
Artifact Registry לא עוקב אחרי רישומים של צד שלישי כדי לראות אם יש עדכונים לתמונות שמועתקות ל-Artifact Registry. אם רוצים לשלב גרסה חדשה יותר של תמונה בצינור העברת הנתונים, צריך להעביר אותה אל Artifact Registry.
סקירה כללית על מיגרציה
ההעברה של קובצי האימג' של הקונטיינרים כוללת את השלבים הבאים:
- מגדירים תנאים מוקדמים.
- זיהוי התמונות שרוצים להעביר.
- חיפוש הפניות למאגרי צד שלישי בקובצי Dockerfile ובמניפסטים של פריסות
- קביעת תדירות השליפה של תמונות ממאגרי מידע של צד שלישי באמצעות Cloud Logging ו-BigQuery.
- העתקת התמונות שזוהו אל Artifact Registry.
- צריך לוודא שההרשאות למאגר מוגדרות בצורה נכונה, במיוחד אם Artifact Registry וסביבת הפריסה שלכם נמצאים בפרויקטים שונים. Google Cloud
- מעדכנים את המניפסטים של הפריסות.
- פורסים מחדש את עומסי העבודה.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
התקינו את ה-CLI של Google Cloud.
-
אם אתם משתמשים בספק זהויות חיצוני (IdP), קודם אתם צריכים להיכנס ל-CLI של gcloud באמצעות המאגר המאוחד לניהול זהויות.
-
כדי לאתחל את ה-CLI של gcloud, הריצו את הפקודה הבאה:
gcloud init -
יוצרים או בוחרים Google Cloud פרויקט.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
יוצרים Google Cloud פרויקט:
gcloud projects create PROJECT_ID
מחליפים את
PROJECT_IDבשם של פרויקט Google Cloud שיוצרים. -
בוחרים את הפרויקט שיצרתם: Google Cloud
gcloud config set project PROJECT_ID
מחליפים את
PROJECT_IDבשם הפרויקט ב- Google Cloud .
מפעילים את Artifact Registry API:
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידיםgcloud services enable artifactregistry.googleapis.com
-
התקינו את ה-CLI של Google Cloud.
-
אם אתם משתמשים בספק זהויות חיצוני (IdP), קודם אתם צריכים להיכנס ל-CLI של gcloud באמצעות המאגר המאוחד לניהול זהויות.
-
כדי לאתחל את ה-CLI של gcloud, הריצו את הפקודה הבאה:
gcloud init -
יוצרים או בוחרים Google Cloud פרויקט.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
יוצרים Google Cloud פרויקט:
gcloud projects create PROJECT_ID
מחליפים את
PROJECT_IDבשם של פרויקט Google Cloud שיוצרים. -
בוחרים את הפרויקט שיצרתם: Google Cloud
gcloud config set project PROJECT_ID
מחליפים את
PROJECT_IDבשם הפרויקט ב- Google Cloud .
מפעילים את Artifact Registry API:
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידיםgcloud services enable artifactregistry.googleapis.com
- אם אין לכם מאגר ב-Artifact Registry, אתם צריכים ליצור מאגר ולהגדיר אימות ללקוחות צד שלישי שזקוקים לגישה למאגר.
- בודקים את ההרשאות. צריך להיות לכם תפקיד IAM בעלים או עורך בפרויקטים שבהם אתם מעבירים תמונות ל-Artifact Registry.
- מייצאים את משתני הסביבה הבאים:
export PROJECT=$(gcloud config get-value project)
- מוודאים שגרסה 1.13 של Go או גרסה חדשה יותר מותקנת.
go version
עלויות
במדריך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
זיהוי התמונות שרוצים להעביר
מחפשים בקבצים שבהם אתם משתמשים כדי ליצור ולפרוס את קובצי האימג' בקונטיינר הפניות למאגרי צד שלישי, ואז בודקים באיזו תדירות אתם מושכים את קובצי האימג'.
זיהוי הפניות בקובצי Dockerfile
מבצעים את השלב הזה במיקום שבו מאוחסנים קובצי ה-Dockerfiles. יכול להיות שזה המקום שבו הקוד שלכם נבדק באופן מקומי, או ב-Cloud Shell אם הקבצים זמינים במכונה וירטואלית.בספרייה עם קובצי ה-Dockerfiles, מריצים את הפקודה:
grep -inr -H --include Dockerfile\* "FROM" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
הפלט אמור להיראות כך:
./code/build/baseimage/Dockerfile:1:FROM debian:stretch
./code/build/ubuntubase/Dockerfile:1:FROM ubuntu:latest
./code/build/pythonbase/Dockerfile:1:FROM python:3.5-buster
הפקודה הזו מחפשת את כל קובצי ה-Dockerfile בספרייה ומזהה את השורה "FROM". משנים את הפקודה לפי הצורך כך שתתאים לאופן שבו שומרים את קובצי ה-Dockerfiles.
זיהוי הפניות במניפסטים
מבצעים את השלבים האלה במיקום שבו מאוחסנים המניפסטים של GKE או של Cloud Run. יכול להיות שהקוד שלכם נמצא במיקום שבו הוא נבדק באופן מקומי, או ב-Cloud Shell אם הקבצים זמינים במכונה וירטואלית.- בספרייה עם מניפסטים של GKE או Cloud Run, מריצים את הפקודה הבאה:
grep -inr -H --include \*.yaml "image:" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
./code/deploy/k8s/ubuntu16-04.yaml:63: image: busybox:1.31.1-uclibc ./code/deploy/k8s/master.yaml:26: image: kubernetes/redis:v1 - כדי להציג רשימה של תמונות שפועלות באשכול, מריצים את הפקודה הבאה:
kubectl get all --all-namespaces -o yaml | grep image: | grep -i -v -E 'docker.pkg.dev|gcr.io'
- image: nginx image: nginx:latest - image: nginx - image: nginx
מריצים את הפקודות הקודמות לכל אשכולות GKE בכלGoogle Cloud הפרויקטים כדי לקבל כיסוי מלא.
זיהוי תדירות השליפה ממאגר מידע של צד שלישי
בפרויקטים ששולפים נתונים ממאגרי צד שלישי, אפשר להשתמש במידע על תדירות השליפה של התמונות כדי לקבוע אם השימוש שלכם קרוב או חורג ממגבלות הקצב שמאגר הצד השלישי אוכף.
איסוף נתוני יומן
יוצרים sink ביומן כדי לייצא נתונים ל-BigQuery. sink ביומן כולל יעד ושאילתה שבוחרת את רשומות היומן לייצוא. אפשר ליצור יעד על ידי שליחת שאילתות לפרויקטים בודדים, או להשתמש בסקריפט כדי לאסוף נתונים מפרויקטים שונים.
כדי ליצור יעד לפרויקט יחיד:
-
במסוף Google Cloud , נכנסים לדף Logs Explorer:
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Logging.
בוחרים Google Cloud פרויקט.
בכרטיסייה Query builder, מזינים את השאילתה הבאה:
resource.type="k8s_pod" jsonPayload.reason="Pulling"משנים את המסנן של היסטוריית השינויים מLast 1 hour (שעה אחרונה) ל-Last 7 Days (7 הימים האחרונים).
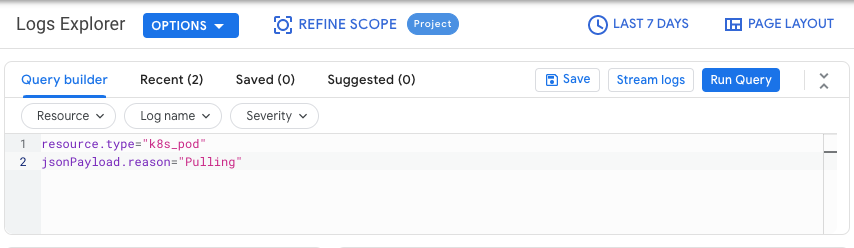
לוחצים על Run Query (הפעלת שאילתה).
אחרי שמוודאים שהתוצאות מוצגות בצורה תקינה, לוחצים על פעולות > יצירת יעד.
בתיבת הדו-שיח Sink details (פרטי יעד), משלימים את הפרטים הבאים:
- בשדה Sink Name, מזינים
image_pull_logs. - בשדה Sink description (תיאור של יעד), מזינים תיאור של היעד.
- בשדה Sink Name, מזינים
לוחצים על הבא.
בתיבת הדו-שיח Sink destination (יעד להעברה), בוחרים את הערכים הבאים:
- בשדה Select Sink service (בחירת שירות יעד), בוחרים באפשרות BigQuery dataset (מערך נתונים ב-BigQuery).
- בשדה Select BigQuery dataset (בחירת מערך נתונים ב-BigQuery), בוחרים באפשרות Create a new BigQuery dataset (יצירת מערך נתונים חדש ב-BigQuery) וממלאים את הפרטים הנדרשים בתיבת הדו-שיח שנפתחת. מידע נוסף על יצירת מערך נתונים ב-BigQuery זמין במאמר יצירת מערכי נתונים.
- לוחצים על יצירת מערך נתונים.
לוחצים על הבא.
בקטע Choose logs to include in sink, השאילתה תואמת לשאילתה שהפעלתם בכרטיסייה Query builder.
לוחצים על הבא.
אופציונלי: בוחרים יומנים לסינון ממאגר הנתונים. מידע נוסף על שליחת שאילתות וסינון נתונים ב-Cloud Logging זמין במאמר בנושא שפת השאילתות של Logging.
לוחצים על Create Sink.
sink ביומן נוצר.
כדי ליצור יעד למספר פרויקטים:
מריצים את הפקודות הבאות ב-Cloud Shell:
PROJECTS="PROJECT-LIST" DESTINATION_PROJECT="DATASET-PROJECT" DATASET="DATASET-NAME" for source_project in $PROJECTS do gcloud logging --project="${source_project}" sinks create image_pull_logs bigquery.googleapis.com/projects/${DESTINATION_PROJECT}/datasets/${DATASET} --log-filter='resource.type="k8s_pod" jsonPayload.reason="Pulling"' doneאיפה
- PROJECT-LIST היא רשימה של מזהי פרויקטים, מופרדים ברווחים. Google Cloud לדוגמה
project1 project2 project3. - DATASET-PROJECT הוא הפרויקט שבו רוצים לאחסן את מערך הנתונים.
- DATASET-NAME: השם של מערך הנתונים, למשל
image_pull_logs.
- PROJECT-LIST היא רשימה של מזהי פרויקטים, מופרדים ברווחים. Google Cloud לדוגמה
אחרי שיוצרים יעד, עובר זמן עד שהנתונים מגיעים לטבלאות ב-BigQuery, בהתאם לתדירות שבה התמונות נשלפות.
שליחת שאילתה לגבי תדירות המשיכה
אחרי שיש לכם מדגם מייצג של משיכות תמונות שהגרסאות שלכם מבצעות, אתם יכולים להריץ שאילתה כדי לראות את תדירות המשיכה.
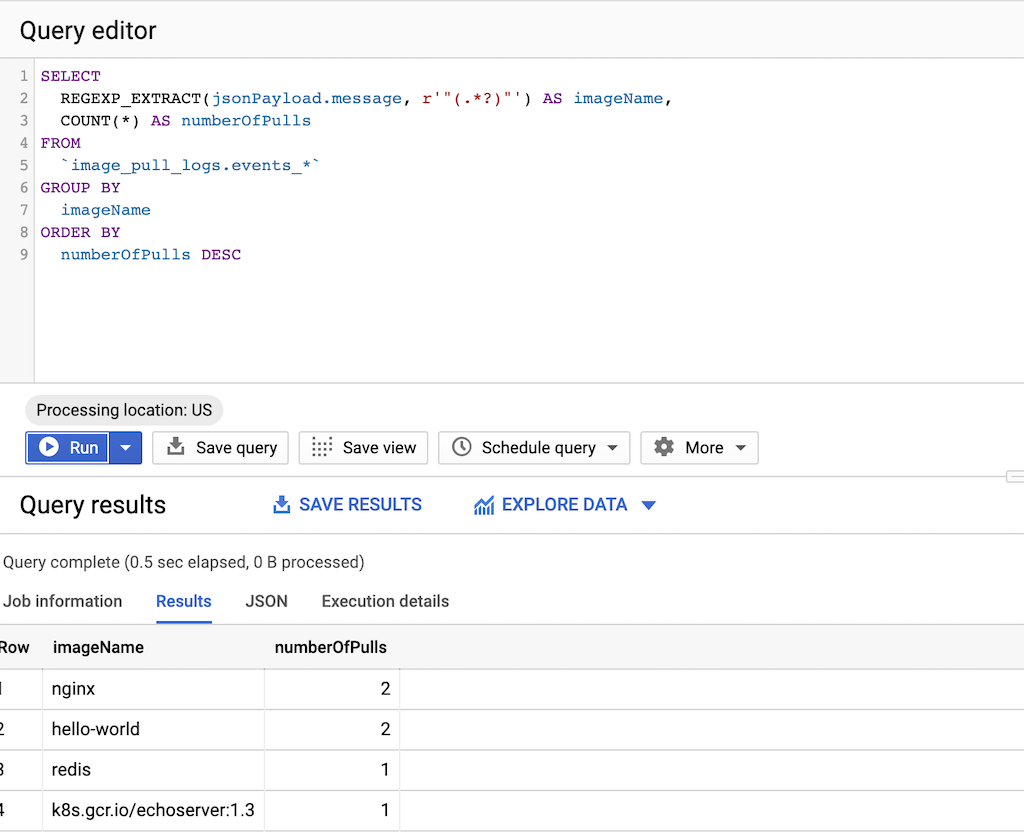
מריצים את השאילתה הבאה:
SELECT REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName, COUNT(*) AS numberOfPulls FROM `DATASET-PROJECT.DATASET-NAME.events_*` GROUP BY imageName ORDER BY numberOfPulls DESCאיפה
- DATASET-PROJECT הוא הפרויקט שמכיל את מערך הנתונים.
- DATASET-NAME הוא שם מערך הנתונים.
העתקת תמונות ל-Artifact Registry
אחרי שמזהים תמונות ממאגרי מידע של צד שלישי, אפשר להעתיק אותן ל-Artifact Registry. הכלי gcrane עוזר בתהליך ההעתקה.
יוצרים קובץ טקסט
images.txtעם שמות התמונות שזיהיתם. לדוגמה:ubuntu:18.04 debian:buster hello-world:latest redis:buster jupyter/tensorflow-notebookמורידים את gcrane.
GO111MODULE=on go get github.com/google/go-containerregistry/cmd/gcraneיוצרים סקריפט בשם
copy_images.shכדי להעתיק את רשימת הקבצים.#!/bin/bash images=$(cat images.txt) if [ -z "${AR_PROJECT}" ] then echo ERROR: AR_PROJECT must be set before running this exit 1 fi for img in ${images} do gcrane cp ${img} LOCATION-docker.pkg.dev/${AR_PROJECT}/${img} done מחליפים את
LOCATIONבמיקום האזורי או במספר אזורים של המאגר.הופכים את הסקריפט לניתן להרצה:
chmod +x copy_images.shמריצים את הסקריפט כדי להעתיק את הקבצים:
AR_PROJECT=${PROJECT} ./copy_images.sh
אימות ההרשאות
לפני שמעדכנים ומפעילים מחדש את עומסי העבודה, חשוב לוודא שההרשאות מוגדרות בצורה נכונה.
מידע נוסף זמין במאמר בנושא בקרת גישה.
עדכון קובצי המניפסט כדי להפנות אל Artifact Registry
מעדכנים את קובצי ה-Dockerfile ואת קובצי המניפסט כך שיפנו אל Artifact Registry במקום אל מאגר חיצוני.
בדוגמה הבאה מוצג מניפסט שמפנה למאגר של צד שלישי:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
הגרסה המעודכנת של המניפסט מפנה לתמונה בכתובת us-docker.pkg.dev.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: us-docker.pkg.dev/<AR_PROJECT>/nginx:1.14.2
ports:
- containerPort: 80
אם יש מספר גדול של קובצי מניפסט, אפשר להשתמש ב-sed או בכלי אחר שיכול לטפל בעדכונים במספר רב של קובצי טקסט.
פריסה מחדש של עומסי עבודה
פורסים מחדש את עומסי העבודה עם קובצי המניפסט המעודכנים.
כדי לעקוב אחרי משיכות חדשות של תמונות, מריצים את השאילתה הבאה במסוף BigQuery:
SELECT`
FORMAT_TIMESTAMP("%D %R", timestamp) as timeOfImagePull,
REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName,
COUNT(*) AS numberOfPulls
FROM
`image_pull_logs.events_*`
GROUP BY
timeOfImagePull,
imageName
ORDER BY
timeOfImagePull DESC,
numberOfPulls DESC
כל משיכות התמונות החדשות צריכות להיות מ-Artifact Registry ולהכיל את המחרוזת docker.pkg.dev.