
Crie um aplicativo de chat de IA generativa que usa a geração aumentada por recuperação (RAG, na sigla em inglês) para fornecer respostas fundamentadas e precisas com base nos dados da sua organização. Este guia descreve o modelo de aplicativo RAG de IA generativa com o Cloud SQL, que pode ser personalizado para atender às suas necessidades exclusivas e implantado como um aplicativo.
Por exemplo, você pode implementar esse modelo para atender às seguintes necessidades comerciais:
| Exemplo | Necessidade comercial | Implementação |
|---|---|---|
| Chatbot de suporte ao cliente | As empresas precisam oferecer suporte ao cliente instantâneo. | Hospede a interface de chat no Cloud Run. A Vertex AI processa embeddings e gera respostas com base na documentação técnica armazenada como vetores no Cloud SQL. |
| Assistente de RH interno | Os funcionários precisam encontrar informações sobre benefícios, políticas da empresa e procedimentos internos. | Hospede o assistente de RH no Cloud Run. Quando os funcionários consultam a ferramenta, a Vertex AI recupera informações relevantes sobre políticas do Cloud SQL para gerar respostas precisas e fundamentadas em fontes. |
| Pesquisador de documentos jurídicos | As equipes jurídicas precisam encontrar rapidamente jurisprudência relevante ou cláusulas contratuais em grandes repositórios de documentos. | Hospede o portal de pesquisa no Cloud Run. A Vertex AI resume precedentes relevantes e identifica linguagem específica em contratos usando documentos jurídicos armazenados como vetores no Cloud SQL. |
| Pesquisa semântica de produtos | As empresas de e-commerce querem facilitar a Pesquisa de produtos usando descrições em linguagem natural em vez de palavras-chave exatas. | Hospede a interface de pesquisa no Cloud Run. A Vertex AI processa as descrições do usuário para retornar os produtos mais relevantes semanticamente dos catálogos de produtos armazenados como vetores no Cloud SQL. |
Arquitetura
A imagem a seguir mostra os componentes e as conexões no aplicativo:
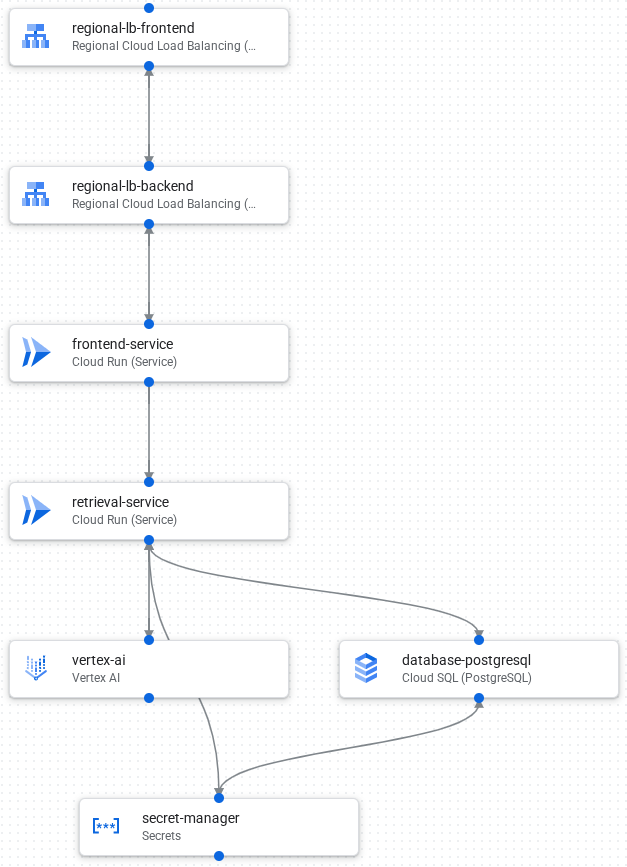
Confira a seguir o fluxo de processamento de solicitações do aplicativo:
- Carregue dados em um banco de dados PostgreSQL no Cloud SQL.
- O Vertex AI cria embeddings de campos de texto e os armazena como vetores no banco de dados.
- Um Cloud Load Balancing front-end recebe solicitações externas e distribui o tráfego para o back-end do Cloud Load Balancing.
- O back-end do Cloud Load Balancing distribui o tráfego para o serviço de front-end do Cloud Run.
- O serviço de front-end se comunica com um serviço de recuperação para uma chamada de IA generativa.
- O serviço de recuperação usa o Secret Manager para acessar com segurança as chaves de API e as credenciais necessárias para acessar a Vertex AI e o Cloud SQL.
- O serviço de recuperação converte a solicitação em um embedding e pesquisa vetores semelhantes no banco de dados do Cloud SQL.
- O serviço de recuperação envia os resultados da pesquisa, juntamente com o comando original, para a Vertex AI criar uma resposta.
A seguir
- Para saber como duplicar e personalizar esse modelo, consulte Início rápido: personalizar e implantar um modelo do Google.
- Defina suas próprias configurações criando modelos de aplicativos.
- Identifique as práticas recomendadas gerais de arquitetura com o Google Cloud Framework de arquitetura.