
ネットワーク帯域幅が大きいほど、GPU インスタンスのパフォーマンスが向上し、Compute Engine で実行される分散ワークロードをサポートできます。
Compute Engine で GPU がアタッチされたインスタンスで使用可能な最大ネットワーク帯域幅は次のとおりです。
- A4X アクセラレータ最適化インスタンスでは、マシンタイプに応じて最大 2,000 Gbps の最大ネットワーク帯域幅を使用できます。
- A4 および A3 アクセラレータ最適化インスタンスでは、マシンタイプに応じて最大 3,600 Gbps の最大ネットワーク帯域幅を使用できます。
- G4 アクセラレータ最適化インスタンスでは、マシンタイプに応じて最大 400 Gbps の最大ネットワーク帯域幅を使用できます。
- A2 および G2 アクセラレータ最適化インスタンスでは、マシンタイプに応じて最大 100 Gbps の最大ネットワーク帯域幅を使用できます。
- P100、P4 GPU が接続された N1 汎用インスタンスの場合、32 Gbps の最大ネットワーク帯域幅を使用できます。これは、GPU が接続されていない N1 インスタンスで使用できる最大レートと類似しています。ネットワーク帯域幅についての詳細は、下り(外向き)最大データ通信速度を参照してください。
- T4 および V100 GPU が接続された N1 汎用インスタンスの場合、GPU と vCPU 数の組み合わせに基づいて、最大 100 Gbps の最大ネットワーク帯域幅を使用できます。
ネットワーク帯域幅と NIC の配置を確認する
次のセクションでは、各 GPU マシンタイプのネットワークの手配と帯域幅速度を確認します。
A4X マシンタイプ
A4X マシンタイプには NVIDIA GB200 Superchips がアタッチされています。これらの Superchip には NVIDIA B200 GPU が搭載されています。
このマシンタイプには、4 つの NVIDIA ConnectX-7(CX-7)ネットワーク インターフェース カード(NIC)と 2 つの Titanium NIC があります。4 つの CX-7 NIC は、合計 1,600 Gbps のネットワーク帯域幅を提供します。これらの CX-7 NIC は、高帯域幅の GPU 間通信専用であり、パブリック インターネット アクセスなどの他のネットワーキングのニーズには使用できません。2 つの Titanium NIC はスマート NIC で、汎用ネットワーキング要件に 400 Gbps のネットワーク帯域幅を追加します。これらのネットワーク インターフェース カードを組み合わせると、これらのマシンに合計 2,000 Gbps の最大ネットワーク帯域幅が提供されます。
A4X は、NVIDIA GB200 NVL72 ラックスケール アーキテクチャに基づくエクサスケール プラットフォームであり、NVIDIA Hopper GPU と NVIDIA Grace CPU を高帯域幅の NVIDIA NVLink チップ間(C2C)インターコネクトで接続する NVIDIA Grace Hopper Superchip アーキテクチャを導入しています。
A4X ネットワーキング アーキテクチャは、レール整列型の設計を使用しています。これは、1 つの Compute Engine インスタンスの対応するネットワーク カードが別のネットワーク カードに接続されるトポロジです。各インスタンスの 4 つの CX-7 NIC は、4 方向のレール整列型ネットワーク トポロジで物理的に分離されているため、A4X は 72 個の GPU のグループでスケールアウトし、単一の非ブロッキング クラスタで数千個の GPU までスケールアウトできます。このハードウェア統合型のアプローチにより、大規模な分散ワークロードに不可欠な、予測可能な低レイテンシのパフォーマンスが実現します。
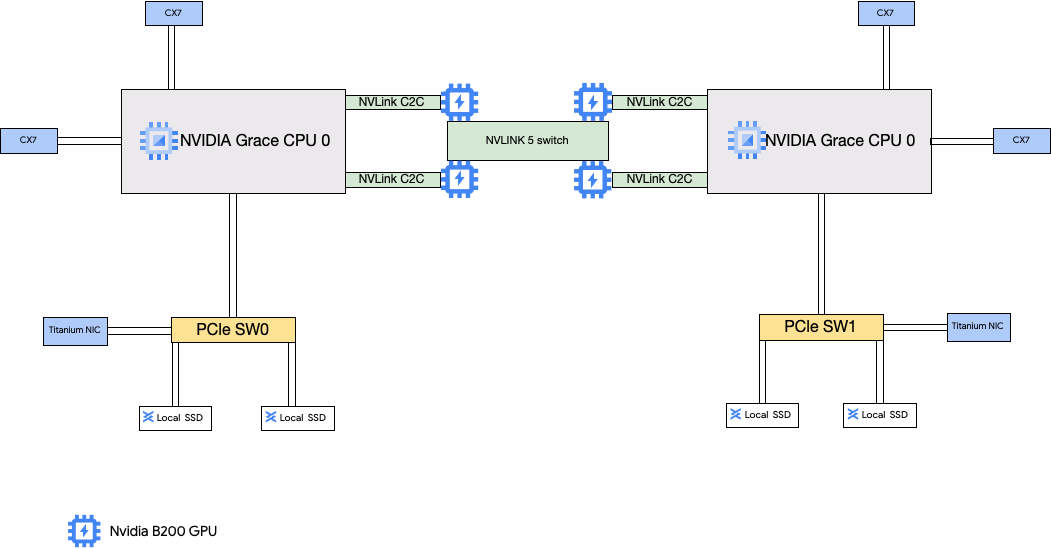
これらの複数の NIC を使用するには、次のように 3 つの Virtual Private Cloud ネットワークを作成する必要があります。
- 2 つの VPC ネットワーク: 各 gVNIC は異なる VPC ネットワークに接続する必要があります
- RDMA ネットワーク プロファイルを含む 1 つの VPC ネットワーク: 4 つの CX-7 NIC すべてが同じ VPC ネットワークを共有します。
これらのネットワークを設定するには、AI Hypercomputer のドキュメントの VPC ネットワークを作成するをご覧ください。
| アタッチされた NVIDIA GB200 Grace Blackwell Superchip | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | アタッチされたローカル SSD(GiB) | 物理 NIC の数 | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM3e) |
a4x-highgpu-4g |
140 | 884 | 12,000 | 6 | 2,000 | 4 | 744 |
1vCPU は、利用可能な CPU プラットフォームのいずれかで単一のハードウェア ハイパースレッドとして実装されます。
2 最大下り(外向き)帯域幅は許容数を超えることはできません。実際の下り(外向き)帯域幅は、宛先 IP アドレスやその他の要因によって異なります。ネットワーク帯域幅の詳細については、ネットワーク帯域幅をご覧ください。
3 GPU メモリは GPU デバイスのメモリであり、データの一時的な保存に使用できます。これはインスタンスのメモリとは別のものであり、グラフィックを多用するワークロードの高帯域幅の需要に対応できるように設計されています。
A4 および A3 Ultra マシンタイプ
A4 マシンタイプには NVIDIA B200 GPU がアタッチされ、A3 Ultra マシンタイプには NVIDIA H200 GPU がアタッチされます。
これらのマシンタイプには、8 つの NVIDIA ConnectX-7(CX-7)ネットワーク インターフェース カード(NIC)と 2 つの Google Virtual NIC(gVNIC)が用意されています。8 つの CX-7 NIC は、合計 3,200 Gbps のネットワーク帯域幅を提供します。これらの NIC は、高帯域幅の GPU 間通信専用であり、パブリック インターネット アクセスなどの他のネットワーキングのニーズには使用できません。次の図に示すように、各 CX-7 NIC は 1 つの GPU と協調し、不均一メモリアクセス(NUMA)を最適化します。8 つの GPU はすべて、それらを接続するオールツーオール NVLink ブリッジを使用して相互に高速に通信できます。他の 2 つの gVNIC ネットワーク インターフェース カードはスマート NIC で、汎用ネットワーキング要件に 400 Gbps のネットワーク帯域幅を追加します。これらのネットワーク インターフェース カードを組み合わせると、これらのマシンに合計 3,600 Gbps の最大ネットワーク帯域幅が提供されます。
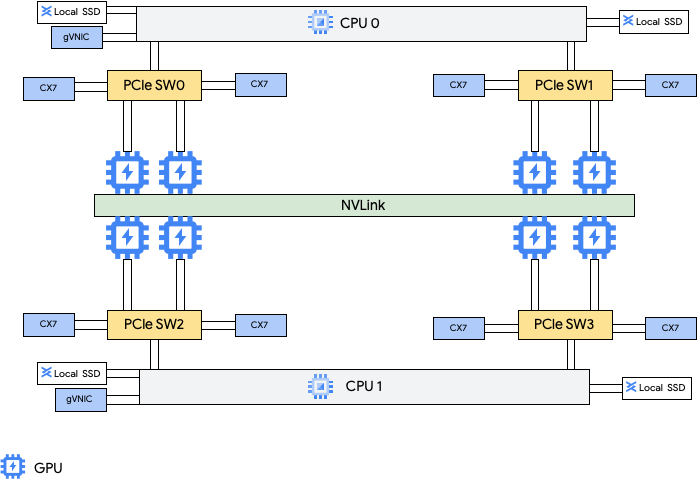
これらの複数の NIC を使用するには、次のように 3 つの Virtual Private Cloud ネットワークを作成する必要があります。
- 2 つの通常の VPC ネットワーク: 各 gVNIC は異なる VPC ネットワークにアタッチする必要があります。
- 1 つの RoCE VPC ネットワーク: 8 つの CX-7 NIC すべてが同じ RoCE VPC ネットワークを共有します。
これらのネットワークを設定するには、AI Hypercomputer のドキュメントの VPC ネットワークを作成するをご覧ください。
A4 VM
| アタッチされた NVIDIA B200 Blackwell GPU | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | アタッチされたローカル SSD(GiB) | 物理 NIC の数 | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM3e) |
a4-highgpu-8g |
224 | 3,968 | 12,000 | 10 | 3,600 | 8 | 1,440 |
1vCPU は、利用可能な CPU プラットフォームのいずれかで単一のハードウェア ハイパースレッドとして実装されます。
2 最大下り(外向き)帯域幅は許容数を超えることはできません。実際の下り(外向き)帯域幅は、宛先 IP アドレスやその他の要因によって異なります。ネットワーク帯域幅の詳細については、ネットワーク帯域幅をご覧ください。
3 GPU メモリは GPU デバイスのメモリであり、データの一時的な保存に使用できます。これはインスタンスのメモリとは別のものであり、グラフィックを多用するワークロードの高帯域幅の需要に対応できるように設計されています。
A3 Ultra VM
| アタッチされた NVIDIA H200 GPU | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | アタッチされたローカル SSD(GiB) | 物理 NIC の数 | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM3e) |
a3-ultragpu-8g |
224 | 2,952 | 12,000 | 10 | 3,600 | 8 | 1128 |
1vCPU は、利用可能な CPU プラットフォームのいずれかで単一のハードウェア ハイパースレッドとして実装されます。
2 最大下り(外向き)帯域幅は許容数を超えることはできません。実際の下り(外向き)帯域幅は、宛先 IP アドレスやその他の要因によって異なります。ネットワーク帯域幅の詳細については、ネットワーク帯域幅をご覧ください。
3 GPU メモリは GPU デバイスのメモリであり、データの一時的な保存に使用できます。これはインスタンスのメモリとは別のものであり、グラフィックを多用するワークロードの高帯域幅の需要に対応できるように設計されています。
A3 Mega、High、Edge マシンタイプ
これらのマシンタイプには、H100 GPU がアタッチされています。これらのマシンタイプには、固定の GPU 数、vCPU 数、メモリサイズが設定されています。
- 単一 NIC A3 VM: 1~4 個の GPU がアタッチされている A3 VM では、単一の物理ネットワーク インターフェース カード(NIC)のみを使用できます。
- マルチ NIC A3 VM: 8 個の GPU がアタッチされている A3 VM では、複数の物理 NIC を使用できます。これらの A3 マシンタイプでは、NIC が Peripheral Component Interconnect Express(PCIe)バス上で次のように配置されます。
- A3 Mega マシンタイプ: NIC を 8+1 で配置できます。この構成では、8 つの NIC が同じ PCIe バスを共有し、1 つの NIC が別の PCIe バス上に配置されます。
- A3 High マシンタイプ: NIC を 4+1 で配置できます。この構成では、4 つの NIC が同じ PCIe バスを共有し、1 つの NIC が別の PCIe バス上に配置されます。
- マシンタイプが A3 Edge マシンタイプの場合: NIC を 4+1 で配置できます。この構成では、4 つの NIC が同じ PCIe バスを共有し、1 つの NIC が別の PCIe バス上に配置されます。これらの 5 つの NIC は、VM ごとに合計 400 Gbps のネットワーク帯域幅を提供します。
同じ PCIe バスを共有する NIC のそれぞれに対し、2 つの NVIDIA H100 GPU の不均一メモリアクセス(NUMA)アライメントが使用されます。これらの NIC は、専用の高帯域幅 GPU 間通信に最適です。他のネットワーク要件には、別の PCIe バス上にある物理 NIC で適切に対応できます。A3 High VM と A3 Edge VM のネットワーキングを設定する方法については、ジャンボ フレーム MTU ネットワークを設定するをご覧ください。
A3 Mega
| アタッチされた NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | アタッチされたローカル SSD(GiB) | 物理 NIC の数 | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM3) |
a3-megagpu-8g |
208 | 1,872 | 6,000 | 9 | 1,800 | 8 | 640 |
A3 High
| アタッチされた NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | アタッチされたローカル SSD(GiB) | 物理 NIC の数 | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM3) |
a3-highgpu-1g |
26 | 234 | 750 | 1 | 25 | 1 | 80 |
a3-highgpu-2g |
52 | 468 | 1,500 | 1 | 50 | 2 | 160 |
a3-highgpu-4g |
104 | 936 | 3,000 | 1 | 100 | 4 | 320 |
a3-highgpu-8g |
208 | 1,872 | 6,000 | 5 | 1,000 | 8 | 640 |
A3 Edge
| アタッチされた NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | アタッチされたローカル SSD(GiB) | 物理 NIC の数 | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM3) |
a3-edgegpu-8g |
208 | 1,872 | 6,000 | 5 |
|
8 | 640 |
1vCPU は、利用可能な CPU プラットフォームのいずれかで単一のハードウェア ハイパースレッドとして実装されます。
2 最大下り(外向き)帯域幅は許容数を超えることはできません。実際の下り(外向き)帯域幅は、宛先 IP アドレスやその他の要因によって異なります。ネットワーク帯域幅の詳細については、ネットワーク帯域幅をご覧ください。
3 GPU メモリは GPU デバイスのメモリであり、データの一時的な保存に使用できます。これはインスタンスのメモリとは別のものであり、グラフィックを多用するワークロードの高帯域幅の需要に対応できるように設計されています。
A2 マシンタイプ
各 A2 マシンタイプには、一定数の NVIDIA A100 40 GB または NVIDIA A100 80 GB GPU がアタッチされています。各マシンタイプには、固定の数の vCPU と固定のサイズのメモリも搭載されます。
A2 マシンシリーズは次の 2 つのタイプで用意されています。
- A2 Ultra: A100 80 GB GPU とローカル SSD ディスクがアタッチされるマシンタイプです。
- A2 Standard: A100 40 GB GPU がアタッチされるマシンタイプです。
A2 Ultra
| アタッチされた NVIDIA A100 80GB GPU | ||||||
|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | アタッチされたローカル SSD(GiB) | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM2e) |
a2-ultragpu-1g |
12 | 170 | 375 | 24 | 1 | 80 |
a2-ultragpu-2g |
24 | 340 | 750 | 32 | 2 | 160 |
a2-ultragpu-4g |
48 | 680 | 1,500 | 50 | 4 | 320 |
a2-ultragpu-8g |
96 | 1,360 | 3,000 | 100 | 8 | 640 |
A2 標準
| アタッチされた NVIDIA A100 40GB GPU | ||||||
|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | サポート対象のローカル SSD | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3 (GB HBM2) |
a2-highgpu-1g |
12 | 85 | はい | 24 | 1 | 40 |
a2-highgpu-2g |
24 | 170 | はい | 32 | 2 | 80 |
a2-highgpu-4g |
48 | 340 | はい | 50 | 4 | 160 |
a2-highgpu-8g |
96 | 680 | はい | 100 | 8 | 320 |
a2-megagpu-16g |
96 | 1,360 | はい | 100 | 16 | 640 |
1vCPU は、利用可能な CPU プラットフォームのいずれかで単一のハードウェア ハイパースレッドとして実装されます。
2 最大下り(外向き)帯域幅は許容数を超えることはできません。実際の下り(外向き)帯域幅は、宛先 IP アドレスやその他の要因によって異なります。ネットワーク帯域幅の詳細については、ネットワーク帯域幅をご覧ください。
3 GPU メモリは GPU デバイスのメモリであり、データの一時的な保存に使用できます。これはインスタンスのメモリとは別のものであり、グラフィックを多用するワークロードの高帯域幅の需要に対応できるように設計されています。
G4 マシンタイプ
G4 アクセラレータ最適化マシンタイプは、NVIDIA RTX PRO 6000 Blackwell Server Edition GPU(nvidia-rtx-pro-6000)を使用し、NVIDIA Omniverse シミュレーション ワークロード、グラフィックを多用するアプリケーション、動画のトランスコーディング、仮想デスクトップに適しています。また、G4 マシンタイプは、A シリーズのマシンタイプと比較して、単一ホストの推論とモデル チューニングを実行するための低コストのソリューションを実現します。
| アタッチされた NVIDIA RTX PRO 6000 GPU | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | インスタンスのメモリ(GB) | サポートされている Titanium SSD の最大容量(GiB)2 | 物理 NIC の数 | 最大ネットワーク帯域幅(Gbps)3 | GPU 数 | GPU メモリ4 (GB GDDR7) |
g4-standard-48 |
48 | 180 | 1,500 | 1 | 50 | 1 | 96 |
g4-standard-96 |
96 | 360 | 3,000 | 1 | 100 | 2 | 192 |
g4-standard-192 |
192 | 720 | 6,000 | 1 | 200 | 4 | 384 |
g4-standard-384 |
384 | 1,440 | 12,000 | 2 | 400 | 8 | 768 |
1vCPU は、利用可能な CPU プラットフォームのいずれかで単一のハードウェア ハイパースレッドとして実装されます。
2 G4 インスタンスの作成時に Titanium SSD ディスクを追加できます。アタッチできるディスクの数については、複数のローカル SSD ディスクを選択する必要があるマシンタイプをご覧ください。
3 最大下り(外向き)帯域幅は許容数を超えることはできません。実際の下り(外向き)帯域幅は、宛先 IP アドレスやその他の要因によって異なります。ネットワーク帯域幅をご覧ください。
4 GPU メモリは GPU デバイスのメモリで、データの一時的な保存に使用できます。これはインスタンスのメモリとは別のものであり、グラフィックを多用するワークロードの高帯域幅の需要に対応できるように設計されています。
G2 マシンタイプ
G2 アクセラレータ最適化マシンタイプには NVIDIA L4 GPU が割り当てられており、費用対効果に優れた推論、グラフィック処理を多用するワークロード、ハイ パフォーマンス コンピューティング ワークロードに最適です。
各 G2 マシンタイプにはデフォルトのメモリとカスタムメモリ範囲もあります。カスタムメモリ範囲はマシンタイプごとにインスタンスに割り当てることができるメモリの量を定義します。G2 インスタンスの作成時にローカル SSD ディスクを追加することもできます。アタッチできるディスクの数については、複数のローカル SSD ディスクを選択する必要があるマシンタイプをご覧ください。
ほとんどの GPU インスタンスに高いネットワーク帯域幅レート(50 Gbps 以上)を適用するには、Google Virtual NIC(gVNIC)の使用をおすすめします。gVNIC を使用する GPU インスタンスの作成の詳細については、高い帯域幅を使用する GPU インスタスの作成をご覧ください。
| アタッチされた NVIDIA L4 GPU | |||||||
|---|---|---|---|---|---|---|---|
| マシンタイプ | vCPU 数1 | デフォルトのインスタンス メモリ(GB) | カスタム インスタンス メモリ範囲(GB) | サポート対象の最大ローカル SSD(GiB) | 最大ネットワーク帯域幅(Gbps)2 | GPU 数 | GPU メモリ3(GB GDDR6) |
g2-standard-4 |
4 | 16 | 16~32 | 375 | 10 | 1 | 24 |
g2-standard-8 |
8 | 32 | 32~54 | 375 | 16 | 1 | 24 |
g2-standard-12 |
12 | 48 | 48~54 | 375 | 16 | 1 | 24 |
g2-standard-16 |
16 | 64 | 54~64 | 375 | 32 | 1 | 24 |
g2-standard-24 |
24 | 96 | 96~108 | 750 | 32 | 2 | 48 |
g2-standard-32 |
32 | 128 | 96~128 | 375 | 32 | 1 | 24 |
g2-standard-48 |
48 | 192 | 192~216 | 1,500 | 50 | 4 | 96 |
g2-standard-96 |
96 | 384 | 384~432 | 3,000 | 100 | 8 | 192 |
1vCPU は、利用可能な CPU プラットフォームのいずれかで単一のハードウェア ハイパースレッドとして実装されます。
2 最大下り(外向き)帯域幅は許容数を超えることはできません。実際の下り(外向き)帯域幅は、宛先 IP アドレスやその他の要因によって異なります。ネットワーク帯域幅の詳細については、ネットワーク帯域幅をご覧ください。
3 GPU メモリは GPU デバイスのメモリであり、データの一時的な保存に使用できます。これはインスタンスのメモリとは別のものであり、グラフィックを多用するワークロードの高帯域幅の需要に対応できるように設計されています。
N1 + GPU マシンタイプ
T4 および V100 GPU が接続された N1 汎用インスタンスの場合、GPU と vCPU 数の組み合わせに基づいて、最大 100 Gbps の最大ネットワーク帯域幅を使用できます。他のすべての N1 GPU インスタンスについては、概要をご覧ください。
GPU モデル、vCPU、GPU 数に基づいて、T4 VM と V100 インスタンスで使用可能な最大ネットワーク帯域幅を計算するには、次のセクションを確認してください。
vCPU が 5 個以下の場合
vCPU が 5 個以下の T4 および V100 インスタンスの場合、最大 10 Gbps のネットワーク帯域幅を使用できます。
vCPU が 5 個より多い場合
vCPU が 5 個より多い T4 インスタンスおよび V100 VM の場合、最大ネットワーク帯域幅はその VM の vCPU と GPU 数に基づいて計算されます。
ほとんどの GPU インスタンスに高いネットワーク帯域幅レート(50 Gbps 以上)を適用するには、Google Virtual NIC(gVNIC)の使用をおすすめします。gVNIC を使用する GPU インスタンスの作成の詳細については、高い帯域幅を使用する GPU インスタスの作成をご覧ください。
| GPU モデル | GPU の数 | 最大ネットワーク帯域幅の計算 |
|---|---|---|
| NVIDIA V100 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 32) |
|
| 4 | min(vcpu_count * 2, 50) |
|
| 8 | min(vcpu_count * 2, 100) |
|
| NVIDIA T4 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 50) |
|
| 4 | min(vcpu_count * 2, 100) |
MTU 設定と GPU マシンタイプ
ネットワーク帯域幅を最大化するには、VPC ネットワークの最大伝送単位(MTU)の値を大きく設定します。MTU 値を大きくすると、パケットサイズが大きくなり、パケット ヘッダーのオーバーヘッドが減少するため、ペイロードのデータ スループットが向上します。
GPU マシンタイプの場合、VPC ネットワークには次の MTU 設定をおすすめします。
| GPU マシンタイプ | 推奨 MTU(バイト単位) | |
|---|---|---|
| VPC ネットワーク | RDMA プロファイルを含む VPC ネットワーク | |
|
8896 | 8896 |
|
8244 | 該当なし |
|
8896 | 該当なし |
MTU 値を設定する際は、次の点に注意してください。
- 8192 は 2 つの 4 KB ページです。
- ヘッダー分割が有効になっている GPU NIC の場合、A3 Mega、A3 High、A3 Edge VM では 8244 が推奨されます。
- テーブルに別途記載がない限り、値 8896 を使用します。
高帯域幅 GPU マシンを作成する
高いネットワーク帯域幅を使用する GPU インスタンスを作成するには、マシンタイプに基づいて次のいずれかの方法を使用します。
高いネットワーク帯域幅を使用する A2、G2、N1 インスタンスを作成するには、A2、G2、N1 インスタンスで高いネットワーク帯域幅を使用するをご覧ください。これらのマシンの帯域幅速度をテストまたは検証するには、ベンチマーク テストを使用します。詳細については、ネットワーク帯域幅の確認をご覧ください。
高いネットワーク帯域幅を使用する A3 Mega インスタンスを作成するには、ML トレーニング用に A3 Mega Slurm クラスタをデプロイするをご覧ください。これらのマシンの帯域幅速度をテストまたは検証するには、ネットワーク帯域幅の確認の手順に沿ってベンチマーク テストを使用します。
高いネットワーク帯域幅を使用する A3 High インスタンスと A3 Edge インスタンスについては、GPUDirect-TCPX を有効にして A3 VM を作成するをご覧ください。これらのマシンの帯域幅速度をテストまたは検証するには、ベンチマーク テストを使用します。詳細については、ネットワーク帯域幅の確認をご覧ください。
他のアクセラレータ最適化マシンタイプでは、ネットワーク帯域幅を増やすために必要な操作はありません。ドキュメントに記載されているようにインスタンスを作成すると、すでに高いネットワーク帯域幅が使用されています。他のアクセラレータ最適化マシンタイプのインスタンスを作成する方法については、GPU が接続された VM を作成するをご覧ください。
次のステップ
- GPU プラットフォームの詳細を学習する。
- GPU が接続されたインスタンスを作成する方法を学習する。
- 詳しくは、より高いネットワーク帯域幅を使用するをご覧ください。
- GPU の料金について学習する。