
Eseguire la migrazione da Aerospike a Bigtable
Questo documento ti guida nella procedura di migrazione dei dati da Aerospike a Bigtable. Descrive come utilizzare gli strumenti open source, come la libreria dell'adattatore, per eseguire la migrazione.
Prima di iniziare la migrazione, familiarizza con Bigtable per gli utenti di Aerospike.
Panoramica della migrazione
Puoi eseguire la migrazione dei dati da Aerospike a Bigtable con tempi di inattività minimi o nulli.
Il seguente diagramma illustra i passaggi della migrazione:
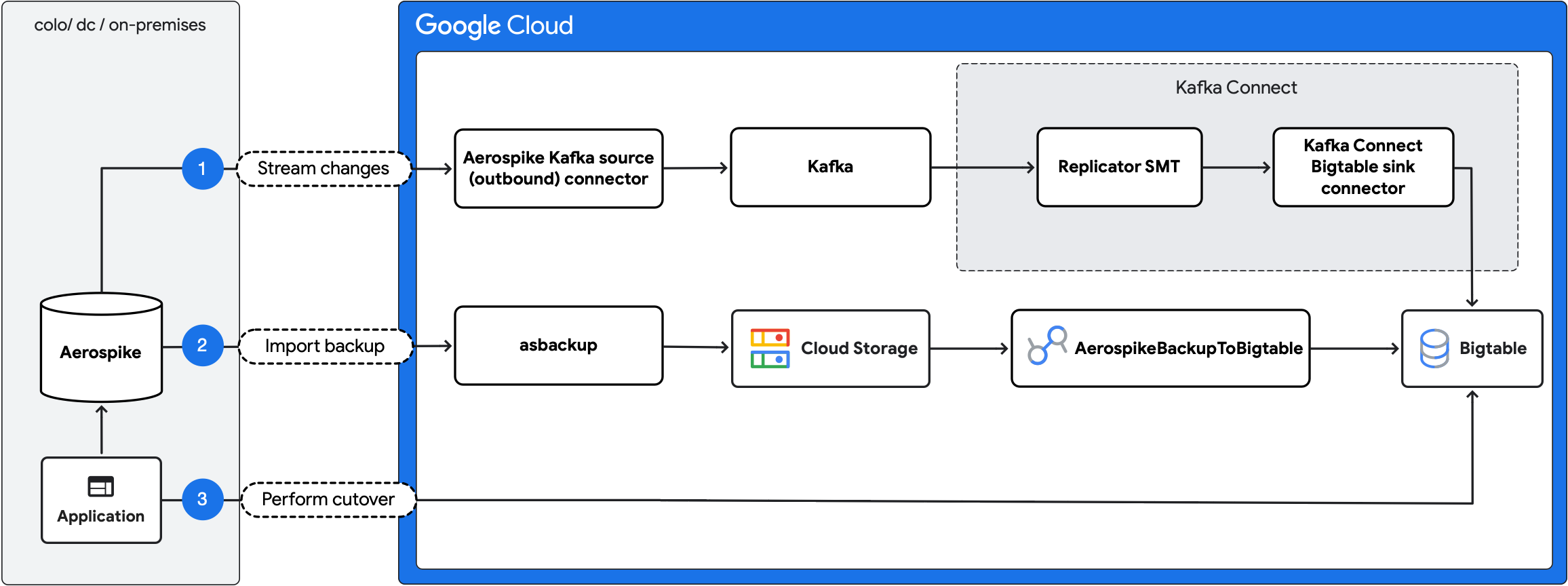
- Trasmetti le modifiche in corso: replica gli aggiornamenti in corso da Aerospike a Bigtable utilizzando il connettore di origine (in uscita) Aerospike Kafka e il connettore di sink Bigtable di Kafka Connect.
- Importa il backup: crea un backup di Aerospike e importalo in Bigtable utilizzando il job Dataflow
AerospikeBackupToBigtable. - Esegui il cutover: sposta il traffico dell'applicazione su Bigtable.
Ambito e compatibilità della migrazione
Poiché Bigtable opera su byte non elaborati anziché su contenitori tipizzati, la procedura di migrazione prevede il mapping delle funzionalità e delle caratteristiche di Aerospike alle strutture Bigtable compatibili. La libreria dell'adattatore fornisce gli strumenti necessari per ottenere la compatibilità strutturale e colmare le lacune, ad esempio la serializzazione degli oggetti. Tuttavia, alcune funzionalità, come le funzioni definite dall'utente (UDF), non possono essere migrate a causa delle differenze fondamentali tra i sistemi.
La seguente tabella riassume come la procedura di migrazione gestisce le funzionalità di Aerospike.
| Funzionalità | Supporto | Descrizione |
|---|---|---|
| Aerospike Hybrid Memory Architecture (HMA) | Supportato | Eseguita la migrazione al livello di archiviazione SSD o al livello in memoria. La versione Bigtable Enterprise Plus fornisce l'accesso all'archiviazione in memoria per i carichi di lavoro sensibili alla latenza che richiedono tempi di risposta inferiori al millisecondo simili alle prestazioni di Aerospike. |
Scalari (Int, Float, String, Bool) |
Supportato | Eseguita la migrazione alle celle Bigtable. |
| Elenchi e mappe | Supportato | Le mappe devono avere chiavi stringa. Gli elenchi e le mappe vengono serializzati in colonne separate dalla libreria dell'adattatore. |
| Indici secondari | Parzialmente supportate | Non viene eseguita la migrazione diretta. Devono essere reimplementati come indici secondari asincroni. |
| Durata (TTL) a livello di record | Supportato | Configurata a livello di famiglia di colonne o simulata per cella in Bigtable. |
| UDF | Non supportata | La logica lato server personalizzata deve essere spostata nell'applicazione lato client. |
| HyperLogLog | Non supportata | Non supportata nella procedura di migrazione. |
| GeoJSON | Non supportata | Non supportata nella procedura di migrazione. |
| Chiavi di record | Non supportata | Non viene eseguita la migrazione diretta delle chiavi di record. La migrazione utilizza invece il digest del record come chiave di riga. |
Prima di iniziare
Prima di iniziare la migrazione, completa i seguenti passaggi preparatori per ridurre i rischi e garantire una transizione senza problemi:
- Convalida i dati: verifica che il deployment di Aerospike non si basi su tipi di dati, indici secondari o UDF non supportati. Come misura di sicurezza, puoi importare un sottoinsieme rappresentativo dei dati in Bigtable e convalidare la progettazione dello schema.
- Esegui il provisioning dell'infrastruttura: configura i servizi necessari per la pipeline di migrazione: Bigtable, Kafka e Kafka Connect.
- Pianificazione della capacità: esegui il provisioning di Bigtable con una capacità sufficiente a gestire il carico di lavoro previsto. Seleziona una regione vicina al cluster Aerospike esistente. Per indicazioni sulla stima delle risorse richieste, consulta Informazioni sulle prestazioni di Bigtable.
- Livello di archiviazione: per i carichi di lavoro che richiedono tempi di risposta inferiori al millisecondo, valuta la possibilità di utilizzare il livello in memoria di Bigtable. Questo livello archivia i dati nella RAM per fornire le massime prestazioni per le applicazioni con un elevato numero di letture o sensibili alla latenza. Per ulteriori informazioni, consulta Panoramica del livello in memoria.
- Configura l'accesso e la rete: assegna i ruoli Identity and Access Management (IAM) appropriati e assicurati la connettività di rete.
- Attiva il monitoraggio e la segnalazione degli errori: configura l'osservabilità per il nuovo ambiente, inclusi logging, metriche e avvisi.
- Esegui il benchmarking delle prestazioni di base: registra le prestazioni attuali del sistema per fornire un riferimento per la convalida dopo la migrazione.
- Crea backup: crea un backup completo dei dati di Aerospike.
- Esegui una migrazione di test: convalida la configurazione in un ambiente di staging prima di tentare una migrazione di produzione.
Migrazione dei dati
Completa i seguenti passaggi per eseguire la migrazione dei dati da Aerospike a Bigtable.
Avviare le modifiche in tempo reale
Quando abiliti le modifiche in tempo reale di Aerospike, il connettore di origine (in uscita) Aerospike Kafka inizia a pubblicare gli aggiornamenti dei record di Aerospike in un argomento Kafka. Assicurati che Kafka abbia una capacità di archiviazione sufficiente per memorizzare nel buffer le modifiche e configura il connettore per generare i dati in formato JSON.
Di seguito è riportato un esempio di configurazione del connettore Kafka:
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
La comunicazione con Kafka utilizzando il connettore di origine (in uscita) Aerospike Kafka richiede la replica tra data center (XDR) di Aerospike, che replica in modo asincrono le modifiche del cluster tramite link con latenza più elevata. XDR è disponibile solo nella versione Aerospike Enterprise. Se utilizzi la versione Aerospike Community, passa alla versione Enterprise o esegui una migrazione offline utilizzando solo il job Dataflow AerospikeBackupToBigtable.
Di seguito è riportata una configurazione di esempio per XDR in Aerospike:
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
Esportare i dati da Aerospike
Dopo aver avviato le modifiche in tempo reale, genera un backup del set di dati Aerospike esistente. Utilizza lo strumento a riga di comando asbackup per creare backup da un cluster di database Aerospike. Alcuni aggiornamenti potrebbero essere visualizzati sia nel backup sia nelle modifiche in tempo reale, il che è previsto e non influisce sulla migrazione. Per consentire le importazioni parallele durante il ripristino, dividi i backup in più file.
Importare i dati in Bigtable
Per importare i dati di cui è stato eseguito il backup in Bigtable:
- Carica il backup in un bucket Cloud Storage.
- Esegui il job Dataflow
AerospikeBackupToBigtableper importare il backup in Bigtable. Se il backup è suddiviso in più file, il job li elabora in parallelo. Per gestire l'aumento del carico di scrittura e mantenere un throughput ottimale, esegui il provisioning di risorse Bigtable aggiuntive.
Applicare gli aggiornamenti dei record a Bigtable
Dopo aver importato il backup in Bigtable, applica gli aggiornamenti dei record memorizzati nel buffer in Kafka a Bigtable utilizzando il connettore di sink Bigtable di Kafka Connect.
Tradurre i messaggi in un formato compatibile
Gli strumenti di migrazione di Aerospike includono Replicator SMT, che viene eseguito all'interno di Kafka Connect. Il replicatore traduce i messaggi pubblicati dal connettore di origine (in uscita) Aerospike Kafka in un formato compatibile con il sink di destinazione che scrive i record in Bigtable. La traduzione è necessaria perché il sink prevede che i dati siano in un formato specifico diverso da quello in cui Aerospike trasmette le modifiche.
La seguente tabella ti aiuta a stimare le risorse della macchina necessarie per ottenere un determinato throughput:
| Struttura dei record | Velocità effettiva | Latenza P99 |
|---|---|---|
| Piatto | Fino a 3700 record al secondo per vCPU | 300 ms |
| Nidificati | Fino a 2600 record al secondo per vCPU | 300 ms |
Queste stime presuppongono che i record serializzati in JSON abbiano una dimensione di 1 KB. Il tempo di analisi aumenta con la complessità delle strutture dei messaggi, il che significa che l'analisi degli oggetti nidificati archiviati nei record di Aerospike richiede più tempo.
Puoi utilizzare la metrica consumer_lag per verificare il numero di messaggi nella coda di elaborazione e misurare il ritardo di replica. Quando il sink elabora il backlog di messaggi nell'argomento, il ritardo del consumer diminuisce fino a stabilizzarsi vicino allo zero, a quel punto il sink elabora gli aggiornamenti di Aerospike quasi in tempo reale, preparandoti per il cutover. Puoi utilizzare sink-record-active-count per verificare il numero di messaggi già elaborati.
Importare i messaggi con il connettore di sink Bigtable di Kafka Connect
Il connettore di sink Bigtable di Kafka Connect importa i messaggi da Kafka a Bigtable. Quando configuri il connettore, imposta insert.mode su REPLACE_IF_NEWEST per assicurarti che il record scritto nella riga di destinazione in Bigtable sia il più recente. Per ulteriori informazioni, consulta Configurazione del connettore di sink Bigtable di Kafka Connect.
La seguente tabella fornisce indicazioni sulla latenza introdotta e sulle risorse di calcolo richieste per diversi carichi di lavoro:
| Struttura dei record | Velocità effettiva | Latenza P99 |
|---|---|---|
| Piatto | Fino a 3700 record al secondo per vCPU | 74 ms |
| Nidificati | Fino a 3700 record al secondo per vCPU | 100 ms |
Queste stime presuppongono che i record serializzati in JSON abbiano una dimensione di 1 KB. La latenza segnalata è il tempo di elaborazione nel sink. Supponi un overhead aggiuntivo di circa 600 ms per effettuare una richiesta di scrittura a Bigtable.
Passare a Bigtable
Passa all'applicazione per utilizzare Bigtable come database principale.
Per garantire la coerenza di lettura dopo scrittura, arresta temporaneamente l'applicazione finché il ritardo di replica non raggiunge lo zero. In questo modo, non vengono perse mutazioni e le letture dei dati riflettono lo stato più recente.
Ad esempio, una mutazione applicata in Aerospike poco prima del cutover potrebbe non essere ancora replicata in Bigtable, causando letture non aggiornate. Per evitare questo scenario, mantieni l'applicazione offline finché le metriche consumer_lag e sink-record-active-count non raggiungono 0. Dopo la propagazione di tutte le modifiche in attesa, riavvia l'applicazione con Bigtable come database principale.
Sebbene una migrazione live possa evitare tempi di inattività, presenta i seguenti vincoli:
- Le mutazioni applicate in Bigtable non vengono replicate di nuovo in Aerospike.
- Le mutazioni provenienti da Aerospike potrebbero essere visualizzate in Bigtable con un ritardo.
- Le mutazioni ritardate da Aerospike possono sovrascrivere gli aggiornamenti più recenti in Bigtable.
Verifica il deployment
Dopo il deployment, convalida il rendimento dell'applicazione esaminando metriche come tassi di errore, latenza e costi. Puoi anche eseguire controlli sull'integrità dei dati.
Monitoraggio e osservabilità
Monitora le seguenti metriche durante la migrazione:
- Ritardo totale: calcolato come ritardo del consumer Kafka più
sink-record-active-count. Queste metriche indicano il ritardo di Bigtable rispetto ad Aerospike. È necessario un valore di ritardo stabile prima di reindirizzare il traffico a Bigtable. - Utilizzo di CPU e memoria: monitora l'utilizzo di CPU e memoria di tutti i componenti della pipeline delle modifiche in tempo reale.
- Capacità di archiviazione di Kafka: monitora la capacità per i deployment di Kafka autogestiti. Se lo spazio di archiviazione si riempie, non è possibile memorizzare nel buffer i nuovi eventi, causando un errore di migrazione.
- Tassi di errore dell'applicazione: monitora i tassi di errore e gli output di errore di tutti gli elementi della pipeline delle modifiche in tempo reale.
Limitazioni
Le sezioni seguenti descrivono le limitazioni da considerare durante la migrazione dei dati da Aerospike a Bigtable.
Coerenza dei dati durante la migrazione
Quando utilizzi lo strumento asbackup per generare il backup di Aerospike, i record modificati durante la procedura di backup potrebbero essere esclusi perché la procedura di backup non supporta i backup atomici. Questa limitazione non influisce sulla correttezza perché tutte le modifiche vengono visualizzate nelle modifiche in tempo reale.
Durante l'importazione del backup in Bigtable, ogni riga viene scritta con un timestamp dell'ora dell'ultimo aggiornamento (LUT) di 0.
Gli aggiornamenti delle modifiche in tempo reale vengono applicati al backup importato. Le righe scritte dal flusso utilizzano il valore LUT come timestamp della riga Bigtable. La configurazione del sink fa sì che l'aggiornamento con un timestamp più recente sovrascriva quello precedente. In questo modo, qualsiasi modifica riprodotta dal flusso sovrascrive la riga corrispondente.
Utilizzo di LUT
La procedura di migrazione utilizza Aerospike XDR per replicare le modifiche e si basa su LUT per la risoluzione dei conflitti. Poiché le LUT si basano sull'orologio di sistema del nodo, potrebbero non essere strettamente monotone. Di conseguenza, un record non aggiornato potrebbe occasionalmente avere una LUT più recente e sovrascrivere un record più recente. Inoltre, il connettore di origine (in uscita) Aerospike Kafka potrebbe non conservare l'ordine esatto dei messaggi durante la pubblicazione in Kafka. Di conseguenza, la LUT funge da marcatore di versione autorevole, garantendo che solo i record con la LUT più recente vengano applicati a Bigtable.
Se un record viene aggiornato dopo l'avvio delle modifiche in tempo reale, ma prima di generare il backup, il backup potrebbe acquisire la versione più recente, mentre le modifiche in tempo reale contengono una versione precedente. Questa versione precedente potrebbe sovrascrivere temporaneamente quella più recente. Tuttavia, quando arriva l'evento di flusso successivo con la LUT corretta, viene ripristinata la versione più recente. Per evitare incoerenze, attendi l'esecuzione del cutover finché la replica non si stabilizza e il messaggio non elaborato meno recente nella pipeline non è più recente del backup.
Convalida dei dati
La pipeline di migrazione non esegue il checksum dei dati in transito. Se sono necessari controlli sull'integrità dei dati end-to-end, devi implementare la convalida.
Risoluzione dei problemi
Le sezioni seguenti descrivono gli errori comuni che potrebbero verificarsi durante la procedura di migrazione e forniscono indicazioni su come risolverli.
Errori di importazione del backup
Durante l'importazione del backup di Aerospike in Bigtable, potresti riscontrare i seguenti errori:
| Tipo di errore | Causa | Soluzione |
|---|---|---|
| File di backup danneggiato | I file di backup non sono leggibili o contengono record danneggiati. Il job di importazione non riesce. | Controlla i file interessati per verificare la presenza di problemi di integrità. Se non è possibile recuperarli, genera un nuovo backup e ripeti l'importazione. |
| Errori di scrittura di Bigtable | Si verificano problemi di connettività o di servizio di Bigtable. L'importazione non riesce. | I record non riusciti vengono esportati in un file di output di errore in formato JSON. Applicali di nuovo manualmente o riprova a eseguire il job di importazione completo. |
| Dati non supportati | Il backup contiene voci che non possono essere importate in Bigtable. L'importazione non riesce. | I dati non supportati, come le UDF, vengono segnalati come avvisi nei log dei job. Esamina i log per verificare le voci non supportate. |
Una volta completata l'importazione del backup e risolti i record non validi, puoi procedere con l'applicazione delle modifiche in tempo reale.
Errori delle modifiche in tempo reale
Durante l'applicazione delle modifiche in tempo reale, potrebbero verificarsi errori ai seguenti livelli:
- Errori di Replicator SMT: SMT non riesce a trasformare i dati prodotti da Aerospike.
- Errori di sink: gli eventi non possono essere applicati a Bigtable.
In entrambi i casi, gli eventi non riusciti vengono reindirizzati a un argomento Kafka dedicato. Puoi registrare gli eventi per l'audit o elaborarli utilizzando una logica di recupero personalizzata.
Passaggi successivi
- Scopri come progettare lo schema Bigtable.
- Scopri come iniziare la tua migrazione a Google Cloud.
- Scopri le strategie a tua disposizione per il trasferimento di set di dati di grandi dimensioni.