
En este tutorial se explica cómo desplegar una base de datos MySQL 5.6 enGoogle Cloud mediante Distributed Replicated Block Device (DRBD) y Compute Engine. DRBD es un sistema de almacenamiento replicado distribuido para la plataforma Linux.
Este tutorial es útil si eres administrador de sistemas, desarrollador, ingeniero, administrador de bases de datos o ingeniero de DevOps. Puede que quieras gestionar tu propia instancia de MySQL en lugar de usar el servicio gestionado por varios motivos, entre los que se incluyen los siguientes:
- Estás usando instancias de MySQL entre regiones.
- Debes definir parámetros que no estén disponibles en la versión gestionada de MySQL.
- Quieres optimizar el rendimiento de formas que no se pueden configurar en la versión gestionada.
DRBD proporciona replicación a nivel de dispositivo de bloque. Esto significa que no tienes que configurar la replicación en MySQL y que obtienes las ventajas de DRBD de inmediato, como la compatibilidad con el equilibrio de carga de lectura y las conexiones seguras.
En el tutorial se utiliza lo siguiente:
No es necesario tener conocimientos avanzados para usar estos recursos, aunque en este documento se hace referencia a funciones avanzadas, como la agrupación en clústeres de MySQL, la configuración de DRBD y la gestión de recursos de Linux.
Arquitectura
Pacemaker es un gestor de recursos de clústeres. Corosync es un paquete de comunicación y participación de clústeres que usa Pacemaker. En este tutorial, usarás DRBD para replicar el disco de MySQL de la instancia principal a la de espera. Para que los clientes se conecten al clúster de MySQL, también debes implementar un balanceador de carga interno.
Despliega un clúster de tres instancias de proceso gestionado por Pacemaker. Instalas MySQL en dos de las instancias, que actúan como instancias principal y de reserva. La tercera instancia actúa como dispositivo de quórum.
En un clúster, cada nodo vota por el nodo que debe ser el nodo activo, es decir, el que ejecuta MySQL. En un clúster de dos nodos, solo se necesita un voto para determinar el nodo activo. En ese caso, el comportamiento del clúster puede provocar problemas de cerebro dividido o tiempos de inactividad. Los problemas de cerebro dividido se producen cuando ambos nodos toman el control, ya que solo se necesita un voto en un escenario de dos nodos. El tiempo de inactividad se produce cuando el nodo que se apaga es el que está configurado para ser siempre el principal en caso de pérdida de conectividad. Si los dos nodos pierden la conectividad entre sí, existe el riesgo de que más de un nodo del clúster asuma que es el nodo activo.
Si añades un dispositivo de quórum, se evitará esta situación. Un dispositivo de quórum actúa como árbitro, cuya única tarea es emitir un voto. De esta forma, en una situación en la que las instancias de database1 y database2 no puedan comunicarse, este nodo de dispositivo de quórum podrá comunicarse con una de las dos instancias y se podrá alcanzar una mayoría.
En el siguiente diagrama se muestra la arquitectura del sistema descrito en este artículo.

Configuración
En esta sección, configurará una cuenta de servicio, creará variables de entorno y reservará direcciones IP.
Configurar una cuenta de servicio para las instancias del clúster
Abre Cloud Shell:
Crea la cuenta de servicio:
gcloud iam service-accounts create mysql-instance \ --display-name "mysql-instance"Asigna los roles necesarios para este tutorial a la cuenta de servicio:
gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.instanceAdmin.v1 gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.viewer gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountUser
Crear variables de entorno de Cloud Shell
Crea un archivo con las variables de entorno necesarias para este tutorial:
cat <<EOF > ~/.mysqldrbdrc # Cluster instance names DATABASE1_INSTANCE_NAME=database1 DATABASE2_INSTANCE_NAME=database2 QUORUM_INSTANCE_NAME=qdevice CLIENT_INSTANCE_NAME=mysql-client # Cluster IP addresses DATABASE1_INSTANCE_IP="10.140.0.2" DATABASE2_INSTANCE_IP="10.140.0.3" QUORUM_INSTANCE_IP="10.140.0.4" ILB_IP="10.140.0.6" # Cluster zones and region DATABASE1_INSTANCE_ZONE="asia-east1-a" DATABASE2_INSTANCE_ZONE="asia-east1-b" QUORUM_INSTANCE_ZONE="asia-east1-c" CLIENT_INSTANCE_ZONE="asia-east1-c" CLUSTER_REGION="asia-east1" EOFCarga las variables de entorno en la sesión actual y configura Cloud Shell para que las cargue automáticamente en futuros inicios de sesión:
source ~/.mysqldrbdrc grep -q -F "source ~/.mysqldrbdrc" ~/.bashrc || echo "source ~/.mysqldrbdrc" >> ~/.bashrc
Reservar direcciones IP
En Cloud Shell, reserva una dirección IP interna para cada uno de los tres nodos del clúster:
gcloud compute addresses create ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} ${QUORUM_INSTANCE_NAME} \ --region=${CLUSTER_REGION} \ --addresses "${DATABASE1_INSTANCE_IP},${DATABASE2_INSTANCE_IP},${QUORUM_INSTANCE_IP}" \ --subnet=default
Crear las instancias de Compute Engine
En los siguientes pasos, las instancias del clúster usan Debian 9 y las instancias del cliente usan Ubuntu 16.
En Cloud Shell, crea una instancia de MySQL llamada
database1en la zonaasia-east1-a:gcloud compute instances create ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE1_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-1 \ --private-network-ip=${DATABASE1_INSTANCE_NAME} \ --tags=mysql --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"Crea una instancia de MySQL llamada
database2en la zonaasia-east1-b:gcloud compute instances create ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE2_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-2 \ --private-network-ip=${DATABASE2_INSTANCE_NAME} \ --tags=mysql \ --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"Crea un nodo de quorum para que lo use Pacemaker en la zona
asia-east1-c:gcloud compute instances create ${QUORUM_INSTANCE_NAME} \ --zone=${QUORUM_INSTANCE_ZONE} \ --machine-type=n1-standard-1 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=10GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${QUORUM_INSTANCE_NAME} \ --private-network-ip=${QUORUM_INSTANCE_NAME}Crea una instancia de cliente de MySQL:
gcloud compute instances create ${CLIENT_INSTANCE_NAME} \ --image-family=ubuntu-1604-lts \ --image-project=ubuntu-os-cloud \ --tags=mysql-client \ --zone=${CLIENT_INSTANCE_ZONE} \ --boot-disk-size=10GB \ --metadata="ILB_IP=${ILB_IP}"
Instalar y configurar DRBD
En esta sección, instalarás y configurarás los paquetes de DRBD en las instancias database1 y database2 y, a continuación, iniciarás la replicación de DRBD de database1 a database2.
Configurar DRBD en database1
En la Google Cloud consola, ve a la página Instancias de VM:
En la fila de la instancia
.database1, haz clic en SSH para conectarte a la instancia.Crea un archivo para obtener y almacenar metadatos de instancias en variables de entorno:
sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOFCarga las variables de metadatos del archivo:
source ~/.varsrcFormatea el disco de datos:
sudo bash -c "mkfs.ext4 -m 0 -F -E \ lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"Para obtener una descripción detallada de las opciones de
mkfs.ext4, consulta la página del manual de mkfs.ext4.Instala DRBD:
sudo apt -y install drbd8-utilsCrea el archivo de configuración de DRBD:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'Crea un archivo de recursos de DRBD:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on database1 { disk /dev/sdb; address 10.140.0.2:7789; } on database2 { disk /dev/sdb; address 10.140.0.3:7789; } } EOF"Carga el módulo del kernel de DRBD:
sudo modprobe drbdBorra el contenido del disco
/dev/sdb:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024Crea el recurso DRBD
r0:sudo drbdadm create-md r0Activa DRBD:
sudo drbdadm up r0Inhabilita DRBD cuando se inicie el sistema para que el software de gestión de recursos del clúster inicie todos los servicios necesarios en el orden correcto:
sudo update-rc.d drbd disable
Configurar DRBD en database2
Ahora, instala y configura los paquetes DRBD en la instancia database2.
- Conéctate a la instancia
database2mediante SSH. Crea un archivo
.varsrcpara obtener y almacenar metadatos de instancias en variables de entorno:sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOFCarga las variables de metadatos del archivo:
source ~/.varsrcFormatea el disco de datos:
sudo bash -c "mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"Instala los paquetes de DRBD:
sudo apt -y install drbd8-utilsCrea el archivo de configuración de DRBD:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'Crea un archivo de recursos de DRBD:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on ${DATABASE1_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE1_INSTANCE_IP}:7789; } on ${DATABASE2_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE2_INSTANCE_IP}:7789; } } EOF"Carga el módulo del kernel de DRBD:
sudo modprobe drbdBorra el
/dev/sdbdisco:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024Crea el recurso DRBD
r0:sudo drbdadm create-md r0Activa DRBD:
sudo drbdadm up r0Inhabilita DRBD cuando se inicie el sistema para que el software de gestión de recursos del clúster inicie todos los servicios necesarios en el orden correcto:
sudo update-rc.d drbd disable
Inicia la replicación de DRBD de database1 a database2
- Conéctate a la instancia
database1mediante SSH. Sobrescribe todos los recursos
r0en el nodo principal:sudo drbdadm -- --overwrite-data-of-peer primary r0 sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/drbd0Verifica el estado de DRBD:
sudo cat /proc/drbd | grep ============La salida tiene este aspecto:
[===================>] sync'ed:100.0% (208/307188)M
Montar
/dev/drbden/srv:sudo mount -o discard,defaults /dev/drbd0 /srv
Instalar MySQL y Pacemaker
En esta sección, instalarás MySQL y Pacemaker en cada instancia.
Instalar MySQL en database1
- Conéctate a la instancia
database1mediante SSH. Actualiza el repositorio APT con las definiciones del paquete MySQL 5.6:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'Añade las claves GPG al archivo
repository.srvde APT:wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysqlActualiza la lista de paquetes:
sudo apt updateInstala el servidor MySQL:
sudo apt -y install mysql-serverCuando se te pida una contraseña, introduce
DRBDha2.Detén el servidor MySQL:
sudo /etc/init.d/mysql stopCrea el archivo de configuración de MySQL:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'Crea un directorio temporal para el servidor MySQL (configurado en
mysql.conf):sudo mkdir /srv/tmp sudo chmod 1777 /srv/tmpMueve todos los datos de MySQL al directorio de DRBD
/srv/mysql:sudo mv /var/lib/mysql /srv/mysqlVincula
/var/lib/mysqlcon/srv/mysqlen el volumen de almacenamiento replicado de DRBD:sudo ln -s /srv/mysql /var/lib/mysqlCambia el propietario de
/srv/mysqla un proceso demysql:sudo chown -R mysql:mysql /srv/mysqlElimina los datos iniciales de
InnoDBpara asegurarte de que el disco esté lo más limpio posible:sudo bash -c "cd /srv/mysql && rm ibdata1 && rm ib_logfile*"InnoDB es un motor de almacenamiento para el sistema de gestión de bases de datos MySQL.
Inicia MySQL:
sudo /etc/init.d/mysql startConcede acceso al usuario root para las conexiones remotas con el fin de probar la implementación más adelante:
mysql -uroot -pDRBDha2 -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'DRBDha2' WITH GRANT OPTION;"Inhabilita el inicio automático de MySQL, que se encarga de la gestión de recursos del clúster:
sudo update-rc.d -f mysql disable
Instala Pacemaker en database1
Cargue las variables de metadatos del archivo
.varsrcque ha creado anteriormente:source ~/.varsrcDetén el servidor MySQL:
sudo /etc/init.d/mysql stopInstalar Pacemaker:
sudo apt -y install pcsHabilita
pcsd,corosyncypacemakeral iniciar el sistema en la instancia principal:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enableConfigura
corosyncpara que se inicie antes quepacemaker:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10Define la contraseña del usuario del clúster como
haCLUSTER3para la autenticación:sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"Ejecuta la secuencia de comandos
corosync-keygenpara generar una clave de autorización de clúster de 128 bits y escribirla en/etc/corosync/authkey:sudo corosync-keygen -lCopia
authkeyen la instanciadatabase2. Cuando se te pida una contraseña, pulsaEnter:sudo chmod 444 /etc/corosync/authkey gcloud beta compute scp /etc/corosync/authkey ${DATABASE2_INSTANCE_NAME}:~/authkey --zone=${DATABASE2_INSTANCE_ZONE} --internal-ip sudo chmod 400 /etc/corosync/authkeyCrea un archivo de configuración de clúster de Corosync:
sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"La sección
totemconfigura el protocolo Totem para una comunicación fiable. Corosync usa esta comunicación para controlar la pertenencia al clúster y especifica cómo deben comunicarse entre sí los miembros del clúster.Los ajustes importantes de la configuración son los siguientes:
transport: especifica el modo de unidifusión (udpu).Bindnetaddr: especifica la dirección de red a la que se vincula Corosync.nodelist: define los nodos del clúster y cómo se puede acceder a ellos. En este caso, los nodosdatabase1ydatabase2.quorum/two_node: de forma predeterminada, en un clúster de dos nodos, ningún nodo adquirirá un quórum. Para anularlo, especifique el valor "1" paratwo_nodeen la secciónquorum.
Esta configuración te permite configurar el clúster y prepararlo para cuando añadas un tercer nodo que actuará como dispositivo de quórum.
Crea el directorio de servicio de
corosync:sudo mkdir -p /etc/corosync/service.dConfigura
corosyncpara que detecte el marcapasos:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'Habilita el servicio
corosyncde forma predeterminada:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'Reinicia los servicios
corosyncypacemaker:sudo service corosync restart sudo service pacemaker restartInstala el paquete del dispositivo de quórum de Corosync:
sudo apt -y install corosync-qdeviceInstala un script de shell para gestionar los eventos de fallo de DRBD:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.log
Instalar MySQL en database2
- Conéctate a la instancia
database2mediante SSH. Actualiza el repositorio APT con el paquete MySQL 5.6:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'Añade las claves GPG al repositorio de APT:
wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysqlActualiza la lista de paquetes:
sudo apt updateInstala el servidor MySQL:
sudo apt -y install mysql-serverCuando se te pida una contraseña, introduce
DRBDha2.Detén el servidor MySQL:
sudo /etc/init.d/mysql stopCrea el archivo de configuración de MySQL:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'Elimina los datos de
/var/lib/mysqly añade un enlace simbólico al destino del punto de montaje del volumen DRBD replicado. El volumen de DRBD (/dev/drbd0) se montará en/srvsolo cuando se produzca una conmutación por error.sudo rm -rf /var/lib/mysql sudo ln -s /srv/mysql /var/lib/mysqlInhabilita el inicio automático de MySQL, que se encarga de la gestión de recursos del clúster:
sudo update-rc.d -f mysql disable
Instalar Pacemaker en database2
Cargue las variables de metadatos del archivo
.varsrc:source ~/.varsrcInstalar Pacemaker:
sudo apt -y install pcsMueve el archivo
authkeyde Corosync que has copiado antes a/etc/corosync/:sudo mv ~/authkey /etc/corosync/ sudo chown root: /etc/corosync/authkey sudo chmod 400 /etc/corosync/authkeyHabilita
pcsd,corosyncypacemakeral iniciar el sistema en la instancia de espera:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enableConfigura
corosyncpara que se inicie antes quepacemaker:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10Define la contraseña del usuario del clúster para la autenticación. La contraseña es la misma (
haCLUSTER3) que usaste para la instancia dedatabase1.sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"Crea el archivo de configuración
corosync:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"Crea el directorio de servicio de Corosync:
sudo mkdir /etc/corosync/service.dConfigura
corosyncpara que detecte el marcapasos:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'Habilita el servicio
corosyncde forma predeterminada:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'Reinicia los servicios
corosyncypacemaker:sudo service corosync restart sudo service pacemaker restartInstala el paquete del dispositivo de quórum de Corosync:
sudo apt -y install corosync-qdeviceInstala un script de shell para gestionar los eventos de fallo de DRBD:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.logComprueba el estado del clúster de Corosync:
sudo corosync-cmapctl | grep "members...ip"La salida tiene este aspecto:
runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(10.140.0.2) runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(10.140.0.3)
Iniciar el clúster
- Conéctate a la instancia
database2mediante SSH. Cargue las variables de metadatos del archivo
.varsrc:source ~/.varsrcAutentícate en los nodos del clúster:
sudo pcs cluster auth --name mysql_cluster ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} -u hacluster -p haCLUSTER3Inicia el clúster:
sudo pcs cluster start --allVerifica el estado del clúster:
sudo pcs statusLa salida tiene este aspecto:
Cluster name: mysql_cluster WARNING: no stonith devices and stonith-enabled is not false Stack: corosync Current DC: database2 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sat Nov 3 07:24:53 2018 Last change: Sat Nov 3 07:17:17 2018 by hacluster via crmd on database2 2 nodes configured 0 resources configured Online: [ database1 database2 ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Configurar Pacemaker para gestionar los recursos del clúster
A continuación, configura Pacemaker con los recursos DRBD, de disco, MySQL y de quórum.
- Conéctate a la instancia
database1mediante SSH. Usa la utilidad Pacemaker
pcspara poner en cola varios cambios en un archivo y, más adelante, enviar esos cambios a la base de información del clúster (CIB) de forma atómica:sudo pcs cluster cib clust_cfgInhabilita STONITH, porque implementarás el dispositivo de quórum más adelante:
sudo pcs -f clust_cfg property set stonith-enabled=falseInhabilita los ajustes relacionados con el quórum. Configurarás el nodo del dispositivo de quórum más adelante.
sudo pcs -f clust_cfg property set no-quorum-policy=stopPara evitar que Pacemaker vuelva a mover los recursos después de una recuperación, haz lo siguiente:
sudo pcs -f clust_cfg resource defaults resource-stickiness=200Crea el recurso DRBD en el clúster:
sudo pcs -f clust_cfg resource create mysql_drbd ocf:linbit:drbd \ drbd_resource=r0 \ op monitor role=Master interval=110 timeout=30 \ op monitor role=Slave interval=120 timeout=30 \ op start timeout=120 \ op stop timeout=60Asegúrate de que solo se asigne un rol principal al recurso DRBD:
sudo pcs -f clust_cfg resource master primary_mysql mysql_drbd \ master-max=1 master-node-max=1 \ clone-max=2 clone-node-max=1 \ notify=trueCrea el recurso del sistema de archivos para montar el disco DRBD:
sudo pcs -f clust_cfg resource create mystore_FS Filesystem \ device="/dev/drbd0" \ directory="/srv" \ fstype="ext4"Configura el clúster para que coloque el recurso DRBD junto con el recurso de disco en la misma máquina virtual:
sudo pcs -f clust_cfg constraint colocation add mystore_FS with primary_mysql INFINITY with-rsc-role=MasterConfigura el clúster para que active el recurso de disco solo después de que se haya promovido el primario de DRBD:
sudo pcs -f clust_cfg constraint order promote primary_mysql then start mystore_FSCrea un servicio MySQL:
sudo pcs -f clust_cfg resource create mysql_service ocf:heartbeat:mysql \ binary="/usr/bin/mysqld_safe" \ config="/etc/mysql/my.cnf" \ datadir="/var/lib/mysql" \ pid="/var/run/mysqld/mysql.pid" \ socket="/var/run/mysqld/mysql.sock" \ additional_parameters="--bind-address=0.0.0.0" \ op start timeout=60s \ op stop timeout=60s \ op monitor interval=20s timeout=30sConfigura el clúster para colocar el recurso de MySQL junto con el recurso de disco en la misma VM:
sudo pcs -f clust_cfg constraint colocation add mysql_service with mystore_FS INFINITYAsegúrate de que el sistema de archivos DRBD preceda al servicio MySQL en el orden de inicio:
sudo pcs -f clust_cfg constraint order mystore_FS then mysql_serviceCrea el agente de alerta y añade el parche al archivo de registro como destinatario:
sudo pcs -f clust_cfg alert create id=drbd_cleanup_file description="Monitor DRBD events and perform post cleanup" path=/var/lib/pacemaker/drbd_cleanup.sh sudo pcs -f clust_cfg alert recipient add drbd_cleanup_file id=logfile value=/var/log/pacemaker_drbd_file.logConfirma los cambios en el clúster:
sudo pcs cluster cib-push clust_cfgVerifica que todos los recursos estén online:
sudo pcs statusLa salida tiene este aspecto:
Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1
Configurar un dispositivo de quórum
- Conéctate a la instancia
qdevicemediante SSH. Instala
pcsycorosync-qnetd:sudo apt update && sudo apt -y install pcs corosync-qnetdInicia el daemon del sistema de configuración de Pacemaker o Corosync (
pcsd) service y habilítalo al iniciar el sistema:sudo service pcsd start sudo update-rc.d pcsd enableDefine la contraseña del usuario del clúster (
haCLUSTER3) para la autenticación:sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"Comprueba el estado del dispositivo de quorum:
sudo pcs qdevice status net --fullLa salida tiene este aspecto:
QNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytes
Configurar los ajustes del dispositivo de quórum en database1
- Conéctate al nodo
database1mediante SSH. Cargue las variables de metadatos del archivo
.varsrc:source ~/.varsrcAutentica el nodo del dispositivo de quórum del clúster:
sudo pcs cluster auth --name mysql_cluster ${QUORUM_INSTANCE_NAME} -u hacluster -p haCLUSTER3Añade el dispositivo de quorum al clúster. Usa el algoritmo
ffsplit, que asegura que el nodo activo se decida en función del 50% de los votos o más:sudo pcs quorum device add model net host=${QUORUM_INSTANCE_NAME} algorithm=ffsplitAñade el ajuste de quórum a
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"Reinicia el servicio
corosyncpara volver a cargar el nuevo ajuste del dispositivo de quórum:sudo service corosync restartInicia el daemon del dispositivo de quórum
corosyncy actívalo al inicio del sistema:sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
Configurar los ajustes del dispositivo de quórum en database2
- Conéctate al nodo
database2mediante SSH. Cargue las variables de metadatos del archivo
.varsrc:source ~/.varsrcAñadir un ajuste de quórum a
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"Reinicia el servicio
corosyncpara volver a cargar el nuevo ajuste del dispositivo de quórum:sudo service corosync restartInicia el daemon del dispositivo de quórum de Corosync y configúralo para que se inicie al arrancar el sistema:
sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
Verificar el estado del clúster
El siguiente paso es verificar que los recursos del clúster estén online.
- Conéctate a la instancia
database1mediante SSH. Verifica el estado del clúster:
sudo pcs statusLa salida tiene este aspecto:
Cluster name: mysql_cluster Stack: corosync Current DC: database1 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sun Nov 4 01:49:18 2018 Last change: Sat Nov 3 15:48:21 2018 by root via cibadmin on database1 2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledMostrar el estado del quórum:
sudo pcs quorum statusLa salida tiene este aspecto:
Quorum information ------------------ Date: Sun Nov 4 01:48:25 2018 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/24 Quorate: Yes Votequorum information ---------------------- Expected votes: 3 Highest expected: 3 Total votes: 3 Quorum: 2 Flags: Quorate Qdevice Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 A,V,NMW database1 (local) 2 1 A,V,NMW database2 0 1 QdeviceMuestra el estado del dispositivo de quórum:
sudo pcs quorum device statusLa salida tiene este aspecto:
Qdevice information ------------------- Model: Net Node ID: 1 Configured node list: 0 Node ID = 1 1 Node ID = 2 Membership node list: 1, 2 Qdevice-net information ---------------------- Cluster name: mysql_cluster QNetd host: qdevice:5403 Algorithm: Fifty-Fifty split Tie-breaker: Node with lowest node ID State: Connected
Configurar un balanceador de carga interno como IP de clúster
Abre Cloud Shell:
Crea un grupo de instancias sin gestionar y añade la instancia
database1:gcloud compute instance-groups unmanaged create ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --description="${DATABASE1_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --instances=${DATABASE1_INSTANCE_NAME}Crea un grupo de instancias sin gestionar y añade la instancia
database2:gcloud compute instance-groups unmanaged create ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --description="${DATABASE2_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --instances=${DATABASE2_INSTANCE_NAME}Crea una comprobación del estado para
port 3306:gcloud compute health-checks create tcp mysql-backend-healthcheck \ --port 3306Crea un servicio backend interno regional:
gcloud compute backend-services create mysql-ilb \ --load-balancing-scheme internal \ --region ${CLUSTER_REGION} \ --health-checks mysql-backend-healthcheck \ --protocol tcpAñade los dos grupos de instancias como backends al servicio de backend:
gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE1_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE1_INSTANCE_ZONE} \ --region ${CLUSTER_REGION} gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE2_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE2_INSTANCE_ZONE} \ --region ${CLUSTER_REGION}Crea una regla de reenvío para el balanceador de carga:
gcloud compute forwarding-rules create mysql-ilb-forwarding-rule \ --load-balancing-scheme internal \ --ports 3306 \ --network default \ --subnet default \ --region ${CLUSTER_REGION} \ --address ${ILB_IP} \ --backend-service mysql-ilbCrea una regla de cortafuegos para permitir una comprobación del estado de un balanceador de carga interno:
gcloud compute firewall-rules create allow-ilb-healthcheck \ --direction=INGRESS --network=default \ --action=ALLOW --rules=tcp:3306 \ --source-ranges=130.211.0.0/22,35.191.0.0/16 --target-tags=mysqlPara comprobar el estado de tu balanceador de carga, ve a la página Balanceo de carga de la Google Cloud consola.
Haz clic en
mysql-ilb:
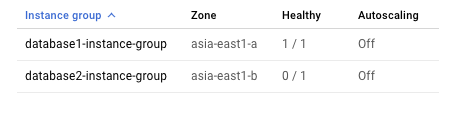
Como el clúster solo permite que se ejecute una instancia de MySQL en un momento dado, solo una instancia está en buen estado desde la perspectiva del balanceador de carga interno.
Conectarse al clúster desde el cliente MySQL
- Conéctate a la instancia
mysql-clientmediante SSH. Actualiza las definiciones de los paquetes:
sudo apt-get updateInstala el cliente de MySQL:
sudo apt-get install -y mysql-clientCrea un archivo de secuencia de comandos que cree y rellene una tabla con datos de ejemplo:
cat <<EOF > db_creation.sql CREATE DATABASE source_db; use source_db; CREATE TABLE source_table ( id BIGINT NOT NULL AUTO_INCREMENT, timestamp timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, event_data float DEFAULT NULL, PRIMARY KEY (id) ); DELIMITER $$ CREATE PROCEDURE simulate_data() BEGIN DECLARE i INT DEFAULT 0; WHILE i < 100 DO INSERT INTO source_table (event_data) VALUES (ROUND(RAND()*15000,2)); SET i = i + 1; END WHILE; END$$ DELIMITER ; CALL simulate_data() EOFCrea la tabla:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -u root -pDRBDha2 "-h${ILB_IP}" < db_creation.sql
Probar el clúster
Para probar la capacidad de alta disponibilidad del clúster implementado, puedes realizar las siguientes pruebas:
- Cierra la instancia
database1para comprobar si la base de datos principal puede conmutar por error a la instanciadatabase2. - Inicia la instancia
database1para ver sidatabase1puede volver a unirse al clúster correctamente. - Cierra la instancia
database2para comprobar si la base de datos principal puede conmutar por error a la instanciadatabase1. - Inicia la instancia
database2para ver sidatabase2puede volver a unirse al clúster correctamente y si la instanciadatabase1sigue teniendo el rol principal. - Crea una partición de red entre
database1ydatabase2para simular un problema de cerebro dividido.
Abre Cloud Shell:
Detén la instancia
database1:gcloud compute instances stop ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}Comprueba el estado del clúster:
gcloud compute ssh ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --command="sudo pcs status"La salida tiene el siguiente aspecto. Verifica que los cambios de configuración que has realizado se hayan aplicado:
2 nodes configured 4 resources configured Online: [ database2 ] OFFLINE: [ database1 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Stopped: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledInicia la instancia
database1:gcloud compute instances start ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}Comprueba el estado del clúster:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"La salida tiene este aspecto:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Slaves: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledDetén la instancia
database2:gcloud compute instances stop ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}Comprueba el estado del clúster:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"La salida tiene este aspecto:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledInicia la instancia
database2:gcloud compute instances start ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}Comprueba el estado del clúster:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"La salida tiene este aspecto:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledCrea una partición de red entre
database1ydatabase2:gcloud compute firewall-rules create block-comms \ --description="no MySQL communications" \ --action=DENY \ --rules=all \ --source-tags=mysql \ --target-tags=mysql \ --priority=800Al cabo de un par de minutos, comprueba el estado del clúster. Fíjate en cómo
database1mantiene su rol principal, ya que la política de quórum es el nodo con el ID más bajo en primer lugar en caso de partición de red. Mientras tanto, el servicio MySQLdatabase2se detiene. Este mecanismo de quórum evita el problema de cerebro dividido cuando se produce la partición de la red.gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"La salida tiene este aspecto:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1Elimina la regla de cortafuegos de la red para quitar la partición de la red. (Pulsa
Ycuando se te solicite).gcloud compute firewall-rules delete block-commsVerifica que el estado del clúster haya vuelto a la normalidad:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"La salida tiene este aspecto:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1Conéctate a la instancia
mysql-clientmediante SSH.En tu shell, consulta la tabla que has creado anteriormente:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -uroot "-h${ILB_IP}" -pDRBDha2 -e "select * from source_db.source_table LIMIT 10"La salida debe mostrar 10 registros con el siguiente formato para verificar la coherencia de los datos en el clúster:
+----+---------------------+------------+ | id | timestamp | event_data | +----+---------------------+------------+ | 1 | 2018-11-27 21:00:09 | 1279.06 | | 2 | 2018-11-27 21:00:09 | 4292.64 | | 3 | 2018-11-27 21:00:09 | 2626.01 | | 4 | 2018-11-27 21:00:09 | 252.13 | | 5 | 2018-11-27 21:00:09 | 8382.64 | | 6 | 2018-11-27 21:00:09 | 11156.8 | | 7 | 2018-11-27 21:00:09 | 636.1 | | 8 | 2018-11-27 21:00:09 | 14710.1 | | 9 | 2018-11-27 21:00:09 | 11642.1 | | 10 | 2018-11-27 21:00:09 | 14080.3 | +----+---------------------+------------+
Secuencia de conmutación por error
Si el nodo principal del clúster deja de funcionar, la secuencia de conmutación por error será la siguiente:
- Tanto el dispositivo de quórum como el nodo de reserva pierden la conectividad con el nodo principal.
- El dispositivo de quórum vota por el nodo de espera y el nodo de espera vota por sí mismo.
- El nodo en espera adquiere el quórum.
- El nodo de reserva se convierte en principal.
- El nuevo nodo principal hace lo siguiente:
- Promueve DRBD a primario
- Monta el disco de datos de MySQL desde DRBD.
- Inicia MySQL.
- Se pone en buen estado para el balanceador de carga.
- El balanceador de carga empieza a enviar tráfico al nuevo nodo principal.