
Questa pagina descrive come vengono utilizzati i service account in Cloud Data Fusion. Per saperne di più, consulta Utilizza i service account.
Progetti tenant e cliente
Cloud Data Fusion configura i service account per accedere alle risorse nei seguenti progetti:
- Progetto tenant
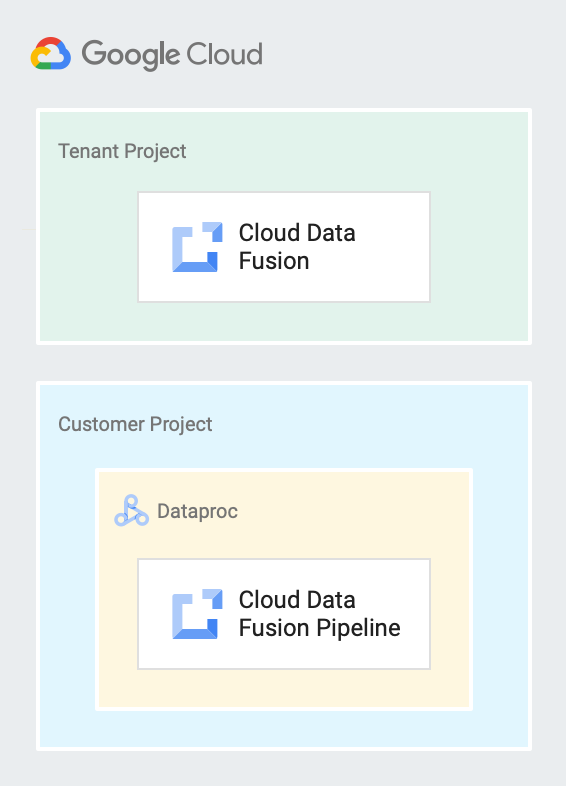
Cloud Data Fusion crea un progetto tenant per contenere le risorse e i servizi necessari per gestire le pipeline per tuo conto. Ad esempio, l'esecuzione di pipeline sui cluster Managed Service for Apache Spark che risiedono nel progetto del cliente. Non puoi vedere un progetto tenant, ma quando crei un'istanza privata, potresti dover utilizzare il nome del progetto tenant per configurare il peering VPC.
Per saperne di più, consulta la documentazione di Service Infrastructure sui progetti tenant.
- Progetto cliente
Questo progetto viene creato e di proprietà dell'utente. Per impostazione predefinita, Cloud Data Fusion crea un cluster Managed Service for Apache Spark temporaneo in questo progetto per eseguire le pipeline.
Il seguente diagramma mostra un'istanza di Cloud Data Fusion in esecuzione in un progetto tenant e una pipeline in esecuzione su un cluster Managed Service for Apache Spark in un progetto cliente.
Service account in Cloud Data Fusion
Un account di servizio fornisce un'identità per Cloud Data Fusion, che consente a Cloud Data Fusion di accedere alle tue risorse.
Quando abiliti l'API Data Fusion e crei un'istanza di Cloud Data Fusion, al tuo progetto viene aggiunto un account di servizio per accedere a risorse come Service Networking, Managed Service for Apache Spark, Cloud Storage, BigQuery, Spanner e Bigtable. Questo account di servizio è denominato il Cloud Data Fusion API Service Agent. A questo agente di servizio vengono concessi automaticamente i ruoli.
Un account di servizio viene identificato dal suo indirizzo email, che è univoco per l'account.
In Cloud Data Fusion vengono utilizzati i seguenti tipi di service account. Per saperne di più, consulta Tipi di service account.
| Service account | Descrizione |
|---|---|
service-CUSTOMER_PROJECT_NUMBER@gcp-sa-
datafusion.iam.gserviceaccount.com |
L'agente di servizio, chiamato Cloud Data Fusion API Data Fusion Service Agent, che Cloud Data Fusion crea per ottenere l'accesso alle risorse del cliente in modo che possa agire per conto del cliente. Viene utilizzato nel progetto tenant per accedere alle risorse del progetto cliente. Ad esempio, l'anteprima viene eseguita in memoria anziché in un cluster Managed Service for Apache Spark. Il
ruolo Identity and Access Management Cloud Data Fusion API Service Agent
( |
CUSTOMER_PROJECT_NUMBER-
compute@developer.gserviceaccount.com |
Il service account Compute Engine predefinito che Cloud Data Fusion crea per eseguire il deployment dei job che accedono ad altre Google Cloud risorse. Per impostazione predefinita, si collega a una VM del cluster Managed Service for Apache Spark per consentire a Cloud Data Fusion di accedere alle risorse di Managed Service for Apache Spark durante l'esecuzione di una pipeline. Nell'edizione Cloud Data Fusion Enterprise, puoi eseguire le pipeline da un service account gestito dall'utente creando un profilo dalla scheda Cloud Data Fusion console→System Admin→Configuration e aggiungendo il service account personalizzato. Nelle versioni 6.2.3 e successive, puoi scegliere un service account personalizzato da collegare al cluster Managed Service for Apache Spark quando crei un' istanza di Cloud Data Fusion. Per saperne di più, consulta Service account in Managed Service for Apache Spark. |
Passaggi successivi
- Scopri come controllare l'accesso ai dati.
- Concedi le autorizzazioni utente del service account.
- Consulta i prezzi di Cloud Data Fusion.