
Cette architecture de référence est particulièrement adaptée aux cas d'utilisation suivants :
- Vous avez besoin d'une protection régionale en complément de votre protection zonale pour vos applications critiques.
Cette architecture de référence pour la disponibilité intègre des instances répliquées avec accès en lecture dans la région même pour la haute disponibilité et entre les régions pour la reprise après sinistre. Ce déploiement multirégional protège contre les perturbations importantes, y compris les pannes de courant généralisées et les catastrophes naturelles à grande échelle.
Considérations relatives à l'architecture de référence pour la disponibilité
Lorsque vous évaluez cette architecture de référence pour la disponibilité, tenez compte des facteurs suivants :
- Latence et bande passante du réseau dans la région et entre les régions
- Emplacement géographique des bases de données et des serveurs d'application
- Stratégie pour décharger les charges de travail en lecture seule vers les instances répliquées
- Déploiement de la haute disponibilité dans la région de reprise après sinistre à distance
Un équilibrage de charge en lecture seule peut être nécessaire, en particulier si vous utilisez des serveurs d'application régionaux, afin que les requêtes soient transférées vers la base de données la plus proche pour obtenir la réponse la plus rapide. Pour en savoir plus, consultez Routage des requêtes vers un équilibreur de charge d'application classique multirégional.
Une surveillance supplémentaire peut être nécessaire pour la réplication interrégionale afin de s'assurer que le décalage de réplication ne commence pas à augmenter en raison de la charge de transactions ou de la capacité du réseau.
Pour vous assurer que votre reprise après sinistre est réussie, veillez à effectuer des tests approfondis. Il est important de tester la fonctionnalité et le débit de l'application en cas de connexions réseau à latence élevée entre les serveurs d'applications et la base de données.
Architectures à haute disponibilité dans une région et de reprise après sinistre entre les régions
La figure 1 montre une configuration de haute disponibilité et de reprise après sinistre suggérée avec trois bases de données de secours répliquées avec accès en lecture dans trois zones de disponibilité et deux régions.
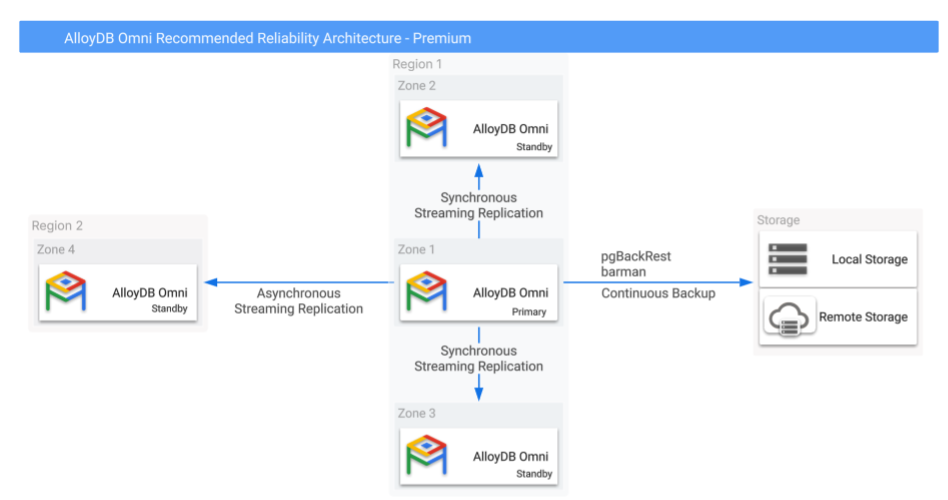
Figure 1 : AlloyDB Omni avec options de sauvegarde et de haute disponibilité interrégionale.
Comme l'illustre la figure 1, la réplication par streaming synchrone vers des instances répliquées locales (dans la même région) offre une haute disponibilité, tandis que la réplication par streaming asynchrone vers une instance répliquée distante géographiquement distincte offre une protection de reprise après sinistre régionale. Dans l'ensemble de la configuration, seule l'instance principale peut effectuer des opérations de lecture/écriture, tandis que les autres instances répliquées peuvent répondre aux requêtes de lecture.
Configurez la réplication de l'instance principale vers les instances de la même région en mode synchrone, tandis que la réplication vers les instances interrégionales doit être configurée en mode asynchrone pour éviter que la latence n'affecte les performances d'écriture de l'instance principale. En cas de défaillance régionale, cette configuration peut entraîner un RPO non nul. Toutefois, cette configuration permet un RTO plus rapide en cas de défaillance. En effet, la base de données principale n'a pas besoin d'attendre la confirmation des bases de données de secours distantes avant de valider les transactions.
Il est possible d'effectuer des sauvegardes interrégionales supplémentaires à partir des bases de données d'instances répliquées avec accès en lecture, ce qui ajoute de la redondance aux sauvegardes effectuées à partir de la base de données principale.
Sauvegardes des instances répliquées avec accès en lecture
Lorsque vous utilisez des déploiements non Kubernetes, vous pouvez choisir de déployer des sauvegardes en fonction des besoins de votre entreprise.
Tenez compte des éléments suivants :
- Si votre sauvegarde à distance est susceptible d'être affectée par une défaillance régionale, vous devez lancer des sauvegardes supplémentaires dans les régions alternatives.
- Si vous avez besoin d'une redondance de sauvegarde, vous devez effectuer des sauvegardes régionales d'instances répliquées avec accès en lecture.
Emplacement de l'instance répliquée avec accès en lecture pour prendre en charge la disponibilité multizone
Dans les déploiements non Kubernetes, vous pouvez choisir des instances répliquées avec accès en lecture spécifiques pour qu'elles assument le rôle de l'instance principale en cas de défaillance de celle-ci.
Migration d'une architecture à haute disponibilité seulement vers une architecture à haute disponibilité avec reprise après sinistre
Pour les déploiements non Kubernetes, vous devez créer une nouvelle instance de secours dans une nouvelle région et ajouter cette configuration à celle du cluster Patroni.
Implémentation
Lorsque vous choisissez une architecture de référence pour la disponibilité, gardez à l'esprit les avantages, les limites et les options suivantes.
Avantages
- Protection contre les défaillances zonales et d'instances
- Protection contre les défaillances régionales
- RTO réduit en cas de défaillance régionale de la base de données
Limites
- Vous pouvez réduire le RPO pour la reprise régionale avec la réplication synchrone, mais cette approche entraîne une latence supplémentaire pour les performances des transactions. Pour la reprise après sinistre et la réplication dans une région distante, nous vous recommandons d'utiliser uniquement la réplication asynchrone.
- La configuration du streaming WAL PostgreSQL en mode synchrone permet d'éviter toute perte de données (
RPO=0) durant le fonctionnement normal ou les basculements typiques. Toutefois, cette approche ne protège pas contre la perte de données dans des situations spécifiques de double défaillance, par exemple lorsque toutes les instances de secours sont perdues ou deviennent inaccessibles depuis l'instance principale, et que l'instance principale redémarre immédiatement après.
Options de protection des données
- L'architecture à disponibilité standard pour les options de sauvegarde et de reprise après sinistre.
- L'architecture à disponibilité améliorée pour les options de haute disponibilité.
Étapes suivantes
- Présentation de l'architecture de référence de disponibilité d'AlloyDB Omni
- Disponibilité standard d'AlloyDB Omni
- Disponibilité d'AlloyDB Omni Enhanced
- Utiliser la réplication entre centres de données
- Routage des requêtes vers un équilibreur de charge d'application classique multirégional