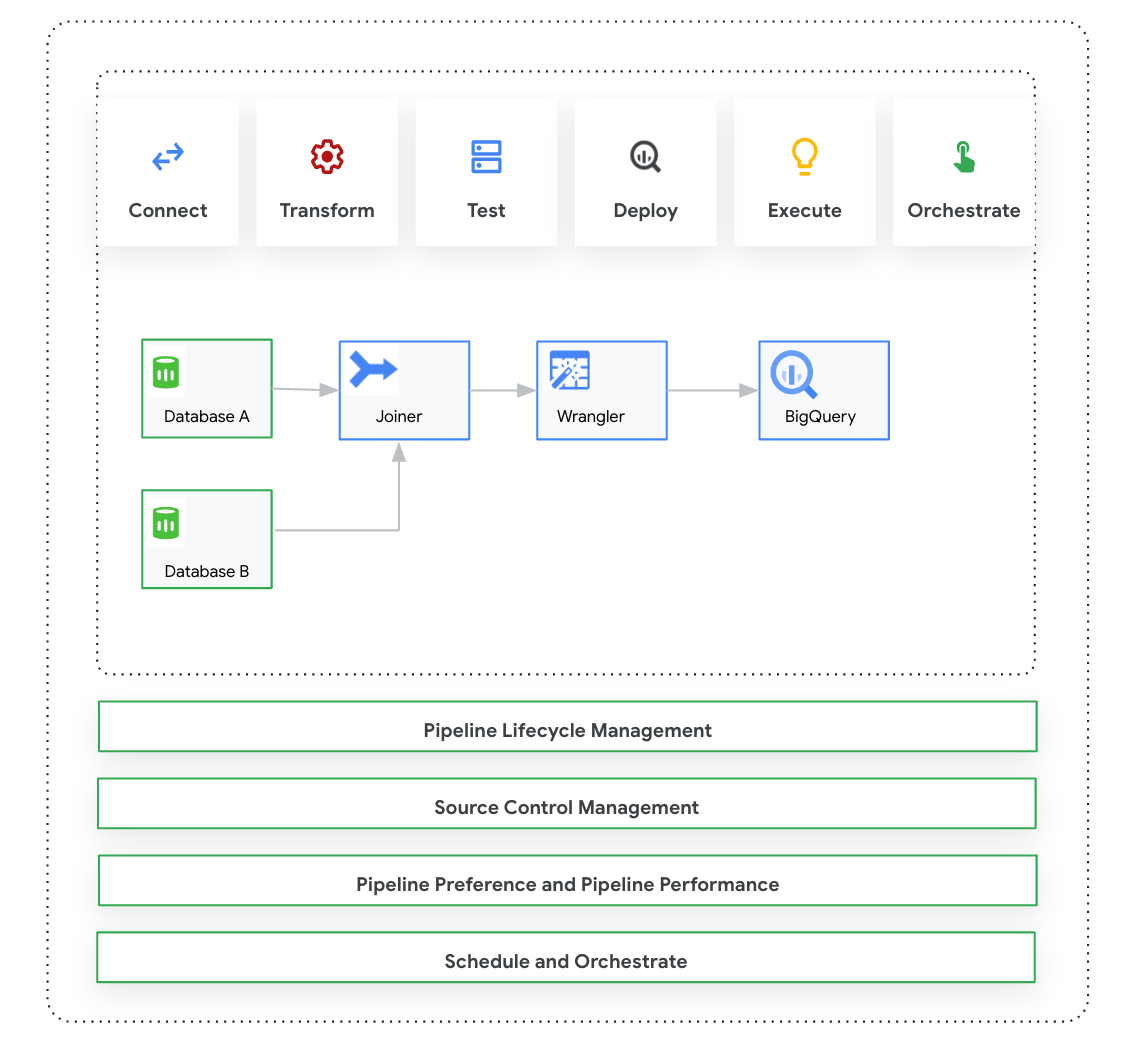
Halaman ini memperkenalkan Cloud Data Fusion: Studio, yang merupakan antarmuka visual dengan fungsi klik dan tarik untuk membangun pipeline data dari library plugin bawaan dan antarmuka tempat Anda mengonfigurasi, menjalankan, dan mengelola pipeline. Membangun pipeline di Studio biasanya mengikuti proses berikut:
- Hubungkan ke sumber data lokal atau cloud.
- Siapkan dan ubah data Anda.
- Hubungkan ke tujuan.
- Uji pipeline Anda.
- Jalankan pipeline Anda.
- Jadwalkan dan picu pipeline Anda.
Setelah mendesain dan menjalankan pipeline, Anda dapat mengelola pipeline di halaman Pipeline Studio Cloud Data Fusion:
- Gunakan kembali pipeline dengan memparameterisasinya menggunakan preferensi dan argumen runtime.
- Kelola eksekusi pipeline dengan menyesuaikan profil komputasi, mengelola resource, dan mengoptimalkan performa pipeline.
- Mengelola siklus proses pipeline dengan mengedit pipeline.
- Mengelola kontrol sumber pipeline menggunakan integrasi Git.
Sebelum memulai
- Aktifkan Cloud Data Fusion API.
- Buat instance Cloud Data Fusion.
- Pahami kontrol akses di Cloud Data Fusion.
- Pahami konsep dan istilah utama di Cloud Data Fusion.
Cloud Data Fusion: Ringkasan Studio
Studio mencakup komponen berikut.
Administrasi
Cloud Data Fusion memungkinkan Anda memiliki beberapa namespace di setiap instance. Dalam Studio, administrator dapat mengelola semua namespace secara terpusat, atau setiap namespace satu per satu.
Studio menyediakan kontrol administrator berikut:
- Administrasi Sistem
- Modul Admin Sistem di Studio memungkinkan Anda membuat namespace baru dan menentukan konfigurasi profil komputasi pusat di tingkat sistem, yang berlaku untuk setiap namespace di instance tersebut. Untuk mengetahui informasi selengkapnya, lihat Mengelola administrasi Studio.
- Administrasi Namespace
- Modul Admin Namespace di Studio memungkinkan Anda mengelola konfigurasi untuk namespace tertentu. Untuk setiap namespace, Anda dapat menentukan profil komputasi, preferensi runtime, driver, akun layanan, dan konfigurasi git. Untuk mengetahui informasi selengkapnya, lihat Mengelola administrasi Studio.
Pipeline Design Studio
Anda mendesain dan menjalankan pipeline di Pipeline Design Studio di antarmuka web Cloud Data Fusion. Mendesain dan menjalankan pipeline data mencakup langkah-langkah berikut:
- Menghubungkan ke sumber: Cloud Data Fusion memungkinkan koneksi ke sumber data lokal dan cloud. Antarmuka Studio memiliki plugin sistem default, yang sudah diinstal sebelumnya di Studio. Anda dapat mendownload plugin tambahan dari repositori plugin, yang dikenal sebagai Hub. Untuk informasi selengkapnya, lihat Ringkasan plugin.
- Persiapan data: Cloud Data Fusion memungkinkan Anda menyiapkan data menggunakan plugin persiapan data yang canggih: Wrangler. Wrangler membantu Anda melihat, menjelajahi, dan mengubah sebagian kecil data di satu tempat sebelum menjalankan logika pada seluruh set data di Studio. Dengan begitu, Anda dapat menerapkan transformasi dengan cepat untuk memahami pengaruhnya terhadap seluruh set data. Anda dapat membuat beberapa transformasi dan menambahkannya ke resep. Untuk mengetahui informasi selengkapnya, lihat Ringkasan Wrangler.
- Transformasi: Plugin transformasi mengubah data setelah dimuat dari sumber—misalnya, Anda dapat meng-clone rekaman, mengubah format file menjadi JSON, atau menggunakan plugin Javascript untuk membuat transformasi kustom. Untuk informasi selengkapnya, lihat Ringkasan plugin.
- Hubungkan ke tujuan: Setelah menyiapkan data dan menerapkan transformasi, Anda dapat terhubung ke tujuan tempat Anda berencana memuat data. Cloud Data Fusion mendukung koneksi ke beberapa tujuan. Untuk mengetahui informasi selengkapnya, lihat Ringkasan plugin.
- Pratinjau: Setelah mendesain pipeline, untuk men-debug masalah sebelum men-deploy dan menjalankan pipeline, Anda menjalankan tugas Pratinjau. Jika Anda menemukan kesalahan, Anda dapat memperbaikinya saat dalam mode Draf. Studio menggunakan 100 baris pertama set data sumber Anda untuk membuat pratinjau. Studio menampilkan status dan durasi tugas Pratinjau. Anda dapat menghentikan tugas kapan saja. Anda juga dapat memantau peristiwa log saat tugas Pratinjau berjalan. Untuk mengetahui informasi selengkapnya, lihat Melihat pratinjau data.
Mengelola konfigurasi pipeline: Setelah melihat pratinjau data, Anda dapat men-deploy pipeline dan mengelola konfigurasi pipeline berikut:
- Konfigurasi komputasi: Anda dapat mengubah profil komputasi yang menjalankan pipeline—misalnya, Anda ingin menjalankan pipeline terhadap cluster Managed Service for Apache Spark yang disesuaikan, bukan cluster Managed Service for Apache Spark default.
- Konfigurasi pipeline: Untuk setiap pipeline, Anda dapat mengaktifkan atau menonaktifkan instrumentasi, seperti metrik waktu. Secara default, instrumentasi diaktifkan.
- Konfigurasi mesin: Spark adalah mesin eksekusi default. Anda dapat meneruskan parameter kustom untuk Spark.
- Resources: Anda dapat menentukan memori dan jumlah CPU untuk driver dan eksekutor Spark. Driver mengorkestrasi tugas Spark. Eksekutor menangani pemrosesan data di Spark.
- Pemberitahuan pipeline: Anda dapat mengonfigurasi pipeline untuk mengirim pemberitahuan dan memulai tugas pasca-pemrosesan setelah operasi pipeline selesai. Anda membuat pemberitahuan pipeline saat mendesain pipeline. Setelah men-deploy pipeline, Anda dapat melihat pemberitahuan. Untuk mengubah setelan pemberitahuan, Anda dapat mengedit pipeline.
- Percepatan transformasi: Anda dapat mengaktifkan Percepatan transformasi jika ingin pipeline menjalankan transformasi tertentu di BigQuery.
Untuk mengetahui informasi selengkapnya, lihat Mengelola konfigurasi pipeline.
Menggunakan kembali pipeline menggunakan makro, preferensi, dan argumen runtime: Cloud Data Fusion memungkinkan Anda menggunakan kembali pipeline data. Dengan pipeline data yang dapat digunakan kembali, Anda dapat memiliki satu pipeline yang dapat menerapkan pola integrasi data ke berbagai kasus penggunaan dan set data. Pipeline yang dapat digunakan kembali memberi Anda kemampuan pengelolaan yang lebih baik. Dengan parameter ini, Anda dapat menetapkan sebagian besar konfigurasi pipeline pada waktu eksekusi, bukan melakukan hard-coding pada waktu desain. Di Pipeline Design Studio, Anda dapat menggunakan makro untuk menambahkan variabel ke konfigurasi plugin sehingga Anda dapat menentukan substitusi variabel saat runtime. Untuk mengetahui informasi selengkapnya, lihat Mengelola makro, preferensi, dan argumen runtime.
Jalankan: Setelah meninjau konfigurasi pipeline, Anda dapat memulai eksekusi pipeline. Anda dapat melihat perubahan status selama fase eksekusi pipeline—misalnya, penyediaan, memulai, menjalankan, dan berhasil.
Jadwalkan dan orkestrasi: Pipeline data batch dapat disetel untuk berjalan sesuai jadwal dan frekuensi yang ditentukan. Setelah membuat dan men-deploy pipeline, Anda dapat membuat jadwal. Di Pipeline Design Studio, Anda dapat mengatur pipeline dengan membuat pemicu pada pipeline data batch agar dapat dijalankan saat satu atau beberapa operasi pipeline selesai. Ini disebut pipeline hilir dan hulu. Anda membuat pemicu di pipeline downstream sehingga pipeline tersebut berjalan berdasarkan penyelesaian satu atau beberapa pipeline upstream.
Direkomendasikan: Anda juga dapat menggunakan Composer untuk mengorkestrasi pipeline di Cloud Data Fusion. Untuk mengetahui informasi selengkapnya, lihat Menjadwalkan pipeline dan Mengatur pipeline.
Mengedit pipeline: Cloud Data Fusion memungkinkan Anda mengedit pipeline yang di-deploy. Saat Anda mengedit pipeline yang di-deploy, versi baru pipeline dengan nama yang sama akan dibuat dan ditandai sebagai versi terbaru. Hal ini memungkinkan Anda mengembangkan pipeline secara iteratif, bukan menduplikasi pipeline, yang akan membuat pipeline baru dengan nama yang berbeda. Untuk mengetahui informasi selengkapnya, lihat Mengedit pipeline.
Pengelolaan Kontrol Sumber: Cloud Data Fusion memungkinkan Anda mengelola pipeline dengan lebih baik antara pengembangan dan produksi dengan Pengelolaan Kontrol Sumber pipeline menggunakan GitHub.
Logging dan pemantauan: Untuk memantau metrik dan log pipeline, sebaiknya aktifkan layanan logging Stackdriver untuk menggunakan Cloud Logging dengan pipeline Cloud Data Fusion Anda.
Langkah berikutnya
- Pelajari lebih lanjut cara mengelola administrasi Studio.