
Dokumen ini memberikan ringkasan konfigurasi ketersediaan tinggi (HA) untuk instance AlloyDB for PostgreSQL. Untuk mengonfigurasi instance baru untuk HA atau mengaktifkan HA pada instance yang ada, lihat Melihat setelan cluster dan instance.
Konfigurasi HA memastikan kelangsungan operasi meskipun setelah peristiwa kegagalan. Meskipun instance zona dapat mengalami periode nonaktif yang lebih lama selama peristiwa kegagalan, dengan ketersediaan tinggi (HA), data Anda akan tetap tersedia untuk aplikasi klien.
Instance utama dan sekunder
Instance utama AlloyDB yang dikonfigurasi dengan ketersediaan tinggi mencakup node aktif dan node standby, yang terletak di zona yang berbeda. Untuk penyimpanan, AlloyDB menggunakan persistor log regional untuk menyimpan write-ahead log (WAL) database dan layanan penyimpanan regional AlloyDB untuk menyimpan blok data. Alamat IP instance merutekan traffic ke node aktif menggunakan load balancer.
Saat memproses penulisan, database AlloyDB pertama-tama menulis WAL ke persistor log regionalnya di node aktif, lalu mentransfer log secara asinkron ke server pemrosesan log regional AlloyDB, yang mewujudkan log menjadi blok data untuk penyimpanan jangka panjang. Kemudian, AlloyDB membersihkan log yang berhasil diproses.
Diagram berikut menunjukkan arsitektur ketersediaan tinggi.
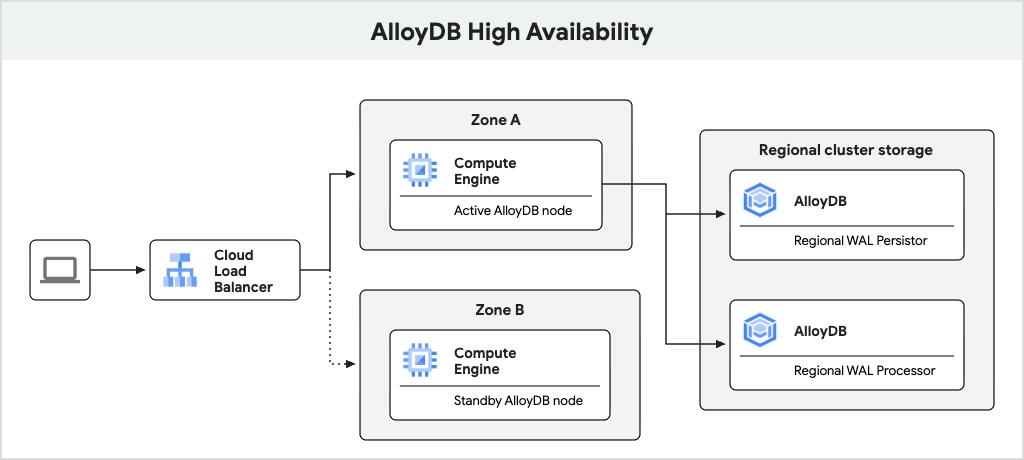
Gambar 1. Arsitektur ketersediaan tinggi.
Failover
Jika node aktif tidak tersedia, AlloyDB akan otomatis melakukan failover instance utama ke node standby-nya, yang akan menjadi node aktif baru. Load balancer mengenali node aktif baru dan mulai merutekan traffic ke node tersebut. Setelah failover, node aktif baru akan tetap aktif meskipun setelah node asli kembali online. Tidak ada kehilangan data selama failover karena penulisan WAL sinkron ke persistor log regional.
Diagram berikut menunjukkan alur traffic setelah failover.
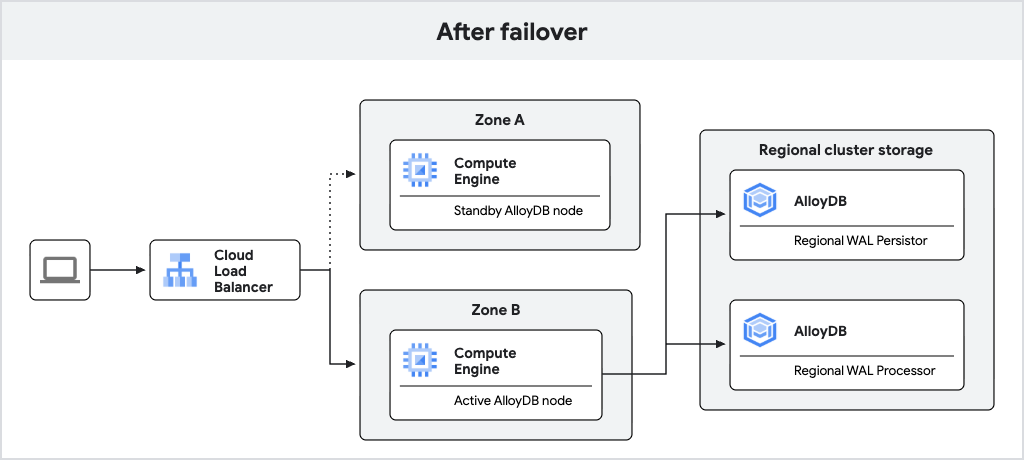
Gambar 2. Alur traffic setelah failover.
Failover terjadi dalam urutan peristiwa berikut:
- Node atau zona aktif gagal. Sistem pemantauan kondisi AlloyDB secara berkala memeriksa apakah node aktif dalam kondisi baik. Jika sistem pemantauan kesehatan gagal dalam beberapa pemeriksaan, sistem akan memulai failover. Deteksi ini dapat memerlukan waktu hingga 30 detik.
- Database dimulai di node standby dan mulai menerima koneksi. Proses ini biasanya memerlukan waktu kurang dari 30 detik.
- Node standby dipromosikan menjadi node utama. Menggunakan alamat IP statis instance, node utama baru mulai menyalurkan data, dan kueri klien berhasil setelah terhubung kembali.
- AlloyDB membuat ulang node standby di zona yang sebelumnya aktif. Node standby ini kemudian siap untuk failover di masa mendatang.
Persyaratan
Agar AlloyDB mengizinkan failover, konfigurasi harus memenuhi persyaratan berikut:
- Instance primer harus dalam status operasi normal (tidak dihentikan atau sedang dalam pemeliharaan).
- Zona standby dan node standby harus dalam kondisi responsif.
Arsitektur baru
Instance AlloyDB yang baru dibuat dengan PostgreSQL 18 memberikan failover yang lebih baik menggunakan fitur hot standby.
Dengan fitur hot standby, AlloyDB menjalankan node standby sebagai replika. Selama failover, replika ini dapat bertransisi ke mode baca-tulis lebih cepat, sehingga mengurangi waktu nonaktif. Selain itu, replikasi memungkinkan cache yang siap digunakan, yang membantu memastikan performa kueri yang konsisten setelah failover.
Diagram berikut menunjukkan arsitektur ketersediaan tinggi dengan standby aktif disertakan.
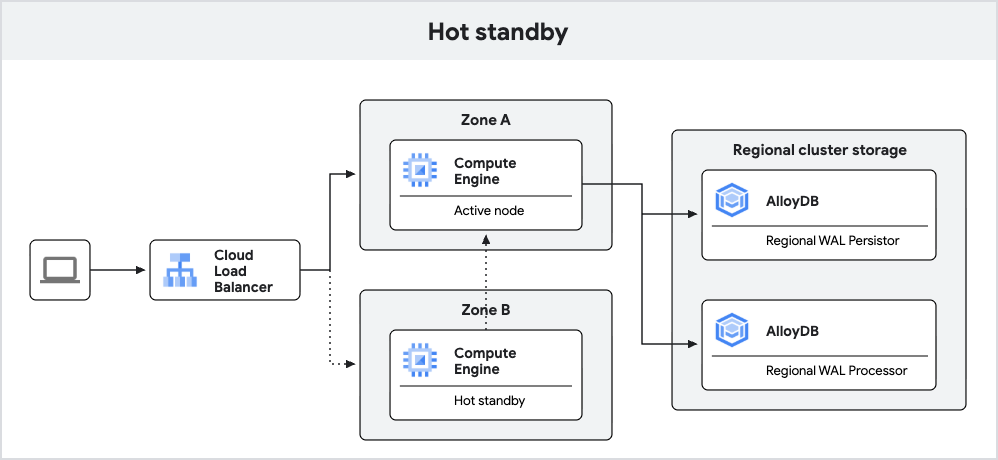
Gambar 3. Hot standby.
Membaca kumpulan
Instance kumpulan baca dengan dua node atau lebih memiliki ketersediaan tinggi. Node didistribusikan secara merata di seluruh zona, sehingga menciptakan ketahanan terhadap peristiwa kegagalan. Jika terjadi peristiwa kegagalan seperti kegagalan node atau zona, load balancer regional akan merutekan traffic ke node responsif yang tersisa, sehingga memastikan tidak ada periode nonaktif untuk klien Anda.
Kumpulan baca tetap online selama failover instance utama. Replikasi WAL dari instance utama dijeda sementara selama failover dan dilanjutkan secara otomatis setelah instance utama dipulihkan.
Langkah berikutnya
- Melakukan failover instance utama atau sekunder secara manual.
- Uji instance utama untuk ketersediaan tinggi.
- Kurangi biaya menggunakan instance dasar.