
Suggerimenti sulla sicurezza
Per i carichi di lavoro che richiedono un limite di sicurezza o un isolamento rigoroso, considera quanto segue:
Per applicare un isolamento rigoroso, inserisci i carichi di lavoro sensibili alla sicurezza in un progetto Google Cloud diverso.
Per controllare l'accesso a risorse specifiche, attiva il controllo dell'accesso basato sui ruoli nelle tue istanze di Cloud Data Fusion.
Per assicurarti che l'istanza non sia accessibile pubblicamente e per ridurre il rischio di esfiltrazione di dati sensibili, attiva gli indirizzi IP interni e i controlli di servizio VPC (VPC-SC) nelle tue istanze.
Autenticazione
La UI web di Cloud Data Fusion supporta i meccanismi di autenticazione supportati dalla console Google Cloud , con l'accesso controllato tramite Identity and Access Management.
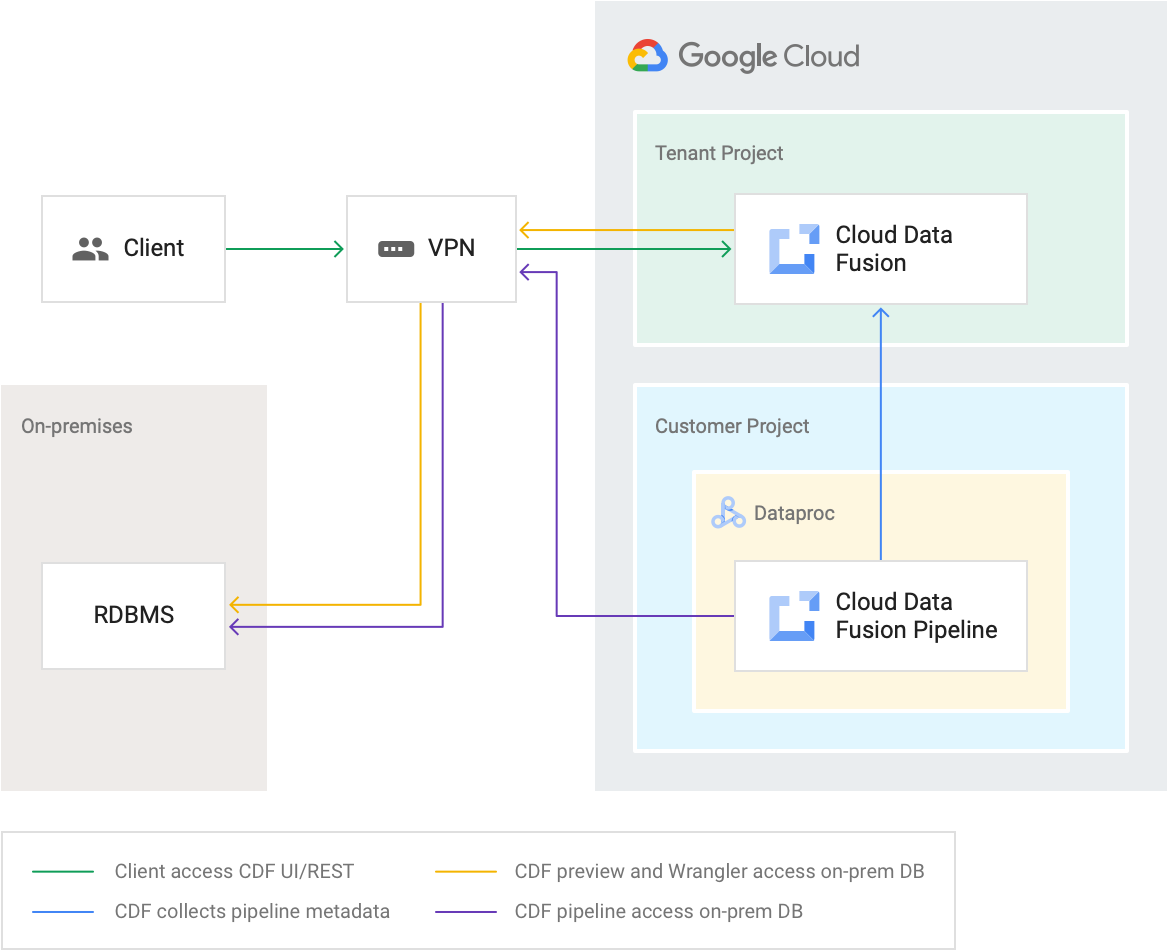
Controlli di networking
Puoi creare un'istanza privata di Cloud Data Fusion, che può essere connessa alla tua rete VPC tramite peering VPC o Private Service Connect. Le istanze private di Cloud Data Fusion hanno un indirizzo IP interno e non sono esposte a internet pubblico. È disponibile una sicurezza aggiuntiva utilizzando i controlli di servizio VPC per stabilire un perimetro di sicurezza attorno a un'istanza privata di Cloud Data Fusion.
Per saperne di più, consulta la panoramica del networking di Cloud Data Fusion.
Esecuzione della pipeline su cluster Managed Service for Apache Spark con IP interni pre-creati
Puoi utilizzare un'istanza privata di Cloud Data Fusion con il provisioner Hadoop remoto. Il cluster Managed Service for Apache Spark deve trovarsi sulla rete VPC con peering con Cloud Data Fusion. Il provisioner Hadoop remoto è configurato con l'indirizzo IP interno del nodo master del cluster Managed Service for Apache Spark.
Controllo degli accessi
Gestione dell'accesso all'istanza di Cloud Data Fusion: le istanze abilitate al controllo dell'accesso basato sui ruoli supportano la gestione dell'accesso a livello di spazio dei nomi tramite Identity and Access Management. Le istanze con RBAC disabilitato supportano solo la gestione dell'accesso a livello di istanza. Se hai accesso a un'istanza, hai accesso a tutte le pipeline e a tutti i metadati in quell'istanza.
Accesso della pipeline ai tuoi dati: l'accesso della pipeline ai dati viene fornito concedendo l'accesso all'account di servizio, che può essere un service account personalizzato specificato da te.
Regole firewall
Per l'esecuzione di una pipeline, controlli l'ingresso e l'uscita impostando le regole firewall appropriate nel VPC del cliente su cui viene eseguita la pipeline.
Per saperne di più, consulta Regole firewall.
Archiviazione delle chiavi
Password, chiavi e altri dati vengono archiviati in modo sicuro in Cloud Data Fusion e criptati utilizzando chiavi archiviate in Cloud Key Management Service. In fase di runtime, Cloud Data Fusion chiama Cloud Key Management Service per recuperare la chiave utilizzata per decriptare i secret archiviati.
Crittografia
Per impostazione predefinita, i dati sono criptati at-rest utilizzando Google-owned and Google-managed encryption keys e in transito utilizzando TLS v1.2. Utilizzi le chiavi di crittografia gestite dal cliente (CMEK) per controllare i dati scritti dalle pipeline Cloud Data Fusion, inclusi i metadati del cluster Managed Service for Apache Spark e le origini e i sink di dati Cloud Storage, BigQuery e Pub/Sub.
Service account
Le pipeline Cloud Data Fusion vengono eseguite nei cluster Managed Service for Apache Spark nel progetto del cliente e possono essere configurate per l'esecuzione utilizzando un account di servizio personalizzato specificato dal cliente. A un account di servizio personalizzato deve essere concesso il ruolo Utente service account.
Progetti
I servizi Cloud Data Fusion vengono creati in progetti tenant gestiti da Google a cui gli utenti non possono accedere. Le pipeline Cloud Data Fusion vengono eseguite su cluster Managed Service for Apache Spark all'interno dei progetti dei clienti. I clienti possono accedere a questi cluster per tutta la loro durata.
Audit log
Gli audit log di Cloud Data Fusion sono disponibili in Logging.
Plug-in e artefatti
Gli operatori e gli amministratori devono fare attenzione all'installazione di plug-in o artefatti non attendibili, in quanto potrebbero rappresentare un rischio per la sicurezza.
Federazione delle identità per la forza lavoro
Gli utenti della federazione delle identità per la forza lavoro possono eseguire operazioni in Cloud Data Fusion, come creare, eliminare, aggiornare ed elencare le istanze. Per ulteriori informazioni sulle limitazioni, consulta Federazione delle identità per la forza lavoro: prodotti supportati e limitazioni.