
本文將概略說明 AlloyDB for PostgreSQL 執行個體的高可用性 (HA) 設定。如要為 HA 設定新的執行個體,或在現有執行個體上啟用 HA,請參閱「查看叢集和執行個體設定」。
高可用性設定可確保即使發生故障事件,作業也能持續進行。雖然區域執行個體在發生故障事件時可能會長時間停機,但高可用性執行個體可確保用戶端應用程式持續存取資料。
主要和次要執行個體
設定高可用性的 AlloyDB 主要執行個體包含常態啟用的節點和待命節點,這兩個節點位於不同區域。在儲存方面,AlloyDB 會使用區域記錄檔保存器儲存資料庫預先寫入記錄檔 (WAL),並使用 AlloyDB 的區域儲存空間服務儲存資料區塊。執行個體的 IP 位址會使用負載平衡器,將流量轉送至作用中節點。
處理寫入作業時,AlloyDB 資料庫會先將 WAL 寫入作用中節點的區域記錄保存器,然後將記錄非同步傳輸至 AlloyDB 的區域記錄處理伺服器,這些伺服器會將記錄具體化為資料區塊,以供長期儲存。AlloyDB 接著會清除已成功處理的記錄。
下圖顯示高可用性架構。
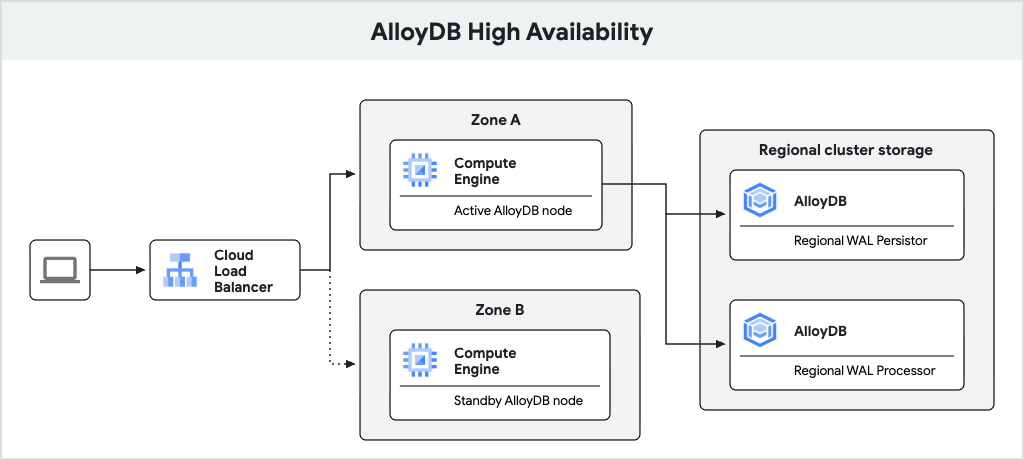
圖 1. 高可用性架構。
容錯移轉
如果作用中節點無法使用,AlloyDB 會自動將主要執行個體容錯移轉至待命節點,該節點會成為新的作用中節點。負載平衡器會辨識新的有效節點,並開始將流量轉送至該節點。容錯移轉後,即使原始節點恢復連線,新的作用中節點仍會保持作用中狀態。由於系統會將 WAL 同步寫入區域記錄保留器,因此容錯移轉期間不會遺失資料。
下圖顯示容錯移轉後的流量流動情形。
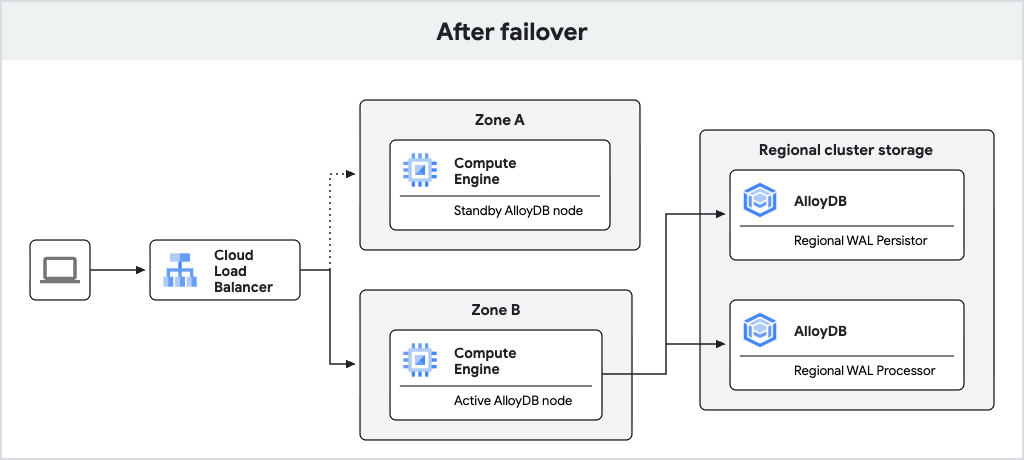
圖 2. 容錯移轉後的流量。
容錯移轉會依下列事件順序發生:
- 使用中節點或區域發生故障。AlloyDB 健康狀態監控系統會定期檢查有效節點是否正常運作。如果健康狀態監控系統多次檢查失敗,就會啟動容錯移轉。這項偵測作業最多可能需要 30 秒。
- 資料庫會在待命節點上啟動,並開始接受連線。 這通常會在 30 秒內完成。
- 待命節點將升級為主要節點。新主要節點會使用執行個體的靜態 IP 位址開始提供資料,且用戶端查詢會在重新連線後成功。
- AlloyDB 會在先前作用中的區域中重建待命節點。這個待命節點隨後即可用於日後的容錯移轉。
需求條件
為了讓 AlloyDB 允許容錯移轉,設定必須符合以下條件要求:
- 主要執行個體必須處於正常作業狀態 (非停止或維護中)。
- 待命區域和待命節點都必須運作正常。
新架構
使用 PostgreSQL 18 建立的 AlloyDB 執行個體,可透過熱待命功能提升容錯移轉效果。
AlloyDB 會將待命節點做為副本執行,在容錯移轉期間,這個副本可以更快轉換為讀寫模式,縮短停機時間。此外,複製作業會啟用暖快取,有助於確保容錯移轉後查詢效能一致。
下圖顯示包含熱待機的高可用性架構。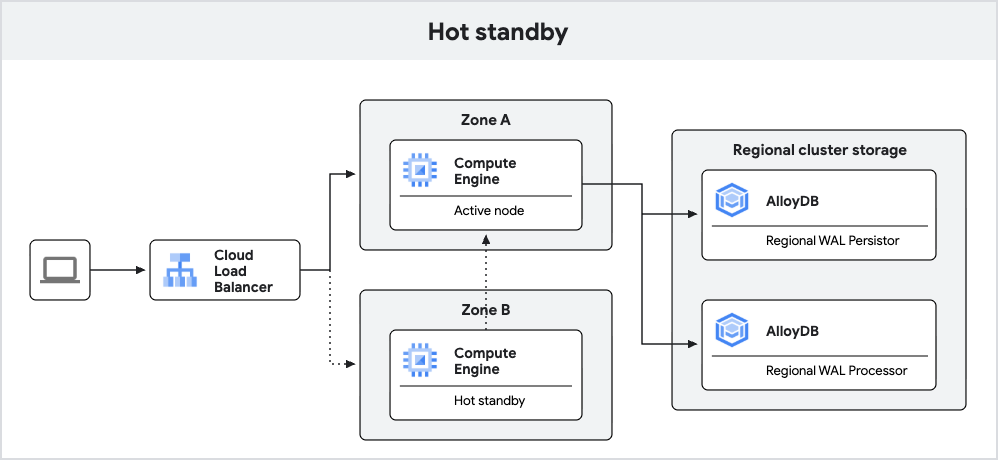
圖 3. 熱待命。
讀取集區
含有兩個以上節點的讀取集區執行個體具備高可用性。節點平均分布在各個可用區,因此可因應故障事件。如果發生節點或可用區故障等失敗事件,區域負載平衡器會將流量轉送至其餘運作正常的節點,確保用戶端不會發生停機情形。
主要執行個體容錯移轉期間,讀取集區會保持連線狀態。容錯移轉期間,系統會暫時停止從主要執行個體複製 WAL,並在主要執行個體復原後自動繼續複製。