
Ce document présente la configuration de la haute disponibilité (HA) pour les instances AlloyDB pour PostgreSQL. Pour configurer la haute disponibilité pour une nouvelle instance ou l'activer sur une instance existante, consultez Afficher les paramètres du cluster et de l'instance.
Une configuration HA assure la continuité des opérations, même en cas d'échec. Bien que les instances zonales puissent subir des temps d'arrêt prolongés en cas de défaillance, la haute disponibilité permet à vos données de rester disponibles pour les applications clientes.
Instances principales et secondaires
Une instance principale AlloyDB configurée avec la haute disponibilité inclut un nœud actif et un nœud de secours, qui sont situés dans des zones différentes. Pour le stockage, AlloyDB utilise un persistor de journaux régional pour stocker les journaux WAL (Write-Ahead Log) de la base de données et le service de stockage régional d'AlloyDB pour stocker les blocs de données. L'adresse IP de l'instance achemine le trafic vers le nœud actif à l'aide d'un équilibreur de charge.
Lors du traitement des écritures, la base de données AlloyDB écrit d'abord le WAL dans son persistor de journaux régional sur le nœud actif, puis transfère les journaux de manière asynchrone vers les serveurs de traitement des journaux régionaux d'AlloyDB, qui matérialisent les journaux en blocs de données pour le stockage à long terme. AlloyDB nettoie ensuite les journaux qui ont été traités avec succès.
Le schéma suivant illustre l'architecture à haute disponibilité.
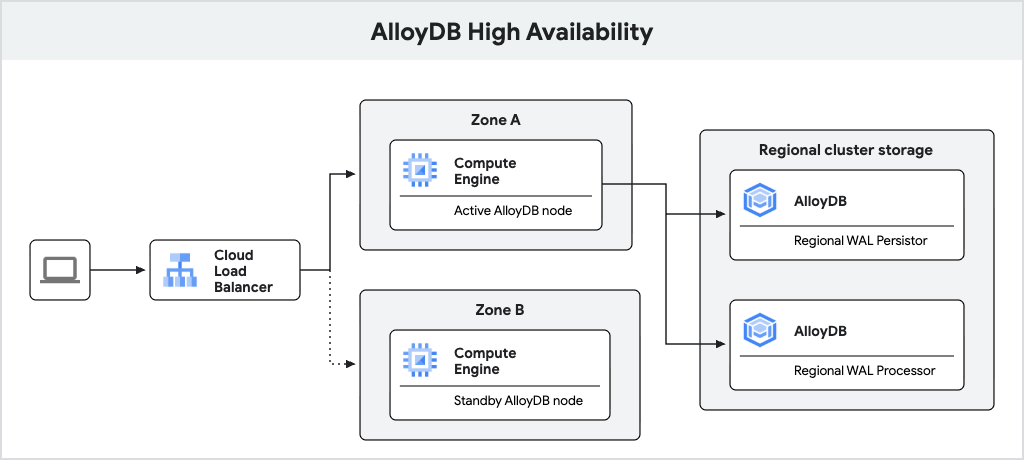
Fig. 1. Architecture à haute disponibilité
Basculement
Si le nœud actif devient indisponible, AlloyDB bascule automatiquement l'instance principale vers son nœud de secours, qui devient le nouveau nœud actif. L'équilibreur de charge reconnaît le nouveau nœud actif et commence à y acheminer le trafic. Après un basculement, le nouveau nœud actif reste actif même après la reconnexion du nœud d'origine. Aucune perte de données ne se produit lors du basculement en raison des écritures WAL synchrones dans le persistor de journaux régionaux.
Le schéma suivant illustre le flux de trafic après le basculement.
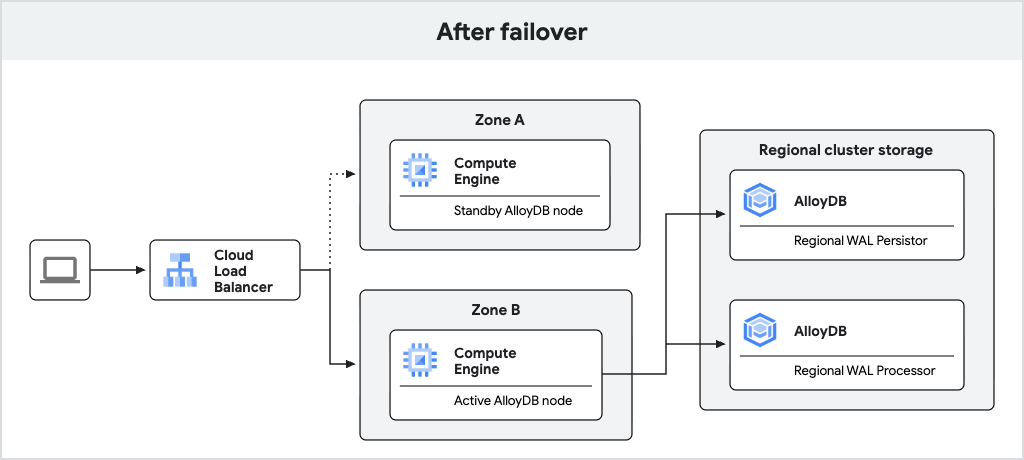
Fig. 2. Flux de trafic après le basculement.
Un basculement se produit dans la séquence d'événements suivante :
- Le nœud ou la zone actifs échouent. Le système de surveillance de l'état d'AlloyDB vérifie régulièrement si le nœud actif est opérationnel. Si le système de surveillance de l'état échoue à plusieurs vérifications, il lance le basculement. Cette détection peut prendre jusqu'à 30 secondes.
- La base de données démarre sur le nœud de secours et commence à accepter les connexions. Cela prend généralement moins de 30 secondes.
- Le nœud de secours devient le nœud principal. À l'aide de l'adresse IP statique de l'instance, le nouveau nœud principal commence à diffuser des données, et les requêtes client aboutissent après une reconnexion.
- AlloyDB recrée un nœud de secours dans la zone précédemment active. Ce nœud de secours est alors prêt pour de futurs basculements.
Conditions requises
Pour qu'AlloyDB autorise un basculement, la configuration doit répondre aux critères suivants :
- L'instance principale doit se trouver dans un état de fonctionnement normal (elle n'est pas arrêtée ni en cours de maintenance).
- La zone et le nœud de secours doivent tous deux être opérationnels.
Nouvelle architecture
Les instances AlloyDB nouvellement créées avec PostgreSQL 18 offrent un basculement amélioré grâce à la fonctionnalité Hot Standby.
Avec la fonctionnalité de secours à chaud, AlloyDB exécute le nœud de secours en tant qu'instance dupliquée. Lors du basculement, cette réplique peut passer plus rapidement en mode lecture/écriture, ce qui réduit les temps d'arrêt. De plus, la réplication permet d'activer les caches "chauds", ce qui contribue à garantir des performances de requête cohérentes après le basculement.
Le schéma suivant illustre l'architecture à haute disponibilité avec le serveur de secours actif inclus.
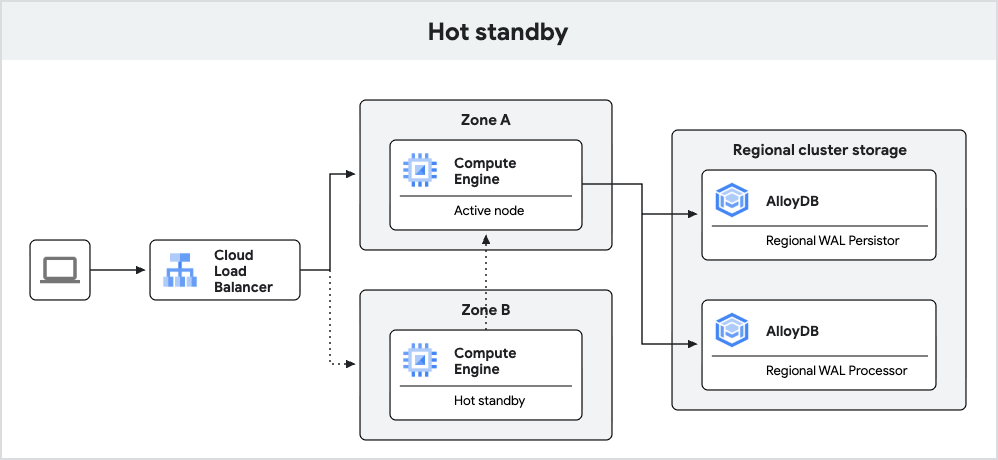
Fig. 3. Système de secours à chaud
Pools de lecture
Les instances de pool de lecture comportant au moins deux nœuds offrent une disponibilité élevée. Les nœuds sont répartis de manière égale entre les zones, ce qui permet de résister aux événements de défaillance. En cas d'événements de défaillance tels qu'une défaillance de nœud ou de zone, un équilibreur de charge régional achemine le trafic vers les nœuds opérationnels restants, ce qui garantit l'absence de temps d'arrêt pour vos clients.
Les pools de lecture restent en ligne lors d'un basculement d'instance principale. La réplication WAL à partir de l'instance principale est temporairement suspendue pendant le basculement et reprend automatiquement une fois l'instance principale récupérée.
Étapes suivantes
- Basculer manuellement une instance principale ou secondaire
- Tester la haute disponibilité d'une instance principale
- Réduisez les coûts en utilisant des instances de base.