
Questo documento è destinato a sviluppatori di software e amministratori di database che vogliono migrare applicazioni esistenti o progettare nuove applicazioni da utilizzare con Bigtable come database. Questo documento applica le tue conoscenze di Apache Cassandra all'utilizzo di Bigtable per descrivere i concetti che devi comprendere prima della migrazione. Per informazioni sugli strumenti open source che puoi utilizzare per completare la migrazione, vedi Migrazione da Cassandra a Bigtable.
Bigtable e Cassandra sono database distribuiti. Implementano archivi coppia chiave-valore multidimensionali che possono supportare decine di migliaia di query al secondo (QPS), letture e scritture a bassa latenza, archiviazione scalabile fino a petabyte di dati e tolleranza agli errori dei nodi.
Quando Bigtable è una buona destinazione per i carichi di lavoro Cassandra
Il miglior servizio Google Cloud per il tuo workload Cassandra dipende dai tuoi obiettivi di migrazione e dalla funzionalità Cassandra che ti serve dopo la migrazione.
Se si verifica una o più delle seguenti condizioni, Bigtable è ottimale:
- Vuoi un servizio completamente gestito senza periodi di manutenzione e con alta disponibilità.
- Hai bisogno di una scalabilità elastica che risponda automaticamente alle variazioni del traffico del server.
- È necessaria una latenza coerente in millisecondi a singola cifra per letture e scritture.
- Utilizzi tipi di raccolta, contatori o viste materializzate di Cassandra oltre ai tipi scalari, per i quali Bigtable è ottimizzato.
- Hai un'applicazione che utilizza il parametro
USING TIMESTAMP. - La velocità effettiva di scrittura e la latenza sono importanti quanto le letture.
- Ti affidi a uno dei modelli di replica a coerenza finale di Cassandra.
- Il tuo caso d'uso richiede uno spazio di archiviazione conveniente.
Per eseguire la migrazione delle applicazioni senza modificare il codice, puoi scegliere di gestire autonomamente Cassandra su GKE o utilizzare un partner come DataStax o ScyllaDB. Google CloudSe la tua applicazione è incentrata sulla lettura e vuoi eseguire il refactoring del codice per ottenere funzionalità di database relazionale elevata coerenzata, potresti prendere in considerazione Spanner.
Questo documento fornisce suggerimenti su cosa considerare durante il refactoring dell'applicazione, se scegli Bigtable come destinazione della migrazione per i tuoi carichi di lavoro Cassandra.
Come utilizzare questo documento
Non è necessario leggere questo documento dall'inizio alla fine. Sebbene questo documento fornisca un confronto tra i due database, puoi anche concentrarti sugli argomenti che si applicano al tuo caso d'uso o ai tuoi interessi.
Per aiutarti a confrontare Bigtable e Cassandra, questo documento:
- Confronta la terminologia, che può variare tra i due database.
- Fornisce una panoramica dei due sistemi di database.
- Esamina il modo in cui ogni database gestisce la modellazione dei dati per comprendere le diverse considerazioni di progettazione.
- Confronta il percorso seguito dai dati durante le scritture e le letture.
- Esamina il layout fisico dei dati per comprendere gli aspetti dell'architettura del database.
- Descrive come configurare la replica geografica in base ai tuoi requisiti e come dimensionare il cluster.
- Rivedi i dettagli relativi a gestione, monitoraggio e sicurezza dei cluster.
Confronto della terminologia
Anche se molti dei concetti utilizzati in Bigtable e Cassandra sono simili, ogni database ha convenzioni di denominazione leggermente diverse e sottili differenze.
Uno dei componenti di base di entrambi i database è la tabella di stringhe ordinate (SSTable). In entrambe le architetture, vengono create SSTable per rendere persistenti i dati utilizzati per rispondere alle query di lettura.
In un post del blog (2012), Ilya Grigorik scrive: "Una SSTable è un'astrazione semplice per memorizzare in modo efficiente un numero elevato di coppie chiave-valore ottimizzando al contempo l'elevata velocità effettiva e i carichi di lavoro di lettura o scrittura sequenziali".
La seguente tabella delinea e descrive i concetti condivisi e la terminologia corrispondente utilizzata da ciascun prodotto:
| Cassandra | Bigtable |
|---|---|
|
chiave primaria: un valore univoco a uno o più campi che determina il posizionamento e l'ordinamento dei dati. Chiave di partizione: un valore di uno o più campi che determina il posizionamento dei dati tramite hash coerente. colonna di clustering: un valore di uno o più campi che determina l'ordinamento lessicografico dei dati all'interno di una partizione. |
Chiave di riga: una stringa di byte singola e univoca che determina il posizionamento dei dati in base a un ordinamento lessicografico. Le chiavi composte vengono imitate unendo i dati di più colonne utilizzando un delimitatore comune, ad esempio i simboli cancelletto (#) o percentuale (%). |
| Nodo: una macchina responsabile della lettura e della scrittura dei dati associati a una serie di intervalli hash di partizioni di chiavichiave primariae. In Cassandra, i dati vengono archiviati in spazio di archiviazione a livello di blocco collegato al server nodo. | nodo: una risorsa di calcolo virtuale responsabile della lettura e della scrittura dei dati associati a una serie di intervalli di chiave di riga. In Bigtable, i dati non sono colocalizzati con i nodi di calcolo. ma in Colossus, il file system distribuito di Google. Ai nodi viene assegnata la responsabilità temporanea di gestire vari intervalli di dati in base al carico operativo e allo stato degli altri nodi del cluster. |
|
Data center: simile a un cluster Bigtable, tranne per alcuni aspetti della topologia e della strategia di replica configurabili in Cassandra. Rack: un raggruppamento di nodi in un data center che influenza il posizionamento delle repliche. |
cluster: un gruppo di nodi nella stessa zona geografica,Google Cloud collocati insieme per problemi di latenza e replica. |
| Cluster: un deployment di Cassandra costituito da una raccolta di data center. | istanza: un gruppo di cluster Bigtable in zone o regioni Google Cloud diverse tra cui si verificano la replica e il routing delle connessioni. |
| vnode: un intervallo fisso di valori hash assegnati a un nodo fisico specifico. I dati in un vnode vengono archiviati fisicamente sul nodo Cassandra in una serie di SSTable. | tablet: una tabella SSTable contenente tutti i dati per un intervallo contiguo di chiavi di riga ordinate lessicograficamente. I tablet non vengono archiviati sui nodi in Bigtable, ma in una serie di SSTable su Colossus. |
| fattore di replica: il numero di repliche di un vnode mantenute in tutti i nodi del data center. Il fattore di replica viene configurato separatamente per ogni data center. | Replica: il processo di replica dei dati archiviati in Bigtable in tutti i cluster dell'istanza. La replica all'interno di un cluster zonale viene gestita dal livello di archiviazione Colossus. |
| tabella (in precedenza famiglia di colonne): un'organizzazione logica di valori indicizzati dalla chiave primaria univoca. | tabella: un'organizzazione logica di valori indicizzati dalla chiave di riga univoca. |
| keyspace: uno spazio dei nomi logico della tabella che definisce il fattore di replica per le tabelle che contiene. | Non applicabile. Bigtable gestisce i problemi relativi allo spazio delle chiavi in modo trasparente. |
| map: un tipo di raccolta Cassandra che contiene coppie chiave-valore. | Famiglia di colonne: uno spazio dei nomi specificato dall'utente che raggruppa i qualificatori di colonna per letture e scritture più efficienti. Quando esegui query Bigtable utilizzando SQL, le famiglie di colonne vengono trattate come le mappe di Cassandra. |
| Chiave mappa: chiave che identifica in modo univoco una coppia chiave-valore in una mappa Cassandra | Qualificatore di colonna: un'etichetta per un valore archiviato in una tabella indicizzata dalla chiave di riga univoca. Quando esegui query su Bigtable utilizzando SQL, le colonne vengono trattate come chiavi di una mappa. |
| Colonna: l'etichetta di un valore memorizzato in una tabella indicizzata dalla chiave primaria univoca. | colonna: l'etichetta di un valore memorizzato in una tabella indicizzata dalla chiave di riga univoca. Il nome della colonna viene creato combinando la famiglia di colonne con il qualificatore di colonna. |
| Cella: un valore timestamp in una tabella associato all'intersezione di una chiave primaria con la colonna. | Cella: un valore timestamp in una tabella associato all'intersezione di una chiave di riga con il nome della colonna. È possibile memorizzare e recuperare più versioni con timestamp per ogni cella. |
| counter: un tipo di campo incrementabile ottimizzato per le operazioni di somma di numeri interi. | Contatori: celle che utilizzano tipi di dati specializzati per operazioni di somma di numeri interi. Per saperne di più, consulta Creare e aggiornare contatori. |
| Policy di bilanciamento del carico: una policy che configuri nella logica dell'applicazione per indirizzare le operazioni a un nodo appropriato nel cluster. Il criterio tiene conto della topologia del data center e degli intervalli di token dei nodi virtuali. | profilo dell'applicazione: impostazioni che indicano a Bigtable come indirizzare una chiamata API client al cluster appropriato nell'istanza. Puoi anche utilizzare il profilo dell'applicazione come tag per segmentare le metriche. Configura il profilo dell'applicazione nel servizio. |
| CQL: il Cassandra Query Language, un linguaggio simile a SQL utilizzato per la creazione di tabelle, le modifiche dello schema, le mutazioni delle righe e le query. | Il client da Cassandra a Bigtable per Java è un sostituto perfetto per i tuoi driver Cassandra. Il client Java comprende le tue query CQL e ti consente di utilizzare Bigtable in modo trasparente con la tua applicazione esistente basata su Cassandra senza riscrivere il codice. L'adattatore proxy da Cassandra a Bigtable è un livello autonomo che puoi eseguire in parallelo all'applicazione e connetterti a Bigtable come a un altro nodo Cassandra. L'adattatore proxy fornisce la compatibilità con CQL e supporta la scrittura doppia e le migrazioni collettive. Questa funzionalità è simile a quella offerta dal client Cassandra to Bigtable per Java. Le API Bigtable sono le librerie client e le API gRPC utilizzate per la creazione di istanze e cluster, la creazione di tabelle e famiglia di colonne, la mutazione delle righe e l'esecuzione delle query. L'API Bigtable SQL è familiare agli utenti di CQL. |
Vista materializzata: un'istruzione SELECT che definisce un insieme
di righe corrispondenti a quelle di una tabella di origine sottostante. Quando la tabella di origine cambia, Cassandra aggiorna automaticamente la vista materializzata.
|
vista materializzata continua: un risultato precalcolato e completamente gestito di una query SQL che viene aggiornata in modo incrementale e automatico da una tabella di origine. Per saperne di più, consulta Viste materializzate continue. |
Panoramiche dei prodotti
Le sezioni seguenti forniscono una panoramica della filosofia di progettazione e degli attributi chiave di Bigtable e Cassandra.
Bigtable
Bigtable fornisce molte delle funzionalità principali descritte nell'articolo Bigtable: A Distributed Storage System for Structured Data. Bigtable separa i nodi di computing, che gestiscono le richieste dei client, dalla gestione dell'archiviazione sottostante. I dati vengono archiviati su Colossus. Il livello di archiviazione replica automaticamente i dati per fornire una durabilità che supera i livelli forniti dalla replica a tre vie standard di Hadoop Distributed File System (HDFS).
Questa architettura fornisce letture e scritture coerenti all'interno di un cluster, esegue lo scale up e lo scale down senza costi di ridistribuzione dell'archiviazione e può ribilanciare i carichi di lavoro senza modificare il cluster o lo schema. Se un nodo di elaborazione dei dati viene danneggiato, il servizio Bigtable lo sostituisce in modo trasparente. Bigtable supporta anche la replica asincrona.
Oltre a gRPC e alle librerie client per vari linguaggi di programmazione, Bigtable mantiene la compatibilità con la libreria client Java HBase open source Apache, un'implementazione alternativa del motore del database open source dell'articolo su Bigtable.
Il seguente diagramma mostra come Bigtable separa fisicamente i nodi di elaborazione dal livello di archiviazione:
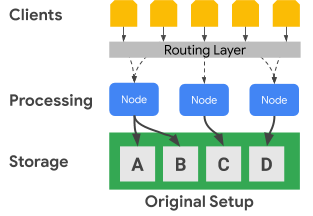
Nel diagramma precedente, il nodo di elaborazione centrale è responsabile solo della gestione delle richieste di dati per il set di dati C nel livello di archiviazione. Se Bigtable identifica che è necessario il ribilanciamento dell'assegnazione dell'intervallo per un set di dati, gli intervalli di dati per un nodo di elaborazione sono semplici da modificare perché il livello di archiviazione è separato dal livello di elaborazione.
Il seguente diagramma mostra, in termini semplificati, un ribilanciamento dell'intervallo di chiavi e un ridimensionamento del cluster:
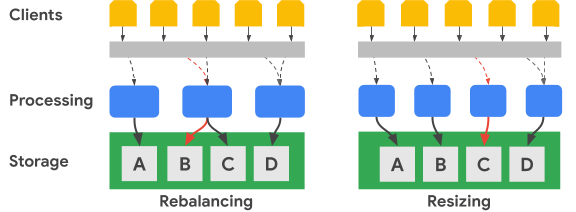
L'immagine Ribilanciamento mostra lo stato del cluster Bigtable dopo che il nodo di elaborazione più a sinistra riceve un numero maggiore di richieste per il set di dati A. Dopo il ribilanciamento, il nodo centrale, anziché il nodo più a sinistra, è responsabile della gestione delle richieste di dati per il set di dati B. Il nodo più a sinistra continua a gestire le richieste per il set di dati A.
Bigtable può riorganizzare gli intervalli di chiave di riga per bilanciare gli intervalli del set di dati su un numero maggiore di nodi di elaborazione disponibili. L'immagine Ridimensionamento mostra lo stato del cluster Bigtable dopo l'aggiunta di un nodo.
Cassandra
Apache Cassandra è un database open source in parte influenzato dai concetti del documento Bigtable. Utilizza un'architettura di nodi distribuiti, in cui lo spazio di archiviazione è collocato insieme ai server che rispondono alle operazioni sui dati. A ogni server viene assegnata in modo casuale una serie di nodi virtuali (vnode) per gestire una parte dello spazio delle chiavi del cluster.
I dati vengono archiviati nei nodi virtuali in base alla chiave di partizione. In genere, viene utilizzata una funzione hash coerente per generare un token per determinare il posizionamento dei dati. Come per Bigtable, puoi utilizzare un partizionatore che preserva l'ordine per la generazione di token e, di conseguenza, anche per il posizionamento dei dati. Tuttavia, la documentazione di Cassandra sconsiglia questo approccio perché è probabile che il cluster diventi sbilanciato, una condizione difficile da risolvere. Per questo motivo, questo documento presuppone che tu utilizzi una strategia di hashing coerente per generare token che comportino la distribuzione dei dati tra i nodi.
Cassandra offre tolleranza di errore tramite livelli di disponibilità correlati al livello di coerenza regolabile, consentendo a un cluster di servire i client mentre uno o più nodi sono danneggiati. Definisci la replica geografica tramite una strategia di topologia di replica dei dati configurabile.
Specifichi un livello di coerenza per ogni operazione. L'impostazione tipica è
QUORUM (o LOCAL_QUORUM in determinate topologie multi-data center). Questa
impostazione del livello di coerenza richiede che la maggior parte dei nodi di replica risponda al
nodo coordinatore affinché l'operazione venga considerata riuscita. Il fattore di replica, che configuri per ogni keyspace, determina il numero di repliche dei dati archiviate in ogni data center del cluster. Ad esempio, è
normale utilizzare un valore del fattore di replica pari a 3 per fornire un equilibrio pratico
tra durabilità e volume di archiviazione.
Il seguente diagramma mostra in termini semplificati un cluster di sei nodi con l'intervallo di chiavi di ogni nodo suddiviso in cinque nodi virtuali. In pratica, puoi avere più nodi e probabilmente avrai più vnode.

Nel diagramma precedente, puoi vedere il percorso di un'operazione di scrittura, con un
livello di coerenza di QUORUM, che ha origine da un'applicazione client o
servizio (Client). Ai fini di questo diagramma, gli intervalli di chiavi sono mostrati
come intervalli alfabetici. In realtà, i token prodotti da un hash della chiave primaria sono numeri interi con segno molto grandi.
In questo esempio, l'hash della chiave è M e i vnode per M si trovano sui nodi 2, 4 e 6. Il coordinatore deve contattare ogni nodo in cui gli intervalli di hash delle chiavi sono
memorizzati localmente in modo che la scrittura possa essere elaborata. Poiché il livello di coerenza
è QUORUM, due repliche (la maggioranza) devono rispondere al nodo coordinatore
prima che il client venga informato che la scrittura è stata completata.
A differenza di Bigtable, lo spostamento o la modifica degli intervalli di chiavi in Cassandra richiede la copia fisica dei dati da un nodo all'altro. Se un nodo è sovraccarico di richieste per un determinato intervallo di hash di token, l'aggiunta dell'elaborazione per quell'intervallo di token è più complessa in Cassandra rispetto a Bigtable.
Replica e coerenza geografica
Bigtable e Cassandra gestiscono la replica e la coerenza geografica (nota anche come multiregionale) in modo diverso. Un cluster Cassandra è costituito da nodi di elaborazione raggruppati in rack e i rack sono raggruppati in data center. Cassandra utilizza una strategia di topologia di rete che configuri per determinare in che modo le repliche dei nodi virtuali vengono distribuite tra gli host in un data center. Questa strategia rivela le origini di Cassandra come database originariamente implementato in data center fisici on-premise. Questa configurazione specifica anche il fattore di replica per ogni data center del cluster.
Cassandra utilizza le configurazioni di data center e rack per migliorare la tolleranza agli errori delle repliche dei dati. Durante le operazioni di lettura e scrittura, la topologia determina i nodi partecipanti necessari per fornire garanzie di coerenza. Devi configurare manualmente nodi, rack e data center quando crei o estendi un cluster. All'interno di un ambiente cloud, un deployment Cassandra tipico considera una zona cloud come un rack e una regione cloud come un data center.
Puoi utilizzare i controlli del quorum di Cassandra per regolare le garanzie di coerenza per
ogni operazione di lettura o scrittura. I livelli di forza della coerenza finale possono
variare, incluse le opzioni che richiedono un singolo nodo di replica (ONE), una
maggioranza di nodi di replica di un singolo data center (LOCAL_QUORUM) o una maggioranza di tutti
i nodi di replica in tutti i data center (QUORUM).
In Bigtable, i cluster sono risorse di zona. Un'istanza Bigtable può contenere un singolo cluster oppure un gruppo di cluster completamente replicati. Puoi posizionare i cluster di istanze in qualsiasi combinazione di zone in qualsiasi regione offerta da Google Cloud . Puoi aggiungere e rimuovere cluster da un'istanza con un impatto minimo sugli altri cluster dell'istanza.
In Bigtable, le scritture vengono eseguite (con coerenza read-your-writes) su un singolo cluster e alla fine saranno coerenti negli altri cluster dell'istanza. Poiché le singole celle sono versionate in base al timestamp, non vengono perse scritture e ogni cluster gestisce le celle con i timestamp più recenti disponibili.
Il servizio espone lo stato di coerenza del cluster. L'API Cloud Bigtable fornisce un meccanismo per ottenere un token di coerenza a livello di tabella. Puoi utilizzare questo token per verificare se tutte le modifiche apportate alla tabella prima della creazione del token sono state replicate completamente.
Supporto per le transazioni
Sebbene nessuno dei due database supporti transazioni multiriga complesse, entrambi supportano le transazioni.
Cassandra ha un metodo di transazione leggera (LWT) che fornisce atomicità per gli aggiornamenti dei valori delle colonne in una singola partizione. Cassandra ha anche la semantica confronta e imposta che completa l'operazione di lettura della riga e il confronto dei valori prima dell'avvio di un'operazione di scrittura.
Bigtable supporta scritture a riga singola completamente coerenti all'interno di un cluster. Le transazioni su riga singola sono ulteriormente abilitate tramite le operazioni ReadModifyWrite e CheckAndMutate. I profili dell'applicazione di routing multicluster non supportano le transazioni a riga singola.
Modello dei dati
Bigtable e Cassandra organizzano i dati in tabelle che supportano ricerche e scansioni di intervalli utilizzando l'identificatore univoco della riga. Entrambi i sistemi sono classificati come spazi di archiviazione a colonne larghe NoSQL.
In Cassandra devi utilizzare CQL per creare in anticipo lo schema completo della tabella, inclusa la definizione della chiave primaria insieme ai nomi delle colonne e ai relativi tipi. Le chiavi primarie in Cassandra sono valori compositi unici costituiti da una chiave di partizione obbligatoria e una chiave di clustering facoltativa. La chiave di partizionamento determina il posizionamento dei nodi di una riga, mentre la chiave di clustering determina l'ordinamento all'interno di una partizione. Quando crei schemi, devi essere consapevole dei potenziali compromessi tra l'esecuzione di scansioni efficienti all'interno di una singola partizione e i costi di sistema associati alla gestione di partizioni di grandi dimensioni.
In Bigtable, devi solo creare la tabella e definire le relative famiglie di colonne in anticipo. Le colonne non vengono dichiarate quando vengono create le tabelle, ma vengono create quando le chiamate API dell'applicazione aggiungono celle alle righe della tabella.
Le chiavi riga sono ordinate lessicograficamente nel cluster Bigtable. I nodi all'interno di Bigtable bilanciano automaticamente la responsabilità nodale per gli intervalli di chiavi, spesso indicati come tablet e a volte come divisioni. Le chiavi di riga Bigtable sono spesso costituite da diversi valori di campo uniti utilizzando un carattere separatore di uso comune che scegli (ad esempio il segno di percentuale). Se separati, i singoli componenti della stringa sono analoghi ai campi di una chiave primaria Cassandra.
Progettazione della chiave di riga
In Bigtable, l'identificatore univoco di una riga della tabella è la chiave di riga . La chiave di riga deve essere un singolo valore univoco in un'intera tabella. Puoi creare chiavi in più parti concatenando elementi disparati separati da un delimitatore comune. La chiave di riga determina l'ordinamento globale dei dati in una tabella. Il servizio Bigtable determina in modo dinamico gli intervalli di chiavi assegnati a ogni nodo.
A differenza di Cassandra, in cui l'hash della chiave di partizione determina il posizionamento delle righe e le colonne di clustering determinano l'ordinamento, la chiave di riga Bigtable fornisce sia l'assegnazione dei nodi sia l'ordinamento. Come per Cassandra, devi progettare una chiave di riga in Bigtable in modo che le righe che vuoi recuperare insieme vengano archiviate insieme. Tuttavia, in Bigtable non è necessario progettare la chiave di riga per il posizionamento e l'ordinamento prima di utilizzare una tabella.
Tipi di dati
Il servizio Bigtable non applica i tipi di dati delle colonne inviati dal client. Le librerie client forniscono metodi helper per scrivere valori delle celle come byte, stringhe codificate UTF-8 e interi a 64 bit codificati (gli interi codificati big-endian sono necessari per le operazioni di incremento atomico).
Famiglia di colonne
In Bigtable, una famiglia di colonne determina quali colonne di una tabella vengono archiviate e recuperate insieme. Ogni tabella ha bisogno di almeno una famiglia di colonne, anche se spesso le tabelle ne hanno di più (il limite è di 100 famiglie di colonne per tabella). Devi creare esplicitamente le famiglie di colonne prima che un'applicazione possa utilizzarle in un'operazione.
Qualificatori di colonna
Ogni valore memorizzato in una tabella in corrispondenza di una chiave di riga è associato a un'etichetta chiamata qualificatore di colonna. Poiché i qualificatori di colonna sono solo etichette, non esiste un limite pratico al numero di colonne che puoi avere in una famiglia di colonne. I qualificatori di colonna vengono spesso utilizzati in Bigtable per rappresentare i dati delle applicazioni.
Cellule
In Bigtable, una cella è l'intersezione della chiave di riga e del nome della colonna (una famiglia di colonne combinata con un qualificatore di colonna). Ogni cella contiene uno o più valori con timestamp che possono essere forniti dal client o applicati automaticamente dal servizio. I vecchi valori delle celle vengono recuperati in base a norme di garbage collection configurate a livello di famiglia di colonne.
Indici secondari
Puoi utilizzare le viste materializzate continue come indici secondari asincroni per le tabelle per eseguire query sugli stessi dati utilizzando attributi o pattern di ricerca diversi. Per maggiori informazioni, consulta Crea un indice secondario asincrono.
Modellazione dei dati: flessibilità con le raccolte
L'adattatore proxy da Cassandra a Bigtable trasforma i tipi di raccolta Cassandra, come mappe, set ed elenchi, in famiglie di colonne in Bigtable. In questo modo, l'utilizzo di Bigtable con i tipi di raccolta Cassandra è molto efficiente, in quanto le singole colonne possono essere scritte e lette molto più velocemente dei singoli blob.
Con Bigtable, puoi creare applicazioni con raccolte grandi e dinamiche senza i compromessi sulle prestazioni richiesti da Cassandra, per i seguenti motivi:
- Bigtable archivia gli elementi della raccolta come singole celle, in modo che le operazioni sugli elementi siano molto granulari. Ciò significa che un singolo aggiornamento della mappa si traduce in una scrittura leggera della cella, che offre prestazioni elevate e scalabilità.
- Le raccolte Bigtable non hanno limiti di dimensioni pratici, a parte i limiti di dimensione delle righe generali.
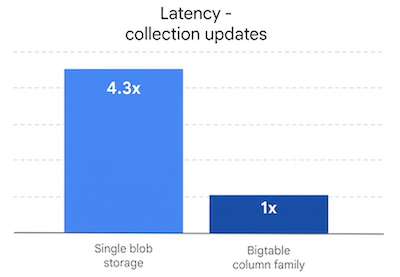
- Bigtable mantiene una latenza bassa e costante indipendentemente dalle dimensioni della raccolta, come mostrato nella Figura 4.
Al contrario, la documentazione di Cassandra ti incoraggia a limitare rigorosamente l'utilizzo dei tipi di raccolta e a limitare spesso il numero di elementi a numeri ridotti a causa del peggioramento delle prestazioni. Poiché Cassandra legge le colonne della raccolta nel loro complesso, le raccolte di grandi dimensioni causano inevitabilmente picchi di latenza di lettura e potenziale instabilità dei nodi.
Puoi aggirare questi limiti con soluzioni alternative come le raccolte bloccate o l'archiviazione dei dati come stringhe JSON, che sacrificano le prestazioni introducendo una tassa di lettura-modifica-scrittura. Questo sovraccarico costringe il database a leggere, deserializzare, aggiornare e riscrivere l'intero oggetto per qualsiasi modifica. Inoltre, Cassandra tratta questi blob JSON come testo opaco, richiedendo tutta la logica di analisi nel livello dell'applicazione. A differenza di Bigtable, che fornisce l'elaborazione lato server integrata per le stringhe JSON tramite le funzioni dell'API SQL.
Bigtable ti consente di combinare elementi dello schema fissi con elementi dinamici senza compromessi. In questo modo, le tue applicazioni hanno la flessibilità di applicare la struttura dove è importante, pur rimanendo agili, il che ti consente di evolvere il tuomodello dei datiti senza migrazioni o tempi di inattività estesi. Supporta anche carichi di lavoro moderni, come machine learning e AI, che richiedono iterazioni frequenti su feature store e serving in tempo reale su scala globale.
Bilanciamento del carico e failover lato client
In Cassandra, il client controlla il bilanciamento del carico delle richieste. Il driver client imposta una policy specificata come parte della configurazione o a livello di programmazione durante la creazione della sessione. Il cluster informa il criterio sui data center più vicini all'applicazione e il client identifica i nodi di questi data center per gestire un'operazione.
Il servizio Bigtable instrada le chiamate API a un cluster di destinazione in base a un parametro (un identificatore del profilo dell'applicazione) fornito con ogni operazione. I profili dell'applicazione vengono gestiti all'interno del servizio Bigtable; le operazioni client che non selezionano un profilo utilizzano un profilo predefinito.
Bigtable ha due tipi di criteri di routing dei profili dell'applicazione: a cluster singolo e a più cluster. Un profilo multi-cluster indirizza le operazioni al cluster disponibile più vicino. I cluster nella stessa regione sono considerati equidistanti dal punto di vista del router delle operazioni. Se il nodo responsabile dell'intervallo di chiavi richiesto è sovraccarico o temporaneamente non disponibile in un cluster, questo tipo di profilo fornisce il failover automatico.
In termini di Cassandra, una policy multicluster offre i vantaggi del failover di una policy di bilanciamento del carico che riconosce i data center.
Un profilo dell'applicazione con routing a un cluster singolo indirizza tutto il traffico a un singolo cluster. La coerenza delle righe e le transazioni su riga singola sono disponibili solo nei profili con routing a cluster singolo.
Lo svantaggio di un approccio a cluster singolo è che, in caso di failover, l'applicazione deve essere in grado di riprovare utilizzando un identificatore del profilo dell'applicazione alternativo oppure devi eseguire manualmente il failover dei profili di routing a cluster singolo interessati.
Routing delle operazioni
Cassandra e Bigtable utilizzano metodi diversi per selezionare il nodo di elaborazione per le operazioni di lettura e scrittura. In Cassandra viene identificata la chiave di partizione, mentre in Bigtable viene utilizzata la chiave di riga.
In Cassandra, il client ispeziona prima la policy di bilanciamento del carico. Questo oggetto lato client determina il data center a cui viene indirizzata l'operazione.
Una volta identificato il data center, Cassandra contatta un nodo coordinatore per gestire l'operazione. Se le norme riconoscono i token, il coordinatore è un nodo che pubblica i dati dalla partizione vnode di destinazione; altrimenti, il coordinatore è un nodo casuale. Il nodo coordinatore identifica i nodi in cui si trovano le repliche dei dati per la chiave di partizione dell'operazione e poi indica a questi nodi di eseguire l'operazione.
In Bigtable, come discusso in precedenza, ogni operazione include un identificatore del profilo di applicazione. Il profilo dell'applicazione è definito a livello di servizio. Il livello di routing di Bigtable esamina il profilo per scegliere il cluster di destinazione appropriato per l'operazione. Il livello di routing fornisce quindi un percorso per l'operazione per raggiungere i nodi di elaborazione corretti utilizzando la chiave di riga dell'operazione.
Processo di scrittura dei dati
Entrambi i database sono ottimizzati per scritture veloci e utilizzano un processo simile per completare una scrittura. Tuttavia, i passaggi eseguiti dai database variano leggermente, soprattutto per Cassandra, dove, a seconda del livello di coerenza dell'operazione, potrebbe essere necessaria la comunicazione con nodi partecipanti aggiuntivi.
Dopo che la richiesta di scrittura viene indirizzata ai nodi (Cassandra) o al nodo (Bigtable) appropriati, le scritture vengono prima rese persistenti sul disco in sequenza in un log di commit (Cassandra) o in un log condiviso (Bigtable). Successivamente, le scritture vengono inserite in una tabella in memoria (nota anche come memtable) che è ordinata come le SSTable.
Dopo questi due passaggi, il nodo risponde per indicare che la scrittura è stata completata. In Cassandra, diverse repliche (a seconda del livello di coerenza specificato per ogni operazione) devono rispondere prima che il coordinatore informi il client che la scrittura è completata. In Bigtable, poiché ogni chiave di riga viene assegnata a un solo nodo in un determinato momento, una risposta dal nodo è tutto ciò che serve per confermare che una scrittura è riuscita.
In un secondo momento, se necessario, puoi svuotare la memtable sul disco sotto forma di una nuova SSTable. In Cassandra, lo svuotamento si verifica quando il log di commit raggiunge una dimensione massima o quando la memtable supera una soglia che configuri. In Bigtable, viene avviato un flush per creare nuove SSTable immutabili quando la memtable raggiunge una dimensione massima specificata dal servizio. Periodicamente, un processo di compattazione unisce le SSTable per un determinato intervallo di chiavi in un'unica SSTable.
Aggiornamenti dei dati
Entrambi i database gestiscono gli aggiornamenti dei dati in modo simile. Tuttavia, Cassandra consente un solo valore per ogni cella, mentre Bigtable può conservare un numero elevato di valori con controllo delle versioni per ogni cella.
Quando il valore all'intersezione di un identificatore di riga univoco e di una colonna viene modificato, l'aggiornamento viene mantenuto come descritto in precedenza nella sezione Processo di scrittura dei dati. Il timestamp di scrittura viene memorizzato insieme al valore nella struttura SSTable.
Se non hai scaricato una cella aggiornata in una SSTable, puoi memorizzare solo il valore della cella nella memtable, ma i database differiscono per ciò che viene memorizzato. Cassandra salva solo il valore più recente nella memtable, mentre Bigtable salva tutte le versioni nella memtable.
In alternativa, se hai scaricato almeno una versione di un valore di cella su disco in SSTable separate, i database gestiscono le richieste per questi dati in modo diverso. Quando la cella viene richiesta da Cassandra, viene restituito solo il valore più recente in base al timestamp; in altre parole, l'ultima scrittura ha la precedenza. In Bigtable, utilizzi i filtri per controllare quali versioni delle celle vengono restituite da una richiesta di lettura.
Eliminazioni di righe
Poiché entrambi i database utilizzano file SSTable immutabili per archiviare i dati sul disco, non è possibile eliminare immediatamente una riga. Per garantire che le query restituiscano i risultati corretti dopo l'eliminazione di una riga, entrambi i database gestiscono le eliminazioni utilizzando lo stesso meccanismo. Viene aggiunto prima un marcatore (chiamato tombstone in Cassandra) alla memtable. Alla fine, una SSTable appena scritta contiene un marcatore con timestamp che indica che l'identificatore univoco della riga è stato eliminato e non deve essere restituito nei risultati della query.
Durata
Le funzionalità di durata (TTL) nei due database sono simili, tranne per una disparità. In Cassandra, puoi impostare il TTL per una colonna o una tabella, mentre in Bigtable puoi impostare i TTL solo per la famiglia di colonne. Esiste un metodo per Bigtable che può simulare il TTL a livello di cella.
Garbage collection
Poiché gli aggiornamenti o le eliminazioni immediate dei dati non sono possibili con le SSTable immutabili, come discusso in precedenza, la garbage collection si verifica durante un processo chiamato compattazione. La procedura rimuove le celle o le righe che non devono essere visualizzate nei risultati della query.
Il processo di garbage collection esclude una riga o una cella quando si verifica un'unione di SSTable. Se esiste un indicatore o un segnaposto per una riga, questa non viene inclusa nella SSTable risultante. Entrambi i database possono escludere una cella dall'SSTable unita. Se il timestamp della cella supera una qualifica TTL, i database escludono la cella. Se per una determinata cella sono presenti due versioni con timestamp, Cassandra include solo il valore più recente nella SSTable unita.
Percorso di lettura dei dati
Quando un'operazione di lettura raggiunge il nodo di elaborazione appropriato, il processo di lettura per ottenere i dati per soddisfare un risultato della query è lo stesso per entrambi i database.
Per ogni SSTable sul disco che potrebbe contenere i risultati della query, viene controllato un filtro Bloom per determinare se ogni file contiene righe da restituire. Poiché i filtri Bloom non forniscono mai un falso negativo, tutte le SSTable idonee vengono aggiunte a un elenco di candidati da includere nell'ulteriore elaborazione dei risultati di lettura.
L'operazione di lettura viene eseguita utilizzando una vista unita creata dalla memtable e dalle SSTable candidate sul disco. Poiché tutte le chiavi sono ordinate in ordine lessicografico, è efficiente ottenere una visualizzazione unita che viene scansionata per ottenere i risultati della query.
In Cassandra, un insieme di nodi di elaborazione determinati dal livello di coerenza dell'operazione deve partecipare all'operazione. In Bigtable, deve essere consultato solo il nodo responsabile dell'intervallo di chiavi. Per Cassandra, devi considerare le implicazioni per il dimensionamento del calcolo, perché è probabile che più nodi elaborino ogni lettura.
I risultati di lettura possono essere limitati nel nodo di elaborazione in modi leggermente diversi.
In Cassandra, la clausola WHERE in una query CQL limita le righe restituite. Il vincolo è che le colonne della chiave primaria o le colonne incluse in un indice secondario possono essere utilizzate per limitare i risultati.
Bigtable offre un ampio assortimento di filtri che influiscono sulle righe o sulle celle recuperate da una query di lettura.
Esistono tre categorie di filtri:
- Filtri di limitazione, che controllano le righe o le celle incluse nella risposta.
- Modifica dei filtri, che influiscono sui dati o sui metadati delle singole celle.
- Composizione di filtri, che consente di combinare più filtri in uno solo.
I filtri di limitazione sono i più di uso comune, ad esempio l'espressione regolare della famiglia di colonne e l'espressione regolare del qualificatore di colonna .
Archiviazione fisica dei dati
Bigtable e Cassandra archiviano i dati in SSTable, che vengono unite regolarmente durante una fase di compattazione. La compressione dei dati SSTable offre vantaggi simili per la riduzione delle dimensioni dello spazio di archiviazione. Tuttavia, la compressione viene applicata automaticamente in Bigtable ed è un'opzione di configurazione in Cassandra.
Quando confronti i due database, devi capire in che modo ciascuno di essi memorizza fisicamente i dati in modo diverso nei seguenti aspetti:
- La strategia di distribuzione dei dati
- Il numero di versioni della cella disponibili
- Il tipo di disco di archiviazione
- Meccanismo di durabilità e replica dei dati
Distribuzione dei dati
In Cassandra, un hash coerente delle colonne di partizione della chiave primaria è il metodo consigliato per determinare la distribuzione dei dati nelle varie SSTable gestite dai nodi del cluster.
Bigtable utilizza un prefisso variabile per la chiave di riga completa per inserire i dati in ordine lessicografico nelle SSTable.
Versioni delle celle
Cassandra conserva una sola versione del valore della cella attiva. Se vengono eseguite due scritture in una cella, un criterio di priorità dell'ultima scrittura garantisce che venga restituito un solo valore.
Bigtable non limita il numero di versioni con timestamp per ogni cella. Potrebbero essere applicati altri limiti alle dimensioni delle righe. Se non viene impostato dalla richiesta del client, il timestamp viene determinato dal servizio Bigtable nel momento in cui il nodo di elaborazione riceve la mutazione. Le versioni delle celle possono essere eliminate utilizzando una policy di garbage collection che può essere diversa per ogni famiglia di colonne della tabella oppure possono essere filtrate da un insieme di risultati di query tramite l'API.
Archiviazione disco
Cassandra archivia le SSTable sui dischi collegati a ogni nodo del cluster. Per ribilanciare i dati in Cassandra, i file devono essere copiati fisicamente tra i server.
Bigtable utilizza Colossus per archiviare le SSTable. Poiché Bigtable utilizza questo file system distribuito, il servizio Bigtable può riassegnare quasi istantaneamente le SSTable a nodi diversi.
Durabilità e replica dei dati
Cassandra garantisce la durabilità dei dati tramite l'impostazione del fattore di replica. Il fattore di
replica determina il numero di copie SSTable archiviate su
nodi diversi nel cluster. Un'impostazione tipica per il fattore di replica è
3, che consente comunque garanzie di coerenza più solide con QUORUM o
LOCAL_QUORUM anche se si verifica un errore del nodo.
Con Bigtable, le garanzie di elevata durabilità dei dati vengono fornite tramite la replica fornita da Colossus.
Il seguente diagramma illustra il layout fisico dei dati, i nodi di elaborazione di calcolo e il livello di routing per Bigtable:

Nel livello di archiviazione Colossus, a ogni nodo viene assegnato il compito di gestire i dati memorizzati in una serie di SSTable. Queste SSTable contengono i dati per gli intervalli di chiave di riga assegnati dinamicamente a ogni nodo. Anche se il diagramma mostra tre SSTable per ogni nodo, è probabile che ce ne siano di più perché le SSTable vengono create continuamente man mano che i nodi ricevono nuove modifiche ai dati.
Ogni nodo ha un log condiviso. Scritture elaborate da ogni nodo vengono immediatamente salvate nel log condiviso prima che il client riceva una conferma di scrittura. Poiché una scrittura in Colossus viene replicata più volte, la durabilità è garantita anche se si verifica un errore hardware del nodo prima che i dati vengano salvati in modo permanente in una SSTable per l'intervallo di righe.
Interfacce applicative
In origine, l'accesso al database Cassandra era esposto tramite un'API Thrift, ma questo metodo di accesso è ritirato. L'interazione con il client consigliata avviene tramite CQL.
Analogamente all'API Thrift originale di Cassandra, l'accesso al database Bigtable viene fornito tramite un'API che legge e scrive dati in base alle chiavi di riga fornite.
Come Cassandra, Bigtable ha sia un'interfaccia a riga di comando,
chiamata CLI cbt,
sia librerie client che supportano molti linguaggi di programmazione
comuni. Queste librerie sono basate sulle API gRPC e REST. Le applicazioni scritte per Hadoop e che si basano sulla libreria open source
Apache HBase per Java possono connettersi senza modifiche
significative
a Bigtable. Per le applicazioni che non richiedono la compatibilità con HBase, ti consigliamo di utilizzare il client Java Bigtable integrato.
I controlli di Identity and Access Management (IAM) di Bigtable sono completamente integrati con Google Cloude le tabelle possono essere utilizzate anche come origine dati esterna da BigQuery.
Configurazione del database
Quando configuri un cluster Cassandra, devi prendere diverse decisioni di configurazione e completare alcuni passaggi. Innanzitutto, devi configurare i nodi server per fornire capacità di calcolo e provisioning dello spazio di archiviazione locale. Quando utilizzi un fattore di replica pari a tre, l'impostazione consigliata e più comune, devi eseguire il provisioning dello spazio di archiviazione per archiviare il triplo della quantità di dati che prevedi di archiviare nel cluster. Devi anche determinare e impostare le configurazioni per i nodi virtuali, i rack e la replica.
La separazione del calcolo dall'archiviazione in Bigtable semplifica l'aumento e la riduzione dei cluster rispetto a Cassandra. In un cluster in esecuzione normale, in genere ti preoccupi solo dello spazio di archiviazione totale utilizzato dalle tabelle gestite, che determina il numero minimo di nodi, e di avere un numero sufficiente di nodi per mantenere le QPS attuali.
Puoi modificare rapidamente le dimensioni del cluster Bigtable se il cluster è sovra o sotto provisioning in base al carico di produzione.
Spazio di archiviazione Bigtable
A parte la posizione geografica del cluster iniziale, l'unica scelta che devi fare quando crei l'istanza Bigtable è il tipo di archiviazione. Bigtable offre due opzioni di archiviazione: unità a stato solido (SSD) o unità disco rigido (HDD). Tutti i cluster di un'istanza devono condividere lo stesso tipo di archiviazione.
Quando tieni conto delle esigenze di archiviazione con Bigtable, non devi tenere conto delle repliche di archiviazione come faresti quando dimensiona un cluster Cassandra. Non si verifica alcuna perdita di densità di archiviazione per ottenere la tolleranza agli errori, come avviene in Cassandra. Inoltre, poiché lo spazio di archiviazione non deve essere esplicitamente provisionato, ti vengono addebitati solo i costi per lo spazio di archiviazione in uso.
SSD
La capacità del nodo SSD di 5 TB, preferita per la maggior parte dei carichi di lavoro, offre una densità di archiviazione superiore rispetto alla configurazione consigliata per le macchine Cassandra, che hanno una densità di archiviazione massima pratica inferiore a 2 TB per ogni nodo. Quando valuti le esigenze di capacità di archiviazione, ricorda che Bigtable conteggia una sola copia dei dati; al contrario, Cassandra deve tenere conto di tre copie dei dati nella maggior parte delle configurazioni.
Mentre le QPS di scrittura per SSD sono circa le stesse dell'HDD, l'SSD fornisce QPS di lettura significativamente superiori rispetto all'HDD. Il prezzo dell'archiviazione SSD è pari o vicino ai costi dei dischi permanenti SSD di cui è stato eseguito il provisioning e varia in base alla regione.
HDD
Il tipo di archiviazione HDD consente una densità di archiviazione considerevole: 16 TB per ogni nodo. Il compromesso è che le letture casuali sono molto più lente, supportando solo la lettura di 500 righe al secondo per ogni nodo. L'HDD è preferito per i workload con uso intensivo di scrittura in cui le letture dovrebbero essere scansioni di intervalli associate all'elaborazione batch. L'archiviazione HDD ha un prezzo pari o vicino al costo associato a Cloud Storage e varia in base alla regione.
Considerazioni sulle dimensioni del cluster
Quando dimensioni un'istanza Bigtable per prepararti alla migrazione di un carico di lavoro Cassandra, devi tenere conto di alcuni aspetti quando confronti i cluster Cassandra a un singolo data center con le istanze Bigtable a un singolo cluster e i cluster Cassandra a più data center con le istanze Bigtable multicluster. Le linee guida nelle sezioni seguenti presuppongono che non siano necessarie modifiche significative al modello dei dati per la migrazione e che la compressione dello spazio di archiviazione sia equivalente tra Cassandra e Bigtable.
Un cluster a un solo data center
Quando confronti un cluster a un solo data center con un'istanza Bigtable a un solo cluster, devi prima considerare i requisiti di archiviazione. Puoi stimare la dimensione non replicata di ogni spazio delle chiavi utilizzando
il comando nodetool tablestats
e dividendo la dimensione totale dello spazio di archiviazione scaricato per il fattore di replica
dello spazio delle chiavi. Poi, dividi la quantità di spazio di archiviazione non replicato di tutti gli spazi chiave per
3,5 TB (5 TB *
0,70
) per determinare il numero suggerito di nodi SSD per gestire solo lo spazio di archiviazione. Come
spiegato, Bigtable gestisce la replica e la durabilità dello spazio di archiviazione
in un livello separato trasparente per l'utente.
Successivamente, devi considerare i requisiti di calcolo per il numero di nodi. Puoi consultare le metriche del server Cassandra e dell'applicazione client per ottenere un numero approssimativo di letture e scritture sostenute eseguite. Per stimare il numero minimo di nodi SSD per eseguire il tuo workload, dividi questa metrica per 10.000. Probabilmente hai bisogno di più nodi per le applicazioni che richiedono risultati di query a bassa latenza. Google consiglia di testare le prestazioni di Bigtable con dati e query rappresentativi per stabilire una metrica per le QPS per nodo che è possibile ottenere per il tuo carico di lavoro.
Il numero di nodi richiesti per il cluster deve essere uguale al maggiore tra le esigenze di spazio di archiviazione e di calcolo. Se hai dubbi sulle tue esigenze di spazio di archiviazione o velocità effettiva, puoi abbinare il numero di nodi Bigtable al numero di macchine Cassandra tipiche. Puoi scalare un cluster Bigtable in base alle esigenze del carico di lavoro con il minimo sforzo e senza tempi di inattività.
Un cluster multi-data center
Con i cluster multidata center, è più difficile determinare la configurazione di un'istanza Bigtable. Idealmente, dovresti avere un cluster nell'istanza per ogni data center nella topologia Cassandra. Ogni cluster Bigtable nell'istanza deve archiviare tutti i dati all'interno dell'istanza e deve essere in grado di gestire la velocità di inserimento totale nell'intero cluster. I cluster in un'istanza possono essere creati in qualsiasi regione cloud supportata in tutto il mondo.
La tecnica per stimare le esigenze di spazio di archiviazione è simile all'approccio per i cluster a singolo data center. Utilizzi nodetool per acquisire le dimensioni dello spazio di archiviazione di
ogni keyspace nel cluster Cassandra e poi dividi le dimensioni per il numero
di repliche. Devi ricordare che lo spazio delle chiavi di una tabella potrebbe avere fattori di replica diversi per ogni data center.
Il numero di nodi in ogni cluster di un'istanza deve essere in grado di gestire tutte le scritture nel cluster e tutte le letture in almeno due data center per mantenere gli obiettivi di livello del servizio (SLO) durante un'interruzione del cluster. Un approccio comune consiste nell'iniziare con tutti i cluster con la capacità dei nodi equivalente del data center più trafficato del cluster Cassandra. I cluster Bigtable in un'istanza possono essere scalati individualmente per soddisfare le esigenze del carico di lavoro senza tempi di inattività.
Amministrazione
Bigtable fornisce componenti completamente gestiti per le funzioni di amministrazione comuni eseguite in Cassandra.
Backup e ripristino
Bigtable offre due metodi per soddisfare le esigenze comuni di backup: backup di Bigtable ed esportazioni di dati gestite.
Puoi considerare i backup Bigtable come analoghi a una versione gestita della funzionalità di snapshot nodetool di Cassandra. I backup di Bigtable
creano copie ripristinabili di una tabella, che vengono archiviate come oggetti membri
di un cluster. Puoi ripristinare i backup come una nuova tabella nel cluster che
ha avviato il backup. I backup sono progettati per creare punti di ripristino in caso di danneggiamento a livello di applicazione. I backup creati tramite questa
utilità non consumano risorse del nodo e hanno un prezzo pari o vicino a quello di
Cloud Storage. Puoi richiamare i backup Bigtable
in modo programmatico o tramite la console Google Cloud per Bigtable.
Un altro modo per eseguire il backup di Bigtable è utilizzare un'esportazione gestita dei dati in Cloud Storage. Puoi esportare nei formati Avro, Parquet o Hadoop Sequence File. Rispetto ai backup Bigtable, le esportazioni richiedono più tempo per l'esecuzione e comportano costi di calcolo aggiuntivi perché utilizzano Dataflow. Tuttavia, queste esportazioni creano file di dati portatili che puoi interrogare offline o importare in un altro sistema.
Ridimensionamento
Poiché Bigtable separa l'archiviazione e il calcolo, puoi aggiungere o rimuovere nodi Bigtable in risposta alla domanda di query in modo più semplice rispetto a Cassandra. L'architettura omogenea di Cassandra richiede di ribilanciare i nodi (o i nodi virtuali) tra le macchine del cluster.
Puoi modificare manualmente le dimensioni del cluster nella console Google Cloud o in modo programmatico utilizzando l'API Cloud Bigtable. L'aggiunta di nodi a un cluster può produrre miglioramenti delle prestazioni notevoli in pochi minuti. Alcuni clienti hanno utilizzato correttamente un gestore della scalabilità automatica open source sviluppato da Spotify .
Manutenzione interna
Il servizio Bigtable gestisce senza problemi le attività di manutenzione interna comuni di Cassandra, come l'applicazione di patch al sistema operativo, il recupero dei nodi, la riparazione dei nodi, il monitoraggio della compattazione dell'archiviazione e la rotazione dei certificati SSL.
Monitoraggio
Il collegamento di Bigtable alla visualizzazione delle metriche o agli avvisi non richiede interventi di amministrazione o sviluppo. La pagina della console Google Cloud Bigtable include dashboard predefinite per il monitoraggio delle metriche di velocità effettiva e utilizzo a livello di istanza, cluster e tabella. È possibile creare visualizzazioni e avvisi personalizzati nelle dashboard di Cloud Monitoring, dove le metriche sono disponibili automaticamente.
Key Visualizer di Bigtable, una funzionalità di monitoraggio nella console Google Cloud , ti consente di eseguire la messa a punto avanzata delle prestazioni.
IAM e sicurezza
In Bigtable, l'autorizzazione è completamente integrata nel framework IAM diGoogle Cloud e richiede una configurazione e una manutenzione minime. Gli account utente e le password locali non vengono condivisi con le applicazioni client. Vengono invece concesse autorizzazioni e ruoli granulari agli utenti a livello di organizzazione e agli service account.
Bigtable cripta automaticamente tutti i dati at-rest e in transito. Non sono disponibili opzioni per disattivare queste funzionalità. Tutti gli accessi amministrativi vengono completamente registrati . Puoi utilizzare i Controlli di servizio VPC per controllare l'accesso alle istanze Bigtable dall'esterno delle reti approvate.
Passaggi successivi
- Scopri di più sulla progettazione dello schema Bigtable.
- Scopri di più su Apache Cassandra.
- Prova il codelab Bigtable per gli utenti Cassandra.
- Scopri di più sull'emulatore Bigtable.
- Esplora architetture, diagrammi e best practice di riferimento su Google Cloud. Consulta il nostro Cloud Architecture Center.