
Bermigrasi dari Aerospike ke Bigtable
Dokumen ini memandu Anda melalui proses migrasi data dari Aerospike ke Bigtable. Dokumen ini menjelaskan cara menggunakan alat open source, seperti library adapter, untuk melakukan migrasi.
Sebelum memulai migrasi, pahami Bigtable untuk pengguna Aerospike.
Ringkasan migrasi
Anda dapat memigrasikan data dari Aerospike ke Bigtable dengan waktu nonaktif minimal atau nol.
Diagram berikut menguraikan langkah-langkah migrasi:
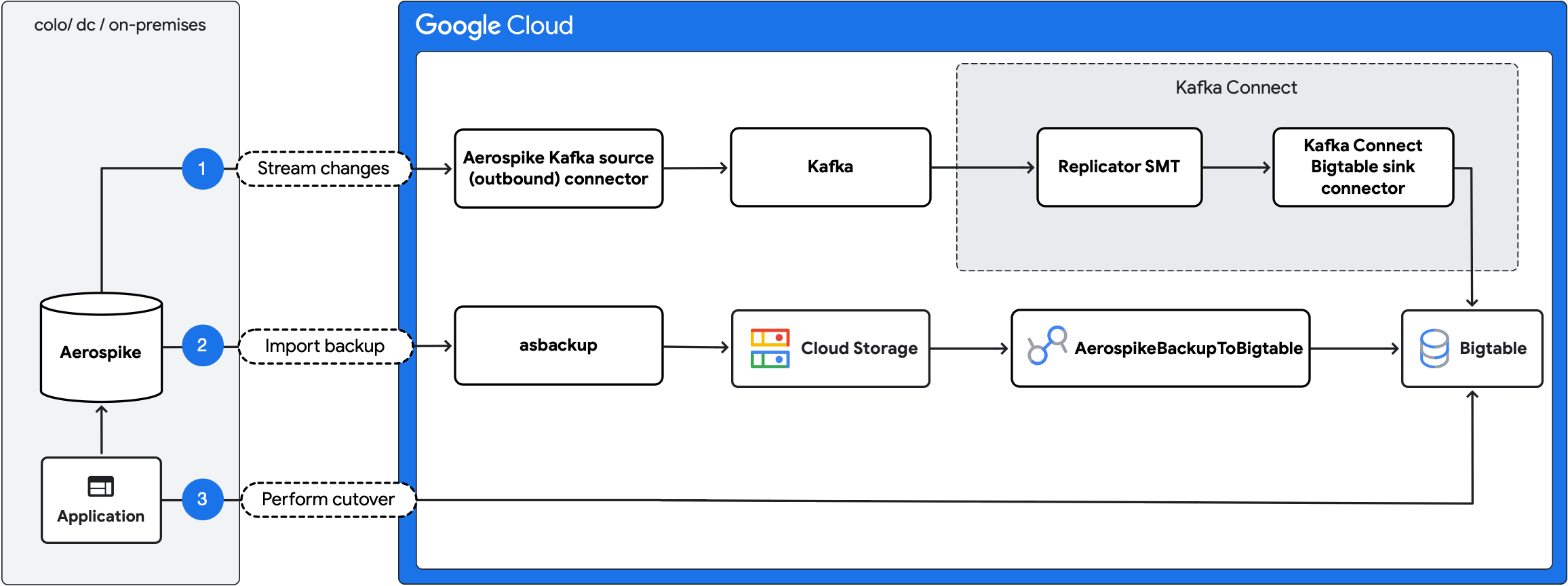
- Streaming perubahan yang sedang berlangsung: mereplikasi pembaruan yang sedang berlangsung dari Aerospike ke Bigtable menggunakan konektor sumber Aerospike Kafka (keluar) dan konektor sink Bigtable Kafka Connect.
- Mengimpor cadangan: membuat cadangan Aerospike dan mengimpornya ke Bigtable menggunakan tugas Dataflow
AerospikeBackupToBigtable. - Melakukan cutover: memindahkan traffic aplikasi ke Bigtable.
Cakupan dan kompatibilitas migrasi
Karena Bigtable beroperasi pada byte mentah, bukan bin yang diketik, proses migrasi melibatkan pemetaan kemampuan dan fitur Aerospike ke struktur Bigtable yang kompatibel. Library adapter menyediakan alat yang diperlukan untuk mencapai kompatibilitas struktural dan mengatasi kesenjangan, seperti serialisasi objek. Namun, fitur tertentu, seperti fungsi yang ditentukan pengguna (UDF), tidak dapat dimigrasikan karena perbedaan mendasar antara sistem.
Tabel berikut merangkum cara proses migrasi menangani kemampuan Aerospike.
| Fitur | Dukungan | Deskripsi |
|---|---|---|
| Arsitektur Memori Hybrid (HMA) Aerospike | Didukung | Dimigrasikan ke tingkat penyimpanan SSD atau ke tingkat dalam memori. Edisi Bigtable Enterprise Plus menyediakan akses ke penyimpanan dalam memori untuk workload sensitif latensi yang memerlukan waktu respons sub-milidetik yang mirip dengan performa Aerospike. |
Skalar (Int, Float, String, Bool) |
Didukung | Dimigrasikan ke sel Bigtable. |
| Daftar dan peta | Didukung | Peta harus memiliki kunci string. Daftar dan peta diserialisasi ke dalam kolom terpisah oleh library adapter. |
| Indeks sekunder | Didukung sebagian | Tidak dimigrasikan secara langsung. Harus diimplementasikan ulang sebagai indeks sekunder asinkron. |
| Time to live (TTL) tingkat data | Didukung | Dikonfigurasi di tingkat grup kolom atau disimulasikan per sel di Bigtable. |
| UDF | Tidak didukung | Logika sisi server kustom harus dipindahkan ke aplikasi sisi klien. |
| HyperLogLog | Tidak didukung | Tidak didukung dalam proses migrasi. |
| GeoJSON | Tidak didukung | Tidak didukung dalam proses migrasi. |
| Kunci data | Tidak didukung | Kunci data tidak dimigrasikan secara langsung. Sebagai gantinya, migrasi menggunakan ringkasan data sebagai row key. |
Sebelum memulai
Sebelum memulai migrasi, selesaikan langkah-langkah persiapan berikut untuk mengurangi risiko dan memastikan transisi yang lancar:
- Memvalidasi data: pastikan deployment Aerospike tidak bergantung pada jenis data, indeks sekunder, atau UDF yang tidak didukung. Sebagai pengamanan, Anda dapat mengimpor subset data representatif ke Bigtable dan memvalidasi desain skema.
- Menyediakan infrastruktur: menyiapkan layanan yang diperlukan untuk pipeline migrasi: Bigtable, Kafka, dan Kafka Connect.
- Perencanaan kapasitas: menyediakan Bigtable dengan kapasitas yang cukup untuk menangani workload yang diharapkan. Pilih region yang dekat dengan cluster Aerospike yang ada. Untuk panduan tentang cara memperkirakan resource yang diperlukan, lihat Memahami performa Bigtable.
- Tingkat penyimpanan: untuk workload yang memerlukan waktu respons sub-milidetik, pertimbangkan untuk menggunakan tingkat dalam memori Bigtable. Tingkat ini menyimpan data dalam RAM untuk memberikan performa tertinggi bagi aplikasi yang banyak membaca atau sensitif terhadap latensi. Untuk mengetahui informasi selengkapnya, lihat Ringkasan tingkat dalam memori.
- Mengonfigurasi akses dan jaringan: menetapkan peran Identity and Access Management (IAM) yang sesuai dan memastikan konektivitas jaringan.
- Mengaktifkan pemantauan dan pelaporan error: mengonfigurasi kemampuan observasi untuk lingkungan baru, termasuk logging, metrik, dan pemberitahuan.
- Performa dasar benchmark: mencatat performa sistem saat ini untuk memberikan referensi untuk memvalidasinya setelah migrasi.
- Membuat cadangan: membuat cadangan lengkap data Aerospike Anda.
- Menjalankan migrasi pengujian: memvalidasi penyiapan di lingkungan staging sebelum Anda mencoba migrasi produksi.
Migrasikan data
Selesaikan langkah-langkah berikut untuk memigrasikan data dari Aerospike ke Bigtable.
Memulai aliran data perubahan
Saat Anda mengaktifkan aliran data perubahan Aerospike, konektor sumber Aerospike Kafka (keluar) akan mulai memublikasikan pembaruan data Aerospike ke topik Kafka. Pastikan Kafka memiliki kapasitas penyimpanan yang cukup untuk menyimpan perubahan dan mengonfigurasi konektor untuk menghasilkan data dalam format JSON.
Berikut adalah contoh konfigurasi konektor Kafka:
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
Komunikasi dengan Kafka menggunakan konektor sumber Aerospike Kafka (keluar) memerlukan Aerospike Cross-Datacenter Replication (XDR), yang mereplikasi perubahan cluster secara asinkron melalui link latensi yang lebih tinggi. XDR hanya tersedia di Aerospike Enterprise Edition. Jika Anda menggunakan Aerospike Community Edition, beralihlah ke Enterprise Edition atau lakukan migrasi offline hanya menggunakan tugas Dataflow AerospikeBackupToBigtable.
Contoh konfigurasi untuk XDR di Aerospike terlihat sebagai berikut:
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
Mengekspor data dari Aerospike
Setelah memulai aliran data perubahan, buat cadangan set data Aerospike yang ada. Gunakan alat command line asbackup untuk membuat cadangan dari cluster database Aerospike. Beberapa pembaruan mungkin muncul di cadangan dan aliran data perubahan, yang diharapkan dan tidak memengaruhi migrasi. Untuk mengizinkan impor paralel selama pemulihan, pisahkan cadangan ke dalam beberapa file.
Mengimpor data ke Bigtable
Untuk mengimpor data yang dicadangkan ke Bigtable, lakukan hal berikut:
- Upload cadangan ke bucket Cloud Storage.
- Jalankan tugas Dataflow
AerospikeBackupToBigtableuntuk mengimpor cadangan ke Bigtable. Jika cadangan dibagi ke beberapa file, tugas akan memprosesnya secara paralel. Untuk menangani peningkatan beban tulis dan mempertahankan throughput yang optimal, sediakan resource Bigtable tambahan.
Menerapkan pembaruan data ke Bigtable
Setelah mengimpor cadangan ke Bigtable, terapkan pembaruan data yang di-buffer di Kafka ke Bigtable menggunakan konektor sink Bigtable Kafka Connect.
Menerjemahkan pesan ke dalam format yang kompatibel
Alat migrasi Aerospike mencakup Replicator SMT, yang berjalan dalam Kafka Connect. Replicator menerjemahkan pesan yang dipublikasikan oleh konektor sumber Aerospike Kafka (keluar) ke dalam format yang kompatibel dengan sink target yang menulis data ke Bigtable. Terjemahan diperlukan karena sink mengharapkan data dalam format tertentu yang berbeda dengan cara Aerospike melakukan streaming perubahan.
Tabel berikut membantu Anda memperkirakan resource mesin yang diperlukan untuk mencapai throughput tertentu:
| Struktur data | Throughput | Latensi p99 |
|---|---|---|
| Tetap | Hingga 3.700 data per detik per vCPU | 300 md |
| Bertingkat | Hingga 2.600 data per detik per vCPU | 300 md |
Perkiraan ini mengasumsikan bahwa data yang diserialisasi JSON berukuran 1 KB. Waktu penguraian meningkat seiring dengan kompleksitas struktur pesan, yang berarti objek bertingkat yang disimpan dalam data Aerospike memerlukan waktu lebih lama untuk diuraikan.
Anda dapat menggunakan metrik consumer_lag untuk memverifikasi jumlah pesan dalam antrean pemrosesan dan mengukur latensi replikasi. Saat sink memproses backlog pesan pada topik, latensi konsumen akan menurun hingga stabil mendekati nol, yang berarti sink memproses pembaruan Aerospike mendekati real time, sehingga Anda siap untuk cutover. Anda dapat menggunakan sink-record-active-count untuk memverifikasi jumlah pesan yang sudah diproses.
Menyerap pesan dengan konektor sink Bigtable Kafka Connect
Konektor sink Bigtable Kafka Connect menyerap pesan dari Kafka ke Bigtable. Saat mengonfigurasi konektor, tetapkan insert.mode ke REPLACE_IF_NEWEST untuk memastikan bahwa data yang ditulis ke baris target di Bigtable adalah yang terbaru. Untuk mengetahui informasi selengkapnya, lihat Konfigurasi konektor sink Bigtable Kafka Connect.
Tabel berikut memberikan panduan tentang latensi yang diperkenalkan dan resource komputasi yang diperlukan untuk berbagai workload:
| Struktur data | Throughput | Latensi p99 |
|---|---|---|
| Tetap | Hingga 3.700 data per detik per vCPU | 74 md |
| Bertingkat | Hingga 3.700 data per detik per vCPU | 100 md |
Perkiraan ini mengasumsikan bahwa data yang diserialisasi JSON berukuran 1 KB. Latensi yang dilaporkan adalah waktu pemrosesan di sink. Asumsikan overhead tambahan untuk membuat permintaan tulis ke Bigtable sekitar 600 md.
Beralih ke Bigtable
Alihkan aplikasi untuk menggunakan Bigtable sebagai database utama.
Untuk memastikan konsistensi baca-tulis, nonaktifkan aplikasi untuk sementara hingga latensi replikasi mencapai nol. Hal ini memastikan tidak ada mutasi yang hilang dan pembacaan data mencerminkan status terbaru.
Misalnya, mutasi yang diterapkan di Aerospike tepat sebelum cutover mungkin belum direplikasi ke Bigtable, sehingga menyebabkan pembacaan yang tidak valid. Untuk mencegah skenario ini, pertahankan aplikasi offline hingga metrik consumer_lag dan sink-record-active-count mencapai 0. Setelah semua perubahan yang tertunda diterapkan, mulai ulang aplikasi dengan Bigtable sebagai database utama.
Meskipun migrasi langsung dapat menghindari waktu nonaktif, migrasi ini memiliki batasan berikut:
- Mutasi yang diterapkan di Bigtable tidak direplikasi kembali ke Aerospike.
- Mutasi yang berasal dari Aerospike mungkin muncul di Bigtable dengan penundaan.
- Mutasi yang tertunda dari Aerospike dapat menimpa pembaruan yang lebih baru di Bigtable.
Memverifikasi deployment
Setelah deployment, validasi performa aplikasi dengan meninjau metrik seperti rasio error, latensi, dan biaya. Anda juga dapat melakukan pemeriksaan integritas data.
Pemantauan dan kemampuan observasi
Pantau metrik berikut selama migrasi:
- Total latensi: dihitung sebagai latensi konsumen Kafka ditambah
sink-record-active-count. Metrik ini menunjukkan seberapa jauh Bigtable tertinggal dari Aerospike. Nilai latensi yang stabil diperlukan sebelum Anda merutekan ulang traffic ke Bigtable. - Penggunaan CPU dan memori: pantau penggunaan CPU dan memori semua komponen pipeline aliran data perubahan.
- Kapasitas penyimpanan Kafka: pantau kapasitas untuk deployment Kafka yang dikelola sendiri. Jika penyimpanan penuh, peristiwa baru tidak dapat di-buffer, sehingga menyebabkan kegagalan migrasi.
- Rasio error aplikasi: pantau rasio error dan output error dari semua elemen pipeline aliran data perubahan.
Batasan
Bagian berikut menguraikan batasan yang perlu dipertimbangkan saat memigrasikan data dari Aerospike ke Bigtable.
Konsistensi data selama migrasi
Saat Anda menggunakan alat asbackup untuk membuat cadangan Aerospike, data yang diubah selama proses pencadangan mungkin dikecualikan karena proses pencadangan tidak mendukung pencadangan atomik. Batasan ini tidak memengaruhi kebenaran karena semua perubahan muncul dalam aliran data perubahan.
Selama impor cadangan ke Bigtable, setiap baris ditulis dengan stempel waktu waktu pembaruan terakhir (LUT) 0.
Pembaruan dari aliran data perubahan diterapkan di atas cadangan yang diimpor. Baris yang ditulis dari aliran menggunakan nilai LUT sebagai stempel waktu baris Bigtable. Konfigurasi sink membuat pembaruan dengan stempel waktu yang lebih baru menimpa yang lebih lama. Hal ini memastikan bahwa setiap perubahan yang diputar ulang dari aliran akan menimpa baris yang sesuai.
Penggunaan LUT
Proses migrasi menggunakan Aerospike XDR untuk mereplikasi perubahan dan bergantung pada LUT untuk penyelesaian konflik. Karena LUT didasarkan pada jam sistem node, LUT mungkin tidak benar-benar monoton. Akibatnya, data yang tidak berlaku terkadang dapat memiliki LUT yang lebih baru dan menimpa data yang lebih baru. Selain itu, konektor sumber Aerospike Kafka (keluar) mungkin tidak mempertahankan urutan pesan yang tepat saat memublikasikan ke Kafka. Akibatnya, LUT berfungsi sebagai penanda versi otoritatif, yang memastikan bahwa hanya data dengan LUT terbaru yang diterapkan ke Bigtable.
Jika data diperbarui setelah Anda memulai aliran data perubahan, tetapi sebelum Anda membuat cadangan, cadangan mungkin menangkap versi yang lebih baru, sedangkan aliran data perubahan berisi versi yang lebih lama. Versi yang lebih lama ini mungkin untuk sementara menimpa versi yang lebih baru. Namun, saat peristiwa aliran data perubahan berikutnya dengan LUT yang benar tiba, versi terbaru akan dipulihkan. Untuk mencegah inkonsistensi, tunggu hingga replikasi stabil dan pesan yang belum diproses terlama dalam pipeline lebih baru daripada cadangan sebelum melakukan cutover.
Validasi data
Pipeline migrasi tidak melakukan checksum data dalam pengiriman. Jika memerlukan pemeriksaan integritas data menyeluruh, Anda harus menerapkan validasi.
Pemecahan masalah
Bagian berikut menjelaskan error umum yang mungkin terjadi selama proses migrasi dan memberikan panduan tentang cara mengatasinya.
Error impor cadangan
Selama impor cadangan Aerospike ke Bigtable, Anda mungkin mengalami error berikut:
| Jenis error | Penyebab | Solusi |
|---|---|---|
| File cadangan rusak | File cadangan tidak dapat dibaca atau berisi data yang rusak. Tugas impor gagal. | Periksa file yang terpengaruh untuk mengetahui masalah integritas. Jika tidak dapat dipulihkan, buat cadangan baru dan ulangi impor. |
| Kegagalan tulis Bigtable | Terjadi masalah konektivitas atau layanan Bigtable. Impor tidak gagal. | Data yang gagal diekspor ke file output error dalam format JSON. Terapkan kembali secara manual atau coba lagi tugas impor lengkap. |
| Data tidak didukung | Cadangan berisi entri yang tidak dapat diimpor ke Bigtable. Impor tidak gagal. | Data yang tidak didukung, seperti UDF, dilaporkan sebagai peringatan dalam log tugas. Tinjau log untuk memverifikasi entri yang tidak didukung. |
Setelah impor cadangan selesai dan data yang tidak valid ditangani, Anda dapat melanjutkan untuk menerapkan aliran data perubahan.
Error aliran data perubahan
Selama penerapan aliran data perubahan, kegagalan mungkin terjadi pada tingkat berikut:
- Error Replicator SMT: SMT gagal mengubah data yang dihasilkan oleh Aerospike.
- Error sink: peristiwa tidak dapat diterapkan ke Bigtable.
Dalam kedua kasus tersebut, peristiwa yang gagal akan dialihkan ke topik Kafka khusus. Anda dapat mencatat peristiwa untuk audit atau memprosesnya menggunakan logika pemulihan kustom.
Langkah berikutnya
- Pelajari cara mendesain skema Bigtable.
- Baca cara memulai Migrasi ke Google Cloud.
- Pahami strategi yang Anda miliki untuk mentransfer set data besar.