
Migrer depuis Aerospike vers Bigtable
Ce document vous guide tout au long du processus de migration des données depuis Aerospike vers Bigtable. Il explique comment utiliser des outils Open Source, tels que la bibliothèque d'adaptateurs, pour effectuer la migration.
Avant de commencer la migration, familiarisez-vous avec Bigtable pour les utilisateurs d'Aerospike.
Présentation de la migration
Vous pouvez migrer vos données depuis Aerospike vers Bigtable avec un temps d'arrêt minimal, voire nul.
Le diagramme suivant décrit les étapes de la migration :
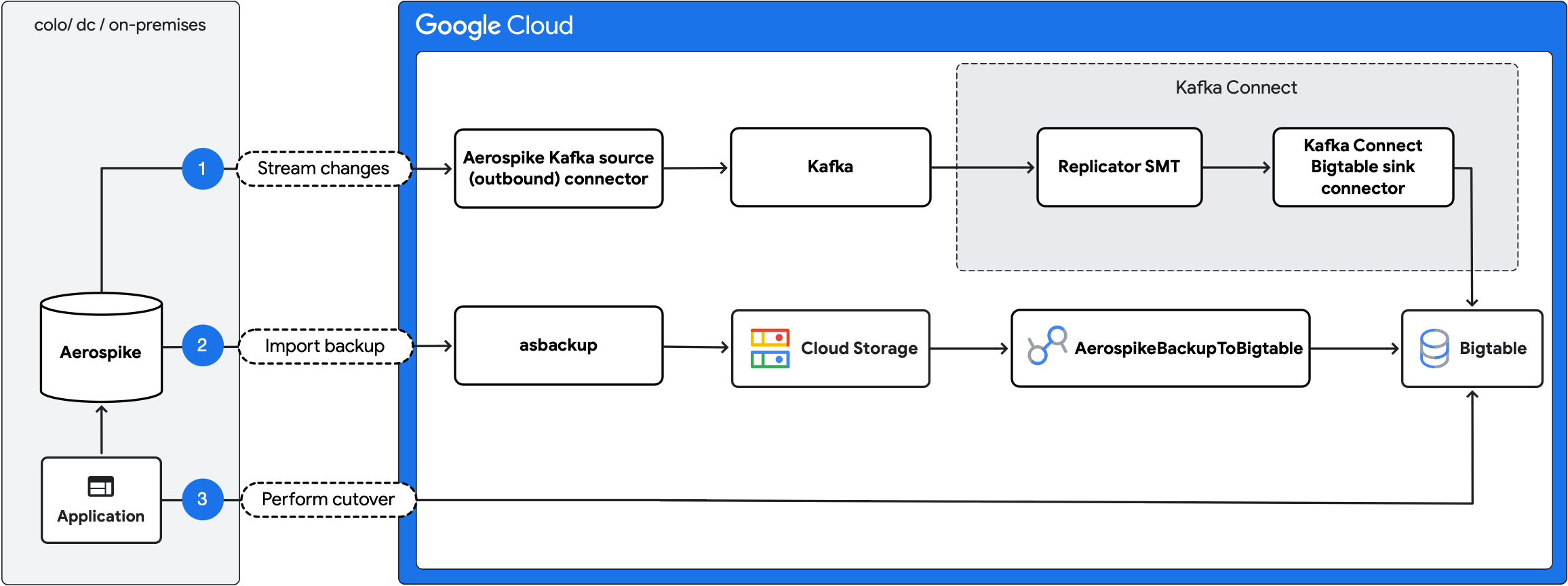
- Diffuser les modifications en cours : répliquez les mises à jour en cours d'Aerospike vers Bigtable à l'aide du connecteur source Aerospike Kafka (sortant) et du connecteur de récepteur Kafka Connect Bigtable.
- Importer une sauvegarde : créez une sauvegarde Aerospike et importez-la dans Bigtable à l'aide du job Dataflow
AerospikeBackupToBigtable. - Effectuez la transition : transférez le trafic de l'application vers Bigtable.
Champ d'application et compatibilité de la migration
Comme Bigtable fonctionne sur des octets bruts plutôt que sur des bins typés, le processus de migration consiste à mapper les capacités et les fonctionnalités d'Aerospike sur des structures Bigtable compatibles. La bibliothèque d'adaptateurs fournit les outils nécessaires pour assurer la compatibilité structurelle et combler les lacunes, comme la sérialisation des objets. Toutefois, certaines fonctionnalités, telles que les fonctions définies par l'utilisateur (UDF), ne peuvent pas être migrées en raison de différences fondamentales entre les systèmes.
Le tableau suivant récapitule la façon dont le processus de migration gère les fonctionnalités Aerospike.
| Fonctionnalité | Assistance | Description |
|---|---|---|
| Architecture de mémoire hybride (HMA) Aerospike | Compatible | Migrées vers le niveau de stockage SSD ou vers le niveau en mémoire. L'édition Enterprise Plus de Bigtable permet d'accéder au stockage en mémoire pour les charges de travail sensibles à la latence qui nécessitent des temps de réponse inférieurs à une milliseconde, semblables aux performances d'Aerospike. |
Scalaires (Int, Float, String, Bool) |
Compatible | Cellules migrées vers Bigtable. |
| Listes et cartes | Compatible | Les cartes doivent comporter des clés de chaîne. Les listes et les cartes sont sérialisées dans des colonnes distinctes par la bibliothèque d'adaptateurs. |
| Index secondaires | Partiellement compatibles | Non migré directement. Doit être réimplémenté en tant qu'index secondaires asynchrones. |
| Valeur TTL (Time To Live) au niveau de l'enregistrement | Compatible | Configurée au niveau de la famille de colonnes ou simulée par cellule dans Bigtable. |
| UDF | Non compatible | La logique côté serveur personnalisée doit être déplacée vers l'application côté client. |
| HyperLogLog | Non compatible | Non disponible dans le processus de migration. |
| GeoJSON | Non compatible | Non disponible dans le processus de migration. |
| Clés d'enregistrement | Non compatible | Les clés d'enregistrement ne sont pas migrées directement. La migration utilise plutôt le résumé de l'enregistrement comme clé de ligne. |
Avant de commencer
Avant de commencer la migration, suivez les étapes préparatoires ci-dessous pour réduire les risques et assurer une transition fluide :
- Validez vos données : vérifiez que le déploiement Aerospike ne repose pas sur des types de données, des index secondaires ni des UDF non compatibles. Par mesure de sécurité, vous pouvez importer un sous-ensemble représentatif de vos données dans Bigtable et valider la conception du schéma.
- Provisionnez l'infrastructure : configurez les services requis pour le pipeline de migration (Bigtable, Kafka et Kafka Connect).
- Planification de la capacité : provisionnez Bigtable avec une capacité suffisante pour gérer la charge de travail attendue. Sélectionnez une région proche du cluster Aerospike existant. Pour obtenir des conseils sur l'estimation des ressources requises, consultez Comprendre les performances de Bigtable.
- Niveau de stockage : pour les charges de travail qui nécessitent des temps de réponse inférieurs à la milliseconde, envisagez d'utiliser le niveau en mémoire de Bigtable. Ce niveau stocke les données dans la RAM pour offrir les meilleures performances aux applications sensibles à la latence ou qui effectuent de nombreuses opérations de lecture. Pour en savoir plus, consultez Présentation du niveau en mémoire.
- Configurer l'accès et le réseau : attribuez les rôles Identity and Access Management (IAM) appropriés et assurez-vous que la connectivité réseau est établie.
- Activez la surveillance et les rapports d'erreurs : configurez l'observabilité pour le nouvel environnement, y compris la journalisation, les métriques et les alertes.
- Établissez une référence pour les performances de base : enregistrez les performances actuelles du système pour disposer d'une référence permettant de les valider après la migration.
- Créer des sauvegardes : créez une sauvegarde complète de vos données Aerospike.
- Effectuez une migration test : validez la configuration dans un environnement de préproduction avant de tenter une migration en production.
Migrer les données
Pour migrer vos données d'Aerospike vers Bigtable, procédez comme suit.
Lancer le flux de modifications
Lorsque vous activez le flux de modifications Aerospike, le connecteur source Aerospike Kafka (sortant) commence à publier les mises à jour des enregistrements Aerospike dans un sujet Kafka. Assurez-vous que Kafka dispose d'une capacité de stockage suffisante pour mettre en mémoire tampon les modifications et configurez le connecteur pour qu'il génère des données au format JSON.
Voici un exemple de configuration de connecteur Kafka :
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
La communication avec Kafka à l'aide du connecteur source Aerospike Kafka (sortant) nécessite la réplication Aerospike entre centres de données (XDR), qui réplique de manière asynchrone les modifications apportées au cluster sur des liens à latence plus élevée. XDR n'est disponible que dans l'édition Aerospike Enterprise. Si vous utilisez l'édition Community d'Aerospike, passez à l'édition Enterprise ou effectuez une migration hors connexion en utilisant uniquement le job Dataflow AerospikeBackupToBigtable.
Voici un exemple de configuration pour XDR dans Aerospike :
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
Exporter des données depuis Aerospike
Une fois le flux de modifications lancé, générez une sauvegarde de l'ensemble de données Aerospike existant. Utilisez l'outil de ligne de commande asbackup pour créer des sauvegardes à partir d'un cluster de bases de données Aerospike. Il est possible que certaines mises à jour apparaissent à la fois dans la sauvegarde et dans le flux de modifications. Ce comportement est normal et n'a aucune incidence sur la migration. Pour autoriser les importations parallèles lors de la restauration, divisez les sauvegardes en plusieurs fichiers.
Importer des données dans Bigtable
Pour importer des données sauvegardées dans Bigtable, procédez comme suit :
- Importez la sauvegarde dans un bucket Cloud Storage.
- Exécutez le job Dataflow
AerospikeBackupToBigtablepour importer la sauvegarde dans Bigtable. Si la sauvegarde est répartie sur plusieurs fichiers, le job les traite en parallèle. Pour gérer la charge d'écriture accrue et maintenir un débit optimal, provisionnez des ressources Bigtable supplémentaires.
Appliquer les modifications apportées aux enregistrements à Bigtable
Après avoir importé la sauvegarde dans Bigtable, appliquez les mises à jour des enregistrements mis en mémoire tampon dans Kafka à Bigtable à l'aide du connecteur de récepteur Kafka Connect Bigtable.
Traduire les messages dans un format compatible
Les outils de migration Aerospike incluent le Replicator SMT, qui s'exécute dans Kafka Connect. Le réplicateur traduit les messages publiés par le connecteur source Aerospike Kafka (sortant) dans un format compatible avec le récepteur cible qui écrit les enregistrements dans Bigtable. La traduction est nécessaire, car le récepteur attend des données dans un format spécifique qui diffère de la façon dont Aerospike diffuse les modifications.
Le tableau suivant vous aide à estimer les ressources machine nécessaires pour atteindre un débit donné :
| Structure des enregistrements | Débit | Latence p99 |
|---|---|---|
| Plats | Jusqu'à 3 700 enregistrements par seconde et par vCPU | 300 ms |
| Nested | Jusqu'à 2 600 enregistrements par seconde et par vCPU | 300 ms |
Ces estimations supposent que les enregistrements sérialisés au format JSON ont une taille de 1 Ko. Le temps d'analyse augmente avec la complexité des structures de message, ce qui signifie que les objets imbriqués stockés dans les enregistrements Aerospike prennent plus de temps à analyser.
Vous pouvez utiliser la métrique consumer_lag pour vérifier le nombre de messages dans la file d'attente de traitement et mesurer le délai de réplication. Lorsque le récepteur a traité le backlog de messages du sujet, le décalage du consommateur diminue jusqu'à se stabiliser près de zéro. À ce moment-là, le récepteur traite les mises à jour Aerospike en temps quasi réel, ce qui vous prépare à la bascule. Vous pouvez utiliser sink-record-active-count pour vérifier le nombre de messages déjà traités.
Ingérer des messages avec le connecteur Kafka Connect Bigtable
Le connecteur de récepteur Kafka Connect Bigtable ingère les messages de Kafka vers Bigtable. Lorsque vous configurez le connecteur, définissez insert.mode sur REPLACE_IF_NEWEST pour vous assurer que l'enregistrement écrit dans la ligne cible de Bigtable est le plus récent. Pour en savoir plus, consultez Configuration du connecteur de récepteur Kafka Connect Bigtable.
Le tableau suivant fournit des indications sur la latence introduite et les ressources de calcul requises pour différentes charges de travail :
| Structure des enregistrements | Débit | Latence p99 |
|---|---|---|
| Plats | Jusqu'à 3 700 enregistrements par seconde et par vCPU | 74 ms |
| Nested | Jusqu'à 3 700 enregistrements par seconde et par vCPU | 100 ms |
Ces estimations supposent que les enregistrements sérialisés au format JSON ont une taille de 1 Ko. La latence signalée correspond au temps de traitement dans le récepteur. Supposons une surcharge supplémentaire d'environ 600 ms pour effectuer une requête d'écriture dans Bigtable.
Passer à Bigtable
Passez à Bigtable comme base de données principale pour l'application.
Pour garantir la cohérence de type "lecture de vos écritures", arrêtez temporairement l'application jusqu'à ce que le délai de réplication atteigne zéro. Cela garantit qu'aucune mutation n'est perdue et que les lectures de données reflètent l'état le plus récent.
Par exemple, une mutation appliquée dans Aerospike juste avant la transition peut ne pas avoir encore été répliquée dans Bigtable, ce qui entraîne des lectures obsolètes. Pour éviter ce cas de figure, gardez l'application hors connexion jusqu'à ce que les métriques consumer_lag et sink-record-active-count atteignent 0. Une fois toutes les modifications en attente propagées, redémarrez l'application avec Bigtable comme base de données principale.
Bien qu'une migration à chaud puisse éviter les temps d'arrêt, elle présente les contraintes suivantes :
- Les mutations appliquées dans Bigtable ne sont pas répliquées dans Aerospike.
- Les mutations provenant d'Aerospike peuvent apparaître dans Bigtable avec un certain délai.
- Les mutations différées d'Aerospike peuvent remplacer les mises à jour plus récentes dans Bigtable.
Vérifier le déploiement
Après le déploiement, validez les performances de l'application en examinant des métriques telles que les taux d'erreur, la latence et le coût. Vous pouvez également effectuer des vérifications de l'intégrité des données.
Surveillance et observabilité
Surveillez les métriques suivantes tout au long de la migration :
- Latence totale : calculée en ajoutant la latence du consommateur Kafka à
sink-record-active-count. Ces métriques indiquent le retard de Bigtable par rapport à Aerospike. Une valeur de latence stable est requise avant de rediriger le trafic vers Bigtable. - Utilisation du processeur et de la mémoire : surveillez l'utilisation du processeur et de la mémoire de tous les composants du pipeline de flux de modifications.
- Capacité de stockage Kafka : surveillez la capacité des déploiements Kafka autogérés. Si l'espace de stockage est plein, les nouveaux événements ne peuvent pas être mis en mémoire tampon, ce qui entraîne l'échec de la migration.
- Taux d'erreur des applications : surveillez les taux d'erreur et les sorties d'erreur de tous les éléments du pipeline de flux de modifications.
Limites
Les sections suivantes décrivent les limites à prendre en compte lors de la migration de données d'Aerospike vers Bigtable.
Cohérence des données pendant la migration
Lorsque vous utilisez l'outil asbackup pour générer la sauvegarde Aerospike, les enregistrements modifiés pendant le processus de sauvegarde peuvent être exclus, car le processus de sauvegarde ne prend pas en charge les sauvegardes atomiques. Cette limite n'a aucune incidence sur l'exactitude, car toutes les modifications apparaissent dans le flux de modifications.
Lors de l'importation de la sauvegarde dans Bigtable, chaque ligne est écrite avec un code temporel de dernière mise à jour (LUT) de 0.
Les mises à jour du flux de modifications sont appliquées en plus de la sauvegarde importée. Les lignes écrites à partir du flux utilisent la valeur LUT comme code temporel de la ligne Bigtable. La configuration du récepteur permet à une mise à jour avec un code temporel plus récent d'écraser une mise à jour plus ancienne. Cela garantit que toute modification rejouée à partir du flux écrase la ligne correspondante.
Utilisation du LUT
Le processus de migration utilise Aerospike XDR pour répliquer les modifications et s'appuie sur LUT pour résoudre les conflits. Étant donné que les LUT sont basées sur l'horloge système du nœud, elles ne sont pas forcément strictement monotones. Par conséquent, un enregistrement non actualisé peut parfois avoir une LUT plus récente et écraser un enregistrement plus récent. De plus, il est possible que le connecteur source Aerospike Kafka (sortant) ne conserve pas l'ordre exact des messages lors de la publication sur Kafka. Par conséquent, la LUT sert de marqueur de version faisant autorité, garantissant que seuls les enregistrements avec la dernière LUT sont appliqués à Bigtable.
Si un enregistrement est mis à jour après le démarrage du flux de modifications, mais avant la génération de la sauvegarde, il est possible que la sauvegarde capture la version la plus récente, tandis que le flux contient une version plus ancienne. Cette ancienne version peut temporairement écraser la plus récente. Toutefois, lorsque l'événement de flux suivant avec la LUT correcte arrive, la dernière version est restaurée. Pour éviter les incohérences, attendez que la réplication se stabilise et que le message non traité le plus ancien du pipeline soit plus récent que la sauvegarde avant d'effectuer la bascule.
Validation des données
Le pipeline de migration n'effectue pas de somme de contrôle des données en transit. Si vous avez besoin de vérifier l'intégrité des données de bout en bout, vous devez implémenter la validation.
Dépannage
Les sections suivantes décrivent les erreurs courantes qui peuvent se produire lors du processus de migration et fournissent des conseils pour les résoudre.
Erreurs d'importation de sauvegarde
Lors de l'importation de la sauvegarde Aerospike dans Bigtable, vous pouvez rencontrer les erreurs suivantes :
| Type d'erreur | Cause | Solution |
|---|---|---|
| Fichier de sauvegarde corrompu | Les fichiers de sauvegarde sont illisibles ou contiennent des enregistrements corrompus. Le job d'importation échoue. | Inspectez les fichiers concernés pour détecter les problèmes d'intégrité. Si elle est irrécupérable, générez une nouvelle sauvegarde et répétez l'importation. |
| Échecs d'écriture Bigtable | Des problèmes de connectivité ou de service Bigtable se produisent. L'importation ne devrait pas échouer. | Les enregistrements ayant échoué sont exportés vers un fichier de sortie d'erreur au format JSON. Réappliquez-les manuellement ou réessayez la tâche d'importation complète. |
| Données non compatibles | La sauvegarde contient des entrées qui ne peuvent pas être importées dans Bigtable. L'importation ne devrait pas échouer. | Les données non compatibles, telles que les UDF, sont signalées comme des avertissements dans les journaux des jobs. Consultez les journaux pour identifier les entrées non compatibles. |
Une fois l'importation de la sauvegarde terminée et les enregistrements non valides corrigés, vous pouvez appliquer le flux de modifications.
Erreurs liées aux flux de modifications
Lors de l'application du flux de modifications, des échecs peuvent se produire aux niveaux suivants :
- Erreurs SMT du réplicateur : SMT ne parvient pas à transformer les données produites par Aerospike.
- Erreurs de récepteur : les événements ne peuvent pas être appliqués à Bigtable.
Dans les deux cas, les événements ayant échoué sont redirigés vers un sujet Kafka dédié. Vous pouvez consigner les événements à des fins d'audit ou les traiter à l'aide d'une logique de récupération personnalisée.
Étapes suivantes
- Découvrez comment concevoir votre schéma.
- Découvrez comment démarrer la migration vers Google Cloud.
- Découvrez les stratégies à votre disposition pour transférer des ensembles de données volumineux.