
עבודה עם נתונים גיאו-מרחביים ב-Bigtable
בדף הזה מוסבר איך לאחסן נתונים גיאו-מרחביים ב-Bigtable ולבצע עליהם שאילתות באמצעות פונקציות גיאוגרפיות של GoogleSQL. נתונים גיאו-מרחביים כוללים ייצוגים גיאומטריים של פני השטח של כדור הארץ בצורה של נקודות, קווים ופוליגונים. אפשר לקבץ את הישויות האלה לאוספים כדי לעקוב אחרי מיקומים, מסלולים או אזורים אחרים שמעניינים אתכם.
פעולות בסיסיות
הפונקציות הייעודיות של GoogleSQL למיקום גיאוגרפי מאפשרות ל-Bigtable לבצע אופטימיזציה של ביצועי מסד הנתונים לחישובים גיאוספציאליים ולזמני שאילתות. בדוגמאות לשימוש הבסיסי, אנחנו משתמשים בטבלת tourist_points_of_interest עם קבוצת עמודות אחת בשם poi_data.
| poi_data | |||
|---|---|---|---|
| row key | name | location | |
| p1 | מגדל אייפל | POINT(2.2945 48.8584) |
כתיבת נתונים גיאוגרפיים
כדי לכתוב נתונים גיאו-מרחביים בעמודות Bigtable, צריך לספק ייצוגים של ישויות גיאוגרפיות בפורמטים GeoJSON או Well-Known Text (WKT). Bigtable שומר את נתוני הבסיס כבייטים גולמיים, כך שאפשר לספק כל שילוב של ישויות בעמודה אחת (למשל Points, LineStrings, Polygons, MultiPoints, MultiLineStrings או MultiPolygons). סוג הישות הגיאוספציאלית שאתם מספקים חשוב בזמן השאילתה, כי צריך להשתמש בפונקציית הגיאוגרפיה המתאימה כדי לפרש את הנתונים.
לדוגמה, כדי להוסיף אטרקציות לטבלה tourist_points_of_interest, אפשר להשתמש בכלי cbt CLI באופן הבא:
- עם WKT:
cbt set tourist_points_of_interest p2 poi_data:name='Louvre Museum' cbt set tourist_points_of_interest p2 poi_data:location='POINT(2.3376 48.8611)' cbt set tourist_points_of_interest p3 poi_data:name='Place Charles de Gaulle' cbt set tourist_points_of_interest p3 poi_data:location='POLYGON(2.2941 48.8733, 2.2941 48.8742, 2.2957 48.8742, 2.2958 48.8732, 2.2941 48.8733)'
- עם GeoJSON:
cbt set tourist_points_of_interest p2 poi_data:name='Louvre Museum' cbt set tourist_points_of_interest p2 poi_data:location='{"type": "Point", "coordinates": [2.3376, 48.8611]}' cbt set tourist_points_of_interest p3 poi_data:name='Place Charles de Gaulle' cbt set tourist_points_of_interest p3 poi_data:location='{"type": "Polygon", "coordinates": [[ [2.2941, 48.8733], [2.2941, 48.8742], [2.2957, 48.8742], [2.2958, 48.8732], [2.2941, 48.8733] ]] }'
שאילתת נתונים גיאוגרפיים
אפשר להריץ שאילתות בטבלה tourist_points_of_interest באמצעות GoogleSQL ב-Bigtable Studio ולסנן את התוצאות באמצעות פונקציות גיאוגרפיות.
לדוגמה, כדי למצוא את כל האטרקציות התיירותיות ברדיוס של 1,500 מטרים מכיכר טרוקדרו, אפשר להשתמש בפונקציה ST_DWITHIN:
SELECT _key, poi_data['name'], poi_data['location']
FROM points_of_interest
WHERE ST_DWITHIN(CAST(poi_data['location'] AS STRING), ST_GEOGPOINT(2.2874, 48.86322), 1500);
התוצאה תהיה דומה לתוצאה הבאה:
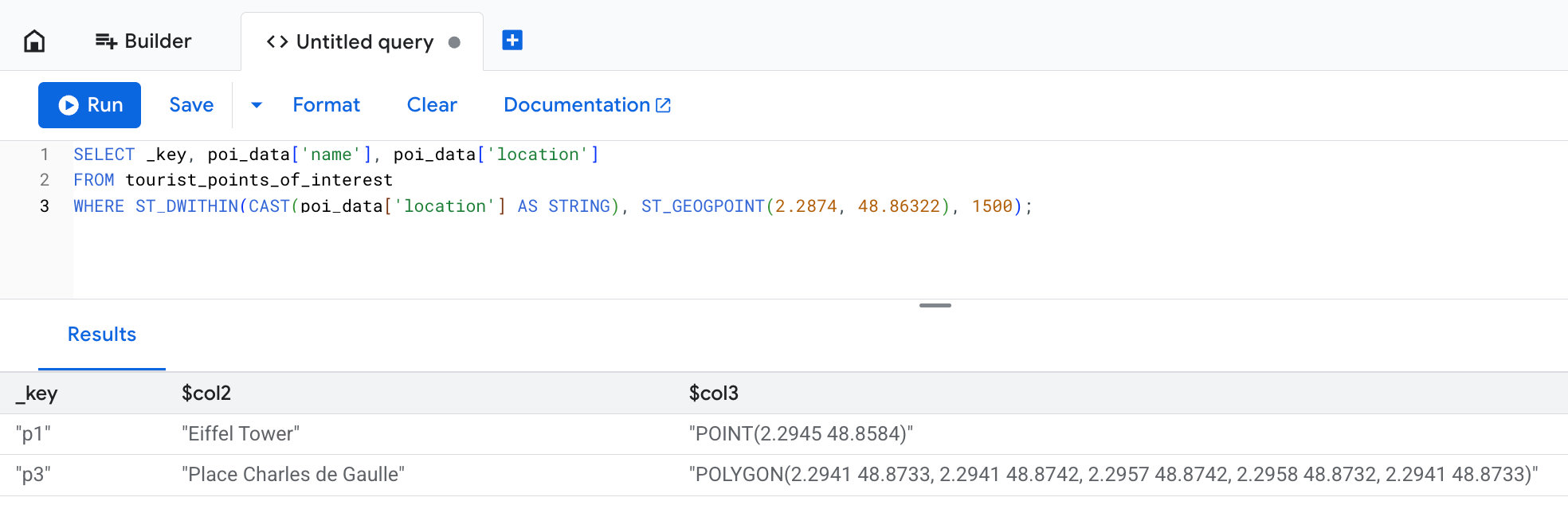
בעמודה location מוצג הייצוג המקורי של הנתונים שסופקו בפעולת הכתיבה, אבל Bigtable מאחסן אותם כבייטים.
בדוגמה הזו, למרות ש-Place Charles de Gaulle מוגדר כפוליגון שמתפרש על שטח גדול יותר מהמגבלה של 1,500 מטר, הוא נכלל בתוצאות השאילתה.
הסיבה לכך היא שהפונקציה ST_DWITHIN מחזירה את הערך True אם נקודה כלשהי שכלולה בישות גיאו-מרחבית נמצאת בטווח המרחק הצפוי.
שימוש מתקדם
בקטעים הבאים מוסבר איך להשתמש בפונקציות גיאוגרפיות בתרחישים מורכבים כמו ניתוח של גדרות וירטואליות. בקטע אופטימיזציה של שאילתות מוסבר איך להשתמש בתצוגות חומריות מתמשכות כדי לשפר את הביצועים.
כדי להמחיש שימושים מתקדמים בפונקציות גיאוגרפיות ב-Bigtable, נניח שאתם חוקרים שעוקבים אחרי ההתנהגות של פינגווינים קיסריים שחיים בצד הדרומי של האי סנואו היל.
הציוד שלכם מספק מאות פינגים של מיקום לכל פינגווין,
לכן אתם יוצרים את הטבלה penguin_movements כדי לאחסן אותם:
| penguin_details | |||
|---|---|---|---|
| row key | penguin_id | חותמת זמן | location |
| ping#123 | pen_01 | 2025-12-06 08:15:22+00 | POINT(-57.51 -64.42) |
| ping#124 | pen_01 | 2025-12-06 10:22:05+00 | POINT(-57.55 -64.43) |
| ping#125 | pen_01 | 2025-12-07 12:35:45+00 | POINT(-57.58 -64.41) |
| ping#126 | pen_02 | 2025-12-12 06:05:11+00 | POINT(-57.49 -64.39) |
דוגמה: איך מוצאים מי חצה את הגדר הגיאוגרפית
במהלך המחקר, אתם צופים בהתנהגות של פינגווינים באזור האכלה ספציפי. אזורים שמוגדרים באמצעות גבולות וירטואליים נקראים בדרך כלל גדרות וירטואליות. אפשר להתייחס לאזור ההאכלה כאזור מגודר וירטואלית.
אתם רוצים לדעת אם פינגווינים ביקרו באזור ההאכלה ב-3 בדצמבר 2025. כדי לענות על השאלה, משתמשים בפונקציה ST_CONTAINS, כך:
SELECT
penguin_details['penguin_id'],
penguin_details['location'],
penguin_details['timestamp']
FROM
penguin_movements
WHERE
penguin_details['timestamp'] >= '2025-12-03 00:00:00 UTC'
AND penguin_details['timestamp'] < '2025-12-04 00:00:00 UTC'
-- The feeding ground boundary is defined with a WKT POLYGON entity
-- Polygon's last point must be equal to its first point to close the loop
AND ST_CONTAINS(
ST_GEOGFROMTEXT('POLYGON((-57.21 -64.51, -57.23 -64.55, -57.08 -64.56, -57.06 -64.51, -57.21 -64.51))'),
ST_GEOGFROMTEXT(CAST(penguin_details['location'] AS STRING))
)
התוצאות שמתקבלות אמורות להיות דומות לתוצאות הבאות:
+------------+----------------------+------------------------+
| penguin_id | location | timestamp |
+------------+----------------------+------------------------+
| pen_01 | POINT(-57.15 -64.53) | 2025-12-03 08:15:22+00 |
| pen_02 | POINT(-57.18 -64.54) | 2025-12-03 14:30:05+00 |
| pen_10 | POINT(-57.10 -64.52) | 2025-12-03 11:45:10+00 |
+------------+----------------------+------------------------+
דוגמה: המרה של נקודות למסלולים
כדי להמחיש טוב יותר את המסלול של הפינגווינים, החלטתם לארגן את הפינגים של כל מיקום בנפרד לLineStrings באמצעות הפונקציה ST_MAKELINE באופן הבא:
SELECT
penguin_id,
DATE(timestamp, 'UTC') AS route_date,
ST_MAKELINE(ARRAY_AGG(location_cast_to_geog)) AS route
FROM (
-- Sub-expression to sort all location pings by timestamp
-- This way you make sure individual points can form a realistic route
SELECT
penguin_details['penguin_id'] AS penguin_id,
-- Extract and cast timestamp once
CAST(CAST(penguin_details['timestamp'] AS STRING) AS TIMESTAMP) AS timestamp,
-- Extract and cast location once
ST_GEOGFROMTEXT(CAST(penguin_details['location'] AS STRING)) AS location_cast_to_geog
FROM
penguin_movements
ORDER BY
-- Pre-sorts location pings for the ARRAY_AGG function
penguin_id, timestamp ASC
)
GROUP BY
penguin_id,
route_date
בעזרת השאילתה הזו תוכלו לקבל תובנות מתקדמות יותר למחקר שלכם. כדי לראות שאילתות ותוצאות לדוגמה, מרחיבים את הקטעים הבאים.
מהו מרחק הנסיעה היומי של כל פינגווין?
כדי לחשב את המרחק שכל פינגווין עובר בכל יום, אפשר להשתמש בפונקציה ST_LENGTH.
SELECT penguin_id, route_date, ST_LENGTH(route) AS daily_distance_meters FROM ( -- Subquery to aggregate points into daily routes SELECT penguin_id, DATE(timestamp, 'UTC') AS route_date, ST_MAKELINE(ARRAY_AGG(location_cast_to_geog)) AS route FROM ( -- Sub-expression to sort all location pings by timestamp -- This way you make sure individual points can form a realistic route SELECT penguin_details['penguin_id'] AS penguin_id, -- Extract and cast timestamp once CAST(CAST(penguin_details['timestamp'] AS STRING) AS TIMESTAMP) AS timestamp, -- Extract and cast location once ST_GEOGFROMTEXT(CAST(penguin_details['location'] AS STRING)) AS location_cast_to_geog FROM penguin_movements ORDER BY -- Pre-sorts location pings for the ARRAY_AGG function penguin_id, timestamp ASC ) GROUP BY penguin_id, route_date ) AS DailyRoutes;
השאילתה הזו מחזירה תוצאה שדומה לזו:
+------------+------------+-----------------------+ | penguin_id | route_date | daily_distance_meters | +------------+------------+-----------------------+ | pen_01 | 2025-12-02 | 15420.7 | | pen_03 | 2025-12-03 | 22105.1 | | pen_32 | 2025-12-03 | 9850.3 | +------------+------------+-----------------------+
כמה מהמסלול היומי מתרחש בתוך האזור עם הגבול הווירטואלי?
כדי לענות על השאלה הזו, מסננים את התוצאות באמצעות הפונקציה ST_INTERSECTION
כדי לבדוק אילו חלקים מהמסלול של הפינגווין חותכים את האזור הגיאוגרפי המגודר.
לאחר מכן, הפונקציה ST_LENGTH יכולה לעזור לחשב את יחס התנועה באזורי ההאכלה למרחק המלא שהחיה עברה באותו היום.
SELECT penguin_id, route_date, ST_LENGTH(ST_INTERSECTION(route, ST_GEOGFROMTEXT('POLYGON((-57.21 -64.51, -57.23 -64.55, -57.08 -64.56, -57.06 -64.51, -57.21 -64.51))'))) / ST_LENGTH(route) AS proportion_in_ground FROM ( -- Subquery to aggregate points into daily routes SELECT penguin_id, DATE(timestamp, 'UTC') AS route_date, ST_MAKELINE(ARRAY_AGG(location_cast_to_geog)) AS route FROM ( -- Sub-expression to sort all location pings by timestamp -- This way you make sure individual points can form a realistic route SELECT penguin_details['penguin_id'] AS penguin_id, -- Extract and cast timestamp once CAST(CAST(penguin_details['timestamp'] AS STRING) AS TIMESTAMP) AS timestamp, -- Extract and cast location once ST_GEOGFROMTEXT(CAST(penguin_details['location'] AS STRING)) AS location_cast_to_geog FROM penguin_movements ORDER BY -- Pre-sorts location pings for the ARRAY_AGG function penguin_id, timestamp ASC ) GROUP BY penguin_id, route_date ) AS DailyRoutes WHERE ST_INTERSECTS(route, ST_GEOGFROMTEXT('POLYGON((-57.21 -64.51, -57.23 -64.55, -57.08 -64.56, -57.06 -64.51, -57.21 -64.51))'))
השאילתה הזו מחזירה תוצאה שדומה לזו:
+------------+------------+----------------------+ | penguin_id | route_date | proportion_in_ground | +------------+------------+----------------------+ | pen_01 | 2025-12-03 | 0.652 | | pen_03 | 2025-12-03 | 0.918 | | pen_32 | 2025-12-04 | 0.231 | +------------+------------+----------------------+
אופטימיזציה של שאילתות באמצעות תצוגות חומריות מתמשכות
שאילתות גיאוגרפיות על מערכי נתונים גדולים יכולות להיות איטיות כי יכול להיות שהן ידרשו סריקה של הרבה שורות. Bigtable לא תומך באינדקסים ייעודיים של נתונים גיאו-מרחביים, אבל אפשר לשפר את הביצועים של השאילתות באמצעות תצוגות חומריות מתמשכות.
כדי ליצור מפתח שורה ייחודי לתצוגות כאלה, אפשר להמיר את GEOGRAPHY
הסוג לתא S2.
S2 היא ספרייה שמאפשרת לבצע טריגונומטריה מורכבת לגיאומטריית כדור.
חישוב מרחקים על סמך קואורדינטות גיאוגרפיות יכול להיות יקר מבחינת משאבי מחשוב. תאי S2 יכולים לייצג אזור ספציפי על פני כדור הארץ כמספר שלם בן 64 ביט, ולכן הם אידיאליים לאינדוקס גיאוגרפי עם תצוגות חומריות רציפות.
כדי להגדיר תא S2, קוראים לפונקציה S2_CELLIDFROMPOINT(location, level) ומספקים את ארגומנט רמת הפירוט level. הארגומנט הזה הוא מספר בין 0 ל-30, והוא מגדיר את הגודל של כל תא: ככל שהמספר גבוה יותר, התא קטן יותר.
בדוגמה של מחקר הפינגווינים, אפשר ליצור תצוגה חומרית רציפה עם אינדקס לפי המיקום וחותמת הזמן של כל פינגווין:
-- Query used to create the continuous materialized view
SELECT
-- Create S2 cells for each penguin's location.
-- Note that the `level` value is the same for each location so that
-- every cell is the same size. This ensures consistency for your data.
S2_CELLIDFROMPOINT(ST_GEOGFROMTEXT(CAST(penguin_details['location'] AS STRING)), level => 16) AS s2_cell_id,
penguin_details['timestamp'] AS observation_time,
penguin_details['penguin_id'] AS penguin_id,
penguin_details['location'] AS location
FROM
penguin_movements
השאילתה הזו כדי לענות על השאלה מי חצה את הגדר הגיאוגרפית? הופכת ליעילה הרבה יותר באמצעות גישה דו-שלבית.
קודם משתמשים באינדקס cell_id בתצוגה המגובשת הרציפה כדי למצוא במהירות שורות מתאימות בסביבה הכללית, ואז מפעילים את הפונקציה המדויקת ST_CONTAINS על מערך הנתונים המצומצם:
SELECT
idx.penguin_id,
idx.location,
idx.observation_time
FROM
penguin_s2_time_index AS idx
WHERE
-- Part one: use an approximate spatial filter and timestamp filter
-- for fast scans on continuous materialized view keys.
-- Use the S2_COVERINGCELLIDS function to create an array of S2 cells
-- that cover the feeding ground polygon. The `level` argument must be the
-- same value as the one you used to create the continuous materialized view.
idx.s2_cell_id IN UNNEST(S2_COVERINGCELLIDS(
ST_GEOGFROMTEXT('POLYGON((-57.21 -64.51, -57.23 -64.55, -57.08 -64.56, -57.06 -64.51, -57.21 -64.51))'),
min_level => 16,
max_level => 16,
max_cells => 500
))
AND idx.observation_time >= '2025-12-03 00:00:00 UTC'
AND idx.observation_time < '2025-12-04 00:00:00 UTC'
-- Part two: use ST_CONTAINS() on the returned set to ensure precision.
-- S2 cells are squares, so they don't equal arbitrary geofence polygons.
-- You still need to check if a specific point is contained within the area,
-- but the filter applies to a smaller data set and is much faster.
AND ST_CONTAINS(ST_GEOGFROMTEXT('POLYGON((-57.21 -64.51, -57.23 -64.55, -57.08 -64.56, -57.06 -64.51, -57.21 -64.51))'), idx.location);
מגבלות
כשעובדים עם נתונים גיאוגרפיים, אין תמיכה בתכונות הבאות ב-Bigtable:
- גיאומטריות תלת-ממדיות. כולל הסיומת 'Z' בפורמט WKT, ואת קואורדינטת הגובה בפורמט GeoJSON.
- מערכות ייחוס לינאריות. זה כולל את הסיומת M בפורמט WKT.
- אובייקטים גיאומטריים בפורמט WKT שאינם פרימיטיבים גיאומטריים או גיאומטריות מרובות חלקים. בפרט, Bigtable תומך רק ב-Point, MultiPoint, LineString, MultiLineString, Polygon, MultiPolygon ו-GeometryCollection.
- הפונקציה
ST_CLUSTERDBSCANלא נתמכת.
בקטעים ST_GEOGFROMGEOJSON וST_GEOGFROMTEXT מפורטות אילוצים ספציפיים לפורמטים של קלט GeoJson ו-WKT.
מה השלב הבא?
- מידע נוסף על פונקציות גיאוגרפיות זמינות סקירה כללית של פונקציות גיאוגרפיות ב-GoogleSQL