
Este documento oferece uma visão geral da configuração de alta disponibilidade (HA) para instâncias do AlloyDB para PostgreSQL. Para configurar uma nova instância de HA ou ativar a HA em uma instância atual, consulte Conferir as configurações de cluster e instância settings.
Uma configuração de HA garante a continuidade das operações mesmo após eventos de falha. Embora as instâncias zonais possam sofrer um tempo de inatividade prolongado durante eventos de falha, com a HA, seus dados permanecem disponíveis para aplicativos cliente.
Instâncias primárias e secundárias
Uma instância primária do AlloyDB configurada com alta disponibilidade inclui um nó ativo e um nó de espera, que estão localizados em zonas diferentes. Para armazenamento, o AlloyDB usa um persistente de registro regional para armazenar registros prévios de escrita (WAL, na sigla em inglês) do banco de dados e o serviço de armazenamento regional do AlloyDB para armazenar blocos de dados. O endereço IP da instância roteia o tráfego para o nó ativo usando um balanceador de carga.
Ao processar gravações, o banco de dados do AlloyDB primeiro grava o WAL no persistente de registro regional no nó ativo e, em seguida, transfere os registros de forma assíncrona para os servidores de processamento de registro regionais do AlloyDB, que materializam os registros em blocos de dados para armazenamento de longo prazo. Em seguida, o AlloyDB limpa os registros processados.
O diagrama a seguir mostra a arquitetura de alta disponibilidade.
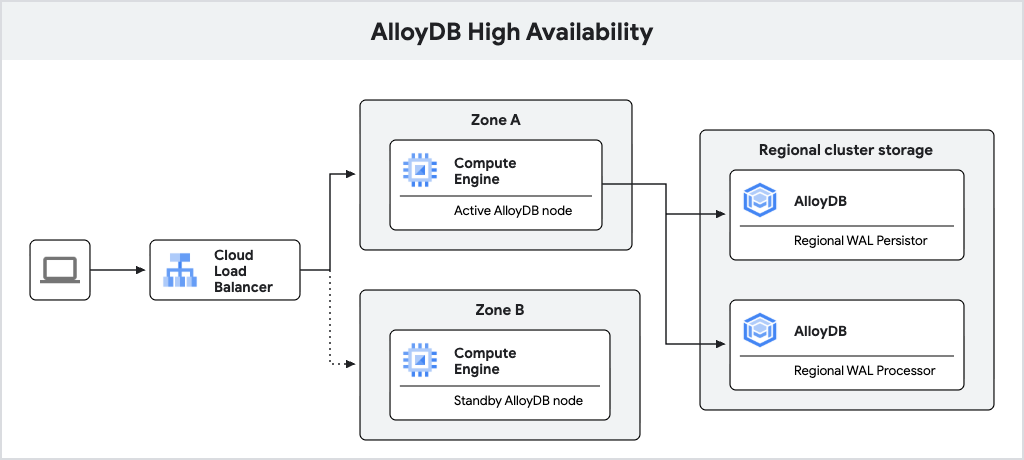
Fig. 1. Arquitetura de alta disponibilidade.
Failover
Se o nó ativo ficar indisponível, o AlloyDB fará automaticamente o failover da instância principal para o nó de espera, que se tornará o novo nó ativo. O balanceador de carga reconhece o novo nó ativo e começa a rotear o tráfego para ele. Após um failover, o novo nó ativo permanece ativo mesmo depois que o nó original volta a ficar on-line. Não ocorre perda de dados durante o failover devido a gravações WAL síncronas no persistente de registro regional.
O diagrama a seguir mostra o fluxo de tráfego após o failover.
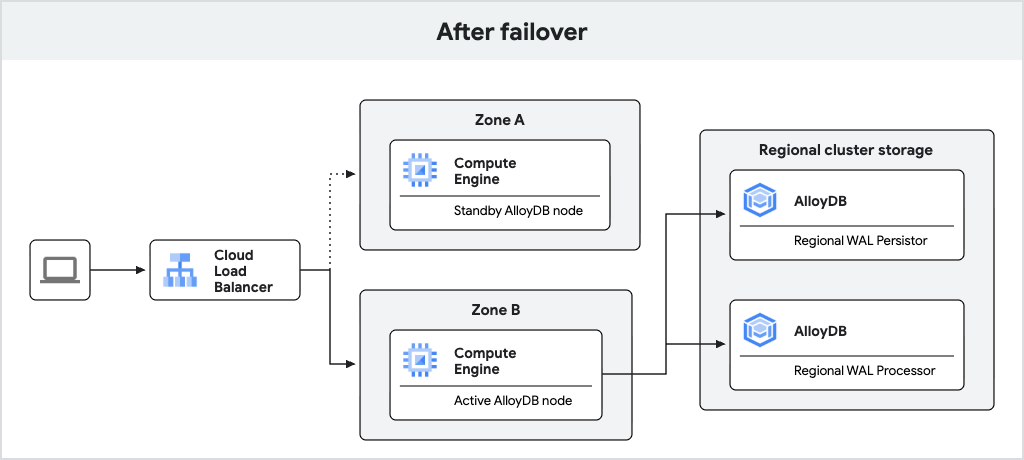
Fig. 2. Fluxo de tráfego após o failover.
Um failover ocorre na seguinte sequência de eventos:
- A zona ou o nó ativo falha. O sistema de monitoramento de integridade do AlloyDB verifica periodicamente se o nó ativo está íntegro. Se o sistema de monitoramento de integridade falhar em várias verificações, ele iniciará o failover. Essa detecção pode levar até 30 segundos.
- O banco de dados é iniciado no nó de espera e começa a aceitar conexões. Isso geralmente leva menos de 30 segundos.
- O nó de espera é promovido para principal. Usando o endereço IP estático da instância, o novo nó principal começa a veicular dados, e as consultas do cliente são bem-sucedidas após uma reconexão.
- O AlloyDB recria um nó de espera na zona anteriormente ativa. Esse nó de espera fica pronto para failovers futuros.
Requisitos
Para que o AlloyDB permita o failover, a configuração precisa atender a estes requisitos:
- A instância principal precisa estar em um estado operacional normal (não interrompida ou em manutenção).
- A zona de espera e o nó de espera precisam estar íntegros.
Nova arquitetura
As instâncias do AlloyDB recém-criadas com o PostgreSQL 18 oferecem failover aprimorado usando o recurso de espera ativa.
Com o recurso de espera ativa, o AlloyDB executa o nó de espera como uma réplica. Durante o failover, essa réplica pode fazer a transição para um modo de leitura/gravação mais rápido, reduzindo o tempo de inatividade. Além disso, a replicação permite caches ativos, o que ajuda a garantir um desempenho de consulta consistente após o failover.
O diagrama a seguir mostra a arquitetura de alta disponibilidade com a espera ativa incluída.
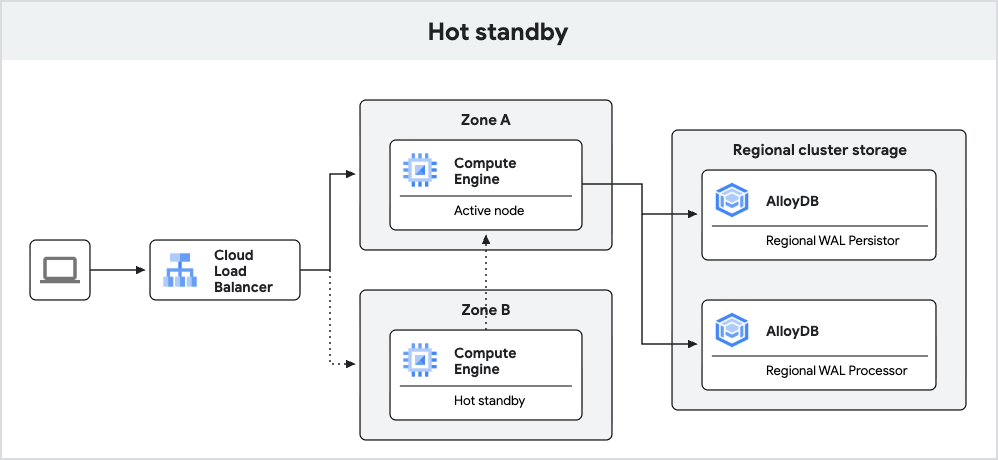
Fig. 3. Espera ativa.
Pools de leitura
As instâncias do pool de leitura com dois ou mais nós são altamente disponíveis. Os nós são distribuídos uniformemente entre as zonas, criando resiliência a eventos de falha. Em caso de eventos de falha, como uma falha de nó ou zona, um balanceador de carga regional roteia o tráfego para os nós íntegros restantes, garantindo que não haja tempo de inatividade para seus clientes.
Os pools de leitura permanecem on-line durante um failover de instância principal. A replicação WAL da instância principal é pausada temporariamente durante o failover e é retomada automaticamente após a recuperação da instância principal.
A seguir
- Fazer failover manual de uma instância principal ou secundária.
- Testar uma instância principal para alta disponibilidade.
- Reduzir custos usando instâncias básicas.