
Este tutorial interativo mostra como usar a recuperação automática para criar apps altamente disponíveis no Compute Engine.
As apps de elevada disponibilidade são concebidas para servir clientes com latência mínima e tempo de inatividade. A disponibilidade é comprometida quando uma app falha ou fica bloqueada. Os clientes de uma app comprometida podem ter uma latência elevada ou um tempo de inatividade.
A autorrecuperação permite-lhe reiniciar automaticamente as apps comprometidas. Deteta prontamente instâncias de máquinas virtuais (VM) com falhas e recria-as automaticamente, para que os clientes possam ser atendidos novamente. Com a autorrecuperação, já não tem de repor manualmente uma app em serviço após uma falha.
Objetivos
- Configure uma verificação de estado e uma política de autorreparação.
- Configure um serviço Web de demonstração num grupo de instâncias geridas (MIG).
- Simule falhas de verificações de estado e observe o processo de recuperação de autocura.
Custos
Este tutorial usa componentes faturáveis do Google Cloud , incluindo:- Compute Engine
Antes de começar
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles. - Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles. - Verificação de funcionamento: Uma política de verificação de funcionamento de HTTP usada pelo reparador automático para detetar VMs com falhas.
- Regras de firewall: Google Cloud as regras de firewall permitem-lhe permitir ou negar tráfego para as suas VMs.
- Grupo de instâncias geridas: Um grupo de VMs que executam o mesmo serviço Web de demonstração.
- Modelo de instância: um modelo usado para criar cada VM no grupo de instâncias.
Crie uma verificação de funcionamento.
Na Google Cloud consola, aceda à página Criar verificação de funcionamento.
No campo Nome, introduza
autohealer-check.Defina o Âmbito para
Regional.No menu pendente Região, selecione
europe-west1.Para Protocolo, selecione
HTTP.Defina Caminho do pedido como
/health. Isto indica o caminho HTTP que a verificação de estado usa. Para este tutorial, o servidor Web de demonstração define o caminho/healthpara devolver uma respostaHTTP 200 (OK)quando está em bom estado ou uma respostaHTTP 500 (Internal Server Error)quando está em mau estado.Defina os critérios de saúde:
- Defina o Intervalo de verificação como
10. Isto define o período de tempo desde o início de uma sondagem até ao início da seguinte. - Defina o Limite de tempo para
5. Isto define o período durante o qual o dispositivo Google Cloud aguarda uma resposta a uma sondagem. Este valor tem de ser igual ou inferior ao intervalo de verificação. - Definir limite saudável para
2. Isto define o número de sondagens sequenciais que têm de ser bem-sucedidas para que a VM seja considerada em bom estado. - Defina o limite não saudável para
3. Isto define o número de sondagens sequenciais que têm de falhar para que a VM seja considerada não saudável.
- Defina o Intervalo de verificação como
Deixe os valores predefinidos para as outras opções.
Clique em Criar na parte inferior.
Crie uma regra de firewall para permitir que as sondas de verificação de funcionamento façam pedidos HTTP.
Na Google Cloud consola, aceda à página Criar regra de firewall.
Em Nome, introduza
default-allow-http-health-check.Para Rede, selecione
default.Para Segmentações, selecione
All instances in the network.Para o Filtro de origem, selecione
IPv4 ranges.Para Intervalos de IPv4 de origem, introduza
130.211.0.0/22, 35.191.0.0/16.Em Protocolos e portas, selecione TCP e introduza
80.Deixe os valores predefinidos para as outras opções.
Clique em Criar.
Crie uma verificação de funcionamento com o comando
health-checks create http.gcloud compute health-checks create http autohealer-check \ --region europe-west1 \ --check-interval 10 \ --timeout 5 \ --healthy-threshold 2 \ --unhealthy-threshold 3 \ --request-path "/health"check-intervaldefine o período de tempo desde o início de uma sondagem até ao início da seguinte.timeoutdefine a quantidade de tempo que Google Cloud aguarda uma resposta a uma sondagem. Este valor tem de ser inferior ou igual ao intervalo de verificação.healthy-thresholddefine o número de sondagens sequenciais que têm de ser bem-sucedidas para que a VM seja considerada em bom estado.unhealthy-thresholddefine o número de sondagens sequenciais que têm de falhar para que a VM seja considerada não saudável.request-pathindica o caminho HTTP que a verificação de estado usa. Para este tutorial, o servidor Web de demonstração define o caminho/healthpara devolver uma respostaHTTP 200 (OK)quando estiver em bom estado ou uma respostaHTTP 500 (Internal Server Error)quando estiver em mau estado.
Crie uma regra de firewall para permitir que as sondas de verificação de funcionamento façam pedidos HTTP.
gcloud compute firewall-rules create default-allow-http-health-check \ --network default \ --allow tcp:80 \ --source-ranges 130.211.0.0/22,35.191.0.0/16unhealthy-threshold. Deve ser superior a1. Idealmente, defina este valor como3ou mais. Isto protege contra falhas raras, como a perda de um pacote de rede.healthy-threshold. Um valor de2é suficiente para a maioria das apps.timeout. Defina este valor de tempo para um valor generoso (cinco vezes ou mais do que o tempo de resposta esperado). Isto protege contra atrasos inesperados, como instâncias ocupadas ou uma ligação de rede lenta.check-interval. Este valor deve estar entre 1 segundo e o dobro do tempo limite (não deve ser demasiado longo nem demasiado curto). Quando um valor é demasiado longo, não é detetada uma instância com falhas com a devida antecedência. Quando um valor é demasiado curto, as instâncias e a rede podem ficar visivelmente ocupadas, dado o elevado número de sondagens de verificação do estado de funcionamento que são enviadas a cada segundo.Crie um modelo de instância. Inclua um script de arranque que inicie o servidor Web de demonstração.
Na Google Cloud consola, aceda à página Criar modelo de instância.
Defina o Nome como
webserver-template.Na secção Localização, no menu pendente Região, selecione europe-west1.
Na secção Configuração da máquina, no menu pendente Tipo de máquina, selecione e2-medium.
Na secção Firewall, selecione a caixa de verificação Permitir tráfego HTTP.
Expanda a secção Opções avançadas para revelar as definições avançadas. São apresentadas várias subsecções.
Na secção Gestão, encontre Automatização e introduza o script de arranque seguinte:
apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo
Deixe os valores predefinidos para as outras opções.
Clique em Criar.
Implemente o servidor Web como um grupo de instâncias geridas.
Na Google Cloud consola, aceda à página Criar grupo de instâncias.
Defina o Nome como
webserver-group.Para Modelo de instância, selecione
webserver-template.Para Região, selecione
europe-west1.Para Zona, selecione
europe-west1-b.Na secção Ajuste de escala automático, para Modo de ajuste de escala automático, selecione Desativado: não ajustar a escala automaticamente.
Desloque a página para trás até ao campo Número de instâncias e defina-o como
3.Na secção Reparação automática, faça o seguinte:
- No menu pendente Verificação de saúde, selecione
autohealer-check. Defina Initial delay como
300.
- No menu pendente Verificação de saúde, selecione
Deixe os valores predefinidos para as outras opções.
Clique em Criar.
Crie uma regra de firewall que permita pedidos HTTP aos servidores Web.
Na Google Cloud consola, aceda à página Criar regra de firewall.
Em Nome, introduza
default-allow-http.Para Rede, selecione
default.Para Segmentações, selecione
Specified target tags.Para Etiquetas de segmentação, introduza
http-server.Para o Filtro de origem, selecione
IPv4 ranges.Para Intervalos IPv4 de origem, introduza
0.0.0.0/0para permitir o acesso a todos os endereços IP.Em Protocolos e portas, selecione TCP e introduza
80.Deixe os valores predefinidos para as outras opções.
Clique em Criar.
Crie um modelo de instância. Inclua um script de arranque que inicie o servidor Web de demonstração.
gcloud compute instance-templates create webserver-template \ --instance-template-region europe-west1 \ --machine-type e2-medium \ --tags http-server \ --metadata startup-script=' apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo'Crie um grupo de instâncias gerido.
gcloud compute instance-groups managed create webserver-group \ --zone europe-west1-b \ --template projects/PROJECT_ID/regions/europe-west1/instanceTemplates/webserver-template \ --size 3 \ --health-check projects/PROJECT_ID/regions/europe-west1/healthChecks/autohealer-check \ --initial-delay 300Crie uma regra de firewall que permita pedidos HTTP aos servidores Web.
gcloud compute firewall-rules create default-allow-http \ --network default \ --allow tcp:80 \ --target-tags http-serverNavegue para uma VM de servidor Web.
Na Google Cloud consola, aceda à página Instâncias de VM.
Para qualquer
webserver-groupVM, na coluna IP externo, clique no endereço IP. É aberto um novo separador no seu navegador de Internet. Se o pedido exceder o tempo limite ou a página Web não estiver disponível, aguarde um minuto para permitir que o servidor termine a configuração e tente novamente.
O servidor Web de demonstração apresenta uma página semelhante à seguinte:
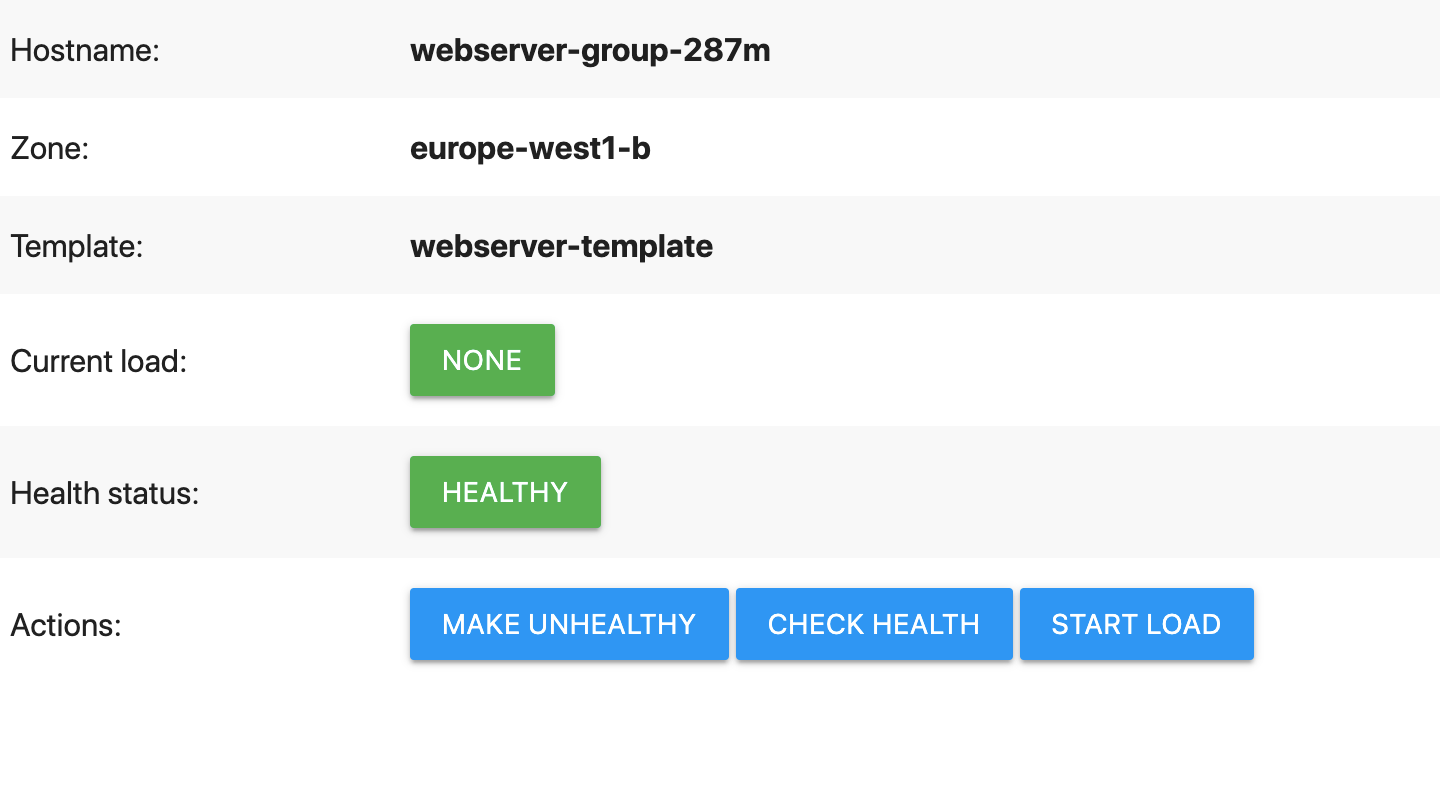
Na página Web de demonstração, clique em Tornar não saudável.
Isto faz com que o servidor Web falhe a verificação de funcionamento. Especificamente, o servidor Web faz com que o caminho
/healthdevolva umHTTP 500 (Internal Server Error). Pode verificar esta situação rapidamente clicando no botão Verificar estado de funcionamento (esta ação deixa de funcionar depois de o reparador automático ter começado a reiniciar a VM).Aguarde que o autohealer tome medidas.
Na Google Cloud consola, aceda à página Instâncias de VM.
Aguarde que o estado da VM do servidor Web se altere. A marca de verificação verde junto ao nome da VM deve mudar para um quadrado cinzento, o que indica que o reparador automático começou a reiniciar a VM não saudável.
Clique em Atualizar na parte superior da página periodicamente para ver o estado mais recente.
O processo de autocorreção termina quando o quadrado cinzento volta a ser uma marca de verificação verde, o que indica que a VM está novamente em bom estado.
Monitorize o estado do grupo de instâncias geridas. (Quando terminar, pare premindo
Ctrl+C.)while : ; do gcloud compute instance-groups managed list-instances webserver-group \ --zone europe-west1-b sleep 5 # Wait for 5 seconds done
NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-4qbx ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-m5v5 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR:
Todas as VMs no grupo têm de apresentar
STATUS: RUNNINGeACTION: NONE. Caso contrário, aguarde alguns minutos para que as VMs terminem a configuração e tente novamente.Abra uma nova sessão do Cloud Shell com a CLI Google Cloud instalada.
Obtenha o endereço de uma VM de servidor Web.
gcloud compute instances list --filter webserver-group
Na coluna
EXTERNAL_IP, copie o endereço IP de qualquer VM do servidor Web e guarde-o como uma variável bash local.export IP_ADDRESS=EXTERNAL_IP_ADDRESS
Verifique se o servidor Web concluiu a configuração. O servidor devolve uma resposta
HTTP 200 OK.curl --head $IP_ADDRESS/health
HTTP/1.1 200 OK Server: gunicorn ...
Se receber um erro
Connection refused, aguarde um minuto para permitir que o servidor conclua a configuração e tente novamente.Tornar o servidor Web pouco saudável.
curl $IP_ADDRESS/makeUnhealthy > /dev/null
Isto faz com que o servidor Web falhe a verificação de funcionamento. Especificamente, o servidor Web faz com que o caminho
/healthdevolva umHTTP 500 INTERNAL SERVER ERROR. Pode verificar isto rapidamente fazendo um pedido para/health(isto deixa de funcionar depois de o reparador automático ter começado a reiniciar a VM).curl --head $IP_ADDRESS/health
HTTP/1.1 500 INTERNAL SERVER ERROR Server: gunicorn ...
Regresse à primeira sessão de shell para monitorizar o grupo de instâncias gerido e aguarde que o reparador automático tome medidas.
Quando o processo de autorreparação é iniciado, as colunas
STATUSeACTIONsão atualizadas, indicando que o autorreparador começou a reiniciar a VM em mau estado.NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: STOPPING HEALTH_STATE: UNHEALTHY ACTION: RECREATING INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
O processo de autorreparação termina quando a VM volta a comunicar um
STATUSdeRUNNINGe umACTIONdeNONE, o que indica que a VM foi reiniciada com êxito.NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
Quando terminar a monitorização do grupo de instâncias gerido, pare premindo
Ctrl+C.
O que acontece se tornar todas as VMs não íntegras ao mesmo tempo? Para mais informações sobre o comportamento da autocorreção durante falhas simultâneas, consulte o comportamento da autocorreção.
Pode atualizar a configuração da verificação de funcionamento para reparar as VMs o mais rapidamente possível? (Na prática, deve definir os parâmetros de verificação do estado de funcionamento para usar valores conservadores, conforme explicado neste tutorial. Caso contrário, pode correr o risco de as VMs serem eliminadas e reiniciadas por engano quando não existe um problema real.)
O grupo de instâncias geridas tem uma definição de configuração
initial delay. Consegue determinar o atraso mínimo necessário para este servidor Web de demonstração? (Na prática, deve definir o atraso para um período ligeiramente superior (10% a 20%) ao necessário para uma VM arrancar e começar a publicar pedidos de apps. Caso contrário, corre o risco de a VM ficar bloqueada num ciclo de arranque de autorreparação.)- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Instance groups page.
-
Select the checkbox for
your
webserver-groupinstance group. - To delete the instance group, click Delete.
Na Google Cloud consola, aceda à página Modelos de instâncias.
Clique na caixa de verificação junto ao modelo de instância.
Clique em Eliminar na parte superior da página. Na nova janela, clique em Eliminar para confirmar a eliminação.
Na Google Cloud consola, aceda à página Verificações de estado.
Clique na caixa de verificação junto à verificação de estado.
Clique em Eliminar na parte superior da página. Na nova janela, clique em Eliminar para confirmar a eliminação.
Na Google Cloud consola, aceda à página Regras de firewall.
Clique nas caixas de verificação junto às regras de firewall denominadas
default-allow-httpedefault-allow-http-health-check.Clique em Eliminar na parte superior da página. Na nova janela, clique em Eliminar para confirmar a eliminação.
- Experimente outro tutorial:
- Saiba mais sobre os grupos de instâncias geridos.
- Saiba mais sobre como conceber sistemas robustos.
- Saiba mais sobre como criar apps Web escaláveis e resilientes no Google Cloud.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Se preferir trabalhar a partir da linha de comandos, instale a CLI do Google Cloud.
Instale a CLI Google Cloud. Após a instalação, inicialize a CLI gcloud executando o seguinte comando:
gcloud initSe estiver a usar um fornecedor de identidade (IdP) externo, primeiro tem de iniciar sessão na CLI gcloud com a sua identidade federada.
Arquitetura da app
A app inclui os seguintes componentes do Compute Engine:
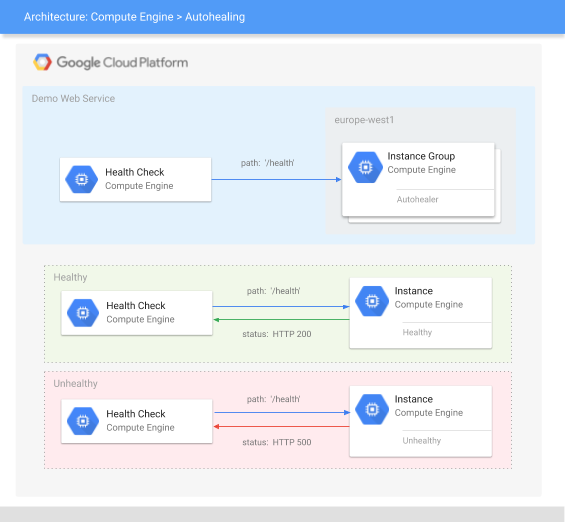
Como a verificação de funcionamento sonda o serviço Web de demonstração
Uma verificação de estado envia pedidos de sondagem a uma VM através de um protocolo especificado, como HTTP(S), SSL ou TCP. Para mais informações, consulte como funcionam as verificações de funcionamento e as categorias, os protocolos e as portas das verificações de funcionamento.
A verificação de funcionamento neste tutorial é uma verificação de funcionamento de HTTP que analisa o caminho HTTP /health na porta 80. Para uma verificação de funcionamento de HTTP, o pedido de sondagem é aprovado apenas se o caminho devolver uma resposta HTTP 200 (OK). Para este tutorial, o servidor Web de demonstração define o caminho /health para devolver uma resposta HTTP 200 (OK) quando estiver em bom estado ou uma resposta HTTP 500 (Internal Server Error) quando estiver em mau estado.
Para mais informações, consulte os critérios de êxito para HTTP, HTTPS e HTTP/2.
Crie a verificação de funcionamento
Para configurar a autorreparação, crie uma verificação de funcionamento personalizada e configure a firewall de rede para permitir sondagens de verificação de funcionamento.
Neste tutorial, cria uma verificação de funcionamento regional. Para a autocura, pode usar uma verificação de estado regional ou global. As verificações de estado regionais reduzem as dependências entre regiões e ajudam a alcançar a residência dos dados. As verificações de estado globais são convenientes se quiser usar a mesma verificação de estado para os MIGs em várias regiões.
Consola
gcloud
O que é necessário para uma boa verificação de funcionamento de autorreparação
As verificações de estado de funcionamento usadas para a autorrecuperação devem ser conservadoras para não eliminarem e recriarem as suas instâncias antecipadamente. Quando uma verificação de estado do reparador automático é demasiado agressiva, o reparador automático pode confundir instâncias ocupadas com instâncias com falhas e reiniciá-las desnecessariamente, reduzindo a disponibilidade.
Configure o serviço Web
Este tutorial usa uma app Web armazenada no GitHub. Se quiser saber mais sobre como a app foi implementada, consulte o repositório do GitHub GoogleCloudPlatform/python-docs-samples.
Para configurar o serviço Web de demonstração, crie um modelo de instância que inicie o servidor Web de demonstração no arranque. Em seguida, use este modelo de instância para implementar um grupo de instâncias gerido e ativar a autorreparação.
Consola
gcloud
Aguarde alguns minutos para que o grupo de instâncias gerido crie e valide as respetivas VMs.
Simule falhas de verificações de funcionamento
Para simular falhas na verificação do estado, o servidor Web de demonstração oferece formas de forçar uma falha na verificação do estado.
Consola
gcloud
Não hesite em repetir este exercício. Seguem-se algumas ideias:
Veja o histórico do reparador automático (opcional)
Para ver um histórico das operações do Autohealer, use o seguinte comando
gcloud:
gcloud compute operations list --filter='operationType~compute.instances.repair.*'
Para mais informações, consulte o artigo sobre como ver operações de autocorreção anteriores
Limpar
Depois de concluir o tutorial, pode limpar os recursos que criou para que deixem de usar a quota e incorrer em custos. As secções seguintes descrevem como eliminar ou desativar estes recursos.
Se criou um projeto separado para este tutorial, elimine o projeto completo. Caso contrário, se o projeto tiver recursos que quer manter, elimine apenas os recursos específicos criados neste tutorial.
Eliminar o projeto
Eliminar recursos específicos
Se não conseguir eliminar o projeto usado para este tutorial, elimine os recursos do tutorial individualmente.
Eliminar o grupo de instâncias
consola
gcloud
gcloud compute instance-groups managed delete webserver-group --zone europe-west1-b -q
Eliminar o modelo de instância
consola
gcloud
gcloud compute instance-templates delete webserver-template -q \
--region=europe-west1
Eliminar a verificação de funcionamento
consola
gcloud
gcloud compute health-checks delete autohealer-check -q \
--region=europe-west1
Eliminar as regras de firewall
consola
gcloud
gcloud compute firewall-rules delete default-allow-http default-allow-http-health-check -q